Information Disorders on Italian Facebook During COVID-19 Infodemic
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

La Nuova Guida Completa 2021
GLI SPECIALI Bonus 1LA10% NUOVA GUIDA COMPLETA 2021 I LIBRI DEL SOLE 24 ORE NON VENDIBILE SEPARATAMENTE Pubblicazione settimanale con Il Sole 24 ORE Solo ed esclusivamente per gli abbonati € 2,50 (I Libri del Sole 24 ORE € 0,50 + Il Sole 24 ORE € 2,00) in vendita separata dal quotidiano a € 0,50 BONUS 110% IL SOLE 24 ORE I prodotti in vetrina Direttore responsabile Smart24 Condominio Fabio Tamburini Il sistema informativo più completo e Progetto e coordinamento approfondito per il mondo del condomi- editoriale Saverio Fossati nio e per la gestione immobiliare. Smart24 Condominio offre in materia ad A cura di amministratori di condominio, consulen- Enrico Bronzo, Annarita D’Ambrosio e ti, società e agenzie immobiliari tutto il Giuseppe Latour patrimonio documentale del Gruppo 24 Testi di Ore. Per scoprire di più: Andrea Barocci, smart24condominio.it Alessandro Borgoglio, Andrea Cartosio, Fabio Chiesa, Eugenio Correale, Augusto Consulente Immobiliare Cirla, Luca De Stefani, Il quindicinale che consente di muoversi Rosario Dolce, Giorgio Gavelli, con sicurezza nel settore immobiliare e Giampiero Gugliotta, dell'edilizia. Silvio Rivetti, Luca Rollino, Condominio, locazione, catasto, Fabio Sandrini, proprietà, risparmio energetico, Guglielmo Saporito, Gian Paolo Tosoni procedure edilizie sono solo alcuni degli argomenti affrontati. Per scoprire di più su I Libri del Sole ORE Settimanale N. / “Consulente Immobiliare”: – Febbraio Registrazione Tribunale di Milano offerte.ilsole24ore.com/ci n. del -- Direttore responsabile: Fabio Tamburini Proprietario ed Editore: Quotidiano del Sole 24 ORE - Condominio Il Sole ORE S.p.A. Sede legale, redazione Fornisce ogni giorno il quadro aggiornato e direzione: Via Monte Rosa di tutte le novità sul mondo immobiliare e n. -

Raffaello a Foligno
Rassegna Stampa RAFFAELLO A FOLIGNO Agenzie 1. Agi 2. Agi 3. MFDJ 4. Adnkronos 5. Asca 6. ITALPRESS 7. Il Velino 8. Agi 9. Agi 10. Agi 11. Adnkronos 12. Italpress 13. Il Velino 14. Asca 15. Tmnews 16. MF-DJ 17. Adnkronos 18. Ag 19. Agi 20. Agi 21. Ansa 22. Ansa Quotidiani e periodici 23. Il Sole 24 Ore 24. Il Giornale 25. Il Messaggero Umbria 26. Il Messaggero Umbria 27. Il Messaggero Umbria 28. La Nazione Umbria 29. La Nazione Umbria 30. Avvenire 31. Corriere Umbria 32. Corriere Umbria 33. Corriere Umbria 34. Corriere Umbria 35. Corriere Umbria 36. Corriere Umbria 37. Giornale Umbria 38. Corriere Umbria 39. Giornale dell’Umbria 40. Corriere Umbria 41. La Nazione Umbria 42. Il Giorno Milano 43. La Repubblica Milano 44. Il Giornale Milano 45. Il Corriere della Sera 46. Il Giorno Milano 47. Libertà 48. Corriere di Como 49. Il Messaggero 50. Il Tempo 51. La Stampa 52. QN 53. Il Messaggero Umbria 54. Corriere dell’Umbria 55. La Nazione Umbria 56. Il Mondo 57. Il Giornale dell’Umbria 58. La Nazione Umbria 59. Il Messaggero Umbria 60. Il Corriere della Sera 61. Libero 62. Italia Oggi 63. Il Giornale dell’Umbria 64. Il Messaggero 65. Il Messaggero – Umbria 66. La Nazione Umbria 67. La Nazione Umbria 68. L’Unità 69. Il Giornale 70. Il Messaggero 71. La Repubblica 72. Il Sole – domenicale 73. QN 74. Corriere dell’Umbria 75. Corriere dell’Umbria 76. Il Giornale Umbria 77. Il Messaggero Umbria 78. La Nazione Umbria 79. Pubblico Today 80. La Stampa 81. -

