The Colon As a Separate Prosodic Category: Tonal Evidence from Paicî (Oceanic, New Caledonia)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Secondary Stress Is Left Edge Marking Quentin Dabouis, Jean-Michel Fournier, Isabelle Girard
Ternarity is not an issue: Secondary stress is left edge marking Quentin Dabouis, Jean-Michel Fournier, Isabelle Girard To cite this version: Quentin Dabouis, Jean-Michel Fournier, Isabelle Girard. Ternarity is not an issue: Secondary stress is left edge marking. 4ème rencontre du GDRI PTA (Phonological Theory Agora), May 2017, Manch- ester, United Kingdom. halshs-02083607 HAL Id: halshs-02083607 https://halshs.archives-ouvertes.fr/halshs-02083607 Submitted on 29 Mar 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. MFM25 Fringe Meeting – PTA Dataset Workshop 24th May 2017, Manchester Suffixal derivatives from free bases, which preserve the stress of their base (see Collie (2007); Dabouis (2016); Hammond (1989); Kiparsky (1979)); e.g. original TERNARITY IS NOT AN ISSUE: SECONDARY STRESS IS LEFT EDGE MARKING > orìginá lity Compounds; e.g. brigadier-general, gender-specific, lady-in-waiting Quentin Dabouis1,2, Jean-Michel Fournier1,2 and Isabelle Girard1,3 ̀ ̀ ́ ̀ ́ ̀ ́ 1Laboratoire Ligérien de Linguistique (UMR 7270) Neoclassical compounds, whose constituents are stress-invariant (Fournier 2010; 2Université de Tours – 3Université du Littoral-Côte d’Opale Guierre 1979); e.g. à goraphó bic, larỳ ngoló gical, ò rthochromá tic Another group of words was left out because they can be related to another form in English, Claim: Secondary stress is only marginally determined by segmental parameters and mainly although they may not be morphologically derived from it (e.g. -

Downstep and Recursive Phonological Phrases in Bàsàá (Bantu A43) Fatima Hamlaoui ZAS, Berlin; University of Toronto Emmanuel-Moselly Makasso ZAS, Berlin
Chapter 9 Downstep and recursive phonological phrases in Bàsàá (Bantu A43) Fatima Hamlaoui ZAS, Berlin; University of Toronto Emmanuel-Moselly Makasso ZAS, Berlin This paper identifies contexts in which a downstep is realized between consecu- tive H tones in absence of an intervening L tone in Bàsàá (Bantu A43, Cameroon). Based on evidence from simple sentences, we propose that this type of downstep is indicative of recursive prosodic phrasing. In particular, we propose that a down- step occurs between the phonological phrases that are immediately dominated by a maximal phonological phrase (휙max). 1 Introduction In their book on the relation between tone and intonation in African languages, Downing & Rialland (2016) describe the study of downtrends as almost being a field in itself in the field of prosody. In line with the considerable literature on the topic, they offer the following decomposition of downtrends: 1. Declination 2. Downdrift (or ‘automatic downstep’) 3. Downstep (or ‘non-automatic downstep’) 4. Final lowering 5. Register compression/expansion or register lowering/raising Fatima Hamlaoui & Emmanuel-Moselly Makasso. 2019. Downstep and recursive phonological phrases in Bàsàá (Bantu A43). In Emily Clem, Peter Jenks & Hannah Sande (eds.), Theory and description in African Linguistics: Selected papers from the47th Annual Conference on African Linguistics, 155–175. Berlin: Language Science Press. DOI:10.5281/zenodo.3367136 Fatima Hamlaoui & Emmanuel-Moselly Makasso In the present paper, which concentrates on Bàsàá, a Narrow Bantu language (A43 in Guthrie’s classification) spoken in the Centre and Littoral regions of Cameroon by approx. 300,000 speakers (Lewis et al. 2015), we will first briefly define and discuss declination and downdrift, as the language displays bothphe- nomena. -

