Naive Regression Growth Models for Prediction of Peppermint Yield Production
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

World Bank Document
95067 Procurement Plan, RRP-II: U.P Aug 13 Revised Procurement Plan for the complete project Cycle for UP Rural Roads Project -II (PMGSY) effective 3rd September 2013 This is an indicative revised procurement plan prepared by the Project for the complete project cycle The Project shall update the Procurement Plan annually or Public Disclosure Authorized as needed throughout the duration of the project in agreement with the Bank to reflect the actual project implementation needs and improvements in institutional capacity. The Project shall implement the Procurement Plan in the manner in which it has been approved by the Bank. I. General Bank’s approval Date of the procurement Plan 3rd September 2013 1. 2. Date of General Procurement Notice issued for Consultancies only: September 14, 2010. Period covered by this procurement plan: June 2013 onwards.. II. Goods and Works 1. Procurement Methods and Prior Review Threshold: Procurement Decisions shall be subject to Prior Review by the Bank as stated in Public Disclosure Authorized Appendix 1 to the Guidelines for Procurement. Expenditure Category Procurement Method Prior Review Threshold Comments US$ GOODS, EQUIPMENT & MACHINERY 1. Goods and Equipment ICB All contracts World Bank SBD will be used and the estimated to cost equivalent of procurement will be as per procedures US$ 300,000 or more per described in World Bank Guidelines contract 2. Goods and Equipment NCB First contract for goods for The NCB bidding document agreed with estimated to cost less than each state , irrespective of GOI will be used and the procurement will US$ 300,000 and greater than value and all contracts be as per procedures described in the Public Disclosure Authorized US$ 100,000 equivalent per estimated to cost more than Procurement and Contract Management contract US$ 200,000 equivalent per Manual. -

Barabanki Dealers Of
Dealers of Barabanki Sl.No TIN NO. UPTTNO FIRM - NAME FIRM-ADDRESS 1 09150600003 BB0010297 J.R.ORGAINIC INDUSTRIES LTD. DEWA ROAD BARABANKKI 2 09150600017 BB0019725 POINEER MEDICAL STORE BEGAM GANJ BARABANKI 3 09150600022 BB0027709 PAL CYCLE HOUSE LAIYA MANDI BARABANKI 4 09150600036 BB0029230 SAMSHUDIN SARRPHUDIN SADAR BAZAR BARABANKI 5 09150600041 BB0034599 TRILOCHAN NATH KESHAO KUMAR SAFDAR GANJ BARABANKI 6 09150600055 BB0016832 SHYAM BIHARI RAM SWROOP JAISWAL DHANOKHAR CHOURAHA BARABANKI 7 09150600060 BB0037812 MATA PRASAD BHURA MALL GALLA FATEHPUR BARABANKI 8 09150600069 BB0041040 GUPTA FERTILIZER FATEHPUR BARABANKI 9 09150600074 BB0041380 HARI TEE CO. MAIN ROAD BARABANKI 10 09150600088 BB0042964 UNITED DRUG AGENCIES MEENA MARKET BARABANKI 11 09150600093 BB0088502 LAXMI RICE MILL & ALLIED