International Press
International press The following international newspapers have published many articles – which have been set in wide spaces in their cultural sections – about the various editions of Europe Theatre Prize: LE MONDE FRANCE FINANCIAL TIMES GREAT BRITAIN THE TIMES GREAT BRITAIN LE FIGARO FRANCE THE GUARDIAN GREAT BRITAIN EL PAIS SPAIN FRANKFURTER ALLGEMEINE ZEITUNG GERMANY LE SOIR BELGIUM DIE ZEIT GERMANY DIE WELT GERMANY SUDDEUTSCHE ZEITUNG GERMANY EL MUNDO SPAIN CORRIERE DELLA SERA ITALY LA REPUBBLICA ITALY A NEMOS GREECE ARTACT MAGAZINE USA A MAGAZINE SLOVAKIA ARTEZ SPAIN A TRIBUNA BRASIL ARTS MAGAZINE GEORGIA A2 MAGAZINE CZECH REP. ARTS REVIEWS USA AAMULEHTI FINLAND ATEATRO ITALY ABNEWS.RU – AGENSTVO BUSINESS RUSSIA ASAHI SHIMBUN JAPAN NOVOSTEJ ASIAN PERFORM. ARTS REVIEW S. KOREA ABOUT THESSALONIKI GREECE ASSAIG DE TEATRE SPAIN ABOUT THEATRE GREECE ASSOCIATED PRESS USA ABSOLUTEFACTS.NL NETHERLANDS ATHINORAMA GREECE ACTION THEATRE FRANCE AUDITORIUM S. KOREA ACTUALIDAD LITERARIA SPAIN AUJOURD’HUI POEME FRANCE ADE TEATRO SPAIN AURA PONT CZECH REP. ADESMEUFTOS GREECE AVANTI ITALY ADEVARUL ROMANIA AVATON GREECE ADN KRONOS ITALY AVLAIA GREECE AFFARI ITALY AVLEA GREECE AFISHA RUSSIA AVRIANI GREECE AGENZIA ANSA ITALY AVVENIMENTI ITALY AGENZIA EFE SPAIN AVVENIRE ITALY AGENZIA NUOVA CINA CHINA AZIONE SWITZERLAND AGF ITALY BABILONIA ITALY AGGELIOF OROS GREECE BALLET-TANZ GERMANY AGGELIOFOROSTIS KIRIAKIS GREECE BALLETTO OGGI ITALY AGON FRANCE BALSAS LITHUANIA AGORAVOX FRANCE BALSAS.LT LITHUANIA ALGERIE ALGERIA BECHUK MACEDONIA ALMANACH SCENY POLAND -

Servizio Della Biblioteca
ASSEMBLEA REGIONALE SICILIANA SERVIZIO DELLA BIBLIOTECA GIORNALI CORRENTI E CESSATI POSSEDUTI DALLA BIBLIOTECA Elenco in ordine alfabetico di titolo* Aggiornato a luglio 2020 TITOLO CONSISTENZA L’AGRICOLTURA MECCANIZZATA. Mensile 1955-1965 d'informazioni, tecnico, commerciale, sindacale, amministrativo, fiscale, a cura della Cooperativa trebbiatori. L’AMICO DEL POPOLO. Settimanale cattolico. 1957-1959 L’AMICO DEL POPOLO Si pubblica tutti i giorni di 1875-1881 mattina. L'APE IBLEA. Giornale per tutti [poi La Sicilia 1/1/1869-31/12/1870 cattolica]. L’ARTIGIANATO D’ITALIA. Organo della 10/1/1953-30/11/1986 Confederazione generale dell'artigianato d'Italia. L’ARTIGIANATO TRAPANESE. Organo mensile 1/1/1954-31/12/1955; 6/3/1957- dell'Associazione provinciale degli artigiani. 30/10/1958 ASSO DI BASTONI. Settimanale satirico 11/7/1948-17/10/1954 anticanagliesco. ATENEO PALERMITANO. Periodico dell'Università 1952-1956 degli studi di Palermo. AVANTI! 1949-1993 AVVENIRE [già Avvenire d’Italia]. 4/12/1968- L’AVVENIRE D’ITALIA [poi Avvenire]. 23/6/1911; 28/12/1911; 2/1/1965-1968 AVVISATORE. Settimanale commerciale - agricolo - 5/1/1946-31/12/1986 industriale - marittimo. L’AZIONE. 