CSRN 2902 (Eds.)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SMART MOVEMENT DETECTION for ANDROID PHONES a Degree Thesis Submitted to the Faculty of the Escola Tècnica D'enginyeria De Tele
SMART MOVEMENT DETECTION FOR ANDROID PHONES A Degree Thesis Submitted to the Faculty of the Escola Tècnica d'Enginyeria de Telecomunicació de Barcelona Universitat Politècnica de Catalunya by Pablo Navarro Morales In partial fulfilment of the requirements for the degree in TELECOMMUNICATION ENGINEERING Advisor: Sergio Bermejo Barcelona, October 2016 Abstract This project describes a decision tree based pedometer algorithm and its implementation on Android using machine learning techniques. The pedometer can count steps accurately and It can discard irrelevant motion. The overall classification accuracy is 89.4%. Accelerometer, gyroscope and magnetic field sensors are used in the device. When user puts his smartphone into the pocket, the pedometer can automatically count steps. A filter is used to map the acceleration from mobile phone’s reference frame to the direction of gravity. As a result of this project, an android application has been developed that, using the built-in sensors to measure motion and orientation, implements a decision tree based algorithm for counting steps. 2 Resumen Este proyecto describe un algoritmo para un podómetro basado en un árbol de decisiones y su aplicación en Android utilizando técnicas de aprendizaje automático. El podómetro puede contar los pasos con precisión y se puede descartar el movimiento irrelevante. La precisión de la clasificación general es del 89,4%. Un acelerómetro, un giroscopio y un sensor de campo magnético se utilizan en el dispositivo. Cuando el usuario pone su teléfono en el bolsillo, el podómetro puede contar automáticamente pasos. Un filtro se utiliza para asignar la aceleración del sistema de referencia de teléfono móvil a la dirección de la gravedad. -

Ipad Pro Just Might Replace Your Laptop 21 January 2016, by Jim Rossman, the Dallas Morning News
Review: IPad Pro just might replace your laptop 21 January 2016, by Jim Rossman, The Dallas Morning News For the first time, Apple made an iPad with a bigger screen. It also introduced a few accessories, like the Apple Pencil and the keyboard cover, that make it even more compelling. Would this be the model to replace my MacBook Pro? BIG SCREEN I'm still making that decision, but let me tell you how it's going so far. The first thing you'll notice about the iPad Pro is its 12.9-inch screen. This is an iPad on steroids. Every time a new iPad is introduced, I have the same conversation with myself. Apple sells laptops with similarly sized screens. "Maybe this one will replace my laptop," I muse. My own iPad is a 7.9-inch iPad mini, so stepping up almost 5 inches in screen size feels quite But alas, each time I've been disappointed. luxurious. "Not yet," I mutter. "Maybe someday." The iPad Pro's screen has a resolution of 2,732 by 2,048 pixels (264 pixels per inch). Third-party keyboard cases do a good job at helping the iPad look like a laptop, but a few basic It runs Apple's A9X processor and has 4 gigabytes things keep me from my dream. of RAM. For my writing, I need a comfortable keyboard, a You can configure the iPad Pro with 32 or 128 decently fast processor and screen, and a way to gigabytes of internal storage. Pricing is $799 for the easily move, copy, and paste among my writing 32GB model and $949 for 128GB. -

