How Will It End? OPERA As an Approach to Prediction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Character Breakdown BANZAI a Slick Yet Childish Hyena Who Works For
Character Breakdown BANZAI A slick yet childish hyena who works for Scar. He would be the leader of the group if hyenas weren't so lazy. Look for an outgoing and confident actor who can portray nastiness and gruffness. As Banzai is always featured with Shenzi and Ed, consider auditioning the hyenas in trios. Male or Female, Any Age ED The third member of Scar's trio of lackeys. He has a loud, cackling laugh that is his only form of communication. Ed should be played by an actor who can laugh unabashedly and communicate through physicality and facial expressions rather than words. This role can be played by a boy or girl. Male or Female, Any Age ENSEMBLE The ensemble plays various inhabitants of the Pridelands, such as giraffes, elephants, antelopes, wildebeest, and other creatures you choose to include. This group can have as few or as many performers as your production permits. There are also several moments to showcase individual dancers in "The Lioness Hunt" and "I Just Can't Wait to Be King." HYENAS Scar's army, helping carry out his evil plot to take over the Pridelands. Hyenas are mangy, mindless creatures who sing in "Be Prepared." Male or Female, Any Age LIONESSES The fierce hunters of the Pridelands and featured in "The Lioness Hunt," "The Mourning," and "Shadowland." Female, Any Age MUFASA The strong, honorable, and wise lion who leads the Pridelands. Mufasa should command respect onstage and also show tenderness with his son, Simba. Male, Any Age NALA Grows from a cub to a lioness before she confronts Scar, so cast a more mature actress to play the character beginning in Scene 10, As with older Simba and Young Simba, ensure that this switch in actors performing a single role is clear. -

Shakespeare for Life
Hamlet By William Shakespeare This lesson was inspired by the Macmillan Readers adaption of William Shakespeare’s original playscript. The language has been adapted and graded to make it suitable for readers at Intermediate level. It also features extracts of key speeches from the original text along with explanatory notes, plus glossaries and exercises designed to reinforce understanding post reading. The book is available with CD, as an audio book and as an eBook. Find out more here. • Order print books • Buy eBooks shakespeare for life www.macmillanreaders.com/shakespeare ©2016 Macmillan Education Hamlet TEACHEr’s NOTES LESSON OVERVIEW Level: Intermediate Length: Approximately 40 minutes Language focus: Expressions from Shakespeare’s Hamlet Learning objectives: In this lesson students complete a series of tasks that will help them to build their vocabulary and speaking skills. Students will have the chance to: • Gain an overview of the story of Hamlet and its characters • Learn a series of expressions from the play still in use today • Discuss ghosts and the supernatural and build related vocabulary • Read, analyse and practise reciting a famous speech from the play ContentS • Activity 1: Shakespeare’s Language • Activity 2: Speak Shakespeare Additional Activities: • Themed Discussion • Vocabulary Task HAMLET: TEACHER’S NOTES HAMLET: TEACHER’S shakespeare for life www.macmillanreaders.com/shakespeare ©2016 Macmillan Education Hamlet OVERVIEW OF the PLAy Key themes: Mortality, madness, ghosts, the supernatural and revenge Key characters: • Hamlet: The tragic hero of the play. Hamlet is Prince of Denmark and the son of Queen Gertrude and the late King Hamlet. Bitter and cynical and full of hatred for his Uncle Claudius. -

