As Focused on Software Tools That Support Software Engineering, Along with Data Structures and Algorithms Generally
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

NUMA-Aware Thread Migration for High Performance NVMM File Systems
NUMA-Aware Thread Migration for High Performance NVMM File Systems Ying Wang, Dejun Jiang and Jin Xiong SKL Computer Architecture, ICT, CAS; University of Chinese Academy of Sciences fwangying01, jiangdejun, [email protected] Abstract—Emerging Non-Volatile Main Memories (NVMMs) out considering the NVMM usage on NUMA nodes. Besides, provide persistent storage and can be directly attached to the application threads accessing file system rely on the default memory bus, which allows building file systems on non-volatile operating system thread scheduler, which migrates thread only main memory (NVMM file systems). Since file systems are built on memory, NUMA architecture has a large impact on their considering CPU utilization. These bring remote memory performance due to the presence of remote memory access and access and resource contentions to application threads when imbalanced resource usage. Existing works migrate thread and reading and writing files, and thus reduce the performance thread data on DRAM to solve these problems. Unlike DRAM, of NVMM file systems. We observe that when performing NVMM introduces extra latency and lifetime limitations. This file reads/writes from 4 KB to 256 KB on a NVMM file results in expensive data migration for NVMM file systems on NUMA architecture. In this paper, we argue that NUMA- system (NOVA [47] on NVMM), the average latency of aware thread migration without migrating data is desirable accessing remote node increases by 65.5 % compared to for NVMM file systems. We propose NThread, a NUMA-aware accessing local node. The average bandwidth is reduced by thread migration module for NVMM file system. -

Command Line Interface
Command Line Interface Squore 21.0.2 Last updated 2021-08-19 Table of Contents Preface. 1 Foreword. 1 Licence. 1 Warranty . 1 Responsabilities . 2 Contacting Vector Informatik GmbH Product Support. 2 Getting the Latest Version of this Manual . 2 1. Introduction . 3 2. Installing Squore Agent . 4 Prerequisites . 4 Download . 4 Upgrade . 4 Uninstall . 5 3. Using Squore Agent . 6 Command Line Structure . 6 Command Line Reference . 6 Squore Agent Options. 6 Project Build Parameters . 7 Exit Codes. 13 4. Managing Credentials . 14 Saving Credentials . 14 Encrypting Credentials . 15 Migrating Old Credentials Format . 16 5. Advanced Configuration . 17 Defining Server Dependencies . 17 Adding config.xml File . 17 Using Java System Properties. 18 Setting up HTTPS . 18 Appendix A: Repository Connectors . 19 ClearCase . 19 CVS . 19 Folder Path . 20 Folder (use GNATHub). 21 Git. 21 Perforce . 23 PTC Integrity . 25 SVN . 26 Synergy. 28 TFS . 30 Zip Upload . 32 Using Multiple Nodes . 32 Appendix B: Data Providers . 34 AntiC . 34 Automotive Coverage Import . 34 Automotive Tag Import. 35 Axivion. 35 BullseyeCoverage Code Coverage Analyzer. 36 CANoe. 36 Cantata . 38 CheckStyle. .. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Artificial Intelligence for Understanding Large and Complex
Artificial Intelligence for Understanding Large and Complex Datacenters by Pengfei Zheng Department of Computer Science Duke University Date: Approved: Benjamin C. Lee, Advisor Bruce M. Maggs Jeffrey S. Chase Jun Yang Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Computer Science in the Graduate School of Duke University 2020 Abstract Artificial Intelligence for Understanding Large and Complex Datacenters by Pengfei Zheng Department of Computer Science Duke University Date: Approved: Benjamin C. Lee, Advisor Bruce M. Maggs Jeffrey S. Chase Jun Yang An abstract of a dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Computer Science in the Graduate School of Duke University 2020 Copyright © 2020 by Pengfei Zheng All rights reserved except the rights granted by the Creative Commons Attribution-Noncommercial Licence Abstract As the democratization of global-scale web applications and cloud computing, under- standing the performance of a live production datacenter becomes a prerequisite for making strategic decisions related to datacenter design and optimization. Advances in monitoring, tracing, and profiling large, complex systems provide rich datasets and establish a rigorous foundation for performance understanding and reasoning. But the sheer volume and complexity of collected data challenges existing techniques, which rely heavily on human intervention, expert knowledge, and simple statistics. In this dissertation, we address this challenge using artificial intelligence and make the case for two important problems, datacenter performance diagnosis and datacenter workload characterization. The first thrust of this dissertation is the use of statistical causal inference and Bayesian probabilistic model for datacenter straggler diagnosis. -

