Supporting Information
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
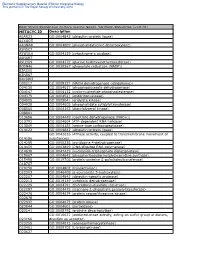
METACYC ID Description A0AR23 GO:0004842 (Ubiquitin-Protein Ligase
Electronic Supplementary Material (ESI) for Integrative Biology This journal is © The Royal Society of Chemistry 2012 Heat Stress Responsive Zostera marina Genes, Southern Population (α=0. -
![Downloaded from the NCBI's Genomes Database [123] Or Prot.Pl?Q98JW4 RHILO] and Other Members of Searched Directly Through the NCBI Web Site](https://docslib.b-cdn.net/cover/4253/downloaded-from-the-ncbis-genomes-database-123-or-prot-pl-q98jw4-rhilo-and-other-members-of-searched-directly-through-the-ncbi-web-site-44253.webp)
Downloaded from the NCBI's Genomes Database [123] Or Prot.Pl?Q98JW4 RHILO] and Other Members of Searched Directly Through the NCBI Web Site
BMC Microbiology BioMed Central Research article Open Access A census of membrane-bound and intracellular signal transduction proteins in bacteria: Bacterial IQ, extroverts and introverts Michael Y Galperin* Address: National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Bethesda, MD 20894, USA Email: Michael Y Galperin* - [email protected] * Corresponding author Published: 14 June 2005 Received: 18 April 2005 Accepted: 14 June 2005 BMC Microbiology 2005, 5:35 doi:10.1186/1471-2180-5-35 This article is available from: http://www.biomedcentral.com/1471-2180/5/35 © 2005 Galperin; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background: Analysis of complete microbial genomes showed that intracellular parasites and other microorganisms that inhabit stable ecological niches encode relatively primitive signaling systems, whereas environmental microorganisms typically have sophisticated systems of environmental sensing and signal transduction. Results: This paper presents results of a comprehensive census of signal transduction proteins – histidine kinases, methyl-accepting chemotaxis receptors, Ser/Thr/Tyr protein kinases, adenylate and diguanylate cyclases and c-di-GMP phosphodiesterases – encoded in 167 bacterial and archaeal genomes, sequenced by the end of 2004. The data have been manually checked to avoid false- negative and false-positive hits that commonly arise during large-scale automated analyses and compared against other available resources. The census data show uneven distribution of most signaling proteins among bacterial and archaeal phyla. -

The World of Cyclic Dinucleotides in Bacterial Behavior
molecules Review The World of Cyclic Dinucleotides in Bacterial Behavior Aline Dias da Purificação, Nathalia Marins de Azevedo, Gabriel Guarany de Araujo , Robson Francisco de Souza and Cristiane Rodrigues Guzzo * Department of Microbiology, Institute of Biomedical Sciences, University of São Paulo, São Paulo 01000-000, Brazil * Correspondence: [email protected] or [email protected]; Tel.: +55-11-3091-7298 Received: 27 December 2019; Accepted: 17 March 2020; Published: 25 May 2020 Abstract: The regulation of multiple bacterial phenotypes was found to depend on different cyclic dinucleotides (CDNs) that constitute intracellular signaling second messenger systems. Most notably, c-di-GMP, along with proteins related to its synthesis, sensing, and degradation, was identified as playing a central role in the switching from biofilm to planktonic modes of growth. Recently, this research topic has been under expansion, with the discoveries of new CDNs, novel classes of CDN receptors, and the numerous functions regulated by these molecules. In this review, we comprehensively describe the three main bacterial enzymes involved in the synthesis of c-di-GMP, c-di-AMP, and cGAMP focusing on description of their three-dimensional structures and their structural similarities with other protein families, as well as the essential residues for catalysis. The diversity of CDN receptors is described in detail along with the residues important for the interaction with the ligand. Interestingly, genomic data strongly suggest that there is a tendency for bacterial cells to use both c-di-AMP and c-di-GMP signaling networks simultaneously, raising the question of whether there is crosstalk between different signaling systems. In summary, the large amount of sequence and structural data available allows a broad view of the complexity and the importance of these CDNs in the regulation of different bacterial behaviors. -