INDUSTRIES FAIZABAD ROAD BARABANKI 12 09150600102 BB0049211 RAM PRAKASH CONTRACTION TIKRA BADDUPUR BARABANKI 13 09150600116 BB0046957 KISAN COLD STORAGE PALHARI CHOURAHA BARABANKI 14 09150600121 BB0046900 BEAUTY PALACE GENERAL MERCHANT, 34 INDIRA MARKET BARABANKI 15 09150600135 BB0048714 FATEHPUR TRADING CO. FATEHPUR BARABANKI 16 09150600140 BB0030073 RINKU COAL DEPOT NAKA SATARAKH BARABANKI 17 09150600149 BB0509224 JAI SHIV BRICK FIELD MO.PUR KHALA BARABANKI 18 09150600154 BB0008710 VISHNU KUMAR AJAY KUMAR MAIN ROAD BARABANKI 19 09150600168 BB0050354 SRI DURGA RICE AND FLOUR MILL TIWARI GANJ H Q BARABANKI 20 09150600173 BB0053854 MAZHAR AZIZ CONTRACTOR SATRIKH BARABANKI 21 09150600187 BB0051660 MANISHA ENTERPRISES FATEHPUR BARABANKI 22 09150600192 -
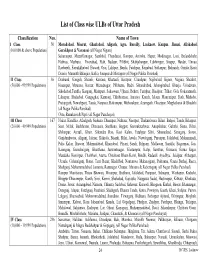
List of Class Wise Ulbs of Uttar Pradesh
List of Class wise ULBs of Uttar Pradesh Classification Nos. Name of Town I Class 50 Moradabad, Meerut, Ghazia bad, Aligarh, Agra, Bareilly , Lucknow , Kanpur , Jhansi, Allahabad , (100,000 & above Population) Gorakhpur & Varanasi (all Nagar Nigam) Saharanpur, Muzaffarnagar, Sambhal, Chandausi, Rampur, Amroha, Hapur, Modinagar, Loni, Bulandshahr , Hathras, Mathura, Firozabad, Etah, Badaun, Pilibhit, Shahjahanpur, Lakhimpur, Sitapur, Hardoi , Unnao, Raebareli, Farrukkhabad, Etawah, Orai, Lalitpur, Banda, Fatehpur, Faizabad, Sultanpur, Bahraich, Gonda, Basti , Deoria, Maunath Bhanjan, Ballia, Jaunpur & Mirzapur (all Nagar Palika Parishad) II Class 56 Deoband, Gangoh, Shamli, Kairana, Khatauli, Kiratpur, Chandpur, Najibabad, Bijnor, Nagina, Sherkot, (50,000 - 99,999 Population) Hasanpur, Mawana, Baraut, Muradnagar, Pilkhuwa, Dadri, Sikandrabad, Jahangirabad, Khurja, Vrindavan, Sikohabad,Tundla, Kasganj, Mainpuri, Sahaswan, Ujhani, Beheri, Faridpur, Bisalpur, Tilhar, Gola Gokarannath, Laharpur, Shahabad, Gangaghat, Kannauj, Chhibramau, Auraiya, Konch, Jalaun, Mauranipur, Rath, Mahoba, Pratapgarh, Nawabganj, Tanda, Nanpara, Balrampur, Mubarakpur, Azamgarh, Ghazipur, Mughalsarai & Bhadohi (all Nagar Palika Parishad) Obra, Renukoot & Pipri (all Nagar Panchayat) III Class 167 Nakur, Kandhla, Afzalgarh, Seohara, Dhampur, Nehtaur, Noorpur, Thakurdwara, Bilari, Bahjoi, Tanda, Bilaspur, (20,000 - 49,999 Population) Suar, Milak, Bachhraon, Dhanaura, Sardhana, Bagpat, Garmukteshwer, Anupshahar, Gulathi, Siana, Dibai, Shikarpur, Atrauli, Khair, Sikandra -

Notice for Appointment of Regular/Rural Retail Outlets Dealerships
