Training a Neural Network Using Synthetically Generated Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cloud Fonts in Microsoft Office
APRIL 2019 Guide to Cloud Fonts in Microsoft® Office 365® Cloud fonts are available to Office 365 subscribers on all platforms and devices. Documents that use cloud fonts will render correctly in Office 2019. Embed cloud fonts for use with older versions of Office. Reference article from Microsoft: Cloud fonts in Office DESIGN TO PRESENT Terberg Design, LLC Index MICROSOFT OFFICE CLOUD FONTS A B C D E Legend: Good choice for theme body fonts F G H I J Okay choice for theme body fonts Includes serif typefaces, K L M N O non-lining figures, and those missing italic and/or bold styles P R S T U Present with most older versions of Office, embedding not required V W Symbol fonts Language-specific fonts MICROSOFT OFFICE CLOUD FONTS Abadi NEW ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Abadi Extra Light ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Note: No italic or bold styles provided. Agency FB MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Agency FB Bold ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Note: No italic style provided Algerian MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ 01234567890 Note: Uppercase only. No other styles provided. Arial MICROSOFT OFFICE CLOUD FONTS ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Italic ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Bold ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz 01234567890 Arial Bold Italic ABCDEFGHIJKLMNOPQRSTUVWXYZ -

Suitcase Fusion 8 Getting Started
Copyright © 2014–2018 Celartem, Inc., doing business as Extensis. This document and the software described in it are copyrighted with all rights reserved. This document or the software described may not be copied, in whole or part, without the written consent of Extensis, except in the normal use of the software, or to make a backup copy of the software. This exception does not allow copies to be made for others. Licensed under U.S. patents issued and pending. Celartem, Extensis, LizardTech, MrSID, NetPublish, Portfolio, Portfolio Flow, Portfolio NetPublish, Portfolio Server, Suitcase Fusion, Type Server, TurboSync, TeamSync, and Universal Type Server are registered trademarks of Celartem, Inc. The Celartem logo, Extensis logos, LizardTech logos, Extensis Portfolio, Font Sense, Font Vault, FontLink, QuickComp, QuickFind, QuickMatch, QuickType, Suitcase, Suitcase Attaché, Universal Type, Universal Type Client, and Universal Type Core are trademarks of Celartem, Inc. Adobe, Acrobat, After Effects, Creative Cloud, Creative Suite, Illustrator, InCopy, InDesign, Photoshop, PostScript, Typekit and XMP are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States and/or other countries. Apache Tika, Apache Tomcat and Tomcat are trademarks of the Apache Software Foundation. Apple, Bonjour, the Bonjour logo, Finder, iBooks, iPhone, Mac, the Mac logo, Mac OS, OS X, Safari, and TrueType are trademarks of Apple Inc., registered in the U.S. and other countries. macOS is a trademark of Apple Inc. App Store is a service mark of Apple Inc. IOS is a trademark or registered trademark of Cisco in the U.S. and other countries and is used under license. Elasticsearch is a trademark of Elasticsearch BV, registered in the U.S. -

SHOPC Minutes
· IOLu\f\ Clex-~ Kc.J 1 \) 1 Approved May 6, 2020 SJlo Izozo 2 I).' LI J'.W1 3 s 4 ~ ~ 5 THE SOUTHBOROUGH HOUSING OPPORTUNITY PARTNERSHIP COMMITTEE 6 (SHOPC) 7 MEETING MINUTES 8 Wednesday, April 29, 2020 8:30 AM 9 VIRTUAL MEETING/REMO E PARTICIPATION 10 11 Members present: Doriann Jasinski, Lisa Braccio, John Wood, Alex Frisch, Tom Bhisitkul, Tom Marcoulier 12 and Jesse Stein. Also present: Karina Quinn, Town Planner, Sarah Hoecker, Business Administrator I and 13 Kathleen Battles, Recording Secretary. Sarah Hoecker managed virtual connection through ZOOM 14 application. 