Intel X86 Assembly Fundamentals
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Copy on Write Based File Systems Performance Analysis and Implementation
Copy On Write Based File Systems Performance Analysis And Implementation Sakis Kasampalis Kongens Lyngby 2010 IMM-MSC-2010-63 Technical University of Denmark Department Of Informatics Building 321, DK-2800 Kongens Lyngby, Denmark Phone +45 45253351, Fax +45 45882673 [email protected] www.imm.dtu.dk Abstract In this work I am focusing on Copy On Write based file systems. Copy On Write is used on modern file systems for providing (1) metadata and data consistency using transactional semantics, (2) cheap and instant backups using snapshots and clones. This thesis is divided into two main parts. The first part focuses on the design and performance of Copy On Write based file systems. Recent efforts aiming at creating a Copy On Write based file system are ZFS, Btrfs, ext3cow, Hammer, and LLFS. My work focuses only on ZFS and Btrfs, since they support the most advanced features. The main goals of ZFS and Btrfs are to offer a scalable, fault tolerant, and easy to administrate file system. I evaluate the performance and scalability of ZFS and Btrfs. The evaluation includes studying their design and testing their performance and scalability against a set of recommended file system benchmarks. Most computers are already based on multi-core and multiple processor architec- tures. Because of that, the need for using concurrent programming models has increased. Transactions can be very helpful for supporting concurrent program- ming models, which ensure that system updates are consistent. Unfortunately, the majority of operating systems and file systems either do not support trans- actions at all, or they simply do not expose them to the users. -

The Linux Kernel Module Programming Guide
The Linux Kernel Module Programming Guide Peter Jay Salzman Michael Burian Ori Pomerantz Copyright © 2001 Peter Jay Salzman 2007−05−18 ver 2.6.4 The Linux Kernel Module Programming Guide is a free book; you may reproduce and/or modify it under the terms of the Open Software License, version 1.1. You can obtain a copy of this license at http://opensource.org/licenses/osl.php. This book is distributed in the hope it will be useful, but without any warranty, without even the implied warranty of merchantability or fitness for a particular purpose. The author encourages wide distribution of this book for personal or commercial use, provided the above copyright notice remains intact and the method adheres to the provisions of the Open Software License. In summary, you may copy and distribute this book free of charge or for a profit. No explicit permission is required from the author for reproduction of this book in any medium, physical or electronic. Derivative works and translations of this document must be placed under the Open Software License, and the original copyright notice must remain intact. If you have contributed new material to this book, you must make the material and source code available for your revisions. Please make revisions and updates available directly to the document maintainer, Peter Jay Salzman <[email protected]>. This will allow for the merging of updates and provide consistent revisions to the Linux community. If you publish or distribute this book commercially, donations, royalties, and/or printed copies are greatly appreciated by the author and the Linux Documentation Project (LDP). -

Use of Seek When Writing Or Reading Binary Files
Title stata.com file — Read and write text and binary files Description Syntax Options Remarks and examples Stored results Reference Also see Description file is a programmer’s command and should not be confused with import delimited (see [D] import delimited), infile (see[ D] infile (free format) or[ D] infile (fixed format)), and infix (see[ D] infix (fixed format)), which are the usual ways that data are brought into Stata. file allows programmers to read and write both text and binary files, so file could be used to write a program to input data in some complicated situation, but that would be an arduous undertaking. Files are referred to by a file handle. When you open a file, you specify the file handle that you want to use; for example, in . file open myfile using example.txt, write myfile is the file handle for the file named example.txt. From that point on, you refer to the file by its handle. Thus . file write myfile "this is a test" _n would write the line “this is a test” (without the quotes) followed by a new line into the file, and . file close myfile would then close the file. You may have multiple files open at the same time, and you may access them in any order. 1 2 file — Read and write text and binary files Syntax Open file file open handle using filename , read j write j read write text j binary replace j append all Read file file read handle specs Write to file file write handle specs Change current location in file file seek handle query j tof j eof j # Set byte order of binary file file set handle byteorder hilo j lohi j 1 j 2 Close -

