Detecting Verb-Particle Constructions with Syntax-Based Methods
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Analysis of Expressive Interjection Translation in Terms of Meanings
perpustakaan.uns.ac.id digilib.uns.ac.id ANALYSIS OF EXPRESSIVE INTERJECTION TRANSLATION IN TERMS OF MEANINGS, TECHNIQUES, AND QUALITY ASSESSMENTS IN “THE VERY BEST DONALD DUCK” BILINGUAL COMICS EDITION 17 THESIS Submitted as a Partial Fulfillment of the Requirement for Sarjana Degree at English Department of Faculty of Letters and Fine Arts University of Sebelas Maret By: LIA ADHEDIA C0305042 ENGLISH DEPARTMENT FACULTY OF LETTERS AND FINE ARTS UNIVERSITY OF SEBELAS MARET SURAKARTA 2012 THESIScommit APPROVAL to user i perpustakaan.uns.ac.id digilib.uns.ac.id commit to user ii perpustakaan.uns.ac.id digilib.uns.ac.id commit to user iii perpustakaan.uns.ac.id digilib.uns.ac.id PRONOUNCEMENT Name : Lia Adhedia NIM : C0305042 Stated whole-heartedly that this thesis entitled Analysis of Expressive Interjection Translation in Terms of Meanings, Techniques, and Quality Assessments in “The Very Best Donald Duck” bilingual comics edition 17 is originally made by the researcher. It is neither a plagiarism, nor made by others. The things related to other people’s works are written in quotation and included within bibliography. If it is then proved that the researcher cheats, the researcher is ready to take the responsibility. Surakarta, May 2012 The researcher Lia Adhedia C0305042 commit to user iv perpustakaan.uns.ac.id digilib.uns.ac.id MOTTOS “Allah does not change a people’s lot unless they change what their hearts is.” (Surah ar-Ra’d: 11) “So, verily, with every difficulty, there is relief.” (Surah Al Insyirah: 5) commit to user v perpustakaan.uns.ac.id digilib.uns.ac.id DEDICATION This thesis is dedicated to My beloved mother and father My beloved sister and brother commit to user vi perpustakaan.uns.ac.id digilib.uns.ac.id ACKNOWLEDGMENT Alhamdulillaahirabbil’aalamiin, all praises and thanks be to Allah, and peace be upon His chosen bondsmen and women. -

Adverb Phrases and Clauses Function in Specific Sentences
MS CCRS L.7.1a: Explain the function of Lesson 3 phrases and clauses in general and their Adverb Phrases and Clauses function in specific sentences. Introduction Phrases and clauses are groups of words that give specific information in a sentence. A clause has both a subject and a predicate, while a phrase does not. Some phrases and clauses function like adverbs, which means they modify a verb, an adjective, or another adverb in a sentence. • An adverb phrase tells “how,” “when,” “where,” or “why.” It is often a prepositional phrase. Soccer players wear protective gear on the field. (tells where; modifies verb wear) Soccer gloves are thick with padding. (tells how; modifies adjective thick) • An adverb clause can also tell “how,” “when,” “where,” or “why.” It is always a dependent clause. Gloves protect goalies when they catch the ball. (tells when; modifies verb protect) Goalies need gloves because the ball can hurt. (tells why; modifies verb need) Guided Practice Circle the word in each sentence that the underlined phrase or clause modifies. Write how, when, where, or why to explain what the phrase or clause tells. Hint 1 Goalies are the only players who touch the ball with their hands. Often an adverb phrase or clause immediately follows 2 As the ball comes toward the goal, the goalie moves quickly. the word it modifies, but sometimes other words separate the 3 If necessary, the goalie dives onto the ground. two. The phrase or clause may also come at the beginning of a 4 Sometimes the other team scores because the ball gets past sentence, before the the goalie. -

