Analyzing Source Code Across Static Conditionals
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Multiprocessor Initialization of INTEL SOC in Coreboot
Multiprocessor Initialization OF INTEL SOC in Coreboot Pratik Prajapati ([email protected]) Subrata Banik ([email protected]) 1 Agenda • Intel Multiple Processor (MP) Initialization • Coreboot + Intel FSP Boot Flow • Problem with existing model • Solution space • Design • Future Scope 2 Intel Multiple Processor (MP) Initialization • The IA-32 architecture (beginning with the P6 family processors) defines a multiple-processor (MP) initialization protocol called the Multiprocessor Specification Version 1.4. • The MP initialization protocol has the following important features: • It supports controlled booting of multiple processors without requiring dedicated system hardware. • It allows hardware to initiate the booting of a system without the need for a dedicated signal or a predefined boot processor. • It allows all IA-32 processors to be booted in the same manner, including those supporting Intel Hyper-Threading Technology. • The MP initialization protocol also applies to MP systems using Intel 64 processors. • Entire CPU multiprocessor initialization can be divided into two parts – BSP (Boot Strap Processor) Initialization – AP (Application Processor) Initialization Reference: Intel SDM Multiple Processor Init - section 8.4 3 Coreboot + Intel FSP (Firmware support package) Boot Flow Coreboot/BIOS FSP * Coreboot uses its own temp ram init code. 4 Problem Statement with existing model • Background: Coreboot is capable enough to handle multiprocessor initialization on IA platforms. So ideally, CPU features programming can be part of Coreboot MP Init sequence. • But, there might be some cases where certain feature programming can't be done with current flow of MP init sequence. Because, Intel FSP-S has to program certain registers to meet silicon init flow due to SAI (Security Attributes of Initiator) and has to lock other registers before exiting silicon init API. -

Command Line Interface
Command Line Interface Squore 21.0.2 Last updated 2021-08-19 Table of Contents Preface. 1 Foreword. 1 Licence. 1 Warranty . 1 Responsabilities . 2 Contacting Vector Informatik GmbH Product Support. 2 Getting the Latest Version of this Manual . 2 1. Introduction . 3 2. Installing Squore Agent . 4 Prerequisites . 4 Download . 4 Upgrade . 4 Uninstall . 5 3. Using Squore Agent . 6 Command Line Structure . 6 Command Line Reference . 6 Squore Agent Options. 6 Project Build Parameters . 7 Exit Codes. 13 4. Managing Credentials . 14 Saving Credentials . 14 Encrypting Credentials . 15 Migrating Old Credentials Format . 16 5. Advanced Configuration . 17 Defining Server Dependencies . 17 Adding config.xml File . 17 Using Java System Properties. 18 Setting up HTTPS . 18 Appendix A: Repository Connectors . 19 ClearCase . 19 CVS . 19 Folder Path . 20 Folder (use GNATHub). 21 Git. 21 Perforce . 23 PTC Integrity . 25 SVN . 26 Synergy. 28 TFS . 30 Zip Upload . 32 Using Multiple Nodes . 32 Appendix B: Data Providers . 34 AntiC . 34 Automotive Coverage Import . 34 Automotive Tag Import. 35 Axivion. 35 BullseyeCoverage Code Coverage Analyzer. 36 CANoe. 36 Cantata . 38 CheckStyle. .. -

Coreboot - the Free Firmware
coreboot - the free firmware vimacs <https://vimacs.lcpu.club> Linux Club of Peking University May 19th, 2018 . vimacs (LCPU) coreboot - the free firmware May 19th, 2018 1 / 77 License This work is licensed under the Creative Commons Attribution 4.0 International License. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/. You can find the source code of this presentation at: https://git.wehack.space/coreboot-talk/ . vimacs (LCPU) coreboot - the free firmware May 19th, 2018 2 / 77 Index 1 What is coreboot? History Why use coreboot 2 How coreboot works 3 Building and using coreboot Building Flashing 4 Utilities and Debugging 5 Join the community . vimacs (LCPU) coreboot - the free firmware May 19th, 2018 3 / 77 Index 6 Porting coreboot with autoport ASRock B75 Pro3-M Sandy/Ivy Bridge HP Elitebooks Dell Latitude E6230 7 References . vimacs (LCPU) coreboot - the free firmware May 19th, 2018 4 / 77 1 What is coreboot? History Why use coreboot 2 How coreboot works 3 Building and using coreboot Building Flashing 4 Utilities and Debugging 5 Join the community . vimacs (LCPU) coreboot - the free firmware May 19th, 2018 5 / 77 What is coreboot? coreboot is an extended firmware platform that delivers a lightning fast and secure boot experience on modern computers and embedded systems. As an Open Source project it provides auditability and maximum control over technology. The word ’coreboot’ should always be written in lowercase, even at the start of a sentence. vimacs (LCPU) coreboot - the free firmware May 19th, 2018 6 / 77 History: from LinuxBIOS to coreboot coreboot has a very long history, stretching back more than 18 years to when it was known as LinuxBIOS. -

