Re-Recognition of Pseudogenes: from Molecular to Clinical Applications Xu Chen1, Lin Wan2, Wei Wang1, Wen-Jin Xi1, An-Gang Yang1 and Tao Wang3
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Merlin Is a Potent Inhibitor of Glioma Growth
Research Article Merlin Is a Potent Inhibitor of Glioma Growth Ying-Ka Ingar Lau,1 Lucas B. Murray,1 Sean S. Houshmandi,2 Yin Xu,1 David H. Gutmann,2 and Qin Yu1 1Department of Oncological Sciences, Mount Sinai School of Medicine, New York, New York and 2Department of Neurology, Washington University School of Medicine, St. Louis, Missouri Abstract The NF2 gene shares sequence similarity with the members of Neurofibromatosis 2 (NF2) is an inherited cancer syndrome in Band 4.1 superfamily (4, 5). In particular, the NF2 protein, merlin (or schwannomin), most closely resembles proteins of the ezrin- which affected individuals develop nervous system tumors, including schwannomas, meningiomas, and ependymomas. radixin-moesin (ERM) subfamily. Similar to the ERM proteins, The NF2 protein merlin (or schwannomin) is a member of the merlin serves as a linker between transmembrane proteins and the Band 4.1superfamily of proteins, which serve as linkers actin cytoskeleton and regulates cytoskeleton remodeling and cell between transmembrane proteins and the actin cytoskeleton. motility (6–8). Unlike ERM proteins, merlin functions as a negative In addition to mutational inactivation of the NF2 gene in NF2- growth regulator or tumor suppressor. In this regard, mutational associated tumors, mutations and loss of merlin expression inactivation of the NF2 gene is sufficient to result in the have also been reported in other types of cancers. In the development of NF2-associated nervous system tumors. Moreover, present study, we show that merlin expression is dramatically NF2 mutations have also been reported in other tumor types, reduced in human malignant gliomas and that reexpression of including melanoma and mesothelioma (9), suggesting that merlin plays an important role, not only in NF2-associated tumors but also functional merlin dramatically inhibits both subcutaneous and intracranial growth of human glioma cells in mice. -

A Multistep Bioinformatic Approach Detects Putative Regulatory
BMC Bioinformatics BioMed Central Research article Open Access A multistep bioinformatic approach detects putative regulatory elements in gene promoters Stefania Bortoluzzi1, Alessandro Coppe1, Andrea Bisognin1, Cinzia Pizzi2 and Gian Antonio Danieli*1 Address: 1Department of Biology, University of Padova – Via Bassi 58/B, 35131, Padova, Italy and 2Department of Information Engineering, University of Padova – Via Gradenigo 6/B, 35131, Padova, Italy Email: Stefania Bortoluzzi - [email protected]; Alessandro Coppe - [email protected]; Andrea Bisognin - [email protected]; Cinzia Pizzi - [email protected]; Gian Antonio Danieli* - [email protected] * Corresponding author Published: 18 May 2005 Received: 12 November 2004 Accepted: 18 May 2005 BMC Bioinformatics 2005, 6:121 doi:10.1186/1471-2105-6-121 This article is available from: http://www.biomedcentral.com/1471-2105/6/121 © 2005 Bortoluzzi et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background: Searching for approximate patterns in large promoter sequences frequently produces an exceedingly high numbers of results. Our aim was to exploit biological knowledge for definition of a sheltered search space and of appropriate search parameters, in order to develop a method for identification of a tractable number of sequence motifs. Results: Novel software (COOP) was developed for extraction of sequence motifs, based on clustering of exact or approximate patterns according to the frequency of their overlapping occurrences. -

