Scientific Computing I
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Report Received March 2006
2005 was a busy year for me as of POSIX was published (the the USENIX standards represen- Shell and Utilities volume), and tative. There are three major it became a second ISO standard. NICHOLAS M. STOUGHTON standards that I watch carefully: Amendments to these standards I POSIX, which also incorpo- were also under development, USENIX rates the Single UNIX Specifi- and led to the addition of real- cation time interfaces, including Standards I ISO-C pthreads, to the core system call I The Linux Standard Base (LSB) set. Many of the other projects Activities died away as the people involved In order to do that, USENIX lost interest or hit political road- funds my participation in the blocks (most of which were Nick is the USENIX Standards committees that develop and reported in ;login: at the time). Liaison and represents the maintain these standards. Association in the POSIX, ISO C, Throughout 2005, the Free Until the end of the twentieth and LSB working groups. He is century, POSIX was developed the ISO organizational repre- Standards Group (FSG) also sentative to the Austin Group, helped fund these activities. For and maintained by IEEE exclu- a member of INCITS commit- each of these, let’s look at the his- sively. At the same time, the tees J11 and CT22, and the Open Group (also known as Specification Authority sub- tory of the standards, then at group leader for the LSB. what has happened over the past X/Open) had an entirely separate but 100% overlapping standard, [email protected] 12 months or so, and, finally, what is on the agenda for this known as the Single UNIX year. -

IT Acronyms.Docx
List of computing and IT abbreviations /.—Slashdot 1GL—First-Generation Programming Language 1NF—First Normal Form 10B2—10BASE-2 10B5—10BASE-5 10B-F—10BASE-F 10B-FB—10BASE-FB 10B-FL—10BASE-FL 10B-FP—10BASE-FP 10B-T—10BASE-T 100B-FX—100BASE-FX 100B-T—100BASE-T 100B-TX—100BASE-TX 100BVG—100BASE-VG 286—Intel 80286 processor 2B1Q—2 Binary 1 Quaternary 2GL—Second-Generation Programming Language 2NF—Second Normal Form 3GL—Third-Generation Programming Language 3NF—Third Normal Form 386—Intel 80386 processor 1 486—Intel 80486 processor 4B5BLF—4 Byte 5 Byte Local Fiber 4GL—Fourth-Generation Programming Language 4NF—Fourth Normal Form 5GL—Fifth-Generation Programming Language 5NF—Fifth Normal Form 6NF—Sixth Normal Form 8B10BLF—8 Byte 10 Byte Local Fiber A AAT—Average Access Time AA—Anti-Aliasing AAA—Authentication Authorization, Accounting AABB—Axis Aligned Bounding Box AAC—Advanced Audio Coding AAL—ATM Adaptation Layer AALC—ATM Adaptation Layer Connection AARP—AppleTalk Address Resolution Protocol ABCL—Actor-Based Concurrent Language ABI—Application Binary Interface ABM—Asynchronous Balanced Mode ABR—Area Border Router ABR—Auto Baud-Rate detection ABR—Available Bitrate 2 ABR—Average Bitrate AC—Acoustic Coupler AC—Alternating Current ACD—Automatic Call Distributor ACE—Advanced Computing Environment ACF NCP—Advanced Communications Function—Network Control Program ACID—Atomicity Consistency Isolation Durability ACK—ACKnowledgement ACK—Amsterdam Compiler Kit ACL—Access Control List ACL—Active Current -

