Analogy in Lovari Morphology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ROMA INCLUSION in the CROATIAN SOCIETY Identity, Social Distance and the Experience of Discrimination
Europska unija Zajedno do fondova EU ROMA INCLUSION IN THE CROATIAN SOCIETY identity, social distance and the experience of discrimination Nikola Rašić - Danijela Lucić - Branka Galić - Nenad Karajić Publisher: Office for Human Rights and the Rights of National Minorities of the Government of the Republic of Croatia For the publisher: Alen Tahiri, M.A.Pol Sci Year of publication: 2020 Original title: Uključivanje Roma u hrvatsko društvo: identitet, socijalna distanca i iskustvo diskriminacije Authors: Nikola Rašić, Danijela Lucić, Branka Galić, Nenad Karajić Reviewers: Helena Popović and Krunoslav Nikodem Translation: Sinonim d.o.o. Graphic design, editing and printing: Kerschoffset d.o.o. Circulation: 50 copies Cataloguing-in-Publication data available in the Online Catalogue of the National and University Library in Zagreb under CIP record 001083072. ISBN: 978-953-7870-26-3 Projekt je sufinancirala Europska unija iz Europskog socijalnog fonda. Sadržaj publikacije isključiva je odgovornost Ureda za ljudska prava i prava nacionalnih manjina Vlade Republike Hrvatske. Za više informacija: Ured za ljudska prava i prava nacionalnih manjina Vlade Republike Hrvatske Mesnička 23, 10 000 Zagreb, + 385 (1) 4569 358, [email protected] Više informacija o EU fondovima dostupno je na www.strukturnifondovi.hr ROMA INCLUSION IN THE CROATIAN SOCIETY identity, social distance and the experience of discrimination Nikola Rašić - Danijela Lucić - Branka Galić - Nenad Karajić Zagreb, 2020 DISCLAIMER: The views and opinions expressed in this publication are those of the authors and do not necessarily reflect the views of the institutions in which the authors are employed nor the views of the Office for Human Rights and the Rights of National Minorities of the Government of the Republic of Croatia. -

Arabic Sociolinguistics: Topics in Diglossia, Gender, Identity, And
Arabic Sociolinguistics Arabic Sociolinguistics Reem Bassiouney Edinburgh University Press © Reem Bassiouney, 2009 Edinburgh University Press Ltd 22 George Square, Edinburgh Typeset in ll/13pt Ehrhardt by Servis Filmsetting Ltd, Stockport, Cheshire, and printed and bound in Great Britain by CPI Antony Rowe, Chippenham and East bourne A CIP record for this book is available from the British Library ISBN 978 0 7486 2373 0 (hardback) ISBN 978 0 7486 2374 7 (paperback) The right ofReem Bassiouney to be identified as author of this work has been asserted in accordance with the Copyright, Designs and Patents Act 1988. Contents Acknowledgements viii List of charts, maps and tables x List of abbreviations xii Conventions used in this book xiv Introduction 1 1. Diglossia and dialect groups in the Arab world 9 1.1 Diglossia 10 1.1.1 Anoverviewofthestudyofdiglossia 10 1.1.2 Theories that explain diglossia in terms oflevels 14 1.1.3 The idea ofEducated Spoken Arabic 16 1.2 Dialects/varieties in the Arab world 18 1.2. 1 The concept ofprestige as different from that ofstandard 18 1.2.2 Groups ofdialects in the Arab world 19 1.3 Conclusion 26 2. Code-switching 28 2.1 Introduction 29 2.2 Problem of terminology: code-switching and code-mixing 30 2.3 Code-switching and diglossia 31 2.4 The study of constraints on code-switching in relation to the Arab world 31 2.4. 1 Structural constraints on classic code-switching 31 2.4.2 Structural constraints on diglossic switching 42 2.5 Motivations for code-switching 59 2. -