Coverity Static Analysis
Coverity Static Analysis Quickly find and fix Overview critical security and Coverity® gives you the speed, ease of use, accuracy, industry standards compliance, and quality issues as you scalability that you need to develop high-quality, secure applications. Coverity identifies code critical software quality defects and security vulnerabilities in code as it’s written, early in the development process when it’s least costly and easiest to fix. Precise actionable remediation advice and context-specific eLearning help your developers understand how to fix their prioritized issues quickly, without having to become security experts. Coverity Benefits seamlessly integrates automated security testing into your CI/CD pipelines and supports your existing development tools and workflows. Choose where and how to do your • Get improved visibility into development: on-premises or in the cloud with the Polaris Software Integrity Platform™ security risk. Cross-product (SaaS), a highly scalable, cloud-based application security platform. Coverity supports 22 reporting provides a holistic, more languages and over 70 frameworks and templates. complete view of a project’s risk using best-in-class AppSec tools. Coverity includes Rapid Scan, a fast, lightweight static analysis engine optimized • Deployment flexibility. You for cloud-native applications and Infrastructure-as-Code (IaC). Rapid Scan runs decide which set of projects to do automatically, without additional configuration, with every Coverity scan and can also AppSec testing for: on-premises be run as part of full CI builds with conventional scan completion times. Rapid Scan can or in the cloud. also be deployed as a standalone scan engine in Code Sight™ or via the command line • Shift security testing left. -

Characterizing, Modeling, and Benchmarking Rocksdb Key-Value
Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook Zhichao Cao, University of Minnesota, Twin Cities, and Facebook; Siying Dong and Sagar Vemuri, Facebook; David H.C. Du, University of Minnesota, Twin Cities https://www.usenix.org/conference/fast20/presentation/cao-zhichao This paper is included in the Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20) February 25–27, 2020 • Santa Clara, CA, USA 978-1-939133-12-0 Open access to the Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST ’20) is sponsored by Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook Zhichao Cao†‡ Siying Dong‡ Sagar Vemuri‡ David H.C. Du† †University of Minnesota, Twin Cities ‡Facebook Abstract stores is still challenging. First, there are very limited studies of real-world workload characterization and analysis for KV- Persistent key-value stores are widely used as building stores, and the performance of KV-stores is highly related blocks in today’s IT infrastructure for managing and storing to the workloads generated by applications. Second, the an- large amounts of data. However, studies of characterizing alytic methods for characterizing KV-store workloads are real-world workloads for key-value stores are limited due to different from the existing workload characterization stud- the lack of tracing/analyzing tools and the difficulty of collect- ies for block storage or file systems. KV-stores have simple ing traces in operational environments. In this paper, we first but very different interfaces and behaviors. A set of good present a detailed characterization of workloads from three workload collection, analysis, and characterization tools can typical RocksDB production use cases at Facebook: UDB (a benefit both developers and users of KV-stores by optimizing MySQL storage layer for social graph data), ZippyDB (a dis- performance and developing new functions. -

Myrocks in Mariadb
MyRocks in MariaDB Sergei Petrunia <[email protected]> MariaDB Shenzhen Meetup November 2017 2 What is MyRocks ● #include <Yoshinori’s talk> ● This talk is about MyRocks in MariaDB 3 MyRocks lives in Facebook’s MySQL branch ● github.com/facebook/mysql-5.6 – Will call this “FB/MySQL” ● MyRocks lives there in storage/rocksdb ● FB/MySQL is easy to use if you are Facebook ● Not so easy if you are not :-) 4 FB/mysql-5.6 – user perspective ● No binaries, no packages – Compile yourself from source ● Dependencies, etc. ● No releases – (Is the latest git revision ok?) ● Has extra features – e.g. extra counters “confuse” monitoring tools. 5 FB/mysql-5.6 – dev perspective ● Targets a CentOS-type OS – Compiler, cmake version, etc. – Others may or may not [periodically] work ● MariaDB/Percona file pull requests to fix ● Special command to compile – https://github.com/facebook/mysql-5.6/wiki/Build-Steps ● Special command to run tests – Test suite assumes a big machine ● Some tests even a release build 6 Putting MyRocks in MariaDB ● Goals – Wider adoption – Ease of use – Ease of development – Have MyRocks in MariaDB ● Use it with MariaDB features ● Means – Port MyRocks into MariaDB – Provide binaries and packages 7 Status of MyRocks in MariaDB 8 Status of MyRocks in MariaDB ● MariaDB 10.2 is GA (as of May, 2017) ● It includes an ALPHA version of MyRocks plugin – Working to improve maturity ● It’s a loadable plugin (ha_rocksdb.so) ● Packages – Bintar, deb, rpm, win64 zip + MSI – deb/rpm have MyRocks .so and tools in a separate package. 9 Packaging for MyRocks in MariaDB 10 MyRocks and RocksDB library ● MyRocks is tied RocksDB@revno MariaDB – RocksDB is a github submodule – No compatibility with other versions MyRocks ● RocksDB is always compiled with RocksDB MyRocks S Z n ● l i And linked-in statically a b p ● p Distros have a RocksDB package y – Not using it. -