Figure S1. HAEC ROS Production and ML090 NOX5-Inhibition
Figure S1. HAEC ROS production and ML090 NOX5-inhibition. (a) Extracellular H2O2 production in HAEC treated with ML090 at different concentrations and 24 h after being infected with GFP and NOX5-β adenoviruses (MOI 100). **p< 0.01, and ****p< 0.0001 vs control NOX5-β-infected cells (ML090, 0 nM). Results expressed as mean ± SEM. Fold increase vs GFP-infected cells with 0 nM of ML090. n= 6. (b) NOX5-β overexpression and DHE oxidation in HAEC. Representative images from three experiments are shown. Intracellular superoxide anion production of HAEC 24 h after infection with GFP and NOX5-β adenoviruses at different MOIs treated or not with ML090 (10 nM). MOI: Multiplicity of infection. Figure S2. Ontology analysis of HAEC infected with NOX5-β. Ontology analysis shows that the response to unfolded protein is the most relevant. Figure S3. UPR mRNA expression in heart of infarcted transgenic mice. n= 12-13. Results expressed as mean ± SEM. Table S1: Altered gene expression due to NOX5-β expression at 12 h (bold, highlighted in yellow). N12hvsG12h N18hvsG18h N24hvsG24h GeneName GeneDescription TranscriptID logFC p-value logFC p-value logFC p-value family with sequence similarity NM_052966 1.45 1.20E-17 2.44 3.27E-19 2.96 6.24E-21 FAM129A 129. member A DnaJ (Hsp40) homolog. NM_001130182 2.19 9.83E-20 2.94 2.90E-19 3.01 1.68E-19 DNAJA4 subfamily A. member 4 phorbol-12-myristate-13-acetate- NM_021127 0.93 1.84E-12 2.41 1.32E-17 2.69 1.43E-18 PMAIP1 induced protein 1 E2F7 E2F transcription factor 7 NM_203394 0.71 8.35E-11 2.20 2.21E-17 2.48 1.84E-18 DnaJ (Hsp40) homolog. -
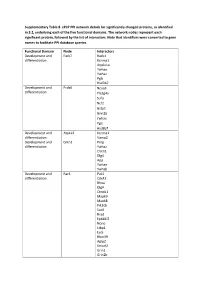
Supplementary Table 8. Cpcp PPI Network Details for Significantly Changed Proteins, As Identified in 3.2, Underlying Each of the Five Functional Domains
Supplementary Table 8. cPCP PPI network details for significantly changed proteins, as identified in 3.2, underlying each of the five functional domains. The network nodes represent each significant protein, followed by the list of interactors. Note that identifiers were converted to gene names to facilitate PPI database queries. Functional Domain Node Interactors Development and Park7 Rack1 differentiation Kcnma1 Atp6v1a Ywhae Ywhaz Pgls Hsd3b7 Development and Prdx6 Ncoa3 differentiation Pla2g4a Sufu Ncf2 Gstp1 Grin2b Ywhae Pgls Hsd3b7 Development and Atp1a2 Kcnma1 differentiation Vamp2 Development and Cntn1 Prnp differentiation Ywhaz Clstn1 Dlg4 App Ywhae Ywhab Development and Rac1 Pak1 differentiation Cdc42 Rhoa Dlg4 Ctnnb1 Mapk9 Mapk8 Pik3cb Sod1 Rrad Epb41l2 Nono Ltbp1 Evi5 Rbm39 Aplp2 Smurf2 Grin1 Grin2b Xiap Chn2 Cav1 Cybb Pgls Ywhae Development and Hbb-b1 Atp5b differentiation Hba Kcnma1 Got1 Aldoa Ywhaz Pgls Hsd3b4 Hsd3b7 Ywhae Development and Myh6 Mybpc3 differentiation Prkce Ywhae Development and Amph Capn2 differentiation Ap2a2 Dnm1 Dnm3 Dnm2 Atp6v1a Ywhab Development and Dnm3 Bin1 differentiation Amph Pacsin1 Grb2 Ywhae Bsn Development and Eef2 Ywhaz differentiation Rpgrip1l Atp6v1a Nphp1 Iqcb1 Ezh2 Ywhae Ywhab Pgls Hsd3b7 Hsd3b4 Development and Gnai1 Dlg4 differentiation Development and Gnao1 Dlg4 differentiation Vamp2 App Ywhae Ywhab Development and Psmd3 Rpgrip1l differentiation Psmd4 Hmga2 Development and Thy1 Syp differentiation Atp6v1a App Ywhae Ywhaz Ywhab Hsd3b7 Hsd3b4 Development and Tubb2a Ywhaz differentiation Nphp4 -