15 16 CALL TO ORDER: The meeting was called to order at 8:44 AM. 17 18 Ms. Jasinski read the following statement: 19 Pursuant to Governor Baker's March 12, 2020 Order Suspending Certain Provisions of the Open Meeting 20 Law, G.L. c. 30A, &18, and the Governor's March 15, 2020 Order imposing strict limitations on the 21 number of people that may gather in one place, this meeting of the Southborough Housing Opportunity 22 Partnership Committee (SHOPC) is being conducted via remote participation to the greatest extent 23 possible. Specific information and the general guidelines for the remote participation by members of 24 the public and/ or parties with a right and/or requirement to attend this meeting can be found on the 25 Town of Southborough's website, at https://www.southboroughtown.com/. 26 For this meeting, members of the pubic who wish to listen to the meeting or participate in the public 27 hearing may do so in the following manner: 28 https://www.southboroughtown.com/remotemeetings 29 30 No in-person attendance of members of the public will be permitted, but every effort will be made to 31 ensure that the public can adequately access the proceedings in real time, via technological means. -

Table of Contents
CentralNET Business User Guide Table of Contents Federal Reserve Holiday Schedules.............................................................................. 3 About CentralNET Business ......................................................................................... 4 First Time Sign-on to CentralNET Business ................................................................. 4 Navigation ..................................................................................................................... 5 Home ............................................................................................................................. 5 Balances ........................................................................................................................ 5 Balance Inquiry Terms and Features ........................................................................ 5 Account & Transaction Inquiries .................................................................................. 6 Performing an Inquiry from the Home Screen ......................................................... 6 Initiating Transfers & Loan Payments .......................................................................... 7 Transfer Verification ................................................................................................. 8 Reporting....................................................................................................................... 8 Setup (User Setup) ....................................................................................................... -

Suitcase Fusion 9 Getting Started Guide
Legal notices Copyright © 2014–2019 Celartem, Inc., doing business as Extensis. This document and the software described in it are copyrighted with all rights reserved. This document or the software described may not be copied, in whole or part, without the written consent of Extensis, except in the normal use of the software, or to make a backup copy of the software. This exception does not allow copies to be made for others. Licensed under U.S. patents issued and pending. Celartem, Extensis, MrSID, NetPublish, Portfolio Flow, Portfolio NetPublish, Portfolio Server, Suitcase Fusion, Type Server, TurboSync, TeamSync, and Universal Type Server are registered trademarks of Celartem, Inc. The Celartem logo, Extensis logos, Extensis Portfolio, Font Sense, Font Vault, FontLink, QuickFind, QuickMatch, QuickType, Suitcase, Suitcase Attaché, Universal Type, Universal Type Client, and Universal Type Core are trademarks of Celartem, Inc. Adobe, Acrobat, After Effects, Creative Cloud, Creative Suite, Illustrator, InCopy, InDesign, Photoshop, PostScript, and XMP are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States and/or other countries. Apache Tika, Apache Tomcat and Tomcat are trademarks of the Apache Software Foundation. Apple, Bonjour, the Bonjour logo, Finder, iPhone, Mac, the Mac logo, Mac OS, OS X, Safari, and TrueType are trademarks of Apple Inc., registered in the U.S. and other countries. macOS is a trademark of Apple Inc. App Store is a service mark of Apple Inc. IOS is a trademark or registered trademark of Cisco in the U.S. and other countries and is used under license. Elasticsearch is a trademark of Elasticsearch BV, registered in the U.S. -