16/1/1915; 24/12/1915 AZIONE SINDACALE. Organo della Confederazione 8/1951-10/1952 italiana sindacati nazionali lavoratori. BANDIERA AZZURRA. Periodico monarchico di 16/7/1948-8/10/1949 opposizione BANDIERA ROSSA. Organo dei gruppi comunisti 15/01/1965-15/12/1966 rivoluzionari. BOLLETTINO DEI LAVORI E DEGLI APPALTI 1956-1974 DELLA CASSA PER IL MEZZOGIORNO. BULLETIN DE L'ÉXECUTIF ÉLARGI DE 12/7/1924 * Titoli ordinati parola per parola; in caso di titoli uguali si ordina secondo il sottotitolo; l’articolo iniziale non viene preso in considerazione. -

Catalogo Emeroteca
SEGRETARIATO GENERALE DELLA PRESIDENZA DELLA REPUBBLICA BIBLIOTECA QUIRINALE EMEROTECA Catalogo ________ novembre 2011 SEGRETARIATO GENERALE DELLA PRESIDENZA DELLA REPUBBLICA BIBLIOTECA EMEROTECA Catalogo _________ Novembre 2011 A cura di Pierpaolo Capelli Biblioteca Quirinale Biblioteca Quirinale INDICE ___________________________________________________ PREMESSA p. 1 TESTATE STORICHE Aretusa p. 5 Critica Sociale p. 6 (Il) Contemporaneo p. 7 Fanfulla della Domenica p. 8 (La) Fiera Letteraria p. 9 Gazzetta Piemontese p. 10 Giornali Clandestini (raccolta di) p. 11 Giovine Italia p. 12 (L’)Italia del Popolo p. 13 Lacerba p. 14 Leonardo p. 15 (Il) Marzocco p. 16 (Il) Repubblicano Piemontese p. 17 (La) Riforma p. 18 Roma Futurista p. 19 (La) Ronda p. 20 Solaria p. 21 (La) Voce p. 22 TESTATE CORRENTI Corriere della Sera p. 25 (L’)Espresso p. 26 (Il) Giornale p. 27 (Il) Giorno p. 28 (L’)Indipendente p. 29 (Il) Messaggero p. 30 - I - Biblioteca Quirinale (Le) Monde p. 31 (Il) Mondo p. 32 (La) Nazione p. 33 (L’)Osservatore Romano p. 34 Panorama p. 35 (La) Repubblica p. 36 (Il) Sole 24 ore p. 37 (La) Stampa p. 38 (Il) Tempo p. 30 (L’)Unità p. 40 - II Biblioteca Quirinale Premessa Il presente Catalogo offre una rassegna delle testate giornalistiche possedute dalla Biblioteca del Quirinale nella sua sezione “Emeroteca”, conservate esclusivamente in formato elettronico, ottico o digitale. La raccolta è costituita sia da testate ancora in corso di abbonamento che da testate spente, addirittura ‒ in taluni casi – di carattere prettamente storico in quanto risalenti al XVIII ed al XIX secolo; è stata per questa ragione realizzata una suddivisione in due sezioni ‒ l’una corrente, l’altra storica ‒ del materiale posseduto. -

Rapporto 2019 Sull'industria Dei Quotidiani in Italia
RAPPORTO 2019 RAPPORTO RAPPORTO 2019 sull’industria dei quotidiani in Italia Il 17 dicembre 2012 si è ASSOGRAFICI, costituito tra AIE, ANES, ASSOCARTA, SLC-‐CGIL, FISTEL-‐CISL e UILCOM, UGL sull’industria dei quotidiani in Italia CHIMICI, il FONDO DI ASSISTENZA SANITARIA INTEGRATIVA “Salute Sempre” per il personale dipendente cui si applicano i seguenti : CCNL -‐CCNL GRAFICI-‐EDITORIALI ED AFFINI -‐ CCNL CARTA -‐CARTOTECNICA -‐ CCNL RADIO TELEVISONI PRIVATE -‐ CCNL VIDEOFONOGRAFICI -‐ CCNL AGIS (ESERCENTI CINEMA; TEATRI PROSA) -‐ CCNL ANICA (PRODUZIONI CINEMATOGRAFICHE, AUDIOVISIVI) -‐ CCNL POLIGRAFICI Ad oggi gli iscritti al Fondo sono circa 103 mila. Il Fondo “Salute Sempre” è senza fini di lucro e garantisce agli iscritti ed ai beneficiari trattamenti di assistenza