Supplementary Table 2
Supplementary Table 2. Differentially Expressed Genes following Sham treatment relative to Untreated Controls Fold Change Accession Name Symbol 3 h 12 h NM_013121 CD28 antigen Cd28 12.82 BG665360 FMS-like tyrosine kinase 1 Flt1 9.63 NM_012701 Adrenergic receptor, beta 1 Adrb1 8.24 0.46 U20796 Nuclear receptor subfamily 1, group D, member 2 Nr1d2 7.22 NM_017116 Calpain 2 Capn2 6.41 BE097282 Guanine nucleotide binding protein, alpha 12 Gna12 6.21 NM_053328 Basic helix-loop-helix domain containing, class B2 Bhlhb2 5.79 NM_053831 Guanylate cyclase 2f Gucy2f 5.71 AW251703 Tumor necrosis factor receptor superfamily, member 12a Tnfrsf12a 5.57 NM_021691 Twist homolog 2 (Drosophila) Twist2 5.42 NM_133550 Fc receptor, IgE, low affinity II, alpha polypeptide Fcer2a 4.93 NM_031120 Signal sequence receptor, gamma Ssr3 4.84 NM_053544 Secreted frizzled-related protein 4 Sfrp4 4.73 NM_053910 Pleckstrin homology, Sec7 and coiled/coil domains 1 Pscd1 4.69 BE113233 Suppressor of cytokine signaling 2 Socs2 4.68 NM_053949 Potassium voltage-gated channel, subfamily H (eag- Kcnh2 4.60 related), member 2 NM_017305 Glutamate cysteine ligase, modifier subunit Gclm 4.59 NM_017309 Protein phospatase 3, regulatory subunit B, alpha Ppp3r1 4.54 isoform,type 1 NM_012765 5-hydroxytryptamine (serotonin) receptor 2C Htr2c 4.46 NM_017218 V-erb-b2 erythroblastic leukemia viral oncogene homolog Erbb3 4.42 3 (avian) AW918369 Zinc finger protein 191 Zfp191 4.38 NM_031034 Guanine nucleotide binding protein, alpha 12 Gna12 4.38 NM_017020 Interleukin 6 receptor Il6r 4.37 AJ002942 -

Genomic and Transcriptome Analysis Revealing an Oncogenic Functional Module in Meningiomas
Neurosurg Focus 35 (6):E3, 2013 ©AANS, 2013 Genomic and transcriptome analysis revealing an oncogenic functional module in meningiomas XIAO CHANG, PH.D.,1 LINGLING SHI, PH.D.,2 FAN GAO, PH.D.,1 JONATHAN RUssIN, M.D.,3 LIYUN ZENG, PH.D.,1 SHUHAN HE, B.S.,3 THOMAS C. CHEN, M.D.,3 STEVEN L. GIANNOTTA, M.D.,3 DANIEL J. WEISENBERGER, PH.D.,4 GAbrIEL ZADA, M.D.,3 KAI WANG, PH.D.,1,5,6 AND WIllIAM J. MAck, M.D.1,3 1Zilkha Neurogenetic Institute, Keck School of Medicine, University of Southern California, Los Angeles, California; 2GHM Institute of CNS Regeneration, Jinan University, Guangzhou, China; 3Department of Neurosurgery, Keck School of Medicine, University of Southern California, Los Angeles, California; 4USC Epigenome Center, Keck School of Medicine, University of Southern California, Los Angeles, California; 5Department of Psychiatry, Keck School of Medicine, University of Southern California, Los Angeles, California; and 6Division of Bioinformatics, Department of Preventive Medicine, Keck School of Medicine, University of Southern California, Los Angeles, California Object. Meningiomas are among the most common primary adult brain tumors. Although typically benign, roughly 2%–5% display malignant pathological features. The key molecular pathways involved in malignant trans- formation remain to be determined. Methods. Illumina expression microarrays were used to assess gene expression levels, and Illumina single- nucleotide polymorphism arrays were used to identify copy number variants in benign, atypical, and malignant me- ningiomas (19 tumors, including 4 malignant ones). The authors also reanalyzed 2 expression data sets generated on Affymetrix microarrays (n = 68, including 6 malignant ones; n = 56, including 3 malignant ones). -

RRAD Expression in Gastric and Colorectal Cancer with Peritoneal