Apple Lancia Ipad Pro: 12.9", Apple A9X, Smart Keyboard E Pencil
Apple lancia iPad Pro: 12.9", Apple A9X, Smart Keyboard e Pencil - Ultima modifica: Giovedì, 10 Settembre 2015 17:04 Pubblicato: Mercoledì, 09 Settembre 2015 20:16 Scritto da Laura Benedetti Apple iPad Pro è ufficiale. Il maxi-tablet da 12.9 pollici Retina (2732 x 2748 pixel) con Apple A9x sarà sul mercato per novembre in tre versioni a 799$, 949$ e 1079$. Opzionalmente, la Apple Pencil e la Smart Keyboard a 99 dollari e 169 dollari. iPad Pro è stato anticipato da svariati rumors ma solo oggi, nello stesso Bill Graham Civic Auditorium dove quasi quarant'anni fa fu mostrato l'Apple II, è stato reso ufficiale. Andrà a completare la gamma di tablet della Mela morsicata, affiancando l'iPad Air da 9.7 pollici e l'iPad mini da 7.9 pollici, con un grosso Retina Display da 12.9 pollici (2732 x 2748 pixel), oltre 5.6 milioni di pixel visualizzati. E la diagonale non è casuale: il lato lungo di iPad Air 2 è uguale a quello corto di iPad Pro (coincidenze?). Non è solo il nuovo modello della famiglia iPad, nonché il più grande fino ad oggi lanciato, ma è anche il più potente; integra uno più veloci processori sul mercato e supporta tutte quelle funzionalità assenti su iPad più piccoli. Dopotutto il suo nome "Pro" parla chiaro, perché è un iPad indicato per la produttività quindi sta bene in ufficio, negli studi medici o grafici. Apple iPad Pro è dotato di un processore Apple A9x, fino a 1.8 volte più veloce di un Apple A8x e con prestazioni grafiche raddoppiate. -

A STUDY of MODERN MOBILE TABLETS by Jordan Kahtava A
A STUDY OF MODERN MOBILE TABLETS By Jordan Kahtava A thesis submitted in partial fulfillment of the requirements for the degree Bachelor of Computer Science Algoma University Gerry Davies, Thesis Advisor April 14th, 2016 A Study of Modern Mobile Tablets - 1 Abstract Mobile tablets have begun playing a larger role in mobile computing because of their portability. To gather an understanding of what mobile computers can currently accomplish Microsoft and Apple tablets were examined. In general this topic is very broad and hard to research because of the number of mobile devices and tablets. Examining this document should provide detailed insight into mobile tablets and their hardware, operating systems, and programming environment. Any developer can use the information to develop, publish, and setup the appropriate development environments for either Apple or Microsoft. The Incremental waterfall methodology was used to develop two applications that utilize the Accelerometer, Gyroscope, and Inclinometer/Attitude sensors. In addition extensive research was conducted and combined to outline how applications can be published and the rules associated with each application store. The Apple application used Xcode and Objective-C while the Microsoft application used Visual Studio 2012, C-Sharp, and XAML. It was determined that developing for Apple is significantly easier because of the extensive documentation and examples available. In addition Apple’s IDE Xcode can be used to develop, design, test, and publish applications without the need for other programs. It is hard to find easily understandable documentation from Microsoft regarding a particular operating system. Visual Studio 2012 or later must be used to develop Microsoft Store applications. -

A Comparative Study of 64 Bit Microprocessors Apple, Intel and AMD
Special Issue - 2016 International Journal of Engineering Research & Technology (IJERT) ISSN: 2278-0181 ICACT - 2016 Conference Proceedings A Comparative Study of 64 Bit Microprocessors Apple, Intel and AMD Surakshitha S Shifa A Ameen Rekha P M Information Science and Engineering Information Science and Engineering Information Science and Engineering JSSATE JSSATE JSSATE Bangalore, India Bangalore, India Bangalore, India Abstract- In this paper, we draw a comparative study of registers, even larger .The term may also refer to the size of microprocessor, using the three major processors; Apple, low-level data types, such as 64-bit floating-point numbers. Intel and AMD. Although the philosophy of their micro Most CPUs are designed so that the contents of a architecture is the same, they differ in their approaches to single integer register can store the address of any data in implementation. We discuss architecture issues, limitations, the computer's virtual considered an appropriate size to architectures and their features .We live in a world of constant competition dating to the historical words of the work with for another important reason: 4.29 billion Charles Darwin-‘Survival of the fittest ‘. As time passed by, integers are enough to assign unique references to most applications needed more processing power and this lead to entities in applications like databases. an explosive era of research on the architecture of Some supercomputer architectures of the 1970s and microprocessors. We present a technical & comparative study 1980s used registers up to 64 bits wide. In the mid-1980s, of these smart microprocessors. We study and compare two Intel i860 development began culminating in a 1989 microprocessor families that have been at the core of the release. -