Notice for appointment of Regular/Rural Retail Outlets Dealerships Hindustan Petroleum Corporation Limited proposes to appoint Retail Outlet dealers in the State of Uttar Pradesh, as per following details: Fixed Fee Minimum Dimension (in / Min bid Security Estimated Type of Finance to be arranged by the Mode of amount ( Deposit ( Sl. No. Name Of Location Revenue District Type of RO M.)/Area of the site (in Sq. Site* applicant (Rs in Lakhs) selection monthly Sales Category M.). * Rs in Rs in Potential # Lakhs) Lakhs) 1 2 3 4 5 6 7 8 9a 9b 10 11 12 SC/SC CC 1/SC PH/ST/ST CC Estimated Estimated fund 1/ST working required for PH/OBC/OBC CC/DC/ capital Draw of Regular/Rural MS+HSD in Kls Frontage Depth Area development of CC 1/OBC CFS requirement Lots/Bidding infrastructure at PH/OPEN/OPE for operation RO N CC 1/OPEN of RO CC 2/OPEN PH ON LHS, BETWEEN KM STONE NO. 0 TO 8 ON 1 NH-AB(AGRA BYPASS) WHILE GOING FROM AGRA REGULAR 150 SC CFS 40 45 1800 0 0 Draw of Lots 0 3 MATHURA TO GWALIOR UPTO 3 KM FROM INTERSECTION OF SHASTRIPURAM- VAYUVIHAR ROAD & AGRA 2 AGRA REGULAR 150 SC CFS 20 20 400 0 0 Draw of Lots 0 3 BHARATPUR ROAD ON VAYU VIHAR ROAD TOWARDS SHASTRIPURAM ON LHS ,BETWEEN KM STONE NO 136 TO 141, 3 ALIGARH REGULAR 150 SC CFS 40 45 1800 0 0 Draw of Lots 0 3 ON BULANDSHAHR-ETAH ROAD (NH-91) WITHIN 6 KM FROM DIBAI DORAHA TOWARDS 4 NARORA ON ALIGARH-MORADABAD ROAD BULANDSHAHR REGULAR 150 SC CFS 40 45 1800 0 0 Draw of Lots 0 3 (NH 509) WITHIN MUNICIAPL LIMITS OF BADAUN CITY 5 BUDAUN REGULAR 120 SC CFS 30 30 900 0 0 Draw of Lots 0 3 ON BAREILLY -

Year 2002-03
Consistence Opium Licesed Average Status/ Reason Net Area in of Opium Tendered Area in per hectare Quality for non- Unique Code of Cultivator District Tehsil Village Name of Cultivator Crop Year Hect. as per at 70° in Old Unique Code Remarks Hect. (Kg/hec) of issuance (0.0000) GOAW Kgs (0.000) (00.0000) Opium of licence (00.00) (00.000) 03010101001 013 BARABANKI NAWABGANJ ADAMPUR RAM SEVEK/ GOKUL PRASAD 2002-03 0.200 0.190 F 03010101002 006 BARABANKI NAWABGANJ ALAPUR RAM NARESH/ CHOTI 2002-03 0.200 0.200 00.00 2.250 10.976 I 02 03010101003 003 BARABANKI NAWABGANJ ALMASGANJ RAGHU NANDAN/ MAIKULAL 2002-03 0.200 0.190 4.250 20.732 F 03010101003 007 BARABANKI NAWABGANJ ALMASGANJ KESHAR/ SHAUKAT ALI 2002-03 0.200 0.210 00.00 3.250 16.250 I 02 03010101003 010 BARABANKI NAWABGANJ ALMASGANJ SARVJEET/ KALIDEEN 2002-03 0.200 0.190 4.150 20.750 F 03010101003 022 BARABANKI NAWABGANJ ALMASGANJ KIDHA LAL/ DAYAL 2002-03 0.200 0.190 2.250 10.976 F 03010101003 027 BARABANKI NAWABGANJ ALMASGANJ RAMDEI/ RAM JIYAVAN 2002-03 0.200 0.190 3.150 15.366 F 03010101003 028 BARABANKI NAWABGANJ ALMASGANJ CHOTYLAL/ CHATURI 2002-03 0.200 0.190 3.250 15.476 F 03010101003 029 BARABANKI NAWABGANJ ALMASGANJ SURESH CHANDRA/ ISWARI PRASAD 2002-03 0.200 0.190 3.250 17.105 F 03010101003 031 BARABANKI NAWABGANJ ALMASGANJ HARILAL/ MAEKULAL 2002-03 0.200 0.190 4.250 20.732 F 03010101003 032 BARABANKI NAWABGANJ ALMASGANJ RAM NARESH/ KALLU 2002-03 0.200 0.190 4.250 21.250 F 03010101003 033 BARABANKI NAWABGANJ ALMASGANJ RAM LAKHAN/ SURJEET 2002-03 0.200 0.190 5.250 26.250 F 03010101004 -

Seria L No. Register Number Tehsil Applicant Name