Coverity Static Analysis
Coverity Static Analysis Quickly find and fix Overview critical security and Coverity® gives you the speed, ease of use, accuracy, industry standards compliance, and quality issues as you scalability that you need to develop high-quality, secure applications. Coverity identifies code critical software quality defects and security vulnerabilities in code as it’s written, early in the development process when it’s least costly and easiest to fix. Precise actionable remediation advice and context-specific eLearning help your developers understand how to fix their prioritized issues quickly, without having to become security experts. Coverity Benefits seamlessly integrates automated security testing into your CI/CD pipelines and supports your existing development tools and workflows. Choose where and how to do your • Get improved visibility into development: on-premises or in the cloud with the Polaris Software Integrity Platform™ security risk. Cross-product (SaaS), a highly scalable, cloud-based application security platform. Coverity supports 22 reporting provides a holistic, more languages and over 70 frameworks and templates. complete view of a project’s risk using best-in-class AppSec tools. Coverity includes Rapid Scan, a fast, lightweight static analysis engine optimized • Deployment flexibility. You for cloud-native applications and Infrastructure-as-Code (IaC). Rapid Scan runs decide which set of projects to do automatically, without additional configuration, with every Coverity scan and can also AppSec testing for: on-premises be run as part of full CI builds with conventional scan completion times. Rapid Scan can or in the cloud. also be deployed as a standalone scan engine in Code Sight™ or via the command line • Shift security testing left. -

A Comparison of SPARK with MISRA C and Frama-C
A Comparison of SPARK with MISRA C and Frama-C Johannes Kanig, AdaCore October 2018 Abstract Both SPARK and MISRA C are programming languages intended for high-assurance applications, i.e., systems where reliability is critical and safety and/or security requirements must be met. This document summarizes the two languages, compares them with respect to how they help satisfy high-assurance requirements, and compares the SPARK technology to several static analysis tools available for MISRA C with a focus on Frama-C. 1 Introduction 1.1 SPARK Overview Ada [1] is a general-purpose programming language that has been specifically designed for safe and secure programming. Information on how Ada satisfies the requirements for high-assurance software, including the avoidance of vulnerabilities that are found in other languages, may be found in [2, 3, 4]. SPARK [5, 6] is an Ada subset that is amenable to formal analysis and thus can bring increased confidence to software requiring the highest levels of assurance. SPARK excludes features that are difficult to analyze (such as pointers and exception handling). Its restrictions guarantee the absence of unspecified behavior such as reading the value of an uninitialized variable, or depending on the evaluation order of expressions with side effects. But SPARK does include major Ada features such as generic templates and object-oriented programming, as well as a simple but expressive set of concurrency (tasking) features known as the Ravenscar profile. SPARK has been used in a variety of high-assurance applications, including hypervisor kernels, air traffic management, and aircraft avionics. In fact, SPARK is more than just a subset of Ada. -

Quadcore with Coreboot / Libreboot on the T500 (Hopefully the T400 As Well)
QuadCore with Coreboot / Libreboot on the T500 (hopefully the T400 as well) (Translator’s note: Unfortunately, I couldn’t get pdflatex to compile with images, so here’s the link, I’ll put lines in at least so that you can see where each image goes) I tested the quadcore-mod from here first on a T500 mainboard, but back then, the BIOS did me a great disservice, see here and read the paragraph “Why this can’t be done for the T500 and W500” at the end of the first post. Meanwhile, we got Libreboot for the T500, which is basically Coreboot without BLOBs, i.e. CPU microcode. The code differs from coreboot in certain other aspects, however I don’t know exactly. With the ROMs offered for the T500, Quads don’t work either. Finally, I got to actually using a Pandaboard to debug Libreboot’s boot process with a Quad-core installed. The boot process hangs when the third CPU is to be initialized. Looking at the code, I found out that the kconfig data is built to the original specs. In the case of the T500 (which takes the data from the folder for the T400), the maximum count for the CPU is set to two. I changed the count to 4, generated the ROM again, flashed it –> You got quadcore. Because the current Libreboot version doesn’t support screens larger than 1280x800 with the T500, I had to extract the original VGA-BIOS for the Intel graphics from the original Lenovo BIOS and integrate it instead of the “native VGA init” into the ROM. -