Market Power, Regulation and the App Economy
GSR-16 Discussion paper THE RACE FOR SCALE: MARKET POWER, REGULATION AND THE APP ECONOMY Work in progress, for discussion purposes Comments are welcome! Please send your comments on this paper at: [email protected] by 30 May 2016 The views expressed in this paper are those of the author and do not necessarily reflect the opinions of ITU or its Membership. CONTENTS 1 EXECUTIVE SUMMARY ........................................................................................... 5 2 BACKGROUND AND DEFINITION ............................................................................. 11 2.1 What is the app economy? ............................................................................................... 11 2.2 Defining the app economy and its ecosystem ................................................................... 14 3 THE APP ECONOMY VALUE CHAIN AND THE GLOBALISATION OF APP DEVELOPMENT . 18 3.1 The structure of the app economy .................................................................................... 18 4 THE ECONOMICS OF DISRUPTION ........................................................................... 26 4.1 Transactions costs ............................................................................................................. 26 4.2 Modes of digital disruption ............................................................................................... 27 4.3 Potential benefits of app disruption .................................................................................. 31 4.4 The race for scale and -
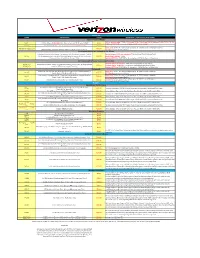
DMS-1011-008C Verizon Contract Pricing
Price Plans CODES DESCRIPTION ACCESS GUIDELINES & OPTIONAL PLAN FEATURES Nationwide Per Minute N/A on feature codes 77294, 77295, and 79740, 79407, and 72409. Must use 79789, 79790, 79791, 86680 $.049 Per Minute Nationwide Voice Plan-includes 600 M2M and 600 N&W $0.00 79780, or 79781. Please see smartphone feature codes below 80245 200 Text/Pix/Flix Messages-Optional on price plan 86680 only $0.00 Basic: (3G) 73749 - $0 Push To Talk Enterprise & 73814 General IP Address (required) 86678/94976 (Dura XV) $10.00 Unlimited Push to Talk w/ Unlimited Mobile 2 Mobile .049 per min rate PTT Plus-$0 (auto attaches-81814) Smartphone Standalone Nationwide Per Minute Unlimited Nationwide Blackberry/ Smartphone Data / Unlimited Domestic Text.Pix, Mobile Hotspot (5 GB auto attached)- 76404 (4G) and 76405 (3G) and 79048 93445 Flix Messaging, Unlimited Mobile 2 Mobile & Nights/Weekends ($.052 Per Minute $35.99 Block Mobile Hotspot-78485 Nationwide Voice Plan)/Mobile Hotspot-5GB) Optional-PTT Plus-$5 (80598 for all smartphones, 80590 for Kyocera Brigadier) Smartphone All Inclusive Nationwide Price Plan 3G Smartphone- $0 Hotspot-79441 (auto attached built into price plan) 86769 (4G) Unlimited Nationwide Calling w/ Unlimited Domestic Text/Pix/Flix Messaging; Email $51.00 4G Smartphone -$0 Hotspot- 76065 (auto attached built into the price plan) 86768 (3G) and Data, 5GB of data hotspot/Tethering Optional-PTT Plus-$5 (80598 for all smartphones, 80590 for Kyocera Brigadier) Nationwide Nationwide 250 Anytime Min ($.052 per min overage rate) w/ Unlimited Mobile -

Security Policy Module Version 10.0
Apple Inc. Apple corecrypto User Space Module for ARM (ccv10) FIPS 140-2 Non-Proprietary Security Policy Module Version 10.0 Prepared for: Apple Inc. One Apple Park Way Cupertino, CA 95014 www.apple.com Prepared by: atsec information security Corp. 9130 Jollyville Road, Suite 260 Austin, TX 78759 www.atsec.com ©2021 Apple Inc. This document may be reproduced and distributed only in its original entirety without revision Trademarks Apple’s trademarks applicable to this document are listed in https://www.apple.com/legal/intellectual- property/trademark/appletmlist.html. Other company, product, and service names may be trademarks or service marks of others. Last update: 2021-03-17 ©2021 Apple Inc. Version: 1.4 Page 2 of 31 Table of Contents 1 Introduction .............................................................................. 5 2 Purpose .................................................................................... 5 2.1 Document Organization / Copyright ............................................................................................. 5 2.2 External Resources / References .................................................................................................. 5 2.2.1 Additional References .......................................................................................................... 5 2.3 Acronyms ...................................................................................................................................... 7 3 Cryptographic Module Specification ......................................... -

