Modelling Rankings in R: the Plackettluce Package
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Starting Line up by Row Michigan International Speedway 44Th Annual Quicken Loans 400
Starting Line Up by Row Michigan International Speedway 44th Annual Quicken Loans 400 Provided by NASCAR Statistics - Sat, June 16, 2012 @ 02:52 PM Eastern Driver Date Time Speed Track Race Record: Dale Jarrett 06/13/99 02:17:56 173.997 Pos Car Driver Team Time Speed Row 1: 1 9 Marcos Ambrose Stanley Ford 35.426 203.241 2 29 Kevin Harvick Budweiser Folds of Honor Chevrolet 35.637 202.037 Row 2: 3 16 Greg Biffle 3M/Salute Ford 35.676 201.816 4 5 Kasey Kahne Farmers Insurance Chevrolet 35.693 201.720 Row 3: 5 39 Ryan Newman US ARMY Chevrolet 35.737 201.472 6 17 Matt Kenseth Ford EcoBoost Ford 35.739 201.461 Row 4: 7 21 Trevor Bayne(i) Motorcraft/Quick Lane Tire & Auto Center Ford 35.742 201.444 8 14 Tony Stewart Office Depot/Mobil 1 Chevrolet 35.755 201.370 Row 5: 9 20 Joey Logano The Home Depot Toyota 35.777 201.247 10 48 Jimmie Johnson Lowe's Chevrolet 35.789 201.179 Row 6: 11 11 Denny Hamlin FedEx Office Toyota 35.842 200.882 12 78 Regan Smith Furniture Row Chevrolet 35.870 200.725 Row 7: 13 15 Clint Bowyer 5-hour Energy Toyota 35.877 200.686 14 55 Mark Martin Aaron's Dream Machine Toyota 35.894 200.591 Row 8: 15 43 Aric Almirola Medallion Ford 35.930 200.390 16 56 Martin Truex Jr. NAPA Auto Parts Toyota 35.931 200.384 Row 9: 17 88 Dale Earnhardt Jr. -

MOTORSPORTS a North Carolina Growth Industry Under Threat
MOTORSPORTS A North Carolina Growth Industry Under Threat A REPORT PREPARED FOR NORTH CAROLINA MOTORSPORTS ASSOCIATION BY IN COOPERATION WITH FUNDED BY: RURAL ECONOMIC DEVELOPMENT CENTER, THE GOLDEN LEAF FOUNDATION AND NORTH CAROLINA MOTORSPORTS FOUNDATION October 2004 Motorsports – A North Carolina Growth Industry Under Threat TABLE OF CONTENTS Preliminary Remarks 6 Introduction 7 Methodology 8 Impact of Industry 9 History of Motorsports in North Carolina 10 Best Practices / Competitive Threats 14 Overview of Best Practices 15 Virginia Motorsports Initiative 16 South Carolina Initiative 18 Findings 20 Overview of Findings 21 Motorsports Cluster 23 NASCAR Realignment and Its Consequences 25 Events 25 Teams 27 Drivers 31 NASCAR Venues 31 NASCAR All-Star Race 32 Suppliers 32 Technology and Educational Institutions 35 A Strong Foothold in Motorsports Technology 35 Needed Enhancements in Technology Resources 37 North Carolina Motorsports Testing and Research Complex 38 The Sanford Holshouser Business Development Group and UNC Charlotte Urban Institute 2 Motorsports – A North Carolina Growth Industry Under Threat Next Steps on Motorsports Task Force 40 Venues 41 Sanctioning Bodies/Events 43 Drag Racing 44 Museums 46 Television, Film and Radio Production 49 Marketing and Public Relations Firms 51 Philanthropic Activities 53 Local Travel and Tourism Professionals 55 Local Business Recruitment Professionals 57 Input From State Economic Development Officials 61 Recommendations - State Policies and Programs 63 Governor/Commerce Secretary 65 North -