Particle Verbs in Italian
Particle Verbs in Italian Dissertation zur Erlangung des akademischen Grades des Doktors der Philosophie an der Universit¨at Konstanz Fachbereich Sprachwissenschaft vorgelegt von Quaglia, Stefano Tag der m ¨undlichen Pr ¨ufung: 23 Juni 2015 Referent: Professor Christoph Schwarze Referentin: Professorin Miriam Butt Referent: Professor Nigel Vincent Konstanzer Online-Publikations-System (KOPS) URL: http://nbn-resolving.de/urn:nbn:de:bsz:352-0-376213 3 Zusammenfassung Die vorliegende Dissertation befasst sich mit italienischen Partikelverben (PV), d.h. Kon- struktionen die aus einem Verb und einer (meist r¨aumlicher) Partikel, wie andare fuori ‘hinaus-gehen’ oder buttare via ‘weg-schmeißen’. Solche komplexe Ausdr¨ucke sind in manchen Hinsichten interessant, erstmal sprachvergleichend, denn sie instantiieren eine morpho-syntaktische Struktur, die in germanischen Sprachen (wie Deutsch, Englisch, Schwedisch und Holl¨andisch) pervasiv ist, aber in den romanischen Sprachen nicht der- maßen ausgebaut ist. Da germanische Partikelverben Eingenschaften aufweisen, die zum Teil f¨ur die Morphologie, zum teil f¨ur die Syntax typisch sind, ist ihr Status in formalen Grammatiktheorien bestritten: werden PV im Lexikon oder in der Syntax gebaut? Dieselbe Frage stellt sich nat¨urlich auch in Bezug auf die italienischen Partikelverben, und anhand der Ergebnisse meiner Forschung komme ich zum Schluss, dass sie syntaktisch, und nicht morphologisch, zusammengestellt werden. Die Forschungsfragen aber die in Bezug auf das grammatische Verhalten italienischer Partikelverben von besonderem Interesse sind, betreffen auch Probleme der italienischen Syntax. In meiner Arbeit habe ich folgende Forschungsfragen betrachtet: (i) Kategorie und Klassifikation Italienischer Partikeln, (ii) deren Interaktion mit Verben auf argument- struktureller Ebene, (iii) strukturelle Koh¨asion zwischen Verb und Partikel und deren Repr¨asentation. -

Adverbs: Qualifying Actions, Descriptions, and Claims
San José State University Writing Center www.sjsu.edu/writingcenter Written by Fatima Hussain Revised by Cindy Baer Adverbs: Qualifying Actions, Descriptions, and Claims An adverb is a word that describes or modifies a verb, adjective, or other adverb. Adverbs communicate where, when, why, how, how often, how much, or to what degree. They qualify the actions we narrate, the descriptions we record, and the claims we make. Adverbs are as versatile as they are mobile; they can often be moved within a sentence, within limits. She picked up her books and ran to class hurriedly. She picked up her books and hurriedly ran to class. She picked up her books and ran, hurriedly, to class. In these sentences, the adverb “hurriedly” is modifying the verb “ran.” Hurriedly, she picked up her books and ran to class. In this sentence, hurriedly modifies both verbs “picked up” and “ran.” From his expression, one could tell he was irreversibly confused. In this sentence, the adverb “irreversibly” is modifying the adjective “confused.” After taking medicine, almost all patients experienced nausea. In this sentence, the adverb “almost” is modifying the adjective “all” to limit the claim about the effect of the medicine. Frame Sentences Adverbs in English are most often formed from adjectives, by adding -ly: Efficient becomes efficiently. The easiest way to recognize an adverb is by its -ly ending. These are often called “-ly adverbs.” But not all adverbs are -ly adverbs. To tell if a word not ending in -ly is an adverb, you can use the following frame sentences. Any single word that qualifies the verb, adjective, adverb to complete frame sentences like these must be an adverb. -
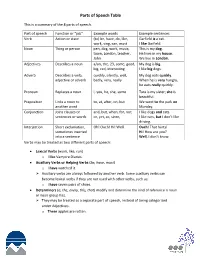
Parts of Speech Table
Parts of Speech Table This is a summary of the 8 parts of speech. Part of speech Function or “job” Example words Example sentences Verb Action or state (to) be, have, do, like, Garfield is a cat. work, sing, can, must I like Garfield. Noun Thing or person pen, dog, work, music, This is my dog. town, London, teacher, He lives in my house. John We live in London. Adjectives Describes a noun a/an, the, 23, some, good, My dog is big. big, red, interesting I like big dogs. Adverb Describes a verb, quickly, silently, well, My dog eats quickly. adjective or adverb badly, very, really When he is very hungry, he eats really quickly. Pronoun Replaces a noun I, you, he, she, some Tara is my sister; she is beautiful. Preposition Links a noun to to, at, after, on, but We went to the park on another word Monday. Conjunction Joins clauses or and, but, when, for, nor, I like dogs and cats. sentences or words or, yet, so, since, I like cars, but I don’t like driving. Interjection Short exclamation, Oh! Ouch! Hi! Well. Ouch! That hurts! sometimes inserted Hi! How are you? into a sentence Well, I don’t know. Verbs may be treated as two different parts of speech: Lexical Verbs (work, like, run) o I like Vampire Diaries. Auxiliary Verbs or Helping Verbs (be, have, must) o I have watched it. Auxiliary verbs are always followed by another verb. Some auxiliary verbs can become lexical verbs if they are not used with other verbs, such as: o I have seven pairs of shoes. -