Ultimate++ Forum It Higher Priority Now
Subject: It's suspected to be an issue with Font. Posted by Lance on Fri, 18 Mar 2011 22:50:28 GMT View Forum Message <> Reply to Message The programs I used to compare are UWord from the UPP, and MS Word. The platform is Windows 7. The text I used to test is: The problem with U++ drawed text is that some characters are notably larger than others and some have incorrect horizontal displacement. Please see attached picture for a visual effect. I also encountered issue where chinese characters are displayed correctly displayed on Windows but are blank on Ubuntu. And when I copies the same text that was displayed as blank to, say gedit, the text displayed correctly as in Windows. That part I will attach picture in future. File Attachments 1) font problem.png, downloaded 650 times Subject: Re: It's suspected to be an issue with Font. Posted by mirek on Sun, 10 Apr 2011 12:42:52 GMT View Forum Message <> Reply to Message Lance wrote on Fri, 18 March 2011 18:50The programs I used to compare are UWord from the UPP, and MS Word. The platform is Windows 7. The text I used to test is: The problem with U++ drawed text is that some characters are notably larger than others and some have incorrect horizontal displacement. It works fine on my Windows 7. However, I believe that the problem is caused by font substitution mechanism and perhaps on your system, you have some font that takes precendence for some glyphs, but does not contain other characters. -
![CSS [10] Desenvolvimento E Design De Websites](https://docslib.b-cdn.net/cover/2447/css-10-desenvolvimento-e-design-de-websites-1552447.webp)
CSS [10] Desenvolvimento E Design De Websites
CSS [10] Desenvolvimento e Design de Websites Prof.: Ari Oliveira CSS [10] │ Folhas de Estilo em Cascata – CSS │ Localização dos estilos │ Seletores 2 CSS [10] │ Faça uma página de “trabalhe conosco”. │ Esta página deverá conter um formulário para que o candidato se cadastre │ Use todos os tipos de campos de formulário 3 CSS [10] │ CSS significa Cascading Style Sheets (Folha de Estilo em Cascata) │ Criado e mantido por World Wide Web Consortium (W3C) - ou seja, é um padrão │ Atualmente na versão 3 │ Definem como mostrar os elementos HTML │ Economizam muito nosso trabalho! 4 CSS [10] │ Todos os navegadores suportam CSS │ Toda a formatação pode ser removida do documento HTML e armazenado em um arquivo separado (arquivo .css) │ Folhas de Estilo permitem que se mude a aparência de todas as páginas Web editando apenas um único arquivo │ Torna o documento HTML mais limpo, enxuto e de fácil manutenção │ É recomendado usar doctype para especificar que se está trabalhando com html5 e css3 5 CSS [10] │ Folha de Estilo externa (.css) ‖ Ideal quando utilizado em vários documentos HTML ‖ Basta criar um novo arquivo .css, e liga-lo na página, desta forma: <head> <link rel="stylesheet" href="meuestilo.css"> </head> Faça! 6 CSS [10] │ É possível inserir um CSS diretamente dentro do HTML. Esta forma não é recomendada, pois cada página terá que ter seu estilo. <head> <style> coloque aqui seu CSS </style> </head> 7 CSS [10] │ É possível também inserir um CSS diretamente dentro de um só elemento. Esta forma só é usada para pequenos reparos, pois a manutenção será mais difícil. -

Indiana Department of Transportation
