Manovich, Lev. "Understanding Metamedia." Software Takes Command
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Gestaltungspotenzial Von Digitalen Compositingsystemen
Gestaltungspotenzial von digitalen Compositingsystemen Thorsten Wolf Diplomarbeit Wintersemester 03/04 1. Betreuer Herr Prof. Martin Aichele 2. Betreuer Herr Prof. Christian Fries Fachhochschule Furtwangen Fachbereich Digitale Medien „Das vielleicht größte Missverständnis über die Fotografie kommt in den Worten ‚die Kamera lügt nicht‛ zum Ausdruck. Genau das Gegenteil ist richtig. Die weitaus meisten Fotos sind ‚Lügen‛ in dem Sinne, daß sie nicht vollkommen der Wirklichkeit entsprechen: sie sind zweidimensionale Abbildungen dreidimensionaler Objekte, Schwarzweißbilder farbiger Wirklichkeit, ‚starre‛ Fotos bewegter Objekte. … “ [Kan78] S. 54f Für Mama und Papa, of course. Eidesstattliche Erklärung i Eidesstattliche Erklärung Ich, Thorsten Wolf, erkläre hiermit an Eides statt, dass ich die vorliegende Diplomarbeit selbstständig und ohne unzulässige fremde Hilfe angefertigt habe. Alle verwendeten Quellen und Hilfsmittel sind angegeben. Furtwangen, 24. Februar 2004 Thorsten Wolf Vorwort iii Vorwort In meiner Diplomarbeit „Gestaltungspotenzial von digitalen Compositingsystemen“ untersuche ich den vielseitigen visuellen Bereich der Medieninformatik. In der vorliegenden Arbeit sollen die gestalterischen Potenziale von digitalem Compositing ausgelotet werden. Hierzu untersuche ich theoretisch wie praktisch die digitalen Bildverarbeitungsverfahren und –möglichkeiten für analoge und digitale Bildquellen. Mein besonderes Augenmerk liegt hierbei auf dem Bereich der Bewegtbildgestaltung durch digitale Compositingsysteme. Diese Arbeit entstand in enger Zusammenarbeit mit der Firma on line Video 46 AG, Zürich. Besonderen Dank möchte ich Herrn Richard Rüegg, General Manager, für seine Unterstützung und allen Mitarbeitern, die mir in technischen Fragestellung zur Seite standen, aussprechen. Des weiteren bedanke ich mich bei Patrischa Freuler, Marian Kaiser, Marianne Klein, Jörg Volkmar und Tanja Wolf für ihre Unterstützung während der Diplomarbeitszeit. Für die gute Betreuung möchte ich meinen beiden Tutoren, Herrn Prof. Martin Aichele (Erstbetreuer) und Prof. -

VFX Prime 2018-19 Course Code: OV-3103 Course Category : Career VFX INDUSTRY
Product Note: VFX Prime 2018-19 Course Code: OV-3103 Course Category : Career VFX INDUSTRY Indian VFX Industry grew from INR 2,320 Crore in 2016 to reach INR 3,130 Crore in 2017.The Industry is expected to grow nearly double to INR 6,350 Crore by 2020. Where reality meets and blends with the imaginary, it is there that VFX begins. The demand for VFX has been rising relentlessly with the production of movies and television shows set in fantasy worlds with imaginary creatures like dragons, magical realms, extra-terrestrial planets and galaxies, and more. VFX can transform the ordinary into something extraordinary. Have you ever been fascinated by films like Transformers, Dead pool, Captain America, Spiderman, etc.? Then you must know that a number of Visual Effects are used in these films. Now the VFX industry is on the verge of changing with the introduction of new tools, new concepts, and ideas. Source:* FICCI-EY Media & Entertainment Report 2018 INDUSTRY TRENDS VFX For Television Episodic Series SONY Television's Show PORUS showcases state-of-the-art Visual Effects to be seen on Television. Based on the tale of King Porus, who fought against Alexander, The Great to stop him from invading India, the show is said to have been made on a budget of Rs500 crore. VFX-based Content for Digital Platforms like Amazon & Netflix Popular web series like House of Cards, Game of Thrones, Suits, etc. on streaming platforms such as Netflix, Amazon Prime, Hot star and many more are unlike any conventional television series. They are edgy and fresh, with high production values, State-of-the-art Visual Effects, which are only matched with films, and are now a rage all over the world. -