The Meaning of Approximative Adverbs: Evidence from European Portuguese
THE MEANING OF APPROXIMATIVE ADVERBS: EVIDENCE FROM EUROPEAN PORTUGUESE DISSERTATION Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Patrícia Matos Amaral, Master’s Degree in Linguistics ***** The Ohio State University 2007 Dissertation Committee: Approved by Professor Scott Schwenter, Adviser Professor Craige Roberts ____________________________ Professor John Grinstead Adviser Spanish and Portuguese Graduate Program ABSTRACT This dissertation presents an analysis of the semantic-pragmatic properties of adverbs like English almost and barely (“approximative adverbs”), both in a descriptive and in a theoretical perspective. In particular, I investigate to what extent the meaning distinctions encoded by the system of approximative adverbs in European Portuguese (EP) shed light on the characterization of these adverbs as a class and on the challenges raised by their semantic-pragmatic properties. I focus on the intuitive notion of closeness associated with the meaning of these adverbs and the related question of the asymmetry of their meaning components. The main claim of this work is that the meaning of approximative adverbs involves a comparison between properties along a scalar dimension, and makes reference to a lexically provided or contextually assumed standard value of comparison. In chapter 2, I present some of the properties displayed by approximative adverbs cross-linguistically and more specifically in European Portuguese. This chapter discusses the difficulties raised by their classification within the major classes assumed in taxonomies of adverbs. In chapter 3, I report two experiments that were conducted to test the asymmetric behavior of the meaning components of approximative adverbs and the role that they play in interpretation. -

Verbs of Liking with the Infinitive and the Gerund
English Studies. 2004, 4, pp. 358-380 ooi3-838x/04/o4-oo97/$i6.oo I j Routledge © 2004, Taylor & Francis L(d. s\ T.ylor6,f™cisGfoc VERBS OF LIKING WITH THE INFINITIVE AND THE GERUND 1. Introduction In a number of teaching grammars of English (Azar,' Murphy/ Steer & Carlisi'), like is treated as one of the verbs which shows no difference in mean- ing when it is construed with the gerund or the /o-infinitive. Even Palmer's spe- cialized study on the English verb"* makes no comment on the distinction between these two constructions. Uses such as (1) and (2) below show however that the infinitival and gerundive constructions do not mean exactly the same thing with the verb like: (1) I like to finish work at 4:00. (2) I like finishing work at 4:00. What the difference is and what is responsible for producing it will be one of the things we will try to come to grips with in this study. Another aspect of usage in this area which will merit our attention is the fact that like is different from most of the other verbs in its semantic field in being used with both the infinitive and the gerund as complements: besides love, which also admits both forms of complementation, all the other verbs in this semantic group are con- strued exclusively either with the gerund {enjoy, relish, fancy, appreciate) or with the infinitive {want, wish, desire, long, yearn, hanker, pine, hunger and thirst). Why some verbs allow both complements and others only one is another fact about the functioning of complementation in this area of usage which calls for an explanation. -