A Comparison of SPARK with MISRA C and Frama-C
A Comparison of SPARK with MISRA C and Frama-C Johannes Kanig, AdaCore October 2018 Abstract Both SPARK and MISRA C are programming languages intended for high-assurance applications, i.e., systems where reliability is critical and safety and/or security requirements must be met. This document summarizes the two languages, compares them with respect to how they help satisfy high-assurance requirements, and compares the SPARK technology to several static analysis tools available for MISRA C with a focus on Frama-C. 1 Introduction 1.1 SPARK Overview Ada [1] is a general-purpose programming language that has been specifically designed for safe and secure programming. Information on how Ada satisfies the requirements for high-assurance software, including the avoidance of vulnerabilities that are found in other languages, may be found in [2, 3, 4]. SPARK [5, 6] is an Ada subset that is amenable to formal analysis and thus can bring increased confidence to software requiring the highest levels of assurance. SPARK excludes features that are difficult to analyze (such as pointers and exception handling). Its restrictions guarantee the absence of unspecified behavior such as reading the value of an uninitialized variable, or depending on the evaluation order of expressions with side effects. But SPARK does include major Ada features such as generic templates and object-oriented programming, as well as a simple but expressive set of concurrency (tasking) features known as the Ravenscar profile. SPARK has been used in a variety of high-assurance applications, including hypervisor kernels, air traffic management, and aircraft avionics. In fact, SPARK is more than just a subset of Ada. -

Dmon: Efficient Detection and Correction of Data Locality
DMon: Efficient Detection and Correction of Data Locality Problems Using Selective Profiling Tanvir Ahmed Khan and Ian Neal, University of Michigan; Gilles Pokam, Intel Corporation; Barzan Mozafari and Baris Kasikci, University of Michigan https://www.usenix.org/conference/osdi21/presentation/khan This paper is included in the Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation. July 14–16, 2021 978-1-939133-22-9 Open access to the Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation is sponsored by USENIX. DMon: Efficient Detection and Correction of Data Locality Problems Using Selective Profiling Tanvir Ahmed Khan Ian Neal Gilles Pokam Barzan Mozafari University of Michigan University of Michigan Intel Corporation University of Michigan Baris Kasikci University of Michigan Abstract cally at run time. In fact, as we (§6.2) and others [2,15,20,27] Poor data locality hurts an application’s performance. While demonstrate, compiler-based techniques can sometimes even compiler-based techniques have been proposed to improve hurt performance when the assumptions made by those heuris- data locality, they depend on heuristics, which can sometimes tics do not hold in practice. hurt performance. Therefore, developers typically find data To overcome the limitations of static optimizations, the locality issues via dynamic profiling and repair them manually. systems community has invested substantial effort in devel- Alas, existing profiling techniques incur high overhead when oping dynamic profiling tools [28,38, 57,97, 102]. Dynamic used to identify data locality problems and cannot be deployed profilers are capable of gathering detailed and more accurate in production, where programs may exhibit previously-unseen execution information, which a developer can use to identify performance problems. -