An Atpase Domain Common to Prokaryotic Cell Cycle Proteins
Proc. Natl. Acad. Sci. USA Vol. 89, pp. 7290-7294, August 1992 Biochemistry An ATPase domain common to prokaryotic cell cycle proteins, sugar kinases, actin, and hsp7O heat shock proteins (structural comparison/property pattern/remote homology) PEER BORK, CHRIS SANDER, AND ALFONSO VALENCIA European Molecular Biology Laboratory, D-6900 Heidelberg, Federal Republic of Germany Communicated by Russell F. Doolittle, March 6, 1992 ABSTRACT The functionally diverse actin, hexokinase, and hsp7O protein families have in common an ATPase domain of known three-dimensional structure. Optimal superposition ofthe three structures and alignment ofmany sequences in each of the three families has revealed a set of common conserved residues, distributed in five sequence motifs, which are in- volved in ATP binding and in a putative interdomain hinge. From the multiple sequence aliment in these motifs a pattern of amino acid properties required at each position is defined. The discriminatory power of the pattern is in part due to the use of several known three-dimensional structures and many sequences and in part to the "property" method ofgeneralizing from observed amino acid frequencies to amino acid fitness at each sequence position. A sequence data base search with the pattern significantly matches sugar kinases, such as fuco-, glucono-, xylulo-, ribulo-, and glycerokinase, as well as the prokaryotic cell cycle proteins MreB, FtsA, and StbA. These are predicted to have subdomains with the same tertiary structure as the ATPase subdomains Ia and Ha of hexokinase, actin, and Hsc7O, a very similar ATP binding pocket, and the capacity for interdomain hinge motion accompanying func- tional state changes. -

Non-Homologous Isofunctional Enzymes: a Systematic Analysis Of
Omelchenko et al. Biology Direct 2010, 5:31 http://www.biology-direct.com/content/5/1/31 RESEARCH Open Access Non-homologousResearch isofunctional enzymes: A systematic analysis of alternative solutions in enzyme evolution Marina V Omelchenko, Michael Y Galperin*, Yuri I Wolf and Eugene V Koonin Abstract Background: Evolutionarily unrelated proteins that catalyze the same biochemical reactions are often referred to as analogous - as opposed to homologous - enzymes. The existence of numerous alternative, non-homologous enzyme isoforms presents an interesting evolutionary problem; it also complicates genome-based reconstruction of the metabolic pathways in a variety of organisms. In 1998, a systematic search for analogous enzymes resulted in the identification of 105 Enzyme Commission (EC) numbers that included two or more proteins without detectable sequence similarity to each other, including 34 EC nodes where proteins were known (or predicted) to have distinct structural folds, indicating independent evolutionary origins. In the past 12 years, many putative non-homologous isofunctional enzymes were identified in newly sequenced genomes. In addition, efforts in structural genomics resulted in a vastly improved structural coverage of proteomes, providing for definitive assessment of (non)homologous relationships between proteins. Results: We report the results of a comprehensive search for non-homologous isofunctional enzymes (NISE) that yielded 185 EC nodes with two or more experimentally characterized - or predicted - structurally unrelated proteins. Of these NISE sets, only 74 were from the original 1998 list. Structural assignments of the NISE show over-representation of proteins with the TIM barrel fold and the nucleotide-binding Rossmann fold. From the functional perspective, the set of NISE is enriched in hydrolases, particularly carbohydrate hydrolases, and in enzymes involved in defense against oxidative stress. -