Adjectives & Adverbs
What, Why, and How? 14 GRAMMAR Adjectives and Adverbs Fragments Appositives Possessives Articles Run-Together Sentences Commas Subject & Verb Identification Contractions Subject-Verb Agreement Coordinators Subordinators Dangling Modifiers Verb Tenses Grammar chapter overview: Adjectives and Adverbs: These are words you can use to modify—to describe or add meaning to—other words. Adjectives modify nouns or pronouns. Examples: young, small, loud, short, fat, pretty. Adverbs modify verbs, adjectives, other adverbs, and even whole clauses. Examples: really, quickly, especially, early, well. Appositives: Appositives modify nouns for the purpose of offering details or being specific. Appositives begin with a noun or an article (a, an, the), they don’t have their own subject and verb, and they are usually set off with a comma. Example: The car, an antique Stingray, cost ten thousand dollars. Articles: The English language has definite (“the”) and indefinite articles (“a” and “an”). The use depends on whether you are referring a specific member of a group (definite) or to any member of a group (indefinite). Commas: Commas have many uses in the English language. They are responsible for everything from setting apart items in a series to making your writing clearer and preventing misreading. Contractions: Apostrophes can show possession (the girl’s hamster is strange), and also can show the omission of one or more letters when words are combined into contractions (do not = don’t). Coordinators: Coordinators are words you can use to join simple sentences to equally stress both ideas you are connecting. You can easily remember the seven coordinators if you keep in mind the word FANBOYS (For, And, Nor, But, Or, Yet, So). -

Particles and Particle-Verb Constructions in English and Other
PARTICLES AND PARTICLE-VERB CONSTRUCTIONS IN ENGLISH AND OTHER GERMANIC LANGUAGES by Darrell Larsen A dissertation submitted to the Faculty of the University of Delaware in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Linguistics Spring 2014 c 2014 Darrell Larsen All Rights Reserved UMI Number: 3631189 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. UMI 3631189 Published by ProQuest LLC (2014). Copyright in the Dissertation held by the Author. Microform Edition © ProQuest LLC. All rights reserved. This work is protected against unauthorized copying under Title 17, United States Code ProQuest LLC. 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, MI 48106 - 1346 PARTICLES AND PARTICLE-VERB CONSTRUCTIONS IN ENGLISH AND OTHER GERMANIC LANGUAGES by Darrell Larsen Approved: Benjamin Bruening, Ph.D. Chair of the Department of Linguistics and Cognitive Science Approved: George H. Watson, Ph.D. Dean of the College of Arts and Science Approved: James G. Richards, Ph.D. Vice Provost for Graduate and Professional Education I certify that I have read this dissertation and that in my opinion it meets the aca- demic and professional standard required by the University as a dissertation for the degree of Doctor of Philosophy. Signed: Benjamin Bruening, Ph.D. Professor in charge of dissertation I certify that I have read this dissertation and that in my opinion it meets the aca- demic and professional standard required by the University as a dissertation for the degree of Doctor of Philosophy. -