Redalyc.DISNEY's “WAR EFFORTS”: the LION KING and EDUCATION
Ilha do Desterro: A Journal of English Language, Literatures in English and Cultural Studies E-ISSN: 2175-8026 [email protected] Universidade Federal de Santa Catarina Brasil Modenessi, Alfredo Michel DISNEY’S “WAR EFFORTS”: THE LION KING AND EDUCATION FOR DEATH, OR SHAKESPEARE MADE EASY FOR YOUR APOCALYPTIC CONVENIENCE Ilha do Desterro: A Journal of English Language, Literatures in English and Cultural Studies, núm. 49, julio-diciembre, 2005, pp. 397-415 Universidade Federal de Santa Catarina Florianópolis, Brasil Available in: http://www.redalyc.org/articulo.oa?id=478348687019 How to cite Complete issue Scientific Information System More information about this article Network of Scientific Journals from Latin America, the Caribbean, Spain and Portugal Journal's homepage in redalyc.org Non-profit academic project, developed under the open access initiative Disney's "War efforts": The Lion King and... 397 DISNEY’S “WAR EFFORTS”: THE LION KING AND EDUCATION FOR DEATH, OR SHAKESPEARE MADE EASY FOR YOUR APOCALYPTIC CONVENIENCE Alfredo Michel Modenessi Universidad Nacional Autónoma de México [...]circumstances are incalculable in the manner in which they come about, even if apocalyptically or politically foreseen, and the identity of the vital individuals and objects is hidden by their humble or frivolous role in an habitual set of circumstances. Nadine Gordimer, July’s People I. “Who is here so rude that would not be a Roman?” “‘Peace, ho! Brutus speaks.’ And speaks. And speaks. And except for a couple of fatal blows that he somewhat misplaces in the bodies of his “best lover[s]” (i.e. Caesar and himself), he hardly does anything but deliver speeches. -
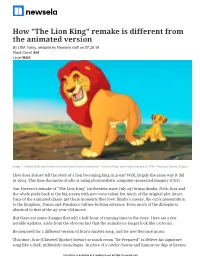
How "The Lion King" Remake Is Different from the Animated Version by USA Today, Adapted by Newsela Staff on 07.29.19 Word Count 854 Level MAX
How "The Lion King" remake is different from the animated version By USA Today, adapted by Newsela staff on 07.29.19 Word Count 854 Level MAX Image 1. Mufasa (left) and Simba in a scene from Disney's animated "The Lion King" which was released in 1994. Photo by: Disney Studios How does Disney tell the story of a lion becoming king in 2019? Well, largely the same way it did in 1994. This time the movie studio is using photorealistic computer-generated imagery (CGI). Jon Favreau's remake of "The Lion King" (in theaters since July 19) brings Simba, Nala, Scar and the whole pride back to the big screen with new voice talent but much of the original plot intact. Fans of the animated classic get those moments they love: Simba's sneeze, the cub's presentation to the kingdom, Timon and Pumbaa's vulture-kicking entrance. Even much of the dialogue is identical to that of the 25-year-old movie. But there are some changes that add a half-hour of running time to the story. Here are a few notable updates, aside from the obvious fact that the animals no longer look like cartoons. Be prepared for a different version of Scar's sinister song, and for new Beyoncé music. This time, Scar (Chiwetel Ejiofor) doesn't so much croon "Be Prepared" as deliver his signature song like a dark, militaristic monologue. In place of a catchy chorus and humorous digs at hyenas This article is available at 5 reading levels at https://newsela.com. -

TEACHING IMAGE PATTERNS in HAMLET HILARY SEMPLE, Former Lecturer at the University of the Witwatersrand
TEACHING IMAGE PATTERNS IN HAMLET HILARY SEMPLE, former lecturer at the University of the Witwatersrand (originally published in CRUX, May 1993) In her fascinating study of Shakespeare’s imagery Caroline Spurgeon writes: The greater and richer the work the more valuable and suggestive become the images, so that in the case of Shakespeare I believe one can scarcely overrate the possibilities of what may be discovered through a systematic examination of them.' A systematic examination involving complete coverage is not possible in class or tutorial room, but many of the difficulties experienced by pupils or students in the study of Hamlet may be resolved by an analysis of some or the main image patterns in the play. First, the question, ‘what is an image?’ needs to be addressed, and the answer need not be one of great sophistication or subtlety. Many literary glossaries give the teacher a variety of definitions with which to work. The students need to grasp the fundamental idea that the dramatist creates many ‘mental pictures’ 2 in order to present ideas and concepts descriptively"3. After the group has agreed on a few working definitions of the image, pupils or students should be invited to create their own mental picture — to visualize a train travelling rapidly, kept on track, and given direction by its rails. This is to be kept in mind as a rough analogy for the movement of the play, which is kept ‘on track‘ and given direction by the image patterns created by the dramatist. In other words, the image patterns support and accompany the play’s action and plot like the rails do a train. -

NCTC- Lkaudition Packet Copy
AUDITIONS MARCH 22 & 23, by appointment FREQUENTLY ASKED QUESTIONS HOW OLD DO I HAVE TO BE TO AUDITION? To audition for the full cast, you must be eight years old by the closing performance. If you have participated in five (5) or more IN PERFORMANCE classes, you may be eligible to audition for the full cast. YOUNGER THAN 8? Children ages 5-8, check out our IN PERFORMANCE: DISNEY’S THE LION KING EXPERIENCE JR class beginning in May. While you may not having speaking lines, you will still have an opportunity to be in the production. WHEN ARE THE AUDITIONS? Auditions are March 22 & 23, by appointment. DO I HAVE TO MAKE AN APPOINTMENT TO AUDITION? Yes. Either schedule your audition online at www.NCTCArts.org. Appointments will last between 5-10 minutes. Appointments begin at 4:30pm on both days. WHERE WILL THE AUDITIONS, REHEARSALS AND PERFORMANCES TAKE PLACE? NCTC Performing Arts Theatre located at 743 North Mountain Road in Newington. IʼVE NEVER DONE THIS BEFORE, CAN I STILL AUDITION? Yes! In each of our productions, we have both children who have had stage experience and children who have not. DO MY PARENTS/FRIENDS WATCH MY AUDITION? No. We ask that all family and friends wait in the lobby during your audition. You will audition for the director and stage manager. WHAT DO I NEED TO PREPARE FOR MY AUDITION? Please make sure to fill out the audition form completely, attach a recent picture of yourself (size of picture doesnʼt matter-as long as we can see your face) and bring with you to your audition appointment. -