sanitaria integrativa al Servizio Sanitario Nazionale, nei limiti e nelle forme stabiliti dal Regolamento Attuativo e dalle deliberazioni del Consiglio Direttivo, mediante la stipula di apposita convenzione con la compagnia di assicurazione UNISALUTE, autorizzata all’esercizio dell’attività di assicurazione nel ramo malattia. Ogni iscritto potrà usufruire di prestazioni quali visite, accertamenti, ricovero, alta diagnostica, fisioterapia, odontoiatria . e molto altro ancora Per prenotazioni: -‐ www.unisalute.it nell’area riservata ai clienti -‐ telefonando al numero verde di Unisalute -‐ 800 009 605 (lunedi venerdi 8.30-‐19.30) Per info: Tel: 06-‐37350433; www.salutesempre.it Osservatorio Quotidiani “ Carlo Lombardi ” Il Rapporto 2019 sull’industria dei quotidiani è stato realizzato dall’Osservatorio tecnico “Carlo Lombardi” per i quotidiani e le agenzie di informazione. Elga Mauro ha coordinato il progetto ed ha curato la stesura dei testi, delle tabelle e dei grafici di corredo e l’aggiornamento della Banca Dati dell’Industria editoriale italiana La versione integrale del Rapporto 2019 è disponibile sul sito www.ediland.it Osservatorio Tecnico “Carlo Lombardi” per i quotidiani e le agenzie di informazione Via Sardegna 139 - 00187 Roma - tel. -

Valutazione Qualitativa Di Un Anno Di Rassegna Stampa Di Ateneo - 2010
Valutazione qualitativa di un anno di rassegna stampa di Ateneo - 2010 A cura del Portavoce del Rettore Simone Mazzucca, con la collaborazione di Andrea Visentin (stagista) Si ringrazia: Tamara Mendelevich, Sonia Lanza, Alberto Garoscio [Segreteria particolare del Rettore, portavoce e relazioni esterne] • Simonetta Cartaregia, Ilaria Portento [Servizio Comunicazione] • Valentina Pollio [Servizio Statistico, programmazione e valutazione] •!Maximilian Rizzardi [Servizio attività negoziale] • Centro stampa Università degli Studi di Genova Valutazione qualitativa Fonte degli articoli:! estratto giornaliero della rassegna stampa di Ateneo, ! sezione “ATENEO GENOVESE” Periodo: da gennaio 2010 a dicembre 2010. Analisi su alcune principali testate: Analisi su altre testate: • Il Manifesto • Il Mattino • Il Secolo XIX • Ancora • IL Messaggero • La Repubblica • Avanti • Il Potere • Il Corriere Mercantile • Avvenire • Il Resto del Carlino • Il Giornale • Avvisatore marittimo • Il Riformista • La Stampa • Cittadino di Genova • Il Secolo d'Italia • Il Sole 24 Ore NordOvest • City Genova • Il Tempo • Corriere della Sera • ItaliaOggi • Dnews • L’Unità • Donna Moderna • La gazzetta di Bari • Eco della riviera • La Nazione • Economy • La Padania • E-polis • Leggo • Espresso • Liberal • Europa • Liberazione • Fatto Quotidiano • Libero • Gazzetta del Lunedi • Liguria Business Journal • Gazzetta del Mezzogiorno • Metro Genova • Gazzetta dello Sport • Opinione • Genova Impresa • Ore 12 • Genova24 • Panorama • Il Clandestino • Soldi • Il Foglio • Terra Valutazione qualitativa e quantitativa di un anno di rassegna stampa di Ateneo - 2010 Università degli Studi di Genova Totale articoli in termini assoluti Il Secolo XIX 1402 La Repubblica 485 Il Corriere Mercantile 743 Il Giornale 159 La Stampa 465 Il Sole 24 Ore - NordOvest 66 Altre Testate 445 Totale 3765 Il totale degli articoli riguardante l’Ateneo genovese nell’anno 2010 è di 3765. -