Adjectives and Adverbs
Adjectives and Adverbs Adjectives Characteristics of Adjectives 1. Adjectives modify nouns and pronouns. That is their only function. 2. An adjective can be a word, a phrase, or a clause. 3. An adjective can describe, identify, intensify, limit, negate, or otherwise alter a noun or pronoun. 4. Possessive nouns and pronouns always function like adjectives. 5. Numbers , colors, sizes, and quantities are always adjectives Single Word Adjectives (Adjectives are in bold font.) The brown cow walked away. “Brown” is an adjective modifying the noun “cow.” Gerard has no cars left on his lot. “No” is an adjective modifying the noun “cars.” Phrases as adjectives (adjective phrases are in bold font.) Prepositional phrases can be adjectives or adverbs. I see a brown cow behind the fence. Just like “brown” is descrbing the cow, “Behind the fence” is a prepositional phrase identifying the cow. The brown cow is walking behind the fence. Here, “behind the fence” is an adverb modifying the action “is walking.” (For more information on adverbs, see the next page.) Present participial phrases can be adjectives.* The silly girl swimming with the sharks was eaten in five minutes. In this sentence, the present participial phrase “swimming with the sharks” is an adjective because it is modifying the noun “girl.” Of course, “silly” and “five” are also adjectives modifying “girl” and “minutes.” *Don’t always assume that a present participle is an adjective because these words sometimes work like a noun, and when they act like nouns, they are called gerunds. For example, in the following sentence, Swimming with sharks is not a very smart thing to do, swimming is a thing that can be done; therefore, it is acting like a noun; in fact, it is the subject of the verb “is.” Past participial phrases are adjectives. -

The Status of Particles in Modern English
INTERNATIONAL JOURNAL OF COMPUTERS Issue 4, Volume 2, 2008 The Status of Particles in Modern English Edison I. Hajiyev “form-word”, “structural”, “functional” or “semi- Abstract—The problem of parts of speech is the one that notional” part of speech. causes great controversies both in general linguistic theory We adhere to the point of view that the particle is a and in the analysis of separate languages. Authors of functional part of speech in Modern English. grammars published in the former USSR treat the particle as a separate part of speech, naming it “form-word”, “structural”, “functional” or “semi-notional” part of speech. In this paper II. MORPHOLOGICAL STRUCTURE we investigate the status of particles as a separate part of Particles are invariable. As far as their structure is speech in Modern English. We concentrate our discussion on concerned, English particles may be: the morphological structure, semantic characteristics, place, polysemantic and homonymous particles. We consider the particle in Modern English as a separate part of speech 1) simple: just, still, yet, even, else; characterized by the following typical features: 1) Its lexico- grammatical meaning of “emphatic specification”; 2) Its 2) derivative: merely, simply, alone; unilateral combinability with words of different classes, groups of words, even clauses; 3) Its function of a specifier. 3) compound: also. Keywords—modern English, morphological structure, III. SEMANTIC CHARACTERISTICS semantic characteristics, place, polysemantic, homonymous particles. The meaning of particles is very hard to define. They denote subjective shades of meaning introduced by the I. INTRODUCTION speaker or writer and serving to emphasize or limit he problem of parts of speech is the one that causes some point in what he says. -

Checklist for Recognizing Complete Verbs
Verbs are a means of ordering the chaos of time --- Audre Lorde Checklist for Recognizing Complete Verbs Use the following six guidelines to help you determine if a word or group of words is a verb. 1. A complete verb tells time by changing form. This is the number one function of a verb: to tell us when the action or state of being took, takes, or will take place. a. Example: I ate spaghetti for lunch; I eat spaghetti for lunch; I will eat spaghetti for lunch. 2. A verb can be more than one word a. Example: I should have been eating spaghetti for lunch. 3. A verb either shows action or state of being. a. Example of action verb: I ate spaghetti for lunch 4. A verb that shows state of being is called a linking verb because it always links the subject to another word. a. Examples of linking verbs that show state of being and which link the subject to another word: The spaghetti is hot. The spaghetti is Italian. The spaghetti was mine. 5. A verb never ever comes after the word “to.” a. I like to eat spaghetti. (“Eat” is not a verb in this sentence because it cannot change form to tell time, nor can you add a helping verb to tell time for it. (I like to ate spaghetti; I like to will eat spaghetti.) 6. An “ing” word can never be a verb by itself. It must have a helping verb in front of it to tell time. a. Example of an incomplete “ing” verb: I swimming in the lake.