Call for Films
CALL FOR FILMS To all Roma, Sinti, Kale, Kalderash, Lovara, Lalleri, Ursari, Beasch, Manouches, Ashkali, Aurari, Romanichals, Droma, Doma, Gypsies, Travellers and all the other Romani groups of the world… The fourth Festival of Romani Film will take place in Berlin in 2020: AKE DIKHEA? Festival of Romani Film 19 – 23 November 2020 We are looking for films with which members of different Romani groups can identify to. People with a Romani background or self-organizations can propose films by Roma and non-Roma filmmakers whose themes concern the lives of Romani people in the world and critically reflect upon the reality of discrimination. Possibilities of film registration: FilmFreeWay: https://filmfreeway.com/AkeDikhea Form: https://bit.ly/2NiDumj E-mail: [email protected] Deadline for submission of proposals: Sunday, 9 August 2020 Background information: AKE DIKHEA? translated means “YOU SEE?". It is a self-organized, international festival of Romani film that will take place in Berlin in November 2020. The festival presents Berlin, Germany and the whole world from the perspective of Romani people: Which films represent us, which themes are important to us, how do we see ourselves and how do we want to be seen? We don't want to wait until someone gives us a voice. We want to shape the social space ourselves and decide on the themes and structure of the festival events. The festival is organized by the Berlin Roma self-organization RomaTrial in cooperation with Germany's oldest cinema, Moviemento. Further information can be found on the roma-filmfestival.com website. Selection process The AKE DIKHEA? Festival of Romani Film stands for a unique, participatory selection process: Thanks to our worldwide network of (Romani) filmmakers, we are able to discover topics, people and perspectives that would otherwise remain hidden or only have a local or national impact. -

The Political Status of the Romani Language in Europe. Mercator Working Papers
DOCUMENT RESUME ED 479 303 FL 027 781 AUTHOR Bakker, Peter; Rooker, Marcia TITLE The Political Status of the Romani Language in Europe. Mercator Working Papers. SPONS AGENCY European Union, Brussels (Belgium). REPORT NO WP-3 ISSN ISSN-1133-3928 PUB DATE 2001-00-00 NOTE 37p.; Produced by CIEMEN (Escarre International Centre for Ethnic Minorities and Nations), Barcelona, Spain. Contains small print. AVAILABLE FROM CIEMEN, Rocafort 242, bis, 08020 Barcelona,(Catalunya), Spain. Tel: 34-93-444-38-00; Fax: 34-93-444-38-09; e-mail: [email protected]; Web site: http://www.ciemen.org/mercator. For full text: http://www.ciemen.org/mercator/ pdf/wp3-def-ang.PDF. PUB TYPE Reports Descriptive (141) EDRS PRICE EDRS Price MF01/PCO2 Plus Postage. DESCRIPTORS Civil Rights; Elementary Secondary Education; Foreign Countries; Language Usage; Language of Instruction; *Minority Groups;,Public Policy; *Regional Dialects; Sociolinguistics IDENTIFIERS European Union; *Gypsies; Roma ABSTRACT This paper examines the political status of Romani. the language of the Gypsies/Roma, in the European Union (EU). Even though some groups do not call themselves "Roma," all Romani speaking groups use the name "Romanes" for their language and "Romani/Romano/Romane" for everything related to their group. All groups use the same language, and all languages can be subdivided into dialects. Three aspects make Romani dialects more diverse than other EU dialects: absence of centuries long influence from a standard language or prestige dialect; influence from a variety of local languages; and a great number of communities of Romani speakers (with speakers not all in contact with each other). -

Hungary: Traditional Roma Names
Responses to Information Requests - Immigration and Refugee Board of Canada Page 1 of 9 Home Country of Origin Information Responses to Information Requests Responses to Information Requests Responses to Information Requests (RIR) are research reports on country conditions. They are requested by IRB decision makers. The database contains a seven-year archive of English and French RIR. Earlier RIR may be found on the UNHCR's Refworld website. Please note that some RIR have attachments which are not electronically accessible here. To obtain a copy of an attachment, please e-mail us. Related Links • Advanced search help 8 January 2018 HUN106036.E Hungary: Traditional Roma names; name-changing practices after marriage; languages spoken by Roma, including variations in spoken Hungarian (2015- December 2017) Research Directorate, Immigration and Refugee Board of Canada, Ottawa 1. Traditional Roma Names In correspondence with the Research Directorate, Tamás Farkas, a linguist at Eötvös Loránd University in Budapest (Országos Doktori Tanács 2017), indicated that the most common and typical surnames of Roma in Hungary are linguistically of Hungarian origin (Farkas 21 Dec. 2017). The same source added that "it is not so easy" to distinguish between Roma names and the rest of the Hungarian population "as in the case of other national or ethnic minorities" (Farkas 21 Dec. 2017). However, the same source indicated that, when looking at someone's full name, https://irb-cisr.gc.ca/en/country-information/rir/Pages/index.aspx?doc=457338&pls=1 9/7/2018 Responses to Information Requests - Immigration and Refugee Board of Canada Page 2 of 9 there are some personal names for which "it is quite obvious that the person belongs to the Roma population" (Farkas 20 Dec. -