INDIANA DEPARTMENT OF TRANSPORTATION CONTRACT INFORMATION BOOK (CIB) PART I CONTRACT NO. LETTING DATE: Certified By: Date: Covering Items in Table of Contents, PART I For Release for Bidding Purposes CONTRACT INFORMATION TABLE OF CONTENTS CONTRACT NO. This book shall be examined to determine that each page set out in the Contract Information Table of Contents, and the Special Provisions Table of Contents is attached, legible, and current. PART I PAGES PROPOSAL PAGE 1 SCHEDULE OF PAY ITEMS 1 – RECURRING PLAN DETAILS 1 - TRAFFIC CONTROL DEVICE REPORT 1 SPECIAL PROVISIONS 1 – PART II CONTACT FOR CONTRACTORS DISTRICT CONSTRUCTION DIRECTOR: *QUESTION FORM Contractors shall submit contract specific questions by completing the Question Form accessed from http://entapps.indot.in.gov/cqa/ The Department will attempt to have an answer on-line within two business days. Retrieve the Question and Answer Form for a specific contract by going on–line in the same manner you retrieve Contract Information Books and Plans. http://erms.indot.in.gov/viewdocs/ will display the interface used for selection of contract letting documents. For the document category, select “Q and A Form”. CONTACTS FOR DISTRICT PERSONNEL ONLY PHONE: PHONE: Indiana Department of Transportation Proposal Date of Letting: April 05, 2017 Time of Letting: 10:00 A.M. Location of Letting: N725 CONF RM, GOVERNMENT CENTER NORTH 100 N. SENATE AVENUE INDIANAPOLIS, INDIANA 46204 State Certified Contract Number: R -36342-A Project Number(s): 1172473 Districts : Greenfield Counties : HOWARD Description: NEW PEDESTRIAN BRIDGE CONSTRUCTION Completion Date or Time ID Description Time Type Liquidated Damages Rate Number of Units 00 COMPLETION DATE 11/9/2018 DT $1,500.00 per Days 01 INTERMEDIATE 11/21/2017 DT $1,500.00 per Days COMPLETION DATE (*) - Indicates Cost Plus Time Site. -

Sketch Block Bold Accord Heavy SF Bold Accord SF Bold Aclonica Adamsky SF AFL Font Pespaye Nonmetric Aharoni Vet Airmole Shaded
Sketch Block Bold Accord Heavy SF Bold Accord SF Bold Aclonica Adamsky SF AFL Font pespaye nonmetric Aharoni Vet Airmole Shaded Airmole Stripe Airstream Alegreya Alegreya Black Alegreya Black Italic Alegreya Bold Alegreya Bold Italic Alegreya Italic Alegreya Sans Alegreya Sans Black Alegreya Sans Black Italic Alegreya Sans Bold Alegreya Sans Bold Italic Alegreya Sans ExtraBold Alegreya Sans ExtraBold Italic Alegreya Sans Italic Alegreya Sans Light Alegreya Sans Light Italic Alegreya Sans Medium Alegreya Sans Medium Italic Alegreya Sans SC Alegreya Sans SC Black Alegreya Sans SC Black Italic Alegreya Sans SC Bold Alegreya Sans SC Bold Italic Alegreya Sans SC ExtraBold Alegreya Sans SC ExtraBold Italic Alegreya Sans SC Italic Alegreya Sans SC Light Alegreya Sans SC Light Italic Alegreya Sans SC Medium Alegreya Sans SC Medium Italic Alegreya Sans SC Thin Alegreya Sans SC Thin Italic Alegreya Sans Thin Alegreya Sans Thin Italic AltamonteNF AMC_SketchyOutlines AMC_SketchySolid Ancestory SF Andika New Basic Andika New Basic Bold Andika New Basic Bold Italic Andika New Basic Italic Angsana New Angsana New Angsana New Cursief Angsana New Vet Angsana New Vet Cursief Annie BTN Another Typewriter Aparajita Aparajita Bold Aparajita Bold Italic Aparajita Italic Appendix Normal Apple Boy BTN Arabic Typesetting Arabolical Archive Arial Arial Black Bold Arial Black Standaard Arial Cursief Arial Narrow Arial Narrow Vet Arial Unicode MS Arial Vet Arial Vet Cursief Aristocrat SF Averia-Bold Averia-BoldItalic Averia-Gruesa Averia-Italic Averia-Light Averia-LightItalic -
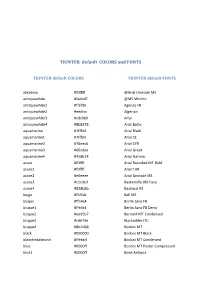
TKINTER Default COLORS and FONTS
TKINTER default COLORS and FONTS TKINTER default COLORS TKINTER default FONTS aliceblue #f0f8ff @Arial Unicode MS antiquewhite #faebd7 @MS Mincho antiquewhite1 #ffefdb Agency FB antiquewhite2 #eedfcc Algerian antiquewhite3 #cdc0b0 Arial antiquewhite4 #8b8378 Arial Baltic aquamarine #7fffd4 Arial Black aquamarine1 #7fffd4 Arial CE aquamarine2 #76eec6 Arial CYR aquamarine3 #66cdaa Arial Greek aquamarine4 #458b74 Arial Narrow azure #f0ffff Arial Rounded MT Bold azure1 #f0ffff Arial TUR azure2 #e0eeee Arial Unicode MS azure3 #c1cdcd Baskerville Old Face azure4 #838b8b Bauhaus 93 beige #f5f5dc Bell MT bisque #ffe4c4 Berlin Sans FB bisque1 #ffe4c4 Berlin Sans FB Demi bisque2 #eed5b7 Bernard MT Condensed bisque3 #cdb79e Blackadder ITC bisque4 #8b7d6b Bodoni MT black #000000 Bodoni MT Black blanchedalmond #ffebcd Bodoni MT Condensed blue #0000ff Bodoni MT Poster Compressed blue1 #0000ff Book Antiqua blue2 #0000ee Bookman Old Style blue3 #0000cd Bookshelf Symbol 7 blue4 #00008b Bradley Hand ITC blueviolet #8a2be2 Britannic Bold brown #a52a2a Broadway brown1 #ff4040 Brush Script MT brown2 #ee3b3b Calibri brown3 #cd3333 Californian FB brown4 #8b2323 Calisto MT burlywood #deb887 Cambria burlywood1 #ffd39b Cambria Math burlywood2 #eec591 Candara burlywood3 #cdaa7d Castellar burlywood4 #8b7355 Centaur cadetblue #5f9ea0 Century cadetblue1 #98f5ff Century Gothic cadetblue2 #8ee5ee Century Schoolbook cadetblue3 #7ac5cd Chiller cadetblue4 #53868b Colonna MT chartreuse #7fff00 Comic Sans MS chartreuse1 #7fff00 Consolas chartreuse2 #76ee00 Constantia chartreuse3 -