The Rnase H-Like Superfamily: New Members, Comparative Structural Analysis and Evolutionary Classification Karolina A
4160–4179 Nucleic Acids Research, 2014, Vol. 42, No. 7 Published online 23 January 2014 doi:10.1093/nar/gkt1414 The RNase H-like superfamily: new members, comparative structural analysis and evolutionary classification Karolina A. Majorek1,2,3,y, Stanislaw Dunin-Horkawicz1,y, Kamil Steczkiewicz4, Anna Muszewska4,5, Marcin Nowotny6, Krzysztof Ginalski4 and Janusz M. Bujnicki1,3,* 1Laboratory of Bioinformatics and Protein Engineering, International Institute of Molecular and Cell Biology, ul. Ks. Trojdena 4, PL-02-109 Warsaw, Poland, 2Department of Molecular Physiology and Biological Physics, University of Virginia, 1340 Jefferson Park Avenue, Charlottesville, VA USA-22908, USA, 3Bioinformatics Laboratory, Institute of Molecular Biology and Biotechnology, Adam Mickiewicz University, Umultowska 89, PL-61-614 Poznan, Poland, 4Laboratory of Bioinformatics and Systems Biology, Centre of New Technologies, University of Warsaw, Zwirki i Wigury 93, PL-02-089 Warsaw, Poland, 5Institute of Biochemistry and Biophysics PAS, Pawinskiego 5A, PL-02-106 Warsaw, Poland and 6Laboratory of Protein Structure, International Institute of Molecular and Cell Biology, ul. Ks. Trojdena 4, PL-02-109 Warsaw, Poland Received September 23, 2013; Revised December 12, 2013; Accepted December 26, 2013 ABSTRACT revealed a correlation between the orientation of Ribonuclease H-like (RNHL) superfamily, also called the C-terminal helix with the exonuclease/endo- the retroviral integrase superfamily, groups together nuclease function and the architecture of the numerous enzymes involved in nucleic acid metab- active site. Our analysis provides a comprehensive olism and implicated in many biological processes, picture of sequence-structure-function relation- including replication, homologous recombination, ships in the RNHL superfamily that may guide func- DNA repair, transposition and RNA interference. -

Genome Analysis and Classification of Novel Species Flavobacterium Gabrieli
NOTICE: The copyright law of the United States (Title 17, United States Code) governs the making of reproductions of copyrighted material. One specified condition is that the reproduction is not to be "used for any purpose other than private study, scholarship, or research." If a user makes a request for, or later uses a reproduction for purposes in excess of "fair use," that user may be liable for copyright infringement. RESTRICTIONS: This student work may be read, quoted from, cited, for purposes of research. It may not be published in full except by permission of the author. 1 Kirsten Fischer Introduction Microbial Systematics and Taxonomy The diversity of bacteria is truly immense and the discovery of new species and higher taxonomic groups happens quite frequently, as evidenced by the ever expanding tree of life (Hug et al., 2016). The classification of prokaryotes, bacteria especially, is formally regulated by the International Committee on the Systematics of Prokaryotes and has experienced rapid change over the last fifty years. However, some feel that these rules could be even stricter for proper organization of taxonomy (Tindall et al., 2010). Problems occur with the integration of newer methodologies, which creates some challenges for the researcher attempting to publish a novel species. For example, some DNA sequences that are deposited in databases are not accurate (Clarridge, 2004). Taxonomy is an artificial system that works based on the intuition of scientists rather than strict, specific standards (Konstantinidis & Tiedje, 2005). Tindall advocates that a strain shown to be a novel taxon should be characterized “as comprehensively as possible” and abide by the framework established in the Bacteriological Code (2010). -

The Impact of Genetic Diversity on Gene Essentiality Within the E. Coli Species
bioRxiv preprint doi: https://doi.org/10.1101/2020.05.25.114553; this version posted May 25, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. The impact of genetic diversity on gene essentiality within the E. coli species François Rousset1,2, José Cabezas Caballero1, Florence Piastra-Facon1, Jesús Fernández-Rodríguez3, Olivier Clermont4, Erick Denamur4,5, Eduardo P.C. Rocha6 & David Bikard1,* 1- Synthetic Biology, Department of Microbiology, Institut Pasteur, Paris, France 2- Sorbonne Université, Collège Doctoral, F-75005Paris, France 3- Eligo Bioscience, Paris, France 4- Université de Paris, IAME, INSERM UMR1137, Paris, France 5- AP-HP, Laboratoire de Génétique Moléculaire, Hôpital Bichat, Paris, France 6- Microbial Evolutionary Genomics, Institut Pasteur, CNRS, UMR3525, 25-28 rue Dr Roux, Paris, 75015, France. *To whom correspondence should be addressed: [email protected] Abstract Bacteria from the same species can differ widely in their gene content. In E. coli, the set of genes shared by all strains, known as the core genome, represents about half the number of genes present in any strain. While recent advances in bacterial genomics have enabled to unravel genes required for fitness in various experimental conditions at the genome scale, most studies have focused on model strains. As a result, the impact of this genetic diversity on core processes of the bacterial cell largely remains to be investigated. Here, we developed a new CRISPR interference platform for high- throughput gene repression that is compatible with most E. -