Avid DS - Your Future Is Now
DSWiki DSWiki Table Of Contents 1998 DS SALES BROCHURE ............................................. 4 2005 DS Wish List ..................................................... 8 2007 Unfiltered DS Wish List ............................................. 13 2007 Wish Lists ....................................................... 22 2007DSWishListFinalistsRound2 ........................................... 28 2010 Wish List ........................................................ 30 A ................................................................. 33 About .............................................................. 53 AchieveMoreWithThe3DDVE ............................................. 54 AmazonStore ......................................................... 55 antler .............................................................. 56 Arri Alexa ........................................................... 58 Avid DS - Your Future Is Now ............................................. 59 Avid DS for Colorists ................................................... 60 B ................................................................. 62 BetweenBlue&Green ................................................... 66 Blu-ray Copy ......................................................... 67 C ................................................................. 68 ColorItCorrected ...................................................... 79 Commercial Specifications ............................................... 80 Custom MC Color Surface Layouts ........................................ -

Curriculium Vitae Biography Main Software
CURRICULIUM VITAE BIOGRAPHY MAIN SOFTWARE ...................................................................................................................................................................................... ...................................................................................................................................................................................... I’m an energetic and diligent Compositor with an eye for pixel Nuke Studio Nuke X perfection. During my last years, I have been working with high-end visual effects houses in London combining the experience of working in films, tv-shows and commercials. SECONDARY SOFTWARE Working on these subfields gave me the ability to solve different types ...................................................................................................................................................................................... of shots proposing distinct solutions. I reshuffled my approaches and merged all the knowledge improving my workflow and technical PF Track After Effects Photoshop proficiency in digital compositing. Silhouette FX Mocha Pro DaVinci Resolve As an information-seeker, I am always eager to push my boundaries facing each project as a new challenge, opportunity to learn and self-development. PROJECT MANAGEMENT SOFTWARE Believing that quality is of utmost importance, my major goal is to ..................................................................................................................................................................................... -

NANCE PATERNOSTER Digital Artist - Compositor - Instructor 503 • 621 • 1073
NANCE PATERNOSTER Digital Artist - Compositor - Instructor 503 • 621 • 1073 OBJECTIVE: Working in a Creative Capacity for Apple Computer or Adobe Products Digital Compositing, Motion Graphics & Special Effects Animation Creating Digital Art & Animated Sequences Teaching in an Animation Department at an Art School EDUCATION: MA 1993 – San Francisco State University Masters in Computer & Film Animation/Video Disk Technology BFA 1984 - Syracuse University: Syracuse, New York Art Media Program: Computer Graphics Major/College of Visual & Performing Arts (Film, Video, Photo. & Computer Graphics/Programming - Fine Art Emphasis) Additional Computer Graphics Training: Art Institute of Portland - Maya Courses Academy of Art College 1994; Pratt Institute, N.Y., NY 1985; The School of Visual Art, NY 1984 N.Y. Institute of Technology 1984-1985; Pratt Brooklyn, 1985 Center for Electronics Arts, S.F., CA 1988-1989 COMPUTER GRAPHIC EQUIPMENT Platforms - Mac/SGI/PC Software - Flame, After Effects Photoshop, Illustrator, Painter, Quark Some - Maya, Max, Lightwave, Soft Image Xaos Tools - Pandemonium, NTITLE Some - Avid, Final Cut, Premiere Amazon Paint 2D/3D, PIRANHA Unix, Dos, + Some C++, Pascal, Fortran, Javascript , HTML Additional Photography, Stereo Photography. Analog and Digital Video editing, Film editing. RELATED WORK: Art Institute of Portland - Adjunct Faculty VEMG/DFV Depts. - Present Pacific Northwest College of Art - Adjunct Faculty - Present Art Institutes Online - Adjunct Faculty - Present Art Institutes Online- Full Time Faculty - Animation Department - 2006-2007 Art Institute of Portland - Full Time Faculty - Animation Department Teaching Compositing, Motion Graphics, Special FX Animation, Advanced Image Manipulation, Digital Paint, Independent Study for Senior Animation Students, & Digital Portfolio. 2000 - 2005 Art Institutes Online - Adjunct Faculty - Game Art & Design Department Teaching Digital Ink & Paint Online, 2D Animation, Image Manipulation. -