File Storage Techniques in Labview
File Storage Techniques in LabVIEW Starting with a set of data as if it were generated by a daq card reading two channels and 10 samples per channel, we end up with the following array: Note that the first radix is the channel increment, and the second radix is the sample number. We will use this data set for all the following examples. The first option is to send it directly to a spreadsheet file. spreadsheet save of 2D data.png The data is wired to the 2D array input and all the defaults are taken. This will ask for a file name when the program block is run, and create a file with data values, separated by tab characters, as follows: 1.000 2.000 3.000 4.000 5.000 6.000 7.000 8.000 9.000 10.000 10.000 20.000 30.000 40.000 50.000 60.000 70.000 80.000 90.000 100.000 Note that each value is in the format x.yyy, with the y's being zeros. The default format for the write to spreadsheet VI is "%.3f" which will generate a floating point number with 3 decimal places. If a number with higher decimal places is entered in the array, it would be truncated to three. Since the data file is created in row format, and what you really need if you are going to import it into excel, is column format. There are two ways to resolve this, the first is to set the transpose bit on the write function, and the second, is to add an array transpose, located in the array pallet. -

System Calls System Calls
System calls We will investigate several issues related to system calls. Read chapter 12 of the book Linux system call categories file management process management error handling note that these categories are loosely defined and much is behind included, e.g. communication. Why? 1 System calls File management system call hierarchy you may not see some topics as part of “file management”, e.g., sockets 2 System calls Process management system call hierarchy 3 System calls Error handling hierarchy 4 Error Handling Anything can fail! System calls are no exception Try to read a file that does not exist! Error number: errno every process contains a global variable errno errno is set to 0 when process is created when error occurs errno is set to a specific code associated with the error cause trying to open file that does not exist sets errno to 2 5 Error Handling error constants are defined in errno.h here are the first few of errno.h on OS X 10.6.4 #define EPERM 1 /* Operation not permitted */ #define ENOENT 2 /* No such file or directory */ #define ESRCH 3 /* No such process */ #define EINTR 4 /* Interrupted system call */ #define EIO 5 /* Input/output error */ #define ENXIO 6 /* Device not configured */ #define E2BIG 7 /* Argument list too long */ #define ENOEXEC 8 /* Exec format error */ #define EBADF 9 /* Bad file descriptor */ #define ECHILD 10 /* No child processes */ #define EDEADLK 11 /* Resource deadlock avoided */ 6 Error Handling common mistake for displaying errno from Linux errno man page: 7 Error Handling Description of the perror () system call. -

Ext4 File System and Crash Consistency
1 Ext4 file system and crash consistency Changwoo Min 2 Summary of last lectures • Tools: building, exploring, and debugging Linux kernel • Core kernel infrastructure • Process management & scheduling • Interrupt & interrupt handler • Kernel synchronization • Memory management • Virtual file system • Page cache and page fault 3 Today: ext4 file system and crash consistency • File system in Linux kernel • Design considerations of a file system • History of file system • On-disk structure of Ext4 • File operations • Crash consistency 4 File system in Linux kernel User space application (ex: cp) User-space Syscalls: open, read, write, etc. Kernel-space VFS: Virtual File System Filesystems ext4 FAT32 JFFS2 Block layer Hardware Embedded Hard disk USB drive flash 5 What is a file system fundamentally? int main(int argc, char *argv[]) { int fd; char buffer[4096]; struct stat_buf; DIR *dir; struct dirent *entry; /* 1. Path name -> inode mapping */ fd = open("/home/lkp/hello.c" , O_RDONLY); /* 2. File offset -> disk block address mapping */ pread(fd, buffer, sizeof(buffer), 0); /* 3. File meta data operation */ fstat(fd, &stat_buf); printf("file size = %d\n", stat_buf.st_size); /* 4. Directory operation */ dir = opendir("/home"); entry = readdir(dir); printf("dir = %s\n", entry->d_name); return 0; } 6 Why do we care EXT4 file system? • Most widely-deployed file system • Default file system of major Linux distributions • File system used in Google data center • Default file system of Android kernel • Follows the traditional file system design 7 History of file system design 8 UFS (Unix File System) • The original UNIX file system • Design by Dennis Ritche and Ken Thompson (1974) • The first Linux file system (ext) and Minix FS has a similar layout 9 UFS (Unix File System) • Performance problem of UFS (and the first Linux file system) • Especially, long seek time between an inode and data block 10 FFS (Fast File System) • The file system of BSD UNIX • Designed by Marshall Kirk McKusick, et al. -