Illinois ... Football Guide
796.33263 lie LL991 f CENTRAL CIRCULATION '- BOOKSTACKS r '.- - »L:sL.^i;:f j:^:i:j r The person charging this material is re- sponsible for its return to the library from which it was borrowed on or before the Latest Date stamped below. Theft, mutllotlen, UNIVERSITY and undarllnlnfl of books are reasons OF for disciplinary action and may result In dismissal from ILUNOIS UBRARY the University. TO RENEW CAll TEUPHONE CENTEK, 333-8400 AT URBANA04AMPAIGN UNIVERSITY OF ILtlNOIS LIBRARY AT URBANA-CHAMPAIGN APPL LiFr: STU0i£3 JAN 1 9 \m^ , USRARy U. OF 1. URBANA-CHAMPAIGN CONTENTS 2 Division of Intercollegiate 85 University of Michigan Traditions Athletics Directory 86 Michigan State University 158 The Big Ten Conference 87 AU-Time Record vs. Opponents 159 The First Season The University of Illinois 88 Opponents Directory 160 Homecoming 4 The Uni\'ersity at a Glance 161 The Marching Illini 6 President and Chancellor 1990 in Reveiw 162 Chief llliniwek 7 Board of Trustees 90 1990 lUinois Stats 8 Academics 93 1990 Game-by-Game Starters Athletes Behind the Traditions 94 1990 Big Ten Stats 164 All-Time Letterwinners The Division of 97 1990 Season in Review 176 Retired Numbers intercollegiate Athletics 1 09 1 990 Football Award Winners 178 Illinois' All-Century Team 12 DIA History 1 80 College Football Hall of Fame 13 DIA Staff The Record Book 183 Illinois' Consensus All-Americans 18 Head Coach /Director of Athletics 112 Punt Return Records 184 All-Big Ten Players John Mackovic 112 Kickoff Return Records 186 The Silver Football Award 23 Assistant -

Modelling Rankings in R: the Plackettluce Package∗
Modelling rankings in R: the PlackettLuce package∗ Heather L. Turnery Jacob van Ettenz David Firthx Ioannis Kosmidis{ December 17, 2019 Abstract This paper presents the R package PlackettLuce, which implements a generalization of the Plackett-Luce model for rankings data. The generalization accommodates both ties (of arbitrary order) and partial rankings (complete rankings of subsets of items). By default, the implementation adds a set of pseudo-comparisons with a hypothetical item, ensuring that the underlying network of wins and losses between items is always strongly connected. In this way, the worth of each item always has a finite maximum likelihood estimate, with finite standard error. The use of pseudo-comparisons also has a regularization effect, shrinking the estimated parameters towards equal item worth. In addition to standard methods for model summary, PlackettLuce provides a method to compute quasi standard errors for the item parameters. This provides the basis for comparison intervals that do not change with the choice of identifiability constraint placed on the item parameters. Finally, the package provides a