Non-Uniformity in English Secondary Stress: the Role of Ranked and Lexically Specific Constraints* Joe Pater University of Alberta and University of Massachusetts
Phonology 17 (2000) 237–274. Printed in the United Kingdom # 2000 Cambridge University Press Non-uniformity in English secondary stress: the role of ranked and lexically specific constraints* Joe Pater University of Alberta and University of Massachusetts 0 Introduction The principles determining secondary stress placement in English display considerable - (Prince 1993) in their application. While in some contexts a syllable will be stressed if it is heavy, or if it is stressed in the stem of a derived form, in other environments syllable weight and stem stress do not entail secondary stress. To take a relatively straight- forward case, the primary stress of the stems in (1a) is preserved as a secondary stress in the derived forms (cf. monomorphemic TaZ tamagoT uchi with initial stress), but stress preservation systematically fails in words like (1b). Here we have phonologically conditioned non-uniformity; stress preservation on light syllables is blocked in the environment of a following primary stress. (1) a. accre! dit accre' dita! tion b. phone! tic pho' netı!cian ima! gine ima' gina! tion cosme! tic co' smetı!cian orı!ginal orı' gina! lity patho! logy pa' tholo! gical medı!cinal medı' cina! lity tele! pathy te' lepa! thic divı!sible divı' sibı!lity phila! tely phı' late! lic pheno! menon pheno' meno! logy dia! meter dı' ame! tric * Thanks to Eric Bakovic! , Bruce Derwing, Laura Downing, Elan Dresher, Edward Flemming, Heather Goad, Kevin Hynna, Bill Idsardi, Rene! Kager, Greg Lamon- tagne, John McCarthy, Armin Mester, Alan Prince, Doug Pulleyblank, Su Urbanczyk, Wolf Wikeley and the participants in classes at Rutgers University, University of British Columbia, University of Alberta and University of Massa- chusetts, Amherst for help and discussion. -

5 Phonology Florian Lionnet and Larry M
5 Phonology Florian Lionnet and Larry M. Hyman 5.1. Introduction The historical relation between African and general phonology has been a mutu- ally beneficial one: the languages of the African continent provide some of the most interesting and, at times, unusual phonological phenomena, which have con- tributed to the development of phonology in quite central ways. This has been made possible by the careful descriptive work that has been done on African lan- guages, by linguists and non-linguists, and by Africanists and non-Africanists who have peeked in from time to time. Except for the click consonants of the Khoisan languages (which spill over onto some neighboring Bantu languages that have “borrowed” them), the phonological phenomena found in African languages are usually duplicated elsewhere on the globe, though not always in as concen- trated a fashion. The vast majority of African languages are tonal, and many also have vowel harmony (especially vowel height harmony and advanced tongue root [ATR] harmony). Not surprisingly, then, African languages have figured dispro- portionately in theoretical treatments of these two phenomena. On the other hand, if there is a phonological property where African languages are underrepresented, it would have to be stress systems – which rarely, if ever, achieve the complexity found in other (mostly non-tonal) languages. However, it should be noted that the languages of Africa have contributed significantly to virtually every other aspect of general phonology, and that the various developments of phonological theory have in turn often greatly contributed to a better understanding of the phonologies of African languages. Given the considerable diversity of the properties found in different parts of the continent, as well as in different genetic groups or areas, it will not be possible to provide a complete account of the phonological phenomena typically found in African languages, overviews of which are available in such works as Creissels (1994) and Clements (2000). -

The Pronunciation of Vowels with Secondary Stress in English Quentin Dabouis
The pronunciation of vowels with secondary stress in English Quentin Dabouis To cite this version: Quentin Dabouis. The pronunciation of vowels with secondary stress in English. CORELA - COgni- tion, REprésentation, LAngage, CERLICO-Cercle Linguistique du Centre et de l’Ouest (France), In press, pp.16 - 18. halshs-01924966 HAL Id: halshs-01924966 https://halshs.archives-ouvertes.fr/halshs-01924966 Submitted on 18 Dec 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Published in Corela [Online], 16-2 | 2018, Online since 18 December 2018. URL: http://journals.openedition.org/corela/7153 The pronunciation of vowels with secondary stress in English Quentin Dabouis Université Clermont Auvergne – LRL (EA 999) RESUME Peu d’études se sont concentrées sur la prononciation des voyelles sous accent secondaire en anglais. Dans le cadre de l’approche introduite par Guierre (1979), cet article propose une étude empirique large de ces voyelles et se concentre sur trois catégories clés de mots : les mots non-dérivés, les constructions contenant un préfixe sémantiquement transparent et les dérivés suffixaux. Dans leur ensemble, les analyses précédentes fondées sur le rang, les domaines phonologiques et l’isomorphisme dérivationnel sont confirmées mais certains phénomènes mis à jour par cette étude rendent nécessaires quelques révisions des modèles existants. -