Linux Standard Base Development Kit for Application Building/Porting
Linux Standard Base Development Kit for application building/porting Rajesh Banginwar Nilesh Jain Intel Corporation Intel Corporation [email protected] [email protected] Abstract validating binaries and RPM packages for LSB conformance. We conclude with a couple of case studies that demonstrate usage of the build The Linux Standard Base (LSB) specifies the environment as well as the associated tools de- binary interface between an application and a scribed in the paper. runtime environment. This paper discusses the LSB Development Kit (LDK) consisting of a build environment and associated tools to assist software developers in building/porting their applications to the LSB interface. Developers 1 Linux Standard Base Overview will be able to use the build environment on their development machines, catching the LSB porting issues early in the development cycle The Linux* Standard Base (LSB)[1] specifies and reducing overall LSB conformance testing the binary interface between an application and time and cost. Associated tools include appli- a runtime environment. The LSB Specifica- cation and package checkers to test for LSB tion consists of a generic portion, gLSB, and conformance of application binaries and RPM an architecture-specific portion, archLSB. As packages. the names suggest, gLSB contains everything that is common across all architectures, and This paper starts with the discussion of ad- archLSBs contain the things that are specific vantages the build environment provides by to each processor architecture, such as the ma- showing how it simplifies application develop- chine instruction set and C library symbol ver- ment/porting for LSB conformance. With the sions. availability of this additional build environment from LSB working group, the application de- As much as possible, the LSB builds on ex- velopers will find the task of porting applica- isting standards, including the Single UNIX tions to LSB much easier. -

Application Binary Interface for the ARM Architecture
ABI for the ARM Architecture (Base Standard) Application Binary Interface for the ARM® Architecture The Base Standard Document number: ARM IHI 0036B, current through ABI release 2.10 Date of Issue: 10th October 2008, reissued 24th November 2015 Abstract This document describes the structure of the Application Binary Interface (ABI) for the ARM architecture, and links to the documents that define the base standard for the ABI for the ARM Architecture. The base standard governs inter-operation between independently generated binary files and sets standards common to ARM- based execution environments. Keywords ABI for the ARM architecture, ABI base standard, embedded ABI How to find the latest release of this specification or report a defect in it Please check the ARM Information Center (http://infocenter.arm.com/) for a later release if your copy is more than one year old (navigate to the ARM Software development tools section, ABI for the ARM Architecture subsection). Please report defects in this specification to arm dot eabi at arm dot com. Licence THE TERMS OF YOUR ROYALTY FREE LIMITED LICENCE TO USE THIS ABI SPECIFICATION ARE GIVEN IN SECTION 1.4, Your licence to use this specification (ARM contract reference LEC-ELA-00081 V2.0). PLEASE READ THEM CAREFULLY. BY DOWNLOADING OR OTHERWISE USING THIS SPECIFICATION, YOU AGREE TO BE BOUND BY ALL OF ITS TERMS. IF YOU DO NOT AGREE TO THIS, DO NOT DOWNLOAD OR USE THIS SPECIFICATION. THIS ABI SPECIFICATION IS PROVIDED “AS IS” WITH NO WARRANTIES (SEE SECTION 1.4 FOR DETAILS). Proprietary notice ARM, Thumb, RealView, ARM7TDMI and ARM9TDMI are registered trademarks of ARM Limited. -

Eb-2015-00549 Document Date: 08/27/2015 To: INCITS Members
InterNational Committee for Information Technology Standards (INCITS) Secretariat: Information Technology Industry Council (ITI) 1101 K Street NW, Suite 610, Washington, DC 20005 www.INCITS.org eb-2015-00549 Document Date: 08/27/2015 To: INCITS Members Reply To: Deborah J. Spittle Subject: Public Review and Comments Register for the Reaffirmations of: Due Date: The public review is from August 28, 2015 to October 27, 2015. The InterNational Committee for Information Technology Standards (INCITS) announces Action: that the subject-referenced document(s) is being circulated for a 60-day public review and comment period. Comments received during this period will be considered and answered. Commenters who have objections/suggestions to this document should so indicate and include their reasons. All comments should be forwarded not later than the date noted above to the following address: INCITS Secretariat/ITI 1101 K Street NW - Suite 610 Washington DC 20005-3922 Email: [email protected] (preferred) This public review also serves as a call for patents and any other pertinent issues (copyrights, trademarks). Correspondence regarding intellectual property rights may be emailed to the INCITS Secretariat at [email protected]. INCITS/ISO/IEC 14443- Identification cards - Contactless Integrated Circuit Cards (CICCs) - Proximity integrated circuit9s0 1:2008[2010] cards Part 1: physical characteristics INCITS/ISO/IEC 19785- Information technology - Common Biometric Exchange File Formats Framework (CBEFF) - Part 3: 3:2007/AM 1:2010[2010] -