Enjoy Flying Your TBM with the New E-COPILOT Reducing Pilot Workload
OWNERS AND PILOTS MAGAZINE SUMMER 2016 TBM SPECIAL EDITION FLYING THE LAST FOUR MINUTES IN CASE YOU HAVE TO DITCH Ditching automatically means you lose the airplane. Just try not to lose anything else Come visit us at Oshkosh! Booth # 2083•Hangar B•Isle D See you there! SimCom is proud to have been the Exclusive Factory Authorized simulator training provider fRUWKH7%0µHHWVLQce 1999. Nothing sharpens yRXUµ\LQJVNLOOV and prepares you for the unexpected like simulator training. Visit www.simulator.com to see a video describing BETTER TRAINING • SAFER PILOTS • GREATER VALUE why SIMCOM’s instructors, simulators and training locations will make your training experience special. ...Nothing Prepares You Like Simulator Training. Visit SIMCOM’s website at simulator.com Call 866.692.1994 to speak with one of our training advisors. © 2016 SIMCOM Aviation Training. All rights reserved. 7 LBS OF POWER START PAC ONE THE SMALLEST STARTER IN THE WORLD YOU NEED THE ONE • PATENTPATENT PENDINGPENDING 7LB7LB CABLECABLE FREEFREE DESIGNDESIGN • • FOR PISTON AND SMALL TO MEDIUM TURBINE ENGINES • • 28V, 1500 PEAK AMPS, AND 10 AH CAPACITY • www.STARTPAC.com OR TOLL FREE 844.901.9987 TBM MAGAZINE 4 SUMMER 2016 TBMBM OwO nerrss& & PiP lotlo s Magaazine • Summer 2016 • Volume 6, Issueu 2 8 12 18 30 D E PA R T M E N T S 6 Hellloo, Oshhkok shs ByB Fraank J. McKee,e TBMOPO A chairmann 8 NNew & NNotaablb e 100 SkSky Gaalss FlF yingg intnto histtory ByB P.J. Goldd 400 From the Facctory A busys andn exciting sprir ngtime foor the TBM By Nicollasa Chaabbert 42 Taax TaTalkl ThThe TTa xppayyer’ss Holy Graaiil Byy Haarryy Dannieels 46 MiPPaad TThe lalateest vere sioon of thhe iPPada features a better screen, faf sttere proceesss oor, new acccessoriei s and greateer fufunnctit onala ity Byy Wayyne Rash JrJ . -