Phonetic Correlates of Stress & Prosodic Hierarchy in Estonian
1 PHONETIC CORRELATES OF STRESS AND THE PROSODIC HIERARCHY IN ESTONIAN MATTHEW GORDON University of California, Los Angeles This paper presents results of several experiments designed to examine some of the phonetic properties associated with stress and the prosodic hierarchy in Estonian. Peak nasal flow, amplitude and duration were measured for /n/ in initial position of four domains: the syllable, the word, the phrase and the utterance. These four prosodic positions were cross-classified by two stress levels: stressed and unstressed. To test the importance of the foot as a prosodic constituent in determining segmental durations in Estonian, two types of data were examined. First, the duration of vowels in different positions within the foot and the word were examined to test the hypothesis that feet are isochronously timed in Estonian. A second experiment tested the hypothesis that the longest type of syllable (the overlong syllable) may, under some conditions, constitute a monosyllabic foot, another manifestation of isochrony. Several results emerged from the experiments. First, data from the nasals provided phonetic evidence for the view that utterances in Estonian consist of progressively larger domains or constituents: the syllable, the word, and the phrase. Not all of these domains, however, are equally well differentiated in terms of the phonetic properties examined in this paper. Second, tentative results suggest that certain durational properties are determined by the foot, while others appear to be a function of domains larger than the foot, in particular the word. Finally, stressed syllables are differentiated from unstressed syllables along subtle and typologically unusual, but nevertheless consistent, acoustic and articulatory parameters.* 1. -

Chapter 1 Theoretical Issues
Chapter 1 Theoretical issues —… no language has a rule stressing the penultimate syllable unless it begins with a voiced consonant, in which case one stresses the antepenultimate syllable“ (Hyman 1985: 96) —(Karo) stress can be predicted by the onset of the last syllable: if it is a voiced stop consonant, then the stress shifts one syllable to the left“ (Gabas 1999: 39) 1.1 Syllable weight The notion of syllable weight is pervasive in phonology. Everywhere we look there are data that make reference to it. The idea behind syllable weight is that depending on their structure, syllables are treated in a different way; thus if a syllable contains a long vowel or - in some languages - a short vowel followed by a coda consonant, then it is heavier than one including a short vowel, i.e. VV, VC > V. The effects of this distinction are most prominently seen in stress, where in many languages heavy syllables attract stress more than light ones. Importantly, VC is heavy in some languages, e.g. Hopi, but light in others, e.g. Lenakel (see below). In Hopi (Gussenhoven and Jacobs 2005: 145), the first syllable is stressed if it is heavy (C)VV or (C)VC [(1a)], but if it is (C)V light, then the second gets stress [(1b)]1. (1) Hopi: VV/VC=heavy; V=light a. q1q .t1.som.pi ‘headbands’ soÂ9.ja ‘planting stick’ b. q1.t1. som.pi ‘headband’ ko.jo. Mo ‘turkey’ 1 In this chapter, unless stated otherwise, the acute accent marks primary stress, the grave accent means secondary stress, and underlining denotes the reduplicated portion. -

A Phonological and Phonetic Study of Word-Level Stress in Chickasaw
A phonological and phonetic study of word-level stress in Chickasaw Matthew Gordon University of California, Santa Barbara This paper presents results of a phonological and phonetic study of stress in Chickasaw, a Muskogean language spoken in south central Oklahoma. Three degrees of stress are differentiated acoustically, with primary stressed vowels having the highest f0 and greatest duration and intensity, unstressed vowels having the lowest f0 and shortest duration and intensity, and secondary stressed vowels displaying intermediate f0, duration, and intensity values. Vowel quality differences and segmental lenition processes also are diagnostic for stress. The location of stress is phonologically predictable, falling on word-final syllables, heavy (CVC and CVV) syllables and on the second in a sequence of light (CV) syllables. Short vowels in non-final open syllables are made heavy through a process of rhythmic vowel lengthening. Primary stress is sensitive to a further weight distinction, treating CVV as heavier than both CV and CVC. In words lacking a CVV syllable, stress falls on the final syllable. 1. Introduction Languages differ in how they realize stress acoustically. Typically, stressed syllables are associated with some combination of the following properties: heightened fundamental frequency (f0), increased loudness, greater duration, and more peripheral vowel qualities, e.g. English (Fry 1955, Beckman 1986), Russian (Bondarko et al. 1973), Polish (Jassem et al. 1968), Mari (Baitschura 1976), Indonesian (Adisasmito-Smith and Cohn 1996), Tagalog (Gonzalez 1970), Dutch (Sluijter and van Heuven 1996), Pirahã (Everett 1998). While a relatively large body of literature has been devoted to acoustic investigation of stress, there is a paucity of quantitative phonetic data on stress in American Indian languages. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