PROPOSED LIST OF BENEFICIARY UNDER NATIONAL FAMILY BENEFIT SCHEME FOR THE APPROVAL OF D.M. (YEAR 2015-16) SERIA REGISTER TEHSIL APPLICANT NAME APPLICANT CATEGORY AGE OF DATE OF GEND ANNUAL ADDRESS FATHER/HUSBA DEATH DEATH L NO. NUMBER ND NAME PERSON PERSON ER INCOME 1 314816575 Sirauli REKHA DESHRAJ OBC 42 28/03/2017 F 42000 MADARPUR,,SIRAULI GAUSPUR,MIRAPUR Gauspur** 2 314816601 Sirauli fool mati beejak ram OBC 42 01/10/2016 F 42000 DUNDI,,SIRAULI GAUSPUR,DUNDI Gauspur** 3 314816603 Fatehpur Shyama sunder lal OBC 35 03/11/2016 F 42000 SELAK JALALPUR,,SURATGANJ,SELAK JALAL PUR 4 314816609 Sirauli LATA SW. RAM SARAN OBC 46 19/03/2017 F 36000 GIDRAPUR,,SIRAULI GAUSPUR,GIDRAPUR Gauspur** 5 314816691 Haidergarh RAMA DEVI SAHDEV OBC 37 15/09/2016 F 36000 MANJHAR,,TRIVEDIGANJ,MANJHAR 6 3148111408 Haidergarh vidyawati ramfal OBC 46 05/07/2018 F 42000 BAHUTA,,TRIVEDIGANJ,BAHUTA 7 314813343 Fatehpur RAHISHA LATE RAFIK OBC 58 17/07/2016 F 36000 TANDA,,SURATGANJ,TANDA KHATOON 8 314813401 Sirauli JAYANTI DEVI LET KAMLESH OBC 57 22/08/2016 F 42000 Select,,SIRAULI GAUSPUR,MADARPUR Gauspur** KUMAR 9 314815855 Sirauli SONAPATI HANOMAN OBC 58 25/01/2017 F 42000 SHYAM NAGAR,,SIRAULI GAUSPUR,SHYAM NAGAR Gauspur** 10 314815895 Ramnagar SARITA DEVI RAMMURAT OBC 24 19/12/2016 F 36000 BANARKI,,SURATGANJ,BANARKI 11 314816355 Sirauli MAYA DEVI SWA LAYAK RAM OBC 48 22/02/2017 F 42000 DUNDI,,SIRAULI GAUSPUR,DUNDI Gauspur** 12 3148111325 Haidergarh RAMRAJA LATE RAM SAGAR OBC 49 25/05/2018 F 42000 MIRAPUR,,SIDDHAUR,MIRAPUR 13 3148111327 Nawabganj PHOOL DHARA LATE -

Serial No. Register Number Tehsil Applicant Name
PROPOSED LIST OF BENEFICIARY UNDER NATIONAL FAMILY BENEFIT SCHEME FOR THE APPROVAL OF D.M. (YEAR 2015-16) SERIAL REGISTER TEHSIL APPLICANT NAME APPLICANT CATEGORY AGE OF DATE OF GENDER ANNUAL ADDRESS NO. NUMBER FATHER/HUSBAND DEATH DEATH PERSON INCOME 3148111691 Ramsanehighat RAM DEI RAM SEVAKNAME SC PERSON58 10/04/2018 F 42000 BADSHAHNAGAR,,PUREDALAI,BADSHAHNAGAR 1 3148111693 Haidergarh shivrani ram sajeewan SC 48 07/08/2018 F 42000 LAKHUPUR,,SIDDHAUR,LAKHUPUR 2 3148111618 Ramsanehighat PREMAVATI DHANIRAM SC 57 14/08/2018 F 42000 SEMARI,,PUREDALAI,SEMARI 3 3148111624 Fatehpur UMA DEVI DEEPAK SC 48 31/08/2018 F 36000 MADANPUR,,FATEHPUR,MADANPUR 4 3148111631 Nawabganj SOOKA LATE KUNJ BIHARI SC 52 27/06/2018 F 42000 KHAJOORGAON,,DEWA,KHAJOORGAON 5 3148111633 Nawabganj Ketki Devi Ram Harakh SC 47 18/08/2018 F 42000 KARPIYA,,MASAULI,KARPIYA 6 3148111643 Fatehpur BADKI HASANU SC 58 28/03/2018 F 42000 TARAWAN,,NINDURA,TARAWAN 7 3148111644 Nawabganj pushpa devi asharam SC 50 21/02/2018 F 42000 WAJIDPUR,,MASAULI,WAJIDPUR 8 3148111599 Haidergarh RAMBETI LATE SURESH SC 35 04/05/2018 F 36000 BEHRAMPUR,,HAIDARGARH,SATRAHI 9 3148111602 Haidergarh MADHURI GOKUL SC 35 13/07/2018 F 42000 DHEDHIYA,,SIDDHAUR,DHEDHIYA 10 3148111608 Haidergarh TILKA LATE GURU SC 57 08/08/2018 F 36000 SANDVA,,HAIDARGARH,SANDVA 11 3148111612 Haidergarh SIRTAJI LATE CHET RAM SC 45 20/06/2018 F 42000 SATRAHI,,HAIDARGARH,SATRAHI 12 3148111613 Haidergarh SUNDARA LATE SARUPE SC 55 25/02/2018 F 42000 SATRAHI,,HAIDARGARH,SATRAHI 13 3148111614 Ramsanehighat BASDEV LATE KAMLESH SC -