Allegato 1 Del Decreto Linee Guida APE; Vi
GLI SPECIALI BONUS 11% Il Codice Le regole da sapere I provvedimenti per professionisti attuativi di ministeri e contribuenti e agenzia delle Entrate 00024 I LIBRI DEL SOLE 24 ORE NON VENDIBILE SEPARATAMENTE Pubblicazione settimanale con Il Sole 24 ORE Solo ed esclusivamente per gli abbonati € 2,50 (I Libri del Sole 24 ORE € 0,50 + Il Sole 24 ORE € 2,00) in vendita separata dal quotidiano a € 0,50 9 771973 564394 BONUS 110% IL CODICE L’offerta del Gruppo 24ORE Direttore responsabile Fabio Tamburini Forum gratuiti dall’Esperto risponde Progetto Sul sito del Sole 24 Ore, nella sezione e coordinamento dell'Esperto risponde, i Forum sul 110%, editoriale Jean Marie Del Bo consultabili gratuitamente. Allo stesso Mauro Meazza indirizzo la banca dati della rubrica, con Hanno collaborato centinaia di migliaia di casi risolti e un motore Giacomo Bagnasco di ricerca per le interrogazioni. Luca De Stefani www.espertorisponde.ilsole24ore.com Testi di questo numero Jean Marie Del Bo Luca De Stefani «24+», riservato agli abbonati Mauro Meazza Su «24+», la sezione premium del sito del Sole 24 Ore riservata agli abbonati, le «Bussole» sul 110% e la Guida con do- mande e risposte diffusa con il quotidia- no il 22 luglio. Ogni giorno la sezione presenta appro- fondimenti, inchieste, infografiche e podcast per seguire e comprendere I Libri del Sole ORE l'attualità economica e finanziaria. Settimanale N. / – Agosto abbonamenti.ilsole24ore.com Registrazione Tribunale di Milano n. del -- Direttore responsabile: Fabio Tamburini Voci e podcast di Radio24 Proprietario ed Editore: Il Sole ORE S.p.A. Su Radio24, ogni giorno, attualità e appro- Sede legale, redazione e direzione: fondimenti proseguono anche in agosto. -

Lawyers, European Law, and the Contentious Transformation of the Port of Genoa
From Marx to Market: Lawyers, European Law, and the Contentious Transformation of the Port of Genoa Accepted for publication, Law & Society Review Tommaso Pavone* What happens when international courts are asked to tackle local political controversies and their judgments subsequently spark contentious resistance? In the European Union (EU), scholars have posited that the politicization of the often– liberalizing rulings of the European Court of Justice (ECJ) provokes Euroscepticism and non–compliance. In contrast, I argue that contentious politics may also produce permissive conditions for Europeanist cause lawyers to promote awareness of EU law and mobilize support for liberalization. To unpack this claim, I conduct an intensive case study of perhaps the most explosive controversy in Italy to generate litigation before the ECJ: The 1991 “Port of Genoa” case, where the public monopoly rights of a centuries–old dockworkers’ union were challenged. Leveraging interviews, court and newspaper records, public opinion data, and litigation statistics, I trace how –– despite dockworkers’ vigorous resistance –– a