method for model-based partitioning using covariates whose values vary between rankings, enabling the identification of subgroups of judges or settings with different item worths. The features of the package are demonstrated through application to classic and novel data sets. 1 Introduction Rankings data arise in a range of applications, such as sport tournaments and consumer studies. In rankings data, each observation is an ordering of a set of items. A classic model for such data is the Plackett-Luce model, which stems from Luce’s axiom of choice (Luce, 1959, 1977). -

DDP Motorsports Also Announces Partnership with Pathfinder Chassis
For Immediate Release DDP Motorsports also Announces Partnership with Pathfinder Chassis Knowles, WI (Jan. 26, 2016) – DDP Motorsports LLC will also be partnering with Pathfinder Chassis from Sun Prairie, Wisconsin, to run a Brand New 2016 Pathfinder Super Late Model Race Car for some select races during the 2016 Racing Season. JJ Fabrication, Inc., the manufacturer of the Pathfinder Chassis brand of Asphalt Late Model Race Car, is headquartered at 3372 Burke Road in Sun Prairie, Wisconsin. They also currently offer the offset (straight rail) chassis, truck chassis and NASCAR perimeter chassis (NASCAR Touring Series legal). In 2005, Pathfinder Chassis’ new owners, Jason Schuler and Joe Wood, introduced an updated soft spring, big bar chassis and began building winning race cars for many of the Midwest’s finest drivers including NASCAR stars Matt Kenseth, Tony Stewart, Scott Wimmer, Travis Kvapil and Ross Kenseth. In addition to their complete shock service, specializing in JRI, Penske and Afco Shocks, Pathfinder Chassis also offers chassis repair and set up, quick change rear end service and maintains a complete inventory of chassis and suspensions parts that can be shipped right to your front door. Everyone at Pathfinder Chassis, Anderson's Pure Maple Syrup and DDP Motorsports are really excited about the 2016 Racing Season!! Anderson's Pure Maple Syrup will also be the Primary Sponsor on this Pathfinder/DDP Motorsports Race Car. For more information…..2016 Racing Schedule…..please visit: www.dennisprunty.com www.andersonsmaplesyrup.com www.pathfinderchassis.com Mike Gaulke Marketing Manager DDP Motorsports LLC. -

1911: All 40 Starters
INDIANAPOLIS 500 – ROOKIES BY YEAR 1911: All 40 starters 1912: (8) Bert Dingley, Joe Horan, Johnny Jenkins, Billy Liesaw, Joe Matson, Len Ormsby, Eddie Rickenbacker, Len Zengel 1913: (10) George Clark, Robert Evans, Jules Goux, Albert Guyot, Willie Haupt, Don Herr, Joe Nikrent, Theodore Pilette, Vincenzo Trucco, Paul Zuccarelli 1914: (15) George Boillot, S.F. Brock, Billy Carlson, Billy Chandler, Jean Chassagne, Josef Christiaens, Earl Cooper, Arthur Duray, Ernst Friedrich, Ray Gilhooly, Charles Keene, Art Klein, George Mason, Barney Oldfield, Rene Thomas 1915: (13) Tom Alley, George Babcock, Louis Chevrolet, Joe