ISO/IEC JTC 1 N8426 2006-11-28 Replaces
ISO/IEC JTC 1 N8426 2006-11-28 Replaces: ISO/IEC JTC 1 Information Technology Document Type: Resolutions Document Title: Final Resolutions Adopted at the 21st Meeting of ISO/IEC JTC 1 13-17 November 2006 in South Africa Document Source: JTC 1 Secretary Project Number: Document Status: This document is circulated to JTC 1 National Bodies for information. Action ID: FYI Due Date: Distribution: Medium: No. of Pages: 20 Secretariat, ISO/IEC JTC 1, American National Standards Institute, 25 West 43rd Street, New York, NY 10036; Telephone: 1 212 642 4932; Facsimile: 1 212 840 2298; Email: [email protected] FINAL Resolutions Adopted at the 21st Meeting of ISO/IEC JTC 1 13-17 November 2006 in South Africa Resolution 1 - JTC 1 Business Plan JTC 1 approves document JTC 1 N 8352, as the current JTC 1 Business Plan. Unanimous Resolution 2 – JTC 1 Long Term Business Plan and Long Term Business Plan Implementation Plan JTC 1 approves document JTC 1 N 7974 as the Long Term Business Plan and document JTC 1 N 7975 as the Long Term Business Plan Implementation Plan. JTC 1 further instructs the JTC 1 Chairman to review these documents and to submit proposals for change to the plans to keep them current. Unanimous Resolution 3 – Approved Criteria for Free Availability of JTC 1 Standards JTC 1 instructs its Secretariat to redistribute the Approved Criteria for Free Availability of JTC 1 Standards (JTC 1 N 7604) to its National Bodies and Subcommittees in order to remind them of what ISO Council and IEC Council Board have agreed. -

Linux Standard Base Core Specification for IA32 4.1
Linux Standard Base Core Specification for IA32 4.1 Linux Standard Base Core Specification for IA32 4.1 ISO/IEC 23360 Part 2:2010(E) Copyright © 2010 Linux Foundation Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.1; with no Invariant Sections, with no Front-Cover Texts, and with no Back- Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License". Portions of the text may be copyrighted by the following parties: • The Regents of the University of California • Free Software Foundation • Ian F. Darwin • Paul Vixie • BSDI (now Wind River) • Andrew G Morgan • Jean-loup Gailly and Mark Adler • Massachusetts Institute of Technology • Apple Inc. • Easy Software Products • artofcode LLC • Till Kamppeter • Manfred Wassman • Python Software Foundation These excerpts are being used in accordance with their respective licenses. Linux is the registered trademark of Linus Torvalds in the U.S. and other countries. UNIX is a registered trademark of The Open Group. LSB is a trademark of the Linux Foundation in the United States and other countries. AMD is a trademark of Advanced Micro Devices, Inc. Intel and Itanium are registered trademarks and Intel386 is a trademark of Intel Corporation. PowerPC is a registered trademark and PowerPC Architecture is a trademark of the IBM Corporation. S/390 is a registered trademark of the IBM Corporation. OpenGL is a registered trademark of Silicon Graphics, Inc. ISO/IEC 23360 Part 2:2010(E) -