1 | Hudson Valley Shakespeare Festival
1 | HUDSON VALLEY SHAKESPEARE FESTIVAL TABLE OF CONTENTS OUR MISSION AND SUPPORTERS EDUCATION DIRECTOR’S STATEMENT PART ONE: SHAKESPEARE’S LIFE AND TIMES William Shakespeare Shakespeare’s England The Elizabethan and Jacobean Stage PART TWO: THE PLAY Plot Summary Who is Who: The Cast The Origins of the Play Themes A Genre Play: Revenge Tragedy or Tragedy? PART THREE: WORDS, WORDS, WORDS By the Numbers Shakespeare’s Language States, Syllables, Stress Feet + Metre = Scansion Metrical Stress vs. Natural Stress PART FOUR: HVSF PRODUCTION Note from the Director Doubling Hamlet: Full Text Vs. The HVSF Cut What to Watch For: Themes and Questions to Consider Theatre Etiquette PART FIVE: CLASSROOM ACTIVITIES Activities That Highlight Language Activities That Highlight Character Activities That Highlight Scene Work PART SIX: Hamlet RESOURCES 2 | HUDSON VALLEY SHAKESPEARE FESTIVAL HUDSON VALLEY SHAKESPEARE FESTIVAL OUR MISSION AND SUPPORTERS Founded in 1987, the Hudson Valley Shakespeare Festival's mission is to engage the widest possible audience in a fresh conversation about what is essential in Shakespeare’s plays. Both in production and in the classroom, our theater lives in the present moment, at the intersection of the virtuosity of the actor, the imagination of the audience, and the inspiration of the text. HVSF’s primary home is a spectacular open-air theater tent at Boscobel House and Gardens in Garrison, NY. Every summer, more than 35,000 patrons join us there for a twelve-week season of plays presented in repertory, with the natural beauty of the Hudson Highlands as our backdrop. HVSF has produced more than 50 classical works on our mainstage. -

The Lion King Monologues
THE LONE KING MONOLOGUES LAST WEEK – VOCAL SKILLS • Pace • Pitch • Power • Pause • Pronunciation THIS WEEK Monologues – VOCAL SKILLS • Space • Levels • Facial Expression • Body Language Zazu – The Lion King Oh, just look at you two. Little seeds of romance blossoming in the savannah. Your parents will be thrilled… what with your being betrothed and all. {trying to explain} Betrothed. Intended. Affianced. One day you two are going to be married! {beat} Well, sorry to bust your bubble, but you two turtle doves have no choice. It’s a tradition… going back generations. {beat} Oh, you can’t fire me. Only a king can do that. You’re not a king yet. And with an attitude like that, I'm afraid you’re shaping up to be a pretty pathetic king indeed. If this is where the monarchy is headed count me out! Out of service, out of Africa, I wouldn't hang about! Young Simba – The Lion King Hey Uncle Scar, guess what! I'm going to be king of Pride Rock. My Dad just showed me the whole kingdom, and I'm going to rule it all. Heh heh. I’m gonna be a mighty king so enemies beware. I’m working on my roar. Here, listen! Roar!! I can’t wait to be king! No one bossing me around… Free to play all day... Free to do it all my way! Hey, Uncle Scar? When I'm king, what will that make you? Mufasa – The Lion King Look Simba. Everything the light touches is our kingdom. A king's time as ruler rises and falls like the sun. -

July 31-August 2 in Consideration of Other Patrons
Music and Lyrics by Elton John & Tim Rice Additional Music and Lyrics by Lebo M, Mark Mancina, Jay Rifkin, and Hans Zimmer Book by Roger Allers & Irene Mecchi Based on the Broadway production directed by Julie Taymor Music Adapted & Arranged and Additional Music & Lyrics and “Luau Hawaiian Treat” written by Will Van Dyke “It’s a Small World” written by Richard M. Sherman and Robert B. Sherman Director Meredith Vandre Assistant Director Nora Wickman July 31-August 2 In Consideration of Other Patrons... • Please turn off or silence all cell phones. • Please do not text during the production. • Thank you for your patronage and polite considera- tion. • Maintain 6’ of social distance at all times • Face coverings over the nose and mouth should be worn at all times when not seated • Concessions will not be available • Bring your own lawn chair and/or blanket And enjoy the show! Cast Cast…………………………………………………………………………………………………………….Role Kaelin Baird……………………………………………………………………………………………………………..Scar Emerson Carter…………………………………………………………………………………………….Young Nala Riley Carter….……………………………………………………………………………………………………..Lioness Angela D’Andrea………………………………………………………………………………………………..Mufasa Madison Herlehy…………………………………………………………………………………………………….Nala Elise Hocevar…………………………………………….……………………………………………………………….Ed Luke Hogan…………………………………………………………………………………………………………..Simba Tyler Hogan…………………………………………………………………………………………………………….Zazu Zoe Hogan……………………………….…………………………………………………………………………….Rafiki Jeannie Hughes………………………………………………………………………..………………Young Simba Ava Ludwig………………………………………………………………………..………………………………Sarafina -