Lecture Notes in Assembly Language
Lecture Notes in Assembly Language Short introduction to low-level programming Piotr Fulmański Łódź, 12 czerwca 2015 Spis treści Spis treści iii 1 Before we begin1 1.1 Simple assembler.................................... 1 1.1.1 Excercise 1 ................................... 2 1.1.2 Excercise 2 ................................... 3 1.1.3 Excercise 3 ................................... 3 1.1.4 Excercise 4 ................................... 5 1.1.5 Excercise 5 ................................... 6 1.2 Improvements, part I: addressing........................... 8 1.2.1 Excercise 6 ................................... 11 1.3 Improvements, part II: indirect addressing...................... 11 1.4 Improvements, part III: labels............................. 18 1.4.1 Excercise 7: find substring in a string .................... 19 1.4.2 Excercise 8: improved polynomial....................... 21 1.5 Improvements, part IV: flag register ......................... 23 1.6 Improvements, part V: the stack ........................... 24 1.6.1 Excercise 12................................... 26 1.7 Improvements, part VI – function stack frame.................... 29 1.8 Finall excercises..................................... 34 1.8.1 Excercise 13................................... 34 1.8.2 Excercise 14................................... 34 1.8.3 Excercise 15................................... 34 1.8.4 Excercise 16................................... 34 iii iv SPIS TREŚCI 1.8.5 Excercise 17................................... 34 2 First program 37 2.1 Compiling, -

File Handling in Python
hapter C File Handling in 2 Python There are many ways of trying to understand programs. People often rely too much on one way, which is called "debugging" and consists of running a partly- understood program to see if it does what you expected. Another way, which ML advocates, is to install some means of understanding in the very programs themselves. — Robin Milner In this Chapter » Introduction to Files » Types of Files » Opening and Closing a 2.1 INTRODUCTION TO FILES Text File We have so far created programs in Python that » Writing to a Text File accept the input, manipulate it and display the » Reading from a Text File output. But that output is available only during » Setting Offsets in a File execution of the program and input is to be entered through the keyboard. This is because the » Creating and Traversing a variables used in a program have a lifetime that Text File lasts till the time the program is under execution. » The Pickle Module What if we want to store the data that were input as well as the generated output permanently so that we can reuse it later? Usually, organisations would want to permanently store information about employees, inventory, sales, etc. to avoid repetitive tasks of entering the same data. Hence, data are stored permanently on secondary storage devices for reusability. We store Python programs written in script mode with a .py extension. Each program is stored on the secondary device as a file. Likewise, the data entered, and the output can be stored permanently into a file. -

System Calls and Standard I/O
System Calls and Standard I/O Professor Jennifer Rexford http://www.cs.princeton.edu/~jrex 1 Goals of Today’s Class • System calls o How a user process contacts the Operating System o For advanced services that may require special privilege • Standard I/O library o Generic I/O support for C programs o A smart wrapper around I/O-related system calls o Stream concept, line-by-line input, formatted output, ... 2 1 System Calls 3 Communicating With the OS User Process signals systems calls Operating System • System call o Request to the operating system to perform a task o … that the process does not have permission to perform • Signal o Asynchronous notification sent to a process … to notify the process of an event that has occurred o 4 2 Processor Modes • The OS must restrict what a user process can do o What instructions can execute o What portions of the address space are accessible • Supervisor mode (or kernel mode) o Can execute any instructions in the instruction set – Including halting the processor, changing mode bit, initiating I/O o Can access any memory location in the system – Including code and data in the OS address space • User mode o Restricted capabilities – Cannot execute privileged instructions – Cannot directly reference code or data in OS address space o Any such attempt results in a fatal “protection fault” – Instead, access OS code and data indirectly via system calls 5 Main Categories of System Calls • File system o Low-level file I/O o E.g., creat, open, read, write, lseek, close • Multi-tasking mechanisms o Process -

Introduction to X86 Assembly
CS342 Computer Security Handout # 5 Prof. Lyn Turbak Monday, Oct. 04, 2010 Wellesley College Lab 4: Introduction to x86 Assembly Reading: Hacking, 0x250, 0x270 Overview Today, we continue to cover low-level programming details that are essential for understanding software vulnerabilities like buffer overflow attacks and format string exploits. You will get exposure to the following: • Understanding conventions used by compiler to translate high-level programs to low-level assembly code (in our case, using Gnu C Compiler (gcc) to compile C programs). • The ability to read low-level assembly code (in our case, Intel x86). • Understanding how assembly code instructions are represented as machine code. • Being able to use gdb (the Gnu Debugger) to read the low-level code produced by gcc and understand its execution. In tutorials based on this handout, we will learn about all of the above in the context of some simple examples. Intel x86 Assembly Language Since Intel x86 processors are ubiquitous, it is helpful to know how to read assembly code for these processors. We will use the following terms: byte refers to 8-bit quantities; short word refers to 16-bit quantities; word refers to 32-bit quantities; and long word refers to 64-bit quantities. There are many registers, but we mostly care about the following: • EAX, EBX, ECX, EDX are 32-bit registers used for general storage. • ESI and EDI are 32-bit indexing registers that are sometimes used for general storage. • ESP is the 32-bit register for the stack pointer, which holds the address of the element currently at the top of the stack. -