How to Create a Trust Anchor with Coreboot
How to create a trust anchor with coreboot. Trusted Computing vs Authenticated Code Modules Philipp Deppenwiese About myself Member of a hackerspace in germany. 10 years of experience in it-security. Did a lot work on trusted computing and system security at my last job at Rohde and Schwarz Cybersecurity. I am a Gentoo user. Now I am a web developer and system administrator. Basics Important acronyms TPM - Trusted Platform Module TCB - Trusted Computing Base PCR - Platform Conguration Register ACM - Authenticated Code Modules PKI - Public Key Infrastructure TEE - Trusted Execution Environment TPM Trusted Platform Modules are smartcards with extra feature set. Version 1.2 and 2.0 are out. www.trustedcomputinggroup.org does the specication and compliance. The authorization is done via ownership model. User can own the TPM. A TPM is always passive and not active ! TPM 1.2 Created for Digital Rights Management but never used for it. Huge portests in the internet done by the FSF. TCG stepped back and modied the specication in order to provide an ownership model, DAA and revokable Endorsement Key in order to stop identication and provide full control. Algorithm sizes are limited RSA-2048 and SHA-1. There is one open source software stack. TPM 1.2 TPM 2.0 Mainly build for Microsoft! Compliance testsuite and everything else was designed for Windows usage only. Specication was removed shortly after it appeared. You can't nd it on the internet. Supports modern cryptographic algorithms. TPM 2.0 Two software stacks. IBM and Intel. TPM architecture/hierachy got much more complex. Protected against bus attacks by having DH key exchange to establish a secure connection. -
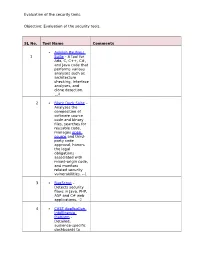
Evaluation of the Security Tools. SL No. Tool Name Comments 1
Evaluation of the security tools. Objective: Evaluation of the security tools. SL No. Tool Name Comments Axivion Bauhaus 1 Suite – A tool for Ada, C, C++, C#, and Java code that performs various analyses such as architecture checking, interface analyses, and clone detection. 4 2 Black Duck Suite – Analyzes the composition of software source code and binary files, searches for reusable code, manages open source and third- party code approval, honors the legal obligations associated with mixed-origin code, and monitors related security vulnerabilities. --1 3 BugScout – Detects security flaws in Java, PHP, ASP and C# web applications. -2 4 CAST Application Intelligence Platform – Detailed, audience-specific dashboards to Evaluation of the security tools. measure quality and productivity. 30+ languages, C, C++, Java, .NET, Oracle, PeopleSoft, SAP, Siebel, Spring, Struts, Hibernate and all major databases. 5 ChecKing – Integrated software quality portal that helps manage the quality of all phases of software development. It includes static code analyzers for Java, JSP, Javascript, HTML, XML, .NET (C#, ASP.NET, VB.NET, etc.), PL/SQL, embedded SQL, SAP ABAP IV, Natural/Adabas, C, C++, Cobol, JCL, and PowerBuilder. 6 ConQAT – Continuous quality assessment toolkit that allows flexible configuration of quality analyses (architecture conformance, clone detection, quality metrics, etc.) and dashboards. Supports Java, C#, C++, JavaScript, ABAP, Ada and many other languages. Evaluation of the security tools. 7 Coverity SAVE – A static code analysis tool for C, C++, C# and Java source code. Coverity commercialized a research tool for finding bugs through static analysis, the Stanford Checker, which used abstract interpretation to identify defects in source code. -

Coreboot on RISCV Ron Minnich, Google Thanks to Stefan Reinauer, Duncan Laurie, Patrick Georgi,
coreboot on RISCV Ron Minnich, Google Thanks to Stefan Reinauer, Duncan Laurie, Patrick Georgi, ... Overview ● What firmware is ● What coreboot is ● Why we want it on RISCV ● History of the port ● Structure of the port ● Status ● Lessons learned Firmware, 1974-present, always-on ● Bottom half of the operating system ● Provided an abstract interface (Basic Input Output System, or Platform-independent code, BIOS) to top half loaded from (e.g.) floppy, ● Supported DOS, CP/M, etc. tape, etc. ● Sucked Platform code, on EEPROM ○ Slow or similar ○ No easy bugfix path ○ Not SMP capable Firmware, 1990-2005, “Fire and Forget” ● Just set up bootloader and get out of the way ● Set all the stuff kernels can’t do Linux ○ Magic configuration, etc. ○ Even now, Linux can not do most of what this code does Platform code, get DRAM going, set naughty bits, load ● LinuxBIOS is one example kernel, please go away ● 2000: boot complex server node to Linux in 3 seconds ● 2015: EFI can do the same in 300 seconds Firmware, 2005-present, “The Empire Strikes Back” ● Kernel is Ring 0 ● Hypervisor is Ring -1 ● Firmware is Ring -2 ● Firmware gets hardware going Platform-independent code ● But never goes away ● Sucks Platform code, on EEPROM ○ Slow or similar ○ No easy bugfix path ○ Not SMP capable on x86 ● This model is even being pushed for ARM V8 ○ :-( Why don’t we (ok, I) like persistent firmware? ● It’s just another attack vector ○ Indistinguishable from persistent embedded threat ○ Is the code an exploit or … ○ Not necessary in an open source world ○ Main function -