Cooper, C.C. Cox, John DePalma, George Hill, Johnny Mais, Eddie O’Donnell, Tom Orr, Jean Porporato, Dario Resta, Noel Van Raalte 1916: (8) Wilbur D’Alene, Jules DeVigne, Aldo Franchi, Ora Haibe, Pete Henderson, Art Johnson, Dave Lewis, Tom Rooney 1919: (19) Paul Bablot, Andre Boillot, Joe Boyer, W.W. Brown, Gaston Chevrolet, Cliff Durant, Denny Hickey, Kurt Hitke, Ray Howard, Charles Kirkpatrick, Louis LeCocq, J.J. McCoy, Tommy Milton, Roscoe Sarles, Elmer Shannon, Arthur Thurman, Omar Toft, Ira Vail, Louis Wagner 1920: (4) John Boling, Bennett Hill, Jimmy Murphy, Joe Thomas 1921: (6) Riley Brett, Jules Ellingboe, Louis Fontaine, Percy Ford, Eddie Miller, C.W. Van Ranst 1922: (11) E.G. “Cannonball” Baker, L.L. Corum, Jack Curtner, Peter DePaolo, Leon Duray, Frank Elliott, I.P Fetterman, Harry Hartz, Douglas Hawkes, Glenn Howard, Jerry Wonderlich 1923: (10) Martin de Alzaga, Prince de Cystria, Pierre de Viscaya, Harlan Fengler, Christian Lautenschlager, Wade Morton, Raoul Riganti, Max Sailer, Christian Werner, Count Louis Zborowski 1924: (7) Ernie Ansterburg, Fred Comer, Fred Harder, Bill Hunt, Bob McDonogh, Alfred E. -
Lead Fin Pos Driver Team Laps Pts Bns Pts Winnings Status Tms Laps
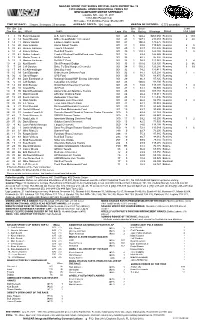
NASCAR SPRINT CUP SERIES OFFICIAL RACE REPORT No. 19 19TH ANNUAL LENOX INDUSTRIAL TOOLS 301 NEW HAMPSHIRE MOTOR SPEEDWAY Loudon, NH - July 17, 2011 1.058-Mile Paved Oval 301 Laps - 318.46 Miles Purse: $5,202,458 TIME OF RACE: 3 hours, 3 minutes, 33 seconds AVERAGE SPEED: 104.1 mph MARGIN OF VICTORY: 0.773 second(s) Fin Str Car Bns Driver Lead Pos Pos No Driver Team Laps Pts Pts Rating Winnings Status Tms Laps 1 1 39 Ryan Newman U.S. Army Chevrolet 301 48 5 140.2 $268,050 Running 6 119 2 2 14 Tony Stewart Office Depot/Mobil 1 Chevrolet 301 43 1 127.1 210,633 Running 2 48 3 14 11 Denny Hamlin FedEx Freight Toyota 301 41 100.4 170,675 Running 4 16 20 Joey Logano Home Depot Toyota 301 41 1 99.5 119,025 Running 2 5 5 28 48 Jimmie Johnson Lowe's Chevrolet 301 40 1 93.7 151,236 Running 1 19 6 10 4 Kasey Kahne Red Bull Toyota 301 39 1 110.3 122,158 Running 1 5 7 23 47 Bobby Labonte Capital Window/CapWinFund.com Toyota 301 37 69.4 126,945 Running 8 13 56 Martin Truex Jr NAPA Toyota 301 36 88.2 95,350 Running 9 22 9 Marcos Ambrose DeWALT Ford 301 36 1 74.9 121,541 Running 1 4 10 4 22 Kurt Busch Shell/Pennzoil Dodge 301 35 1 118.0 128,125 Running 2 66 11 7 24 Jeff Gordon Drive To End Hunger Chevrolet 301 34 1 110.3 126,286 Running 1 19 12 17 43 AJ Allmendinger Best Buy Ford 301 32 74.2 120,411 Running 13 15 99 Carl Edwards Ortho Home Defense Ford 301 32 1 94.1 125,291 Running 1 1 14 26 6 David Ragan UPS Ford 301 30 70.7 88,875 Running 15 27 88 Dale Earnhardt Jr National Guard/AMP Energy Chevrolet 301 29 66.3 87,425 Running 16 6 31 Jeff Burton Catepillar Chevrolet 301 28 100.0 88,300 Running 17 12 33 Clint Bowyer Good Sam/Cheerios Chevrolet 301 28 1 74.0 118,708 Running 1 3 18 20 16 Greg Biffle 3M Ford 301 27 1 83.1 92,900 Running 1 1 19 3 00 David Reutimann Aaron's Dream Machine Toyota 301 25 88.0 107,158 Running 20 30 17 Matt Kenseth Affliction Clothing Ford 301 24 60.4 115,911 Running 21 18 29 Kevin Harvick Budweiser Chevrolet 301 23 73.3 122,436 Running 22 24 5 Mark Martin GoDaddy.com Chevrolet 301 23 1 66.8 84,850 Running 1 3 23 38 38 J.J. -