www.nature.com/scientificreports OPEN RRAD expression in gastric and colorectal cancer with peritoneal carcinomatosis Hee Kyung Kim1,4,5, Inkyoung Lee2,5, Seung Tae Kim1, Jeeyun Lee 1, Kyoung-Mee Kim3, Joon Oh Park1 & Won Ki Kang1* The role of Ras-related associated with diabetes (RRAD) in gastric cancer (GC) or colorectal cancer (CRC) has not been investigated. We aimed to investigate the biological and clinical roles of RRAD in GC and CRC and to assess RRAD as a therapeutic target. A total of 31 cancer cell lines (17 GC cell lines, 14 CRC cell lines), 59 patient-derived cells (PDCs from 48 GC patients and 11 CRC patients), and 84 matched pairs of primary cancer tissue and non-tumor tissue were used to evaluate the role of RRAD in vitro and in vivo. RRAD expression was frequently increased in GC and CRC cell lines, and siRNA/shRNA- mediated RRAD inhibition induced signifcant decline of tumor cell proliferation both in vitro and in vivo. A synergistic efect of RRAD inhibition was generated by combined treatment with chemotherapy. Notably, RRAD expression was markedly increased in PDCs, and RRAD inhibition suppressed PDC proliferation. RRAD inhibition also resulted in reduced cell invasion, decreased expression of EMT markers, and decreased angiogenesis and levels of associated proteins including VEGF and ANGP2. Our study suggests that RRAD could be a novel therapeutic target for treatment of GC and CRC, especially in patients with peritoneal seeding. Gastric cancer (GC) and colorectal cancer (CRC) are the most common gastrointestinal malignancies world- wide1. Despite declining incidence and advances in treatment, the prognosis of metastatic GC is poor, and GC is the second leading cause of cancer mortality2,3. -

Egfr Activates a Taz-Driven Oncogenic Program in Glioblastoma
EGFR ACTIVATES A TAZ-DRIVEN ONCOGENIC PROGRAM IN GLIOBLASTOMA by Minling Gao A thesis submitted to Johns Hopkins University in conformity with the requirements for the degree of Doctor of Philosophy Baltimore, Maryland March 2020 ©2020 Minling Gao All rights reserved Abstract Hyperactivated EGFR signaling is associated with about 45% of Glioblastoma (GBM), the most aggressive and lethal primary brain tumor in humans. However, the oncogenic transcriptional events driven by EGFR are still incompletely understood. We studied the role of the transcription factor TAZ to better understand master transcriptional regulators in mediating the EGFR signaling pathway in GBM. The transcriptional coactivator with PDZ- binding motif (TAZ) and its paralog gene, the Yes-associated protein (YAP) are two transcriptional co-activators that play important roles in multiple cancer types and are regulated in a context-dependent manner by various upstream signaling pathways, e.g. the Hippo, WNT and GPCR signaling. In GBM cells, TAZ functions as an oncogene that drives mesenchymal transition and radioresistance. This thesis intends to broaden our understanding of EGFR signaling and TAZ regulation in GBM. In patient-derived GBM cell models, EGF induced TAZ and its known gene targets through EGFR and downstream tyrosine kinases (ERK1/2 and STAT3). In GBM cells with EGFRvIII, an EGF-independent and constitutively active mutation, TAZ showed EGF- independent hyperactivation when compared to EGFRvIII-negative cells. These results revealed a novel EGFR-TAZ signaling axis in GBM cells. The second contribution of this thesis is that we performed next-generation sequencing to establish the first genome-wide map of EGF-induced TAZ target genes. -