pair of entrepreneurial lawyers liberalized Italy’s largest port by combining strategic litigation with a public relations campaign to mobilize a compliance constituency. I conclude with insights the case study offers into the contemporary politics of transnational legal governance. Of all transnational legal orders (Halliday & Shaffer 2015), the European Union (EU) represents an exemplary process of “integration through law” (Kelemen 2011). The conventional view is that the construction of a liberalized common market and a “supranational constitution” (Stone Sweet & Brunell 1998) in Europe can be largely attributed to the “quiet” collaborations of national courts and the European * The author is grateful to the National Science Foundation (grant no. -
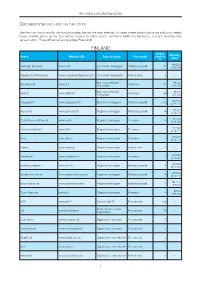
Pay Models in European News Appendix
PAY MODELS IN EUROPEAN NEWS ORGANISATIONS INCLUDED IN THE STUDY See the main document for the sample strategy behind the sites selected. In cases where subscriptions are sold on a weekly basis, monthly prices are for four weeks. Source for online reach: comScore MMX Key Measures, % reach desktop only, January 2017, Finland/France/Germany/Italy/Poland/UK. FINLAND Online Monthly Brand Website URL Type of media Pay model reach in price % €16.50 Helsingin Sanomat www.hs.fi Up-market newspaper Metered paywall 32 (£13.99) Maaseudun Tulevaisuus www.maaseuduntulevaisuus.fi Up-market newspaper Free access 2 – Mid-market/tabloid €9.90 Ilta-Sanomat www.is.fi Freemium 51 newspaper (£8.39) Mid-market/tabloid €8.90 Iltalehti www.iltalehti.fi Freemium 45 newspaper (£7.54) €24.90 Kauppalehti www.kauppalehti.fi Business newspaper Metered paywall n/a (£21.11) €15.00 Aamulehti www.aamulehti.fi Regional newspaper Metered paywall 14 (£12.71) €14.50 Etelä-Suomen Sanomat www.ess.fi Regional newspaper Freemium 4 (£12.29) €14.99 Huvudstadsbladet www.hbl.fi Regional newspaper Freemium 1 (£12.71) €19.00 Ilkka www.ilkka.fi Regional newspaper Freemium 3 (£16.11) Kaleva www.kaleva.fi Regional newspaper Free access 8 – €18.00 Karjalainen www.karjalainen.fi Regional newspaper Freemium 2 (£15.26) €19.62 Keskisuomalainen www.ksml.fi Regional newspaper Metered paywall 4 (£16.63) €15.00 Satakunnan Kansa www.satakunnankansa.fi Regional newspaper Metered paywall 4 (£12.71) €11.10 Savon Sanomat www.savonsanomat.fi Regional newspaper Metered paywall 5 (£9.41) €7.90 Turun Sanomat -

Is Specialised in Observation, Analysis and Predicting Acoustic Emissi
BRIEF COMPANY PROFILE Consulting&Management (C&M) is specialised in observation, analysis and predicting acoustic emissions and environmental vibrations produced by transportation systems, as 1 well as in building acoustics. We carry out through a phase in which studies are run to examine the existing source, or to predict sound emissions if the source is non-existent or different than expected in a possible future scenario. This work is completed with pre and post operational acoustic monitoring campaigns. We also make the acoustic verification tests of the mitigation structures designed. To do all this, C&M is equipped with advanced