Gonda and Barabanki Districts
81°0'0"E 81°10'0"E 81°20'0"E 81°30'0"E 81°40'0"E 81°50'0"E 82°0'0"E 82°10'0"E 82°20'0"E 82°30'0"E N N " " 0 0 ' ' 0 0 4 4 GEOGRAPHICAL AREA ° ° 7 7 2 ± 2 GONDA AND BARABANKI DISTRICTS KEY MAP N N " " 0 0 ' ' 0 0 3 3 ° ° 7 7 2 2 U T T A R P R A D E S H Vishunpur Belbhariya ! Khargupur Lonawa Dargah !( ! Khargupur Imilia N ! N " Á " 0 0 ' ' 0 0 2 2 ° ° 7 7 2 2 It!ia Thok !Á Phrenda Shukul Parsia Bahoripur ! ! ! Para Saray Belhara Á ! Tribhuwan Nagar Grint ! Retwagara ! ! ! Rajapur Retwagara Katra ! Dhanepur Bhatwamau Dewa Pasiya Á! CA-02 ! Khinjhna Mithwara ! ! !( Ramapur Ujjani Kalan ! ! Bangawan ! Suratganj Selhari ! GONDA Madhau Ganj ! Dewari Kalan ! ! Beerpur Katra ! ! Devria Alawal Dulhapur Bankat ! ! Total Geographical Area (Sq Km) 8,405 N Nindura Ashokpur N " CA-08 ! ! Rudragarh Mausi ! " 0 Fatehpur Paharapur 0 ' ! ' 0 Á!Á!!( Sarbang Pur ! 0 1 ! Bankati Suryabali Singh 1 No. of Charge Area 10 ° Ghughter FATEHPUR Kauraha Jagdishpur ! ° 7 ! CA-07 7 2 Keswapur Pahrwa JanÁ!ki Nagar 2 ! ! !! !( ! Baranpur !! Á Parsa Godri Á Á Total Household 11,20,305 Á RAM ! Á ! Gonda !( Sakraura !!( Colonelganj(Rural) 18 E !. Gonda Á! ¤£ !( Á! Mohsand Total Population 66,94,618 ! NAGAR Á! Gird Gonda Jigana ! Á! ! ! Machhali Gaon Nankar Á! Chandpur Banvaria Ummed Jot Sihali Ramnagar CA-04 ! ! Dhuswa Khas ! ! ! ! Á! !( Banghusra Khorhansha Daulatpur Grint Á! COLONELGANJ Bhonka ! ITI Mankapur ! Kursi Tilokpur Khargupur Á! CHARGE CHARGE ! ! ! !( Hathia Gardh NAME NAME Bhitaura Mankapur ! ¤£1 A Saraiya Anta ¤£30 ! !!( AREA ID AREA ID Bahrauli Dewa ! ! Á! -

Haidergarh Assembly Uttar Pradesh Factbook
Editor & Director Dr. R.K. Thukral Research Editor Dr. Shafeeq Rahman Compiled, Researched and Published by Datanet India Pvt. Ltd. D-100, 1st Floor, Okhla Industrial Area, Phase-I, New Delhi- 110020. Ph.: 91-11- 43580781-84 Email : [email protected] Website : www.indiastatelections.com Online Book Store : www.indiastatpublications.com Report No. : AFB/UP-272-0121 ISBN : 978-93-5293-999-2 First Edition : January, 2017 Third Updated Edition : January, 2021 Price : Rs. 11500/- US$ 310 © Datanet India Pvt. Ltd. All rights reserved. No part of this book may be reproduced, stored in a retrieval system or transmitted in any form or by any means, mechanical photocopying, photographing, scanning, recording or otherwise without the prior written permission of the publisher. Please refer to Disclaimer at page no. 283 for the use of this publication. Printed