White-Nose Syndrome Is Associated with Increased Replication of A
www.nature.com/scientificreports OPEN White-nose syndrome is associated with increased replication of a naturally persisting coronaviruses Received: 16 July 2018 Accepted: 9 October 2018 in bats Published: xx xx xxxx Christina M. Davy1,2, Michael E. Donaldson1, Sonu Subudhi 3, Noreen Rapin3, Lisa Warnecke4,5, James M. Turner4,6, Trent K. Bollinger7, Christopher J. Kyle8, Nicole A. S.-Y. Dorville4, Emma L. Kunkel4, Kaleigh J. O. Norquay4, Yvonne A. Dzal4, Craig K. R. Willis4 & Vikram Misra 3 Spillover of viruses from bats to other animals may be associated with increased contact between them, as well as increased shedding of viruses by bats. Here, we tested the prediction that little brown bats (Myotis lucifugus) co-infected with the M. lucifugus coronavirus (Myl-CoV) and with Pseudogymnoascus destructans (Pd), the fungus that causes bat white-nose syndrome (WNS), exhibit diferent disease severity, viral shedding and molecular responses than bats infected with only Myl-CoV or only P. destructans. We took advantage of the natural persistence of Myl-CoV in bats that were experimentally inoculated with P. destructans in a previous study. Here, we show that the intestines of virus-infected bats that were also infected with fungus contained on average 60-fold more viral RNA than bats with virus alone. Increased viral RNA in the intestines correlated with the severity of fungus-related pathology. Additionally, the intestines of bats infected with fungus exhibited diferent expression of mitogen-activated protein kinase pathway and cytokine related transcripts, irrespective of viral presence. Levels of coronavirus antibodies were also higher in fungal-infected bats. -

Systematic Elucidation of Neuron-Astrocyte Interaction in Models of Amyotrophic Lateral Sclerosis Using Multi-Modal Integrated Bioinformatics Workflow
ARTICLE https://doi.org/10.1038/s41467-020-19177-y OPEN Systematic elucidation of neuron-astrocyte interaction in models of amyotrophic lateral sclerosis using multi-modal integrated bioinformatics workflow Vartika Mishra et al.# 1234567890():,; Cell-to-cell communications are critical determinants of pathophysiological phenotypes, but methodologies for their systematic elucidation are lacking. Herein, we propose an approach for the Systematic Elucidation and Assessment of Regulatory Cell-to-cell Interaction Net- works (SEARCHIN) to identify ligand-mediated interactions between distinct cellular com- partments. To test this approach, we selected a model of amyotrophic lateral sclerosis (ALS), in which astrocytes expressing mutant superoxide dismutase-1 (mutSOD1) kill wild-type motor neurons (MNs) by an unknown mechanism. Our integrative analysis that combines proteomics and regulatory network analysis infers the interaction between astrocyte-released amyloid precursor protein (APP) and death receptor-6 (DR6) on MNs as the top predicted ligand-receptor pair. The inferred deleterious role of APP and DR6 is confirmed in vitro in models of ALS. Moreover, the DR6 knockdown in MNs of transgenic mutSOD1 mice attenuates the ALS-like phenotype. Our results support the usefulness of integrative, systems biology approach to gain insights into complex neurobiological disease processes as in ALS and posit that the proposed methodology is not restricted to this biological context and could be used in a variety of other non-cell-autonomous communication -

Supplementary Table 2: Infection-Sensitive Genes