Toon Boom Harmony 12.1 Essentials
TOON BOOM HARMONY 12.1 - Essentials Edition - Compositing and Effects Guide Legal Notices Toon Boom Animation Inc. 4200 Saint-Laurent, Suite 1020 Montreal, Quebec, Canada H2W 2R2 Tel: +1 514 278 8666 Fax: +1 514 278 2666 toonboom.com Disclaimer The content of this guide is covered by a specific limited warranty and exclusions and limit of liability under the applicable License Agreement as supplemented by the special terms and conditions for Adobe®Flash® File Format (SWF). For details, refer to the License Agreement and to those special terms and conditions. The content of this guide is the property of Toon Boom Animation Inc. and is copyrighted. Any reproduction in whole or in part is strictly prohibited. Trademarks Harmony is a trademark of Toon Boom Animation Inc. Publication Date 2015-08-07 Copyright © 2015 Toon Boom Animation Inc. All rights reserved. 2 Harmony 12.1 Essentials - Compositing and Effects Guide Contents Toon Boom Harmony 12.1- Essentials Edition -Compositing and Effects Guide 1 Contents 3 Chapter 1: Compositing - An Introduction 7 Chapter 2: Import 9 Importing Bitmap Images 9 Importing a Bitmap Image Without Vectorization 10 Bitmap Image Quality 11 Importing and Vectorizing Bitmap Images 11 Importing PSD Files as Separate Layers 14 Exporting a Layout 20 Scanning Images 24 Importing AI and PDF Files 32 Importing SWF Files 34 Redistributing Elements 36 Importing QuickTime Movies 37 Custom Vectorization Parameters 38 Options Tab 39 Help Tab 41 File IO Options 41 Registration Options 42 Filtering Options 42 Options for bitmap -
Third Semester
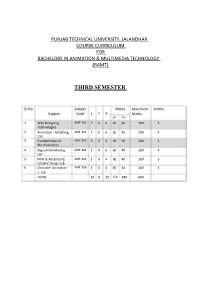
PUNJAB TECHNICAL UNIVERSITY, JALANDHAR COURSE CURRICULUM FOR BACHELORS IN ANIMATION & MULTIMEDIA TECHNOLOGY (BAMT) THIRD SEMESTER Sr.No Subject Marks Maximum credits Subject Code L T P Marks Int. Ext. 1 Web Designing AMT-301 3 0 0 40 60 100 3 Technologies 2 Animation - Modeling AMT-302 1 0 6 60 40 100 4 Lab 3 Fundamentals of AMT-303 3 0 0 40 60 100 3 Pre-Production 4 Digital Film Making AMT-304 1 0 6 60 40 100 4 Lab 5 Print & Advertising AMT-305 1 0 4 60 40 100 3 Graphic Design Lab 6 Character Animation - AMT-306 1 0 4 60 40 100 3 1 Lab TOTAL 10 0 20 320 280 600 SEMESTER - III Internal: 40 Marks External: 60 Marks AMT- 301 Web Designing Technologies L-3 T-0 P-0 OBJECTIVE - The main objective of the subject is to impart the basic understanding of the methods and techniques of developing a web site. 1) Introduction to the Internet (5%) Modes of connecting to internet, search optimization on internet, applications of internet, introduction to World Wide Web (WWW). 2) Introduction to HTML (5%) HTML tags, HTML Editor. 3) Tags, Attributes, Lists and Tables (15%) Structure Tags (HTML,HEAD,TITLE,BODY),Paired and unpaired tags, Ordered list, unordered list, formatting list, tables in HTML, formatting table, cell spacing, cell padding 4) Links and Images (15%) Making hyper links- anchor tag, images as link, Adding Images, Aligning the image Using Images as a link, Using Background images. 5) Cascading Style Sheets (5%) Style sheet design, using internal and external style sheets 6) Creating a Basic Web Page (20%) Creating web pages using basic HTML Tags. -