Mike Twedt 4/29 (Woo) Mark K
COMPLETE RESULTS FOR 1988 Date (Sanction/Event) – Winners 4/23 410 – Jerry Richert Jr., 360 – Mike Twedt 4/29 (WoO) Mark Kinser 4/30 (WoO) Steve Kinser 5/7 410 – Sammy Swindell, 360 – David Hesmer 5/14 410 – Jerry Richert Jr., 360 – Dean Chadd 5/21 Rain 5/28 410 – Danny Thoman, 360 – Dwight Snodgrass 6/4 410 – Danny Lasoski, 360 – Rick McClure 6/11 (USAC winged) Sammy Swindell, 360 – Rick McClure 6/18 Rain 6/22 (WoO) Steve Kinser, 360 – Dean Chadd 6/25 410 – Randy Smith, 360 – David Hesmer 7/2 410 – Randy Smith, 360 – Jordan Albaugh 7/9 (Twin Features) 410 – Randy Smith, Danny Young, 360 – David Hesmer, Mike Twedt 7/16 410 – Randy Smith, 360 – Toby Lawless 7/23 410 – Terry McCarl, 360 – Terry Thorson 7/26 (Enduro) Bob Maschman 7/28 (Modified) Brad Dubil 7/29 (WoO Late Models) Billy Moyer 7/30 410 – Danny Lasoski, 360 – Mike Twedt 8/6 410 – Danny Lasoski, 360 – David Hesmer 8/10 (Knoxville Nationals Prelim) Bobby Davis Jr. 8/11 (Knoxville Nationals Prelim) Dave Blaney 8/12 (Knoxville Nationals NQ) Doug Wolfgang, (Race of States) Doug Wolfgang, (Mystery Feature) Sammy Swindell 8/13 (Knoxville Nationals) Steve Kinser 8/27 410 – Randy Smith, 360 – David Hesmer 4/23/88 Weather Cold, Richert Hot at Knoxville Opener by Bob Wilson Knoxville, IA – Jerry Richert Jr., son of 1962 Knoxville Nationals champion, Jerry Richert Sr., captured the 20 lap season opener at the Knoxville Raceway Saturday night. The win, Richert’s initial here, came aboard the Marty Johnson Taggert Racing Gambler and earned $2,000 for the young Minnesota pilot in track record time. -

Points Report Talladega Superspeedway UAW-Ford 500 UNOFFICIAL Provided by NASCAR Statistical Services - Sun, Oct 2, 2005 @ 08:09 PM Eastern UNOFFICIAL
Points Report Talladega Superspeedway UAW-Ford 500 UNOFFICIAL Provided by NASCAR Statistical Services - Sun, Oct 2, 2005 @ 08:09 PM Eastern UNOFFICIAL Pos Driver BPts Points -Ldr -Nxt Starts Poles Wins T5s T10s DNFs Money Won PPos G/L 1 Tony Stewart 120 5519 0 0 29 2 5 14 20 1 $5,829,335 5 4 2 Ryan Newman 80 5515 -4 -4 29 6 1 8 13 3 $4,590,956 3 1 3 Rusty Wallace 35 5443 -76 -72 29 0 0 8 16 0 $4,048,697 2 -1 4 Jimmie Johnson 80 5437 -82 -6 29 1 3 10 17 4 $5,622,476 1 -3 5 Greg Biffle 115 5421 -98 -16 29 0 5 11 16 1 $4,563,902 6 1 6 Carl Edwards 40 5419 -100 -2 29 1 2 9 12 1 $3,512,909 8 2 7 Matt Kenseth 75 5408 -111 -11 29 1 1 8 13 4 $4,595,182 9 2 8 Jeremy Mayfield 50 5407 -112 -1 29 0 1 4 8 1 $3,831,461 7 -1 9 Mark Martin 50 5381 -138 -26 29 0 0 7 14 2 $4,593,193 4 -5 10 Kurt Busch 105 5339 -180 -42 