Text Steganography Based on Font Type in MS-Word Documents
Journal of Computer Science 9 (7): 898-904, 2013 ISSN: 1549-3636 © 2013 Science Publications doi:10.3844/jcssp.2013.898.904 Published Online 9 (7) 2013 (http://www.thescipub.com/jcs.toc) Text Steganography Based on Font Type in MS-Word Documents 1Wesam Bhaya, 2Abdul Monem Rahma and 3Dhamyaa AL-Nasrawi 1Department of Information Networks, Information Technology Collage, Babylon University, Babil, Iraq 2Department of Computer Science, University of Technology, Baghdad, Iraq 3Department of Computer Science, Science Collage, Kerbala University, Kerbala, Iraq Received 2013-01-03, Revised 2013-04-22; Accepted 2013-06-22 ABSTRACT With the rapid development of Internet, safe covert communications in the network environment become an essential research direction. Steganography is a significant means that secret information is embedded into cover data imperceptibly for transmission, so that information cannot be easily aware by others. Text Steganography is low in redundancy and related to natural language rules these lead to limit manipulation of text, so they are both great challenges to conceal message in text properly and to detect such concealment. This study proposes a novel text steganography method which takes into account the Font Types. This new method depends on the Similarity of English Font Types; we called it (SEFT) technique. It works by replace font by more similar fonts. The secret message was encoded and embedded as similar fonts in capital Letters of cover document. Proposed text steganography method can works in different cover documents of different font types. The size of cover and stego document was increased about 0.766% from original size. The capacity of this method is very high and the secret message was inconspicuous to an adversary. -
Fixedsys Regular Font Free Download Fixedsys Excelsior 3.01 Font
fixedsys regular font free download Fixedsys Excelsior 3.01 Font. Cufonfonts.com's fonts are uploaded by our members. The license information stated by the members is usually correct but we cannot guarantee it. We give great importance to copyright and have developed some techniques to make sure that the previously mentioned issue doesn't occur, also the system automatically displays the copyright information of the font here. If you believe that this font is in violation of copyright and isn't legal, please let us know in order for the font to be removed or revised. The legal authority of the font can make a request using the "Report a Violation" button above. You can also check the legal and commercial status of this font; It is the users' own legal responsibility to download and use this font. Your download will begin in a moment. How About 1.5 Million Design Resources? Don't forget to check out our partners over at Envato Elements where you can explore over 1.5 million items with unlimited downloads: Mirc Font. Use the text generator tool below to preview Mirc font, and create appealing text graphics with different colors and hundreds of text effects. Font Tags. Search. :: You Might Like. About. Font Meme is a fonts & typography resource. The "Fonts in Use" section features posts about fonts used in logos, films, TV shows, video games, books and more; The "Text Generator" section features simple tools that let you create graphics with fonts of different styles as well as various text effects; The "Font Collection" section is the place where you can browse, filter, custom preview and download free fonts.