Ayrımcılık, İzolasyon Ve Sosyal Dışlanmışlık: Çapraz Ateş Arasında Suriyeli Dom Sığınmacılar
DOMLAR / Suriye’nin “Öteki” Sığınmacıları DOMLAR / Suriye’nin Ayrımcılık, İzolasyon ve Sosyal Dışlanmışlık: 1 Çapraz Ateş Arasında Suriyeli Dom Sığınmacılar “Lübnan, Ürdün ve Türkiye’ye Sığınan Suriyeli Dom ve İlgili Diğer Grupların Haklarının Desteklenmesi Projesi” Ön Raporu Proje Danışmanları Kemal Vural Tarlan Hacer Foggo Ön-Raporu Yayına Hazırlayan Kemal Vural Tarlan Rapora Katkı Verenler Aslı Saban Ezgi Durmaz Zühal Gezicier Lana Mohammadd Issa Abu Samra Özlem Anadol Sally Sharaf Proje Koordinatörü Aslı Saban Proje Asistanı Ezgi Durmaz Fotoğraflar Kemal Vural Tarlan Tasarım Kurtuluş Karaşın KIRKAYAK KÜLTÜR Kırkayak Kültür Sanat ve Doğa Derneği Akyol Mah. Atatürk Bul. Şaban Sok. No:36/1, 27010 Şahinbey/ G. Antep 0 342 230 74 54 www.kirkayak.org [email protected] [email protected] KirkayakSanat kirkayakkultur Middle East Gypsies www.middleeastgypsies.com Bu rapor, Kırkayak Kültür – Dom Araştırmalar Atölyesi tarafından hazırlanmıştır, raporun içeriği yalınızca hazırlayanlara aittir ve Avrupa Komisyonu görüşlerini yansıtmamaktadır. Bu rapor kamu malıdır. Kaynak gösterilerek rapordan alıntı yapılabilir. Yaygın olarak dağıtılabilir. Ayrımcılık, İzolasyon ve Sosyal Dışlanmışlık: Çapraz Ateş Arasında Suriyeli Dom Sığınmacılar Lübnan, Ürdün ve Türkiye’ye Sığınan Suriyeli Dom ve İlgili Diğer Grupların Haklarının Desteklenmesi Projesi Ön Raporu DOMLAR / Suriye’nin “Öteki” Sığınmacıları DOMLAR / Suriye’nin 2 Kısaltmalar AFAD Afet ve Acil Durum Yönetimi Başkanlığı BM Birleşmiş Milletler BMEHS Engellilerin Haklarına İlişkin Sözleşme BMMYK -

Place Names in Romani and Bayash Communities in Hungary1
ONOMÀSTICA 6 (2020): 191-215 | RECEPCIÓ 27.10.2019 | ACCEPTACIÓ 15.1.2020 Place names in Romani and Bayash communities in Hungary1 Mátyás Rosenberg Research Institute for Linguistics, Hungarian Academy of Sciences [email protected] Gábor Mikesy Lechner Knowledge Centre [email protected] Andrea Bölcskei Károli Gáspár University of the Reformed Church in Hungary [email protected] Abstract: Research into Romani and Bayash toponyms in Hungary lags significantly behind the study of the place names of other minorities, a fact attributable to the only relatively recent appearance of Romani Studies and a number of other historical factors. Among the latter, it should be borne in mind that Romani and Bayash communities only became the dominant populations in certain areas of Hungary in the last few decades and that the standard written versions of the Romani and Bayash linguistic varieties are still being formed. This study describes the main features of the ethnic and linguistic divisions of the Roma communities in Hungary; the problems of Romani and Bayash literacy; and initial attempts at collecting Romani and Bayash toponyms in the country. Although an elaborate, widely used system of Romani and Bayash settlement names exists, the collection and analysis of the microtoponyms is hindered by the fact that the settlement of the Roma population is only a fairly recent event and that the communities have not typically been involved in agriculture, an occupation much more closely associated with the use of these names. This paper provides, for the first time, a summary of the results of several toponymic field studies conducted in Hungary’s Romani and Bayash communities. -