in India Contents No. Particulars Page No. Introduction 1 Assembly Constituency - (Vidhan Sabha) at a Glance | Features of Assembly 1-2 as per Delimitation Commission of India (2008) Location and Political Maps Location Map | Boundaries of Assembly Constituency - (Vidhan Sabha) in 2 District | Boundaries of Assembly Constituency under Parliamentary 3-10 Constituency - (Lok Sabha) | Town & Village-wise Winner Parties-2019, 2017, 2014, 2012 and 2009 Administrative Setup 3 District | Sub-district | Towns | Villages | Inhabited Villages | Uninhabited 11-25 Villages | Village Panchayat | Intermediate Panchayat Demographics 4 Population | Households | Rural/Urban Population | Towns -

Sr No. NAME AS AADHAR FATHER/HUSBAND NAME ULB
Sr No. NAME AS AADHAR FATHER/HUSBAND NAME ULB NAME ADDRESS 0;AHIRAN ZAIDPUR;;Uttar Pradesh ;Bara ZAIDPUR 1 VAIMUN NISHA MO SARVAR Banki;Zaidpur RAM NAGAR 20;KADIRABAD;;Uttar Pradesh ;Bara 2 KANDHAILAL SALIK RAM Banki;Ramnagar RAM NAGAR 157;BARABANKI RAM NAGAR;;Uttar 3 RAMSAHARE PARSHU RAM Pradesh ;Bara Banki;Ramnagar 347;Gandhi Nagar;;Uttar Pradesh ;Bara NAWABGANJ 4 SUNEETA Prem Lal Banki;Nawabganj 14;MULIHA;Uttar Pradesh ;Bara DARIYABAD Banki;Dariyabad;0;;Uttar Pradesh ;Bara 5 SHIVSHANKAR SANTRAM Banki;Dariyabad 36;36;BANNE TALE;Uttar Pradesh ;Bara DARIYABAD Banki;Dariyabad;;Uttar Pradesh ;Bara 6 RAJRANI RAJENDRA Banki;Dariyabad RAM NAGAR 3;RAMNAGAR;;Uttar Pradesh ;Bara 7 RAMESH YADAV BHAGAUTI Banki;Ramnagar RAM NAGAR 209;BARABANKI RAM NAGAR;;Uttar 8 RAM JAS MAURYA BADLU Pradesh ;Bara Banki;Ramnagar RAM NAGAR 344/A;RAM NAGAR;;Uttar Pradesh ;Bara 9 BHAGAUTI PRASAD GHIRRAU Banki;Ramnagar 0;Nai basti;;Uttar Pradesh ;Bara Banki 10 Ganga Mishra Ram Lalan Mishra Banki;Banki 0;BHEETRI PEERBATAWAN CHOTA JAIN NAWABGANJ MANDIR;;Uttar Pradesh ;Bara 11 OM PRAKASH MUNNA LAL Banki;Nawabganj RAM NAGAR 1;LAKHRORA;;Uttar Pradesh ;Bara 12 CHANDNI VINOD KUMAR Banki;Ramnagar RAM NAGAR 3;DHAMEDI 3;;Uttar Pradesh ;Bara 13 LALTA PRASAD DESI DEEN Banki;Ramnagar 0;MO. NAYA PURA NAGAR ZAIDPUR PANCHAYAT;;Uttar Pradesh ;Bara 14 VIRENDRA KUMAR BANWARI LAL Banki;Zaidpur RAM NAGAR 1;LAKHRORA;;Uttar Pradesh ;Bara 15 PHULENA GOURAKH Banki;Ramnagar 229;MOULVI KATRA;;Uttar Pradesh ;Bara ZAIDPUR 16 BEWA SHEETLA LATE BARATI LAL Banki;Zaidpur 0;BUDHUGANJ NAYA PURA;;Uttar -

Barabanki Page:- 1 Cent-Code & Name Exam Sch-Status School Code & Name #School-Allot Sex Part Group 1001 Govt.Inter College Barabanki Aum