An Instrumental Study of Vowel Reduction and Stress Placement in Spanish-Accented English
SSLA. 11. 35-62. Printed in the United States of America. -------- -.- AN INSTRUMENTAL STUDY OF VOWEL REDUCTION AND STRESS PLACEMENT IN SPANISH-ACCENTED ENGLISH James Emil Flege Ocke-Schwen Bohn University of Alabama, Birmingham Morphophonological alternations in English words such as able versus ability involve changes in both stress and vowel quality. This study examined how native speakers of Spanish and English produced four such morphologically related English word pairs. Degree of stress and vowel quality was assessed auditorily and instrumentally. Stress placement generally seemed to constitute less of a learning problem for the native Spanish speakers than vowel reduction. The results suggest that Englishlike stress placement is acquired earlier than vowel reduction and that the ability to unstress vowels is a necessary, but not sufficient, condition for vowel reduction. The magnitude of stress and vowel quality differences for the four word pairs suggests that L2 learners acquire stress placement and vowel reduction in English on a word-by-word basis. INTRODUCTION Many second language (12) learners retain a foreign accent long after achieving proficiency in other aspects of 12 production. A foreign accent may result from segmental substitutions of replica for model sounds as well as non-12-like rhythmic, intonational, and stress patterns (Flege, )984). Even though it is generally agreed that This study was supported by NIH grant NS20963-04. The authors would like to thank Sherry Sutphin for fabricating the pseudopalates and for data analysis. ~ 1969 Cambridge Univenity Press OZ7Z·Z63 1/69 $5.00 + .00 3S 36 James Emil Flege and Ocke-Schwen Bohn the use of full instead of reduced vowels in unstressed syllables may contribute impor• tantly to foreign accent and this phenomenon "is extremely typical" (Hammond, 1986) in Spanish-accented English, to our knowledge it has never been examined empirically. -

Morphological Sources of Phonological Length
Morphological Sources of Phonological Length by Anne Pycha B.A. (Brown University) 1993 M.A. (University of California, Berkeley) 2004 A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Linguistics in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Sharon Inkelas (chair) Professor Larry Hyman Professor Keith Johnson Professor Johanna Nichols Spring 2008 Abstract Morphological Sources of Phonological Length by Anne Pycha Doctor of Philosophy in Linguistics University of California, Berkeley Professor Sharon Inkelas, Chair This study presents and defends Resizing Theory, whose claim is that the overall size of a morpheme can serve as a basic unit of analysis for phonological alternations. Morphemes can increase their size by any number of strategies -- epenthesizing new segments, for example, or devoicing an existing segment (and thereby increasing its phonetic duration) -- but it is the fact of an increase, and not the particular strategy used to implement it, which is linguistically significant. Resizing Theory has some overlap with theories of fortition and lenition, but differs in that it uses the independently- verifiable parameter of size in place of an ad-hoc concept of “strength” and thereby encompasses a much greater range of phonological alternations. The theory makes three major predictions, each of which is supported with cross-linguistic evidence. First, seemingly disparate phonological alternations can achieve identical morphological effects, but only if they trigger the same direction of change in a morpheme’s size. Second, morpheme interactions can take complete control over phonological outputs, determining surface outputs when traditional features and segments fail to do so. -
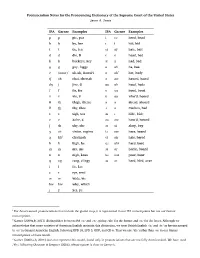
Pronunciation Notes (PDF)
Pronunciation Notes for the Pronouncing Dictionary of the Supreme Court of the United States Jason A. Zentz IPA Garner Examples IPA Garner Examples p p pie, pea i ee heed, bead b b by, bee ɪ i hid, bid t t tie, tea eɪ ay hate, bait d d die, D ɛ e head, bed k k buckeye, key æ a had, bad ɡ g guy, foggy ɑ ah ha, baa ʔ (none)1 uh-uh, Hawaiʻi ɑ ah2 hot, body tʃ ch chai, cheetah ɔ aw hawed, bawd dʒ j jive, G oʊ oh hoed, bode f f fie, fee ʊ uu hood, book v v vie, V u oo whoʼd, booed θ th thigh, theme ə ə ahead, aboard ð th thy, thee ʌ ə Hudson, bud s s sigh, sea aɪ ɪ hide, bide z z Zaire, Z aʊ ow howʼd, bowed ʃ sh shy, she ɔɪ oi ahoy, boy ʒ zh vision, regime iɹ eer here, beard χ kh3 chutzpah ɛɹ air hair, bared h h high, he ɑɹ ahr hard, bard m m my, me ɔɹ or horde, board n n nigh, knee uɹ oor poor, boor ŋ ng rang, clingy əɹ ər herd, bird, over l l lie, Lee ɹ r rye, reed w w wide, we hw hw why, which j y yes, ye 1 For Americanized pronunciations that include the glottal stop, it is represented in our IPA transcriptions but not our Garner transcriptions. 2 Garner (2009a,b, 2011) distinguishes between IPA /ɑ/ and /ɒ/, giving /ah/ for the former and /o/ for the latter.