Linux Standard Base Core Specification 2.0.1
Linux Standard Base Core Specification 2.0 .1 Linux Standard Base Core Specification 2.0 .1 Copyright © 2004 Free Standards Group Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.1; with no Invariant Sections, with no Front-Cover Texts, and with no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License". Portions of the text are copyrighted by the following parties: • The Regents of the University of California • Free Software Foundation • Ian F. Darwin • Paul Vixie • BSDI (now Wind River) • Andrew G Morgan • Jean-loup Gailly and Mark Adler • Massachusetts Institute of Technology These excerpts are being used in accordance with their respective licenses. Linux is a trademark of Linus Torvalds. UNIX a registered trademark of the Open Group in the United States and other countries. LSB is a trademark of the Free Standards Group in the USA and other countries. AMD is a trademark of Advanced Micro Devices, Inc. Intel and Itanium are registered trademarks and Intel386 is a trademarks of Intel Corporation. OpenGL is a registered trademark of Silicon Graphics, Inc. Specification Introduction Specification Introduction Table of Contents Foreword .......................................................................................................................................................................i Introduction ............................................................................................................................................................... -

Sibylfs: Formal Specification and Oracle-Based Testing for POSIX and Real-World File Systems
SibylFS: formal specification and oracle-based testing for POSIX and real-world file systems Tom Ridge1 David Sheets2 Thomas Tuerk3 Andrea Giugliano1 Anil Madhavapeddy2 Peter Sewell2 1University of Leicester 2University of Cambridge 3FireEye http://sibylfs.io/ Abstract 1. Introduction Systems depend critically on the behaviour of file systems, Problem File systems, in common with several other key but that behaviour differs in many details, both between systems components, have some well-known but challeng- implementations and between each implementation and the ing properties: POSIX (and other) prose specifications. Building robust and portable software requires understanding these details and differences, but there is currently no good way to system- • they provide behaviourally complex abstractions; atically describe, investigate, or test file system behaviour • there are many important file system implementations, across this complex multi-platform interface. each with its own internal complexities; In this paper we show how to characterise the envelope • different file systems, while broadly similar, nevertheless of allowed behaviour of file systems in a form that enables behave quite differently in some cases; and practical and highly discriminating testing. We give a math- • other system software and applications often must be ematically rigorous model of file system behaviour, SibylFS, written to be portable between file systems, and file sys- that specifies the range of allowed behaviours of a file sys- tems themselves are sometimes ported from one OS to tem for any sequence of the system calls within our scope, another, or written to support application portability. and that can be used as a test oracle to decide whether an ob- served trace is allowed by the model, both for validating the File system behaviour, and especially these variations in be- model and for testing file systems against it. -
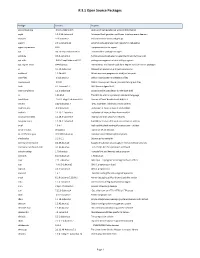
R 3.1 Open Source Packages
R 3.1 Open Source Packages Package Version Purpose accountsservice 0.6.15-2ubuntu9.3 query and manipulate user account information acpid 1:2.0.10-1ubuntu3 Advanced Configuration and Power Interface event daemon adduser 3.113ubuntu2 add and remove users and groups apport 2.0.1-0ubuntu12 automatically generate crash reports for debugging apport-symptoms 0.16 symptom scripts for apport apt 0.8.16~exp12ubuntu10.27 commandline package manager aptitude 0.6.6-1ubuntu1 Terminal-based package manager (terminal interface only) apt-utils 0.8.16~exp12ubuntu10.27 package managment related utility programs apt-xapian-index 0.44ubuntu5 maintenance and search tools for a Xapian index of Debian packages at 3.1.13-1ubuntu1 Delayed job execution and batch processing authbind 1.2.0build3 Allows non-root programs to bind() to low ports base-files 6.5ubuntu6.2 Debian base system miscellaneous files base-passwd 3.5.24 Debian base system master password and group files bash 4.2-2ubuntu2.6 GNU Bourne Again Shell bash-completion 1:1.3-1ubuntu8 programmable completion for the bash shell bc 1.06.95-2 The GNU bc arbitrary precision calculator language bind9-host 1:9.8.1.dfsg.P1-4ubuntu0.16 Version of 'host' bundled with BIND 9.X binutils 2.22-6ubuntu1.4 GNU assembler, linker and binary utilities bsdmainutils 8.2.3ubuntu1 collection of more utilities from FreeBSD bsdutils 1:2.20.1-1ubuntu3 collection of more utilities from FreeBSD busybox-initramfs 1:1.18.5-1ubuntu4 Standalone shell setup for initramfs busybox-static 1:1.18.5-1ubuntu4 Standalone rescue shell with tons of built-in utilities bzip2 1.0.6-1 High-quality block-sorting file compressor - utilities ca-certificates 20111211 Common CA certificates ca-certificates-java 20110912ubuntu6 Common CA certificates (JKS keystore) checkpolicy 2.1.0-1.1 SELinux policy compiler command-not-found 0.2.46ubuntu6 Suggest installation of packages in interactive bash sessions command-not-found-data 0.2.46ubuntu6 Set of data files for command-not-found. -