Reduce Firmware Booting Time in Multi-Threaded Environment
Open Source Firmware Development Reduce Firmware Booting Time Using Multi- Threaded Environment White Paper Revision 001 January 2019 Document Number: 338658-001 You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to grant Intel a non-exclusive, royalty-free license to any patent claim thereafter drafted which includes subject matter disclosed herein. No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document. Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Learn more at Intel.com, or from the OEM or retailer. No computer system can be absolutely secure. Intel does not assume any liability for lost or stolen data or systems or any damages resulting from such losses. The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request. Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade. Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Learn more at intel.com, or from the OEM or retailer. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest Intel product specifications and roadmaps. -

As Focused on Software Tools That Support Software Engineering, Along with Data Structures and Algorithms Generally
PETER C DILLINGER, Ph.D. 2110 N 89th St [email protected] Seattle WA 98103 http://www.peterd.org 404-509-4879 Overview My work in software has focused on software tools that support software engineering, along with data structures and algorithms generally. My core strength is seeing many paths to “success,” so I'm often the person consulted when others think they're stuck. Highlights ♦ Key developer and project lead in adapting and extending the legendary Coverity static analysis engine, for C/C++ bug finding, to find bugs with high accuracy in Java, C#, JavaScript, PHP, Python, Ruby, Swift, and VB. https://www.synopsys.com/blogs/software-security/author/pdillinger/ ♦ Inventor of a fast, scalable, and accurate method of detecting mistyped identifiers in dynamic languages such as JavaScript, PHP, Python, and Ruby without use of a natural language dictionary. Patent pending, app# 20170329697. Coverity feature: https://stackoverflow.com/a/34796105 ♦ Did the impossible with git: on wanting to “copy with history” as part of a refactoring, I quickly developed a way to do it despite the consensus wisdom. https://stackoverflow.com/a/44036771 ♦ Did the impossible with Bloom filters: made the data structure simultaneously fast and accurate with a simple hashing technique, now used in tools including LevelDB and RocksDB. https://en.wikipedia.org/wiki/Bloom_filter (Search "Dillinger") ♦ Early coder / Linux user: started BASIC in 1st grade; first game hack in 3rd grade; learned C in middle school; wrote Tetris in JavaScript in high school (1997); steady Linux user since 1998. Work Coverity, August 2009 to October 2017, acquired by Synopsys in 2014 Software developer, tech lead, and manager for static and dynamic program analysis projects. -

Libreboot – Free Boot Firmware Libreboot Is a Free Boot Firmware for Use on Computers Certified "Respects Your Freedom"
LibreBoot – Free Boot Firmware LibreBoot is a free boot firmware for use on computers certified "Respects Your Freedom". Most x86 computers are designed to run Windows and come with a non-free BIOS or UEFI firmware that often includes some Malware. Windows itself is malware, and Windows licences are often stored in the BIOS on OEM PCs. For the sake of our freedom we replace Windows with a free distribution of GNU/Linux such as Trisquel (an Ubuntu derivative). But we also have to replace the non-free software that initializes the Hardware with free software. Most hardware vendors do not document how to install a different BIOS, and make it hard to install a different one. But there is coreboot, a free BIOS that can run on some computers. Coreboot contains binary blobs, but some systems can stable run without any blobs. LibreBoot also contains documentation how to install a released version of the coreboot firmware on supported hardware such as some older Thinkpads, and scripts to build the firmware from source, for all supported models. Because newer systems are unable to boot without those blobs, there is no support for newer x86 based computers. For Intel based hardware one challenge is the Management Engine (ME), which is designed for remote out of band management. The firmware for the ME is proprietary and it is impossible to run a free replacement, because it is signed using a secret key. However it is possible to remove the ME firmware on some systems so that it is possible to use them in freedom.