Filesystem Considerations for Embedded Devices ELC2015 03/25/15
Filesystem considerations for embedded devices ELC2015 03/25/15 Tristan Lelong Senior embedded software engineer Filesystem considerations ABSTRACT The goal of this presentation is to answer a question asked by several customers: which filesystem should you use within your embedded design’s eMMC/SDCard? These storage devices use a standard block interface, compatible with traditional filesystems, but constraints are not those of desktop PC environments. EXT2/3/4, BTRFS, F2FS are the first of many solutions which come to mind, but how do they all compare? Typical queries include performance, longevity, tools availability, support, and power loss robustness. This presentation will not dive into implementation details but will instead summarize provided answers with the help of various figures and meaningful test results. 2 TABLE OF CONTENTS 1. Introduction 2. Block devices 3. Available filesystems 4. Performances 5. Tools 6. Reliability 7. Conclusion Filesystem considerations ABOUT THE AUTHOR • Tristan Lelong • Embedded software engineer @ Adeneo Embedded • French, living in the Pacific northwest • Embedded software, free software, and Linux kernel enthusiast. 4 Introduction Filesystem considerations Introduction INTRODUCTION More and more embedded designs rely on smart memory chips rather than bare NAND or NOR. This presentation will start by describing: • Some context to help understand the differences between NAND and MMC • Some typical requirements found in embedded devices designs • Potential filesystems to use on MMC devices 6 Filesystem considerations Introduction INTRODUCTION Focus will then move to block filesystems. How they are supported, what feature do they advertise. To help understand how they compare, we will present some benchmarks and comparisons regarding: • Tools • Reliability • Performances 7 Block devices Filesystem considerations Block devices MMC, EMMC, SD CARD Vocabulary: • MMC: MultiMediaCard is a memory card unveiled in 1997 by SanDisk and Siemens based on NAND flash memory. -
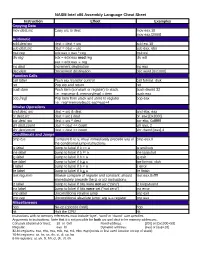
NASM Intel X86 Assembly Language Cheat Sheet
NASM Intel x86 Assembly Language Cheat Sheet Instruction Effect Examples Copying Data mov dest,src Copy src to dest mov eax,10 mov eax,[2000] Arithmetic add dest,src dest = dest + src add esi,10 sub dest,src dest = dest – src sub eax, ebx mul reg edx:eax = eax * reg mul esi div reg edx = edx:eax mod reg div edi eax = edx:eax reg inc dest Increment destination inc eax dec dest Decrement destination dec word [0x1000] Function Calls call label Push eip, transfer control call format_disk ret Pop eip and return ret push item Push item (constant or register) to stack. push dword 32 I.e.: esp=esp-4; memory[esp] = item push eax pop [reg] Pop item from stack and store to register pop eax I.e.: reg=memory[esp]; esp=esp+4 Bitwise Operations and dest, src dest = src & dest and ebx, eax or dest,src dest = src | dest or eax,[0x2000] xor dest, src dest = src ^ dest xor ebx, 0xfffffff shl dest,count dest = dest << count shl eax, 2 shr dest,count dest = dest >> count shr dword [eax],4 Conditionals and Jumps cmp b,a Compare b to a; must immediately precede any of cmp eax,0 the conditional jump instructions je label Jump to label if b == a je endloop jne label Jump to label if b != a jne loopstart jg label Jump to label if b > a jg exit jge label Jump to label if b > a jge format_disk jl label Jump to label if b < a jl error jle label Jump to label if b < a jle finish test reg,imm Bitwise compare of register and constant; should test eax,0xffff immediately precede the jz or jnz instructions jz label Jump to label if bits were not set (“zero”) jz looparound jnz label Jump to label if bits were set (“not zero”) jnz error jmp label Unconditional relative jump jmp exit jmp reg Unconditional absolute jump; arg is a register jmp eax Miscellaneous nop No-op (opcode 0x90) nop hlt Halt the CPU hlt Instructions with no memory references must include ‘byte’, ‘word’ or ‘dword’ size specifier.