The Case of the Romani Ethnic Minority Prologu
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Loughborough University Institutional Repository Mainstream Narratives and Counter-Narratives in the Representation of The Other: The Case of the Romani Ethnic Minority Amalia Sabiescu Coventry University, UK [email protected] Prologue “The other kids say I’m dirty. At the beginning I was mad with them, but now I don’t respond anymore, I just let them say what they will. I have a hole in my shoes and I just walk like that. Sometimes I hit on stones. Like a horse...” The Romani boy laughs as he completes the story about his experiences in second- ary school. There is no sign of distress, hate, or madness on his smiling face as he reveals his difficulties in school attendance, the poverty, and the bullying of Romani- an colleagues. He has been born a Kalderash Roma, or Gypsy, living in a rural com- munity in South-Eastern Romania where the traditional ways of hundreds of years ago blend with selective forms of modernity. The Roma in the village of Munteni are traditional tinkers; they craft metal objects, cauldrons for spirits brewing, spoons, cups. Until little more than 50 years ago they used to be nomadic and travelled throughout Romania selling their products and settling for weeks or months in no- madic camps. Since the end of the 1950s, when they were settled by force by the Communist regime, the Kalderash in Munteni travel only in the warm months of the year, from April to October. -
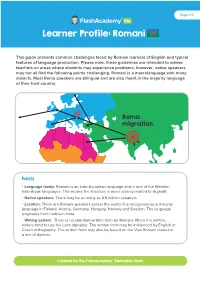
Article Snap2
Page: 1/5 Learner Profile: Romani This guide presents common challenges faced by Romani learners of English and typical features of language production. Please note, these guidelines are intended to advise teachers on areas where students may experience problems; however, native speakers may not all find the following points challenging. Romani is a macrolanguage with many dialects. Most Roma speakers are bilingual and are also fluent in the majority language of their host country. Roma migration Facts Language family: Romani is an Indo-European language and is one of the Western Indo-Aryan languages. This means the structure is more closely related to Gujarati. Native speakers: There may be as many as 3.5 million speakers Location: There are Romani speakers across the world. It is recognised as a minority language in Finland, Austria, Germany, Hungary, Norway and Sweden. The language originates from northern India. Writing system: There is no standard written form for Romani. When it is written, writers tend to use the Latin alphabet. The written form may be influenced by English or Czech orthography. The written form may also be based on the Vlax Romani dialect or a mix of dialects. Created by the FlashAcademy® Education Team Page: 2/5 Learner Profile: Romani Dialects There are many dierent Romani dialect families due to speakers being dispersed across Europe. More information about dierent dialects can be found here: https://romani.humanities.manchester.ac.uk/rms/. There are many discussions on grouping Romani dialects and this group is based onhttps://www.ethnologue.com/ subgroups/romani. Many of these dialect groups are highly endangered, with the most common dialect family being Vlax Romani. -