29 0 3 8 15 3 $5,721,366 10 0 11 Kevin Harvick 45 3321 0 0 29 2 1 3 9 1 $4,098,812 12 1 12 Jamie McMurray 10 3307 -14 -14 29 1 0 4 8 3 $3,309,124 13 1 13 Elliott Sadler 55 3288 -33 -19 29 3 0 1 10 2 $4,077,999 11 -2 14 Dale Jarrett 15 3270 -51 -18 29 1 1 4 6 1 $3,859,097 15 1 15 Joe Nemechek 50 3222 -99 -48 29 1 0 1 8 2 $3,437,038 16 1 16 Jeff Gordon 65 3202 -119 -20 29 2 3 5 9 8 $5,686,421 14 -2 17 Brian Vickers 55 3187 -134 -15 29 1 0 5 10 3 $3,363,819 18 1 18 Dale Earnhardt Jr. -

1994 Results
COMPLETE RESULTS FOR 1994 Date (Sanction/Event) – Winners 4/23 410 – Danny Lasoski, 360 – Duane Van Heukelom 4/29 (WoO) – Dave Blaney 4/30 (WoO) – Snow 5/7 410 – Johnny Herrera, 360 – Danny Young 5/14 – Rain 5/21 410 – Danny Lasoski, 360 – Randy Martin 5/28 410 – Danny Lasoski, 360 – Lee Nelson 6/4 410 – Terry McCarl, 360 – Randy Martin 6/10 (Masters Classic) – Rain 6/11 410 – Danny Lasoski, (Masters Classic) – Rick Ferkel 6/18 (WoO) – Rain 6/24 (WoO) – Steve Kinser 6/25 (WoO Twin Features) – Steve Kinser, Danny Lasoski, 360 – Bruce Drottz 7/2 410 – Danny Lasoski, 360 – Larry Pinegar II 7/9 (Twin Features) 410 – Skip Jackson, Todd Wessels, 360 – Randy Martin, Duane Van Heukelom 7/16 410 – Danny Lasoski, 360 – Scott Whitworth 7/20 (WoO) – Steve Kinser 7/21 IMCA Modified – Rex Van Buskirk, Hobby Stocks – Ron VerBeek 7/22 Enduro – Randy Spaulding 7/23 410 – Danny Lasoski, 360 – Scott Whitworth 7/30 410 – Terry McCarl, 360 – Randy Martin 8/6 410 – Danny Lasoski, 360 – Randy Martin 8/13 410 – Ray Lipsey, 360 – Billy Bell 8/17 (Knoxville Nationals Prelim) – Andy Hillenburg 8/18 (Knoxville Nationals Prelim) – Jac Haudenschild 8/19 (Knoxville Nationals NQ) – Greg Hodnett 8/20 (Knoxville Nationals) – Steve Kinser 8/26 (360 Nationals Prelim) – Danny Young 8/27 (360 Nationals) – Lee Nelson 9/3 410 – Danny Lasoski, 360 – Randy Martin 9/10 Deery Brothers Late Models – Steve Kosiski, Hobby Stocks – Wayne Hale 9/23 (WoO) - Jac Haudenschild 9/24 (WoO) - Rain 4/23/94 Lasoski Sweeps Knoxville Opener by Bob Wilson www.KnoxvilleRaceway.com Page 1 of 64 Knoxville, IA – Danny Lasoski made it look easy as he swept to a convincing win at the 41st season opener at the Knoxville Raceway Saturday night. -

1968 Hot Wheels
1968 - 2003 VEHICLE LIST 1968 Hot Wheels 6459 Power Pad 5850 Hy Gear 6205 Custom Cougar 6460 AMX/2 5851 Miles Ahead 6206 Custom Mustang 6461 Jeep (Grass Hopper) 5853 Red Catchup 6207 Custom T-Bird 6466 Cockney Cab 5854 Hot Rodney 6208 Custom Camaro 6467 Olds 442 1973 Hot Wheels 6209 Silhouette 6469 Fire Chief Cruiser 5880 Double Header 6210 Deora 6471 Evil Weevil 6004 Superfine Turbine 6211 Custom Barracuda 6472 Cord 6007 Sweet 16 6212 Custom Firebird 6499 Boss Hoss Silver Special 6962 Mercedes 280SL 6213 Custom Fleetside 6410 Mongoose Funny Car 6963 Police Cruiser 6214 Ford J-Car 1970 Heavyweights 6964 Red Baron 6215 Custom Corvette 6450 Tow Truck 6965 Prowler 6217 Beatnik Bandit 6451 Ambulance 6966 