Supplementary Table 2: Infection-Sensitive Genes Supplementary Table 2: Upregulated with Adenoviral Infection (pages 1 - 7)- genes that were significant by ANOVA as well as significantly increased in control compared to both 'infected control' (Ad-LacZ) and 'calcineurin infected' (Ad-aCaN). Downregulated with Adenoviral Infection (pages 7 - 13) as above except for direction of change. Columns: Probe Set- Affymetrix probe set identifier for RG-U34A microarray, Symbol and Title- annotated information for above probe set (annotation downloaded June, 2004), ANOVA- p-value for 1-way Analysis of Variance, Uninfected, Ad-LacZ and Ad- aCaN- mean ± SEM expression for uninfected control, adenovirus mediated LacZ treated control, and adenovirus mediated calcineurin treated cultures respectively. Upregulated with Adenoviral Infection Probe Set Symbol Title ANOVA Uninfected Ad-LacZ Ad-aCaN Z48444cds_at Adam10 a disintegrin and metalloprotease domain 10 0.00001 837 ± 31 1107 ± 24 1028 ± 29 L26986_at Adcy8 adenylyl cyclase 8 0.00028 146 ± 12 252 ± 21 272 ± 21 U94340_at Adprt ADP-ribosyltransferase 1 0.00695 2096 ± 100 2783 ± 177 2586 ± 118 U01914_at Akap8 A kinase anchor protein 8 0.00080 993 ± 44 1194 ± 65 1316 ± 44 AB008538_at Alcam activated leukocyte cell adhesion molecule 0.01012 2775 ± 136 3580 ± 216 3429 ± 155 M34176_s_at Ap2b1 adaptor-related protein complex 2, beta 1 subunit 0.01389 2408 ± 199 2947 ± 143 3071 ± 116 D44495_s_at Apex1 apurinic/apyrimidinic endonuclease 1 0.00089 4959 ± 185 5816 ± 202 6057 ± 158 U16245_at Aqp5 aquaporin 5 0.02710 -

Supplementary Data
Supplementary Information Supplementary Materials and Methods Multiple myeloma specimens Primary bone marrow samples from 116 MM patients and 12 patients without tumors were obtained from the 4th Department of Internal Medicine, Hiroshima Atomic-Bomb Survivors Hospital; the 1st Department of Internal Medicine, Sapporo Medical University Hospital; and the Department of Hematology, Teine Keijinkai Hospital after acquisition of informed consent from each patient. Mononuclear cells were separated from 99 samples using Ficoll-Paque (StemCell Technologies), after which we separated the CD138-positive cells using CD138 MicroBeads (Miltenyi Biotec). There were five patients whose bone marrow specimens were collected before and after treatment. All five of those patients received treatment with Dex. Of those five patients, three received bortezomib and Dex; one received vincristine, adriamysin and Dex; and one received melphalan and Dex followed by peripheral blood stem cell transplantation. Methylation analysis Combined bisulfite restriction analysis (COBRA) were performed as described previously (1). The PCR products were digested with the restriction endonuclease Hinf (TaKaRa) and precipitated with ethanol, after which the resultant DNA fragments were subjected to 2.5% agarose gel electrophoresis and stained with ethidium bromide. Bisulfite-pyrosequencing was carried out as described previously (2). The primers used for COBRA were also used for pyrosequencing. After PCR, the biotinylated PCR product was purified, made single-stranded, and used as a template in the pyrosequencing reaction. Briefly, the PCR products were bound to streptavidin sepharose beads HP (Amersham Biosciences), after which beads containing the immobilized PCR product were purified, washed, and denatured using a 0.2 mol/L NaOH solution. After addition of 0.3 μmol/L sequencing primer to the purified PCR product, pyrosequencing was carried out using a PSQ96MA system (Biotage) and Pyro Q-CpG software (Biotage).