Report on Romani Language
ROMANINET- A MULTIMEDIA ROMANI COURSE FOR PROMOTING LINGUISTIC DIVERSITY AND IMPROVING SOCIAL DIALOGUE: REPORT ON ROMANI LANGUAGE 1 Instituto de Enseñanza Secundaria Ribeira do Louro (Spain), Asesoramiento, Tecnología e Investigación S.L. (Spain), Fundación Secretariado Gitano (Spain), "ETHNOTOLERANCE" (Bulgary), Secretariado Diocesano de Lisboa da Obra Pastoral dos Ciganos (Portugal), Grup Scolar Industrial Victor Jinga (Romania), SC CONCEPT CONSULTING SRL (România), University of Manchester (United Kingdom) CONTENT REPORT ON ROMANI LANGUAGE .................................................................2 1. Spoken Dialects ...................................................................................2 2. Geographical spread .............................................................................8 3. Users - by group and number ................................................................. 11 4. The place of the language in the European curriculum .................................. 13 5. Educational materials and other information sources available in Romani language18 2 Instituto de Enseñanza Secundaria Ribeira do Louro (Spain), Asesoramiento, Tecnología e Investigación S.L. (Spain), Fundación Secretariado Gitano (Spain), "ETHNOTOLERANCE" (Bulgary), Secretariado Diocesano de Lisboa da Obra Pastoral dos Ciganos (Portugal), Grup Scolar Industrial Victor Jinga (Romania), SC CONCEPT CONSULTING SRL (România), University of Manchester (United Kingdom) REPORT ON ROMANI LANGUAGE 1. Spoken Dialects A. Origins and attestation Romani -

Map by Steve Huffman; Data from World Language Mapping System
Svalbard Greenland Jan Mayen Norwegian Norwegian Icelandic Iceland Finland Norway Swedish Sweden Swedish Faroese FaroeseFaroese Faroese Faroese Norwegian Russia Swedish Swedish Swedish Estonia Scottish Gaelic Russian Scottish Gaelic Scottish Gaelic Latvia Latvian Scots Denmark Scottish Gaelic Danish Scottish Gaelic Scottish Gaelic Danish Danish Lithuania Lithuanian Standard German Swedish Irish Gaelic Northern Frisian English Danish Isle of Man Northern FrisianNorthern Frisian Irish Gaelic English United Kingdom Kashubian Irish Gaelic English Belarusan Irish Gaelic Belarus Welsh English Western FrisianGronings Ireland DrentsEastern Frisian Dutch Sallands Irish Gaelic VeluwsTwents Poland Polish Irish Gaelic Welsh Achterhoeks Irish Gaelic Zeeuws Dutch Upper Sorbian Russian Zeeuws Netherlands Vlaams Upper Sorbian Vlaams Dutch Germany Standard German Vlaams Limburgish Limburgish PicardBelgium Standard German Standard German WalloonFrench Standard German Picard Picard Polish FrenchLuxembourgeois Russian French Czech Republic Czech Ukrainian Polish French Luxembourgeois Polish Polish Luxembourgeois Polish Ukrainian French Rusyn Ukraine Swiss German Czech Slovakia Slovak Ukrainian Slovak Rusyn Breton Croatian Romanian Carpathian Romani Kazakhstan Balkan Romani Ukrainian Croatian Moldova Standard German Hungary Switzerland Standard German Romanian Austria Greek Swiss GermanWalser CroatianStandard German Mongolia RomanschWalser Standard German Bulgarian Russian France French Slovene Bulgarian Russian French LombardRomansch Ladin Slovene Standard -

Poland 1St Report Public EN Prov
Strasbourg, 7 December 2011 ECRML (2011) 5 EUROPEAN CHARTER FOR REGIONAL OR MINORITY LANGUAGES APPLICATION OF THE CHARTER IN POLAND Initial monitoring cycle A. Report of the Committee of Experts on the Charter B. Recommendation of the Committee of Ministers of the Council of Europe on the application of the Charter by Poland The European Charter for Regional or Minority Languages provides for a control mechanism to evaluate how the Charter is applied in a State Party with a view to, where necessary, making Recommendations for improvements in its legislation, policy and practices. The central element of this procedure is the Committee of Experts, established in accordance with Article 17 of the Charter. Its principal purpose is to examine the real situation of the regional or minority languages in the State, to report to the Committee of Ministers on its evaluation of compliance by a Party with its undertakings, and, where appropriate, to encourage the Party to gradually reach a higher level of commitment. To facilitate this task, the Committee of Ministers has adopted, in accordance with Article 15.1, an outline for the periodical reports that a Party is required to submit to the Secretary General. The report shall be made public by the government concerned. This outline requires the State to give an account of the concrete application of the Charter, the general policy for the languages protected under its Part II and in more precise terms all measures that have been taken in application of the provisions chosen for each language protected under Part III of the Charter.