Op E N So U R C E Yea R B O O K 2 0
OPEN SOURCE YEARBOOK 2016 ..... ........ .... ... .. .... .. .. ... .. OPENSOURCE.COM Opensource.com publishes stories about creating, adopting, and sharing open source solutions. Visit Opensource.com to learn more about how the open source way is improving technologies, education, business, government, health, law, entertainment, humanitarian efforts, and more. Submit a story idea: https://opensource.com/story Email us: [email protected] Chat with us in Freenode IRC: #opensource.com . OPEN SOURCE YEARBOOK 2016 . OPENSOURCE.COM 3 ...... ........ .. .. .. ... .... AUTOGRAPHS . ... .. .... .. .. ... .. ........ ...... ........ .. .. .. ... .... AUTOGRAPHS . ... .. .... .. .. ... .. ........ OPENSOURCE.COM...... ........ .. .. .. ... .... ........ WRITE FOR US ..... .. .. .. ... .... 7 big reasons to contribute to Opensource.com: Career benefits: “I probably would not have gotten my most recent job if it had not been for my articles on 1 Opensource.com.” Raise awareness: “The platform and publicity that is available through Opensource.com is extremely 2 valuable.” Grow your network: “I met a lot of interesting people after that, boosted my blog stats immediately, and 3 even got some business offers!” Contribute back to open source communities: “Writing for Opensource.com has allowed me to give 4 back to a community of users and developers from whom I have truly benefited for many years.” Receive free, professional editing services: “The team helps me, through feedback, on improving my 5 writing skills.” We’re loveable: “I love the Opensource.com team. I have known some of them for years and they are 6 good people.” 7 Writing for us is easy: “I couldn't have been more pleased with my writing experience.” Email us to learn more or to share your feedback about writing for us: https://opensource.com/story Visit our Participate page to more about joining in the Opensource.com community: https://opensource.com/participate Find our editorial team, moderators, authors, and readers on Freenode IRC at #opensource.com: https://opensource.com/irc . -

Rotoscoping Software
JOB ROLE – ROTO ARTIST Sector – Media and Entertainment Sector (Qualification Pack Code: MES/Q3504) ( Class-XI ) PSS Central Institute of Vocational Education Shyamla Hills, Bhopal – 462 013 , Madhya Pradesh, India _________________________________________________________ www.psscive.ac.in 1 UNIT 2: CREATIVE AND TECHNICAL REQUIREMENT Chapter 7: Rotoscoping Software 2 Content Title Slide No. Chapter Objectives 04 Introduction 05 Rotoscoping Software 06-07 Adobe After Effects 08-13 System requirement for Adobe after Effects 14 Advantage of Adobe After Effects in Rotoscoping 15 Silhouette 2020 16- 19 System requirement of Silhouette 2020 20 Nuke 21-24 Minimum System Requirement of Nuke 25 Summary 26 3 Chapter Objectives The students will be able to: ❑ Define Rotoscoping Software, ❑ Explain Adobe After Effects software, its key features, ❑ Prepare System requirement for Adobe after Effects CC2019, ❑ Describe advantage of Adobe After Effects in Rotoscoping, ❑ Explain SilhouetteFX software, its Key features with rotoscoping feature and advantages, ❑ Prepare System requirement of Silhouette 2020, ❑ Explain Nuke, its Key feature and Advantage, ❑ Prepare Minimum System Requirement of Nuke. 4 Introduction Shifting from traditional to digital rotoscopy started in 1990s, Bob sabiston, a computer scientist made a program named ‘Rotoshop’. The technique of rotoshop is adopted from sketching, where artist traced first image and then copied it for next movement. It saves the time of sketching the second image. Another program ‘Matador’ was used for rotoscopy on hundred of feature film between 1990s to early 2000 including Jurassic park, forest gump and hulk. Matador was a paint application. Its main characteristics were paint, mask creation, animation, image stabilization and tracking. In comparison to traditional roto artist, a digital roto artist can do the eight time more work in 1/4th of time. -