Best Tablets June 2021
24.06.2021 Best Tablets - June 2021 Best Tablets June 2021 Choose OS Android iOS Choose test 3DMark for Android Wild Life Performance 3DMark for Android Wild Life Performance 3DMark for Android Wild Life Unlimited 3DMark for Android Wild Life Extreme 3DMark for Android Sling Shot Extreme (OpenGL ES 3.1 / Metal) 3DMark for Android Sling Shot Extreme (Vulkan / Metal) 3DMark for Android Sling Shot Extreme Unlimited 3DMark for Android Sling Shot 3DMark for Android Sling Shot Unlimited PCMark for Android Work 3.0 Performance PCMark for Android Work 3.0 Battery Life PCMark for Android Work 2.0 Performance PCMark for Android Work 2.0 Battery Life PCMark for Android Computer vision PCMark for Android Storage 2.0 PCMark for Android Storage Choose category Phone Tablet Other Choose screen size 3.0" 15.0" 3.0" 15.0" Search Model name Rank Device Performance Screen Hardware Popularity Apple M1 Apple Up to 3.2 GHz quad- iPad Pro core "Firestorm" and 1 17133 12.9" 2.8 12.9 2.064 GHz quad-core (2021) "Icestorm" Apple M1 GPU https://benchmarks.ul.com/compare/best-tablets 1/7 24.06.2021 Best Tablets - June 2021 Rank Device Performance Screen Hardware Popularity Apple M1 Up to 3.2 GHz quad- Apple core "Firestorm" and 2 iPad Pro 17084 11" 3.7 2.064 GHz quad-core 11 (2021) "Icestorm" Apple M1 GPU Apple A12Z Bionic Apple Up to 2.49 GHz quad- iPad Pro 3 12749 12.9" core "Vortex" and quad- 0.6 12.9 core "Tempest" (2020) Apple A12Z GPU Apple A12Z Bionic Apple Up to 2.49 GHz quad- 4 iPad Pro 12565 11" core "Vortex" and quad- 1.4 11 (2020) core "Tempest" Apple -
Sector Primer
U.S. Semiconductors Primer AMERICAS SEMICONDUCTORS EQUITY RESEARCH December 11, 2013 Chip-by-Chip: Semiconductor ABCs Sector view Remains Neutral Sector Primer In this detailed industry report, we provide a framework for longer- Research analysts term analysis by examining the market size, competitive landscape, and growth drivers for the semiconductor industry. Separately, we Americas Semiconductors have published an outlook piece, titled “Comfortably Numb,” with Romit Shah - NSI themes, catalysts, and best ideas for 2014. [email protected] +1 212 298 4326 Sidney Ho, CFA, CPA - NSI This report offers historical analysis, a discussion of key themes, and an [email protected] outlook for each of the major sub-segments including Microprocessors, +1 212 298 4329 Wireless, Logic, Memory, Analog, and Graphics. We also detail the Sanjay Chaurasia - NSI [email protected] semiconductor manufacturing processes, Moore’s Law, and new +1 212 298 4305 production technologies such as FinFET, double and quadruple patterning, and 450mm. We discuss in the Microprocessor section: new product roadmaps, Intel’s leadership position in servers, and ARM’s 64-bit architecture. We provide a PC model forecast with analysis of the weakening correlation between unit growth and GDP. We also examine integrated CPU graphics, PC gaming, and applications that will support GPU in cloud (GRID). In addition, we look at the evolution of cellular standards, economics of baseband processors, and Qualcomm’s leadership position in LTE. Emerging market smartphone adoption along the S-curve, increasing complexity of RF, and the number 2 player in LTE are key themes we discuss in the Wireless section. -

Content-Aware Internet Video Delivery
Neural Adaptive Content-aware Internet Video Delivery Hyunho Yeo, Youngmok Jung, Jaehong Kim, Jinwoo Shin, Dongsu Han 2 Observation on Current Video Ecosystem Adaptive streaming has been widely deployed (a primary tool for improving user QoE) Video server Client Quality Bandwidth Quality High ABR Medium Low Time Time Time 3 Traditional Approaches Optimizing ABR algorithms Pensieve [SIGCOMM 17], MPC [SIGCOMM 15] Choosing better servers, CDNs Content Multihoming [SIGCOMM 12], VDN [SIGCOMM 15] Leveraging centralized control plan Video Control Plane [SIGCOMM 12], Pythease [NSDI 17] Goal: Find how to best utilize the network resource 4 Limitation of Current Video Delivery Video quality heavily depends on available bandwidth Video server Client Network Low Quality Congestion Directly affect 5 Limitation of Current Video Delivery Client computing power is scarcely utilized other than for decoding Mobile GPU Desktop GPU 500 Apple A10X 12 Apple A9X Apple A10 GTX 1080Ti 375 Apple A8X GTX 1080 9 GTX 980Ti Apple A7 GTX 780Ti 250 Apple A6X 6 GTX 780 (TFLOPs) (GFLOPs) 125 Apple A5 Apple A9 3 GTX 480 Apple A4 Apple A8 GTX 680 GTX 980 Apple A6 GTX 580 Computing Computing power Computing Computing power 0 0 2009 2012 2015 2018 2009 2012 2015 2018 Year Year 6 Observation on Current Video Ecosystem Standard codecs efficiently reduce redundancy inside GOP Group of Pictures (GOP) Video Standard codecs (H.26x, VPx, AV1) Compressed : Intra-frame coding : Inter-frame coding I-frame P-frames I-frame 7 Observation on Current Video Ecosystem Standard codecs efficiently