Real-Time LSM-Trees for HTAP Workloads
Real-Time LSM-Trees for HTAP Workloads Hemant Saxena Lukasz Golab University of Waterloo University of Waterloo [email protected] [email protected] Stratos Idreos Ihab F. Ilyas Harvard University University of Waterloo [email protected] [email protected] ABSTRACT We observe that a Log-Structured Merge (LSM) Tree is a natu- Real-time data analytics systems such as SAP HANA, MemSQL, ral fit for a lifecycle-aware storage engine. LSM-Trees are widely and IBM Wildfire employ hybrid data layouts, in which dataare used in key-value stores (e.g., Google’s BigTable and LevelDB, Cas- stored in different formats throughout their lifecycle. Recent data sandra, Facebook’s RocksDB), RDBMSs (e.g., Facebook’s MyRocks, are stored in a row-oriented format to serve OLTP workloads and SQLite4), blockchains (e.g., Hyperledger uses LevelDB), and data support high data rates, while older data are transformed to a stream and time-series databases (e.g., InfluxDB). While Cassandra column-oriented format for OLAP access patterns. We observe that and RocksDB can simulate columnar storage via column families, a Log-Structured Merge (LSM) Tree is a natural fit for a lifecycle- we are not aware of any lifecycle-aware LSM-Trees in which the aware storage engine due to its high write throughput and level- storage layout can change throughout the lifetime of the data. We oriented structure, in which records propagate from one level to fill this gap in our work, by extending the capabilities ofLSM- the next over time. To build a lifecycle-aware storage engine using based systems to efficiently serve real-time analytics and HTAP an LSM-Tree, we make a crucial modification to allow different workloads. -
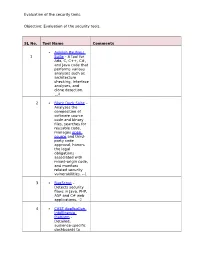
Evaluation of the Security Tools. SL No. Tool Name Comments 1
Evaluation of the security tools. Objective: Evaluation of the security tools. SL No. Tool Name Comments Axivion Bauhaus 1 Suite – A tool for Ada, C, C++, C#, and Java code that performs various analyses such as architecture checking, interface analyses, and clone detection. 4 2 Black Duck Suite – Analyzes the composition of software source code and binary files, searches for reusable code, manages open source and third- party code approval, honors the legal obligations associated with mixed-origin code, and monitors related security vulnerabilities. --1 3 BugScout – Detects security flaws in Java, PHP, ASP and C# web applications. -2 4 CAST Application Intelligence Platform – Detailed, audience-specific dashboards to Evaluation of the security tools. measure quality and productivity. 30+ languages, C, C++, Java, .NET, Oracle, PeopleSoft, SAP, Siebel, Spring, Struts, Hibernate and all major databases. 5 ChecKing – Integrated software quality portal that helps manage the quality of all phases of software development. It includes static code analyzers for Java, JSP, Javascript, HTML, XML, .NET (C#, ASP.NET, VB.NET, etc.), PL/SQL, embedded SQL, SAP ABAP IV, Natural/Adabas, C, C++, Cobol, JCL, and PowerBuilder. 6 ConQAT – Continuous quality assessment toolkit that allows flexible configuration of quality analyses (architecture conformance, clone detection, quality metrics, etc.) and dashboards. Supports Java, C#, C++, JavaScript, ABAP, Ada and many other languages. Evaluation of the security tools. 7 Coverity SAVE – A static code analysis tool for C, C++, C# and Java source code. Coverity commercialized a research tool for finding bugs through static analysis, the Stanford Checker, which used abstract interpretation to identify defects in source code. -

Rocksdb…The Old Way…Log Structured Merge
TRocksDB Remi Brasga Sr. Software Engineer | Memory Storage Strategy Division Toshiba Memory America, Inc. Hi! I’m Remi (Remington Brasga). As a Sr. Software Engineer for the Memory Storage Strategy Division at Toshiba Memory America, Inc., I am dedicated to development and collaboration on open source software. I earned my B.S. and M.S. from University of California, Irvine. Today, I am here fresh from having my 3rd son who has kept me very busy the past few weeks. (thanks for letting me come here and rest!) Applications are King • Software is eating the world • Storage is “Defined by Software” – i.e., applications define how storage is used • Yet, applications do not always use storage wisely For Example, RocksDB RocksDB is a popular data storage engine …used by a wide range of database applications ArangoDB Ceph™ Cassandra® MariaDB® Python® MyRocks Rockset Cassandra is a registered trademark of The Apache Software Foundation. Ceph is a trademark of Red Hat, Inc. or its subsidiaries in the United States and other countries. Python is a registered trademark of the Python Software Foundation. MariaDB is a registered trademark of MariaDB in the European Union and other regions. All other company names, product names and service names may be trademarks of their respective companies. The Challenge of Rocks While highly effective as a data storage engine, RocksDB has some challenges for SSDs: Write Amplification is very large 20-30X (or more) as a result of the compaction layers rewriting the same data This can result in impact to SSD endurance. How does RocksDB work? Keys and Values are stored Data Key together in pairs.