Volume 160 May, 2020
Volume 160 May, 2020 Short Topix: Zoombombing Is A Crime, Not A Prank GIMP Tutorial: Photo Editing, Part 3 PCLinuxOS Magazine Friends & Family - jzakiya Champions Of Regnum On PCLinuxOS EBCDIC Handling Library, Part 2 PCLinuxOS Recipe Corner: Lemon Pepper Chicken ms_meme's Nook: The Linux Bounce Wallpaper Roundup, Revisited Finally! ShotCut Running On PCLinuxOS And more inside! PCLinuxOS Magazine Page 1 In This Issue... 3 From The Chief Editor's Desk... 5 Staying "Safe" While You Stream: DBD's Tips On Living DRM-Free During Quarantine The PCLinuxOS name, logo and colors are the trademark of 6 Screenshot Showcase Texstar. 7 PCLinuxOS Recipe Corner: Lemon Pepper Chicken The PCLinuxOS Magazine is a monthly online publication containing PCLinuxOS-related materials. It is published 8 Wallpaper Roundup, Revisited primarily for members of the PCLinuxOS community. The magazine staff is comprised of volunteers from the 13 Screenshot Showcase PCLinuxOS community. 14 ms_meme's Nook: I Want It That Way Visit us online at http://www.pclosmag.com 15 Short Topix: Zoombombing Is A Crime, Not A Prank This release was made possible by the following volunteers: 19 Screenshot Showcase Chief Editor: Paul Arnote (parnote) 20 GIMP Tutorial: Photo Editing, Part 3 Assistant Editor: Meemaw Artwork: Sproggy, Timeth, ms_meme, Meemaw 22 Better than Zoom: Magazine Layout: Paul Arnote, Meemaw, ms_meme HTML Layout: YouCanToo Try These Free Software Tools For Staying In Touch Staff: 25 PCLinuxOS Family Member Spotlight: jzakiya ms_meme CgBoy Meemaw YouCanToo 26 Screenshot Showcase Gary L. Ratliff, Sr. Pete Kelly Daniel Meiß-Wilhelm phorneker 27 Champions Of Regnum On PCLinuxOS daiashi Khadis Thok 32 Screenshot Showcase Alessandro Ebersol Smileeb 33 EBCDIC Handling Library, Part 2 Contributors: 44 PCLinuxOS Bonus Recipe Corner: jzakiya Mashed Potato Mac & Cheese Bake 45 Screenshot Showcase The PCLinuxOS Magazine is released under the Creative 46 Finally! ShotCut Running On PCLinuxOS! Commons Attribution-NonCommercial-Share-Alike 3.0 Unported license. -

MCE Society's Abeda Inamdar Senior College of Arts Science And
MCE Society’s Abeda Inamdar Senior College of Arts Science and Commerce Animation Department PG Diploma in Visual Effects M. C. E. Society’s Abeda Inamdar Senior College Of Arts, Science and Commerce, Camp, Pune-1 (Autonomous) Affiliated to Savitribai Phule Pune University NAAC accredited ‘A’ Grade PG Diploma in Visual Effects 2021-22 (CBCS – Autonomy 21 Pattern) Course/ Paper Title The Fundamental of Filmmaking Course Code 21AUPGDVFX101 Semester 1 No. of Credits 4 Aims & Objectives of the Course Sr. Objectives No. 1. The prime objective of this unit is to introduce you to different aspects of camera work and also aim at developing or honing your skills related to your camera work. 2. The unit will include knowledge that can benefit both a beginner and a professional in this field. 3. The unit will explain all types of camera work irrespective of whether an individual aims at becoming an amateur movie maker or a hardcore professional in camera operations. 4. This course will teach students the basic knowledge and concepts of editing and develop their editing sense in practical editing assignments. 2 Expected Course Specific Learning Outcomes Sr. Learning Outcome No. 1. Define the terms used in video production. 2. Understand the planning of a video shoot. 3. Know about the various camera functions. 4. Techniques of framing. 5. Analyze the ‘basic camera moves. 6. Elucidate various shooting techniques. Syllabus: Unit No. Title with Contents No. of Lectures Unit I. Handling video camera 14 1. Video Camera Terminology 2. Shot 1 3. Framing & Composition 4. Transitions 5. Planning 6. -

Digital Compositing in the Vfx Pipeline
DIGITAL COMPOSITING IN THE VFX PIPELINE Alexandra Ostasheva Bachelor’s thesis May 2015 Degree Programme In Media 2 ABSTRACT Tampereen ammattikorkeakoulu Tampere University of Applied Sciences Degree programme in Media AUTHOR: Alexandra Ostasheva Digital Compositing in the VFX Pipeline Bachelor's thesis 68 pages, May 2015 The purpose of this thesis is to explore a specific area of visual effects production - Digital Compositing. The work explains the origin of this craft and clarifies reasons for its demand in the field. The theoretical section explains the role of Digital Compositing in the VFX pipeline, as well as introduces a reader to the major compositing operations, which digital artists in the field have to be able to perform. Among those are compositing CGI materials into live-action plates, rotoscoping, keying, clean up, tracking and recreation of realistic lens effects. The practical part demonstrates how those Digital Compositing operations are com- bined on practice to achieve a desirable illusion in a shot. Based on the ability to produce realistic illusions and implement complex visual ideas, the works concludes, that Digital Compositing is an important and inseparable part of the VFX pipeline, and a demanded craft in the industry. 3 CONTENTS 1 INTRODUCTION ............................................................................................. 5 WHAT IS DIGITAL COMPOSITING ................................................................. 10 1.1 The value of Digital Compositing ..........................................................