Supplementary Materials
Supplementary Materials Figure S1. Differentially abundant spots between the mid-log phase cells grown on xylan or xylose. Red and blue circles denote spots with increased and decreased abundance respectively in the xylan growth condition. The identities of the circled spots are summarized in Table 3. Figure S2. Differentially abundant spots between the stationary phase cells grown on xylan or xylose. Red and blue circles denote spots with increased and decreased abundance respectively in the xylan growth condition. The identities of the circled spots are summarized in Table 4. S2 Table S1. Summary of the non-polysaccharide degrading proteins identified in the B. proteoclasticus cytosol by 2DE/MALDI-TOF. Protein Locus Location Score pI kDa Pep. Cov. Amino Acid Biosynthesis Acetylornithine aminotransferase, ArgD Bpr_I1809 C 1.7 × 10−4 5.1 43.9 11 34% Aspartate/tyrosine/aromatic aminotransferase Bpr_I2631 C 3.0 × 10−14 4.7 43.8 15 46% Aspartate-semialdehyde dehydrogenase, Asd Bpr_I1664 C 7.6 × 10−18 5.5 40.1 17 50% Branched-chain amino acid aminotransferase, IlvE Bpr_I1650 C 2.4 × 10−12 5.2 39.2 13 32% Cysteine synthase, CysK Bpr_I1089 C 1.9 × 10−13 5.0 32.3 18 72% Diaminopimelate dehydrogenase Bpr_I0298 C 9.6 × 10−16 5.6 35.8 16 49% Dihydrodipicolinate reductase, DapB Bpr_I2453 C 2.7 × 10−6 4.9 27.0 9 46% Glu/Leu/Phe/Val dehydrogenase Bpr_I2129 C 1.2 × 10−30 5.4 48.6 31 64% Imidazole glycerol phosphate synthase Bpr_I1240 C 8.0 × 10−3 4.7 22.5 8 44% glutamine amidotransferase subunit Ketol-acid reductoisomerase, IlvC Bpr_I1657 C 3.8 × 10−16 -

Supplementary Table S1. Table 1. List of Bacterial Strains Used in This Study Suppl
Supplementary Material Supplementary Tables: Supplementary Table S1. Table 1. List of bacterial strains used in this study Supplementary Table S2. List of plasmids used in this study Supplementary Table 3. List of primers used for mutagenesis of P. intermedia Supplementary Table 4. List of primers used for qRT-PCR analysis in P. intermedia Supplementary Table 5. List of the most highly upregulated genes in P. intermedia OxyR mutant Supplementary Table 6. List of the most highly downregulated genes in P. intermedia OxyR mutant Supplementary Table 7. List of the most highly upregulated genes in P. intermedia grown in iron-deplete conditions Supplementary Table 8. List of the most highly downregulated genes in P. intermedia grown in iron-deplete conditions Supplementary Figures: Supplementary Figure 1. Comparison of the genomic loci encoding OxyR in Prevotella species. Supplementary Figure 2. Distribution of SOD and glutathione peroxidase genes within the genus Prevotella. Supplementary Table S1. Bacterial strains Strain Description Source or reference P. intermedia V3147 Wild type OMA14 isolated from the (1) periodontal pocket of a Japanese patient with periodontitis V3203 OMA14 PIOMA14_I_0073(oxyR)::ermF This study E. coli XL-1 Blue Host strain for cloning Stratagene S17-1 RP-4-2-Tc::Mu aph::Tn7 recA, Smr (2) 1 Supplementary Table S2. Plasmids Plasmid Relevant property Source or reference pUC118 Takara pBSSK pNDR-Dual Clonetech pTCB Apr Tcr, E. coli-Bacteroides shuttle vector (3) plasmid pKD954 Contains the Porpyromonas gulae catalase (4) -