instrumentation for analysis and registration of acoustic and vibration phenomena that, used with hardware and software systems, makes it possible to elaborate the data collected in real time. All elaboration processes involve computer integration, even in the phases of extrapolating the phenomena and designing noise control systems by applying the more advanced mathematical models used by the US National Highway System, the EMPA (Swiss Highways), the French Ministry of Transportation for problems concerning the TGV, the SBB (Swiss Railways) and the German company RLS. The building acoustics division also has access to automatic calculation and simulation systems designed by experts at the Polytechnic University of Milan. The activities of this division include preparing noise maps of the territory and preparing action plans for noise abatement. Also, the company carries out studies for acoustic and vibration characterisation of any environmental source (fixed or mobile) and for drawing up technical specifications concerning the purchase of noisy materials. Lastly, in partnership with the company R.G.E. -

The Value of Advertising in Il Sole 24
Il Sole 24 ORE. HIGHLIGHTS ABOUT A LEADING NEWSPAPER. 2 IlIlIlSole 242424 ORE isisis thethethe first Italian newspaper forforfor distribution ofofof IL SOLE 24 ORE digital copiescopies. ... Everyday the daily has got 3 sections: The leading newspaper in Italy • First sectionsection, ,,, daily appointment with politics and current affairs (it includes Impresa e Territori) • Finanza &&& MercatiMercati, Tuesday-Saturday • Norme &&& TributiTributi, Monday-Friday. IlIlIlSole 242424 ORE is a business andfinancial The daily has777 weekly appointments NUMBERS daily newspaper that was launched on Risparmio e Famiglia + L’Esperto Risponde Circulation: 237,127 November 9th 1965, following the merger Rapporti Digital circulation: 112,577 of IL SOLE Casa24Plus Readership: 833,000 (a newspaper established in 1865) and 24 Moda24 ADS July 2016/net of multiple digital copies, ORE (a newspaper founded in 1946). Plus24 Audipress 2016.I Domenica Nòva24 3 ADULTS : 833.000 65% 35% A HIGH MEN WOMEN ADULTS MEN WOMEN 707070%70 % OF READERS 69% OF READERS 73% OF READERS SOCIO-DEMO Don’t read Corriere della Sera and La Repubblica 39% 45% 29% Degree High school Entrepreneurs, managers, freelancers PROFILE . Sosial class: Social class: superior medium-superior 15% 30% North West North East Centre South and Islands 30% 23% 23% 24% 12% 18% 25% 20% 17% 25 – 34 yrs 35 – 44 yrs 45 – 54 yrs 55 – 64 yrs > 64 yrs Source:Audipress 2016/1 paper and/or replication. 1 4 237.127 copies A TREND DIGITAL COPIES NET OF MULTIPLE DIGITAL COPIES Var% July ’16/July ’15 OF +4,2% SUCCESS . 125.000 120.000 115.000 112.577 110.000 105.000 108.037 100.000 95.000 l15 a15 s15 o15 n15 d15 g16 f16 m16 a16 M16 G16 L16 ADS 2016/2015 Absolute value and % 5 THIRD POSITION FOR TOTAL CIRCULATION PRINT + DIGITAL LEADER FOR (NET OF MULTIPLE DIGITAL COPIES) DAILY Total Circulation DIGITAL Print + Digital CORRIERE DELLA SERA 328,494 REPUBBLICA (LA) 282,211 COPIES SOLE 24 ORE (IL) 237,127 CIRCUALTION.