Hamlet 1/31/01 Cx and © Web Copy
HAMLET PRINCE OF DENMARK Adapted by Peggy L. Anderson & Judith D. Anderson High Noon Books A division of Academic Therapy Publications 20 Commercial Boulevard Novato, CA 94949-6191 www.HighNoonBooks.com Table of Contents About William Shakespeare . .v The Story . .7 Prologue . .9 Act I . .11 Act II . .25 Act III . .31 Act IV . .41 Act V . .53 The Play . .63 Cast of Characters . .65 Act I . .67 Act II . .81 Act III . .87 Act IV . .99 Act V . .115 Globe Theatre . .125 About the Editors . .127 ABOUT WILLIAM SHAKESPEARE (1564-1616) illiam Shakespeare was born in Stratford-upon- Avon, a market town about eighty miles Wnorthwest of London. His father was a glovemaker and a trader in wool, hides, and grain. The family, which had eight children, while not rich, led a comfortable life. William was the third child in the family, and it is thought that he attended the Stratford grammar school where classes started at six or seven in the morning and lasted until five or six in the late afternoon. When the family’s finances declined, it became necessary for him to leave school to go to work for a local tradesman. He married Anne Hathaway when he was eighteen and she was twenty-six. They had three children, including twins. It is not known exactly when or why Shakespeare left Stratford and moved to London where he quickly became involved in the theater both as an actor and a playwright. Theaters in London were closed from 1592 to 1594 because of the terrifying plague that swept throughout Europe, so Shakespeare spent his time writing plays and publishing two long narrative poems that immediately became popular and started him on the road to fame. -

Deconstructing Walt Disney's the Lion King
Deconstructing Walt Disney’s The Lion King By Vicky Wong Spring 1999 Issue of KINEMA DECONSTRUCTING THE WALT DISNEY ANIMATION THE LION KING: ITS IDEOL- OGY AND THE PERSPECTIVE OF HONG KONG CHINESE Walt Disney’s animations have always been popular, largely of course due to their aesthetic appeal, vivid characters, interesting plots, and for the parents, obvious moral standards that save their time teaching their children. The artifact this paper is going to study is one of Disney’s most popular animation The Lion King released in 1994 both in the US and in Hong Kong. The film broke all records in the first weekend, grossing USD42 million. It was similarly popular when it was released in Hong Kong during the summer vacation in the same year. Simply put, the story is about how a regal lion is victimised by his uncle: experiences an exile and a life free from responsibility: free by whim or by chance, when he grows up, meets up with his friend and goes through a period of identity crisis and introspection: and finally, the lion gains back his throne by challenging the illegitimate king, his uncle. Though in the form of an animation which one would naturally think is dedicated to children, and which is generally thought of as being surrealistic, which at most contain moral lessons. The Lion King, in analysis, is more than a fable. I will argue that The Lion King should ”rightfully” (a term often appears in the script as we will discuss later) be an adult’s film. Hinson (1994) said, ”Of the 32 animated films Disneyhas produced, this story of a young African lion’s search for identity is not only more mature in its themes, it is also the darkest and the most intense. -

Touring Spring 2020 Across the State of Washington by William Shakespeare | Directed by Ana María Campoy
Touring Spring 2020 Across The State of Washington By William Shakespeare | Directed by Ana María Campoy All original material copyright © 2020 Seattle Shakespeare Company CONTENT HAMLET Welcome Letter..........................................................................1 Plot and Characters...................................................................2 Articles Why Bilingual Shakespeare?................................................................3 About William Shakespeare.................................................................4 Theater Audiences: Then and Now.....................................................5 Educator Resource Guide Resource Educator At a Glance Modern Shakespeare Adaptations......................................................7 About the Play.......................................................................................8 Themes in Hamlet.................................................................................9 Soliloquies....................................................................................11 Our Production Director’s Notes..................................................................................12 Central Components of a Día de los Muertos Ofrenda/Altar............14 Activities Cross the Line: Quotes........................................................................15 Compliments and Insults...................................................................16 Cross the Line: Themes......................................................................17