Progress Toward Understanding the Contribution of Alkali Generation in Dental Biofilms to Inhibition of Dental Caries
International Journal of Oral Science (2012) 4, 135–140 ß 2012 WCSS. All rights reserved 1674-2818/12 www.nature.com/ijos REVIEW Progress toward understanding the contribution of alkali generation in dental biofilms to inhibition of dental caries Ya-Ling Liu1, Marcelle Nascimento2 and Robert A Burne1 Alkali production by oral bacteria is believed to have a major impact on oral microbial ecology and to be inibitory to the initiation and progression of dental caries. A substantial body of evidence is beginning to accumulate that indicates the modulation of the alkalinogenic potential of dental biofilms may be a promising strategy for caries control. This brief review highlights recent progress toward understanding molecular genetic and physiologic aspects of important alkali-generating pathways in oral bacteria, and the role of alkali production in the ecology of dental biofilms in health and disease. International Journal of Oral Science (2012) 4, 135–140; doi:10.1038/ijos.2012.54; published online 21 September 2012 Keywords: arginine; biofilm; dental caries; microbial ecology; urea INTRODUCTION via the arginine deiminase system (ADS).15–18 Urea is provided con- Dental biofilms, the microbial communities that colonize the surfaces tinuously in salivary secretions and gingival exudates at concentra- of the teeth, exist in a dynamic equilibrium with host defenses and are tions roughly equivalent to those in serum, which range from about 3 generally compatible with the integrity of the tissues they colonize.1–4 to10 mmol?L21 in healthy humans. Urea is rapidly converted to A strong correlation is evident between the compositional and meta- ammonia and CO2 by bacterial ureases (Figure 1), which are produced bolic changes of the dental biofilms and the transition from oral health by a small subset of oral bacteria that includes Streptococcus salivarius, 2,5 to disease states, including dental caries and periodontal disease. -

Serine Proteases with Altered Sensitivity to Activity-Modulating
(19) & (11) EP 2 045 321 A2 (12) EUROPEAN PATENT APPLICATION (43) Date of publication: (51) Int Cl.: 08.04.2009 Bulletin 2009/15 C12N 9/00 (2006.01) C12N 15/00 (2006.01) C12Q 1/37 (2006.01) (21) Application number: 09150549.5 (22) Date of filing: 26.05.2006 (84) Designated Contracting States: • Haupts, Ulrich AT BE BG CH CY CZ DE DK EE ES FI FR GB GR 51519 Odenthal (DE) HU IE IS IT LI LT LU LV MC NL PL PT RO SE SI • Coco, Wayne SK TR 50737 Köln (DE) •Tebbe, Jan (30) Priority: 27.05.2005 EP 05104543 50733 Köln (DE) • Votsmeier, Christian (62) Document number(s) of the earlier application(s) in 50259 Pulheim (DE) accordance with Art. 76 EPC: • Scheidig, Andreas 06763303.2 / 1 883 696 50823 Köln (DE) (71) Applicant: Direvo Biotech AG (74) Representative: von Kreisler Selting Werner 50829 Köln (DE) Patentanwälte P.O. Box 10 22 41 (72) Inventors: 50462 Köln (DE) • Koltermann, André 82057 Icking (DE) Remarks: • Kettling, Ulrich This application was filed on 14-01-2009 as a 81477 München (DE) divisional application to the application mentioned under INID code 62. (54) Serine proteases with altered sensitivity to activity-modulating substances (57) The present invention provides variants of ser- screening of the library in the presence of one or several ine proteases of the S1 class with altered sensitivity to activity-modulating substances, selection of variants with one or more activity-modulating substances. A method altered sensitivity to one or several activity-modulating for the generation of such proteases is disclosed, com- substances and isolation of those polynucleotide se- prising the provision of a protease library encoding poly- quences that encode for the selected variants.