Update on Standards Ties Have Been Centered on Maintenance
At the end of last year, the USENIX Board of Directors asked me to prepare a report NICK STOUGHTON for ;login: on the activities in the world of formal standards in 2004. And a very busy year it’s been. For two years or so, since the Austin Group revised the POSIX standard completely, the majority of activi- update on standards ties have been centered on maintenance. Maintenance is a good thing; the fact that since 2001 we have Nick is the USENIX Standards Liaison and represents the Association in the POSIX, ISO C, and LSB working addressed hundreds of problem reports against the groups. He is the ISO organizational representative 3700+ pages of POSIX, as well as publishing two to the Austin Group, a member of INCITS commit- Technical Corrigenda, shows that the standard is tees J11 and CT22, and the Specification Authority subgroup leader for the LSB. being used. People are reading it carefully and asking hard questions of the form “Did you really mean to [email protected] say this?” Sometimes the answer is “yes,” sometimes it’s “no,” but every question is carefully reviewed , and if necessary new text is written to clarify the meaning. Having the standard freely available online (see http://www.unix.org/single_unix_specification/) helps enormously in spreading the use of POSIX: no system implementer or application developer can excuse nonconformance with “I couldn’t afford the stan- dard.” Additionally, the relative ease of licensing the text means that open source implementations have started to adopt the actual standard text for their man pages; both FreeBSD and the Linux Man Page project have licensed it for this purpose. -

API Standards Briefing: ISO/JTC1 Linux Study Group Meeting
APIAPI StandardsStandards Briefing:Briefing: ISO/JTC1ISO/JTC1 LinuxLinux StudyStudy GroupGroup MeetingMeeting Andrew Josey The Open Group Email: [email protected] UNIX is a registered trademark of The Open Group Linux is a registered trademark of Linus Torvalds 1 This talk covers ! Why Standards Matter… ! The Standards " A review of the latest API standards " How Linux shapes up to them ! Their use… " POSIX " The Single UNIX Specification " The Linux Standard Base (LSB) 2 “Despite their well earned reputation as a source of confusion, standards are one of the enabling factors behind the success of Linux. If it weren't for the adoption of the right standards by Linus Torvalds and other developers, Linux would likely be a small footnote in the history of operating systems.” - Dan Quinlan, Free Standards Group Chairman 3 The Free Market ! The key to the growth of the Linux market is the free-market demands placed upon suppliers by customers " Open Standards ! These systems ultimately compete on quality and added value features to retain customers ! Dissatisfied customers can move on to another supplier 4 Background: Source Standards versus Binary Standards Source Specific Binary API Stds Linux Stds Behavior enables enables Shrink Application Wrapped Source Applications Portability 5 What is an API? ! Application Program Interface ! A written contract between system developers and application developers ! It is not a piece of code, it is a piece of paper defining what the two sets of developers are guaranteed to receive and are in turn