Paddy Wagon 6218 Custom El Dorado 6452 Cement Mixer 6967 Dune Daddy 6219 Hot Heap 6453 Dump Truck 6968 Alive '55 6220 Custom Volkswagen Cheetah 6454 Fire Engine 6969 Snake 1969 Hot Wheels 6455 Moving Van 6970 Mongoose 6216 Python 1970 Rrrumblers 6971 Street Snorter 6250 Classic '32 Ford Vicky 6010 Road Hog 6972 Porsche 917 6251 Classic '31 Ford Woody 6011 High Tailer 6973 Ferrari 213P 6252 Classic '57 Bird 6031 Mean Machine 6974 Sand Witch 6253 Classic '36 Ford Coupe 6032 Rip Snorter 6975 Double Vision 6254 Lolo GT 70 6048 3-Squealer 6976 Buzz Off 6255 Mclaren MGA 6049 Torque Chop 6977 Zploder 6256 Chapparral 2G 1971 Hot Wheels 6978 Mercedes C111 6257 Ford MK IV 5953 Snake II 6979 Hiway Robber 6258 Twinmill 5954 Mongoose II 6980 Ice T 6259 Turbofire 5951 Snake Rail Dragster 6981 Odd Job 6260 Torero 5952 Mongoose Rail Dragster 6982 Show-off -

Table of Contents
TABLE OF CONTENTS MEDIA INFORMATION 1 FOX NASCAR PRODUCTION STAFF 2 DAYTONA 500 PRODUCTION ELEMENTS 3-4 DAYTONA 500 AUDIENCE FACTS 5-6 DAYTONA 500 AUDIENCE HISTORY 7-8 DAYTONA SPEEDWEEKS ON FOX PROGRAMMING SCHEDULE 9-12 JEFF GORDON’S DAYTONA 500 KICKOFF CELEBRATION ON FOX 13 FOX DEPORTES 14 FOX DIGITAL 15-17 FOX SPORTS SUPPORTS 18 FOX NASCAR HISTORY & TIMELINE 19-21 MOTOR SPORTS ON FOX 22-24 BROADCASTER & EXECUTIVE BIOS 25-48 MEDIA INFORMATION The FOX NASCAR Daytona 500 press kit has been prepared by the FOX Sports Communications Department to assist you with your coverage of this year’s “Great American Race” on Sunday, Feb. 21 (1:00 PM ET) on FOX and will be updated continuously on our press site: www.foxsports.com/presspass. The FOX Sports Communications staff is available to provide further information and facilitate interview requests. Updated FOX NASCAR photography, featuring new FOX NASCAR analyst and four-time NASCAR champion Jeff Gordon, along with other FOX on-air personalities, can be downloaded via the aforementioned FOX Sports press pass website. If you need assistance with photography, contact Ileana Peña at 212/556-2588 or [email protected]. The 59th running of the Daytona 500 and all ancillary programming leading up to the race is available digitally via the FOX Sports GO app and online at www.FOXSportsGO.com. FOX SPORTS ON-SITE COMMUNICATIONS STAFF Chris Hannan EVP, Communications & Cell: 310/871-6324; Integration [email protected] Lou D’Ermilio SVP, Media Relations Cell: 917/601-6898; [email protected] Erik Arneson VP, Media Relations Cell: 704/458-7926; [email protected] Megan Englehart Publicist, Media Relations Cell: 336/425-4762 [email protected] Eddie Motl Manager, Media Relations Cell: 845/313-5802 [email protected] Claudia Martinez Director, FOX Deportes Media Cell: 818/421-2994; Relations claudia.martinez@foxcom 2016 DAYTONA 500 MEDIA CONFERENCE CALL & REPLAY FOX Sports is conducting a media event and simultaneous conference call from the Daytona International Speedway Infield Media Center on Thursday, Feb.