DATE:27-02-2021 BHS&IE, UP EXAM YEAR-2021 **** FINAL CENTRE ALLOTMENT REPORT **** DIST-CD & NAME :- 63 BARABANKI PAGE:- 1 CENT-CODE & NAME EXAM SCH-STATUS SCHOOL CODE & NAME #SCHOOL-ALLOT SEX PART GROUP 1001 GOVT.INTER COLLEGE BARABANKI AUM HIGH BUM 1006 D A V HR SEC SCHOOL BARABANKI 62 M HIGH CUM 1008 ANAND BHAWAN HIGH SCHOOL BARABANKI 17 F HIGH CUM 1052 RAM SEWAK YADAV SMARAK INTER COLLEGE BAREL BARABANKI 72 M HIGH CRM 1064 S S INTER COLLEGE BHANAULI BARABANKI 66 M HIGH CRM 1069 SUBHASH ADARSH I C KURAULI BARABANKI 44 M HIGH CUF 1130 S B H S SCHOOL LAKHPERA BAGH BARABANKI 16 F HIGH CUM 1134 SCHOLARS PUBLIC INTER COLLEGE BARABANKI 7 F HIGH CUF 1169 JHABER BA PATEL B V INTER COLLEGE BARABANKI 21 F HIGH CRM 1183 BHAVI BHARAT SIKSHA NIKETAN IC BARABANKI 53 M HIGH CRM 1236 RAMLAKHAN RAMDAS H S S SALEMPUR DEWA BARABANKI 19 M HIGH ARM 1262 RAJKEEYA HIGH SCHOOL BADEL BANKI BARABANKI 26 M HIGH CRM 1297 NEW VIKAS U M V MAINAHAR BARABANKI 36 M 439 INTER ARM 1009 G INTER COLLEGE BARAULI JATA BARABANKI 29 M SCIENCE INTER CUM 1079 WARIS CHILDRENS ACADEMY I C BARABANKI 33 M SCIENCE INTER CUM 1122 SRI SAI INTER COLLEGE LAKHPERABAGH BARABANKI 181 M - SCIENCE INTER CRM 1137 JYOTI SHIKSHA NIKETAN INTER COLLEGE BHATEHATA DEWA BARABANKI 78 M SCIENCE INTER CRM 1229 RAMBHEEKH RAJRANI S S I C MALOOKPURGADIYABARABANKI 155 M SCIENCE 476 CENTRE TOTAL >>>>>> 915 1002 GOVERNMENT GIRLS INTER COLLEGE, BARABANKI AUF HIGH AUF 1002 GOVERNMENT GIRLS INTER COLLEGE, BARABANKI 285 F HIGH CUM 1126 PUBLIC CITY MONTESSORI H S BARABANKI 3 F HIGH CUM 1129 J N HIGH SCHOOL RASOOLPUR -
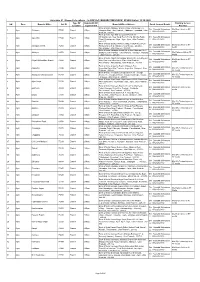
Office Sol ID Type of Location Bandwidth of Required Link Branch
Annexure 01 : Domestic locations - to RFP Ref : BOI/HO/IT/MPLS/RFP- 01/2020 Dated: 13.10.2020 Type Of Bandwidth Of Existing Service SN Zone Branch/ Office Sol ID Branch/Office Address Zonal Contact Details Location required link Provider Bank Of India Abbaspur Branch,Village Bharaielpur, Po Shri Saurabh Shrivastava M/s Bharti Airtel on RF 1 Agra Abbaspur 77090 Branch 2 Mbps Ghaghau,State- Utar Pradesh , Abbaspur , Firozabad , Uttar LL: 0562-2523830 media Pradesh , 205141 Bank Of India Agra Mid- Corporate Branch,49- 50,Sulabpuram, Near Kargil Petrol Pump, Skindra-Bodla Shri Saurabh Shrivastava 2 Agra Agra Mcb 72590 Branch 2 Mbps Road, Shastripuram, Agra , Agra , Agra , Uttar Pradesh , LL: 0562-2523830 282 007 Bank Of India Ajmatpur Branch,Village-Kuaiya Boot, Post- Shri Saurabh Shrivastava M/s Bharti Airtel on RF 3 Agra Ajmatpur Branch 76260 Branch 2 Mbps Pachpokhara, Near Mahadev Cold Storage, Ajmatpur , LL: 0562-2523830 media Farrukhabad , Uttar Pradesh , 209 625 Bank Of India Akbarpur Branch,Vill. & Post Akbarpur, Nh-2, Shri Saurabh Shrivastava 4 Agra Akbarpur 68570 Branch 2 Mbps Mathura Delhi Highway, Tehsil Mathura , Akbarpur , Mathura M/s Reliance JIO on RF LL: 0562-2523830 , Uttar Pradesh , 281 406 Media Bank Of India Aligarh Mohaddipur Branch,Vill. & Po Rajepur, Shri Saurabh Shrivastava M/s Bharti Airtel on RF 5 Agra Aligarh Mohaddipur Branch 76200 Branch 2 Mbps Near Pwd Inspection House,State- Uttar Pradesh , LL: 0562-2523830 media Farrukhabad , Farrukhabad , Uttar Pradesh , 209 621 Bank Of India Angautha Branch,Village & Post