National Electoral Thresholds and Disproportionality
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Low-Magnitude Proportional Electoral Systems
The Electoral Sweet Spot: Low-Magnitude Proportional Electoral Systems John M. Carey Dartmouth College Simon Hix London School of Economics and Political Science Can electoral rules be designed to achieve political ideals such as accurate representation of voter preferences and accountable governments? The academic literature commonly divides electoral systems into two types, majoritarian and proportional, and implies a straightforward trade-off by which having more of an ideal that a majoritarian system provides means giving up an equal measure of what proportional representation (PR) delivers. We posit that these trade-offs are better characterized as nonlinear and that one can gain most of the advantages attributed to PR, while sacrificing less of those attributed to majoritarian elections, by maintaining district magnitudes in the low to moderate range. We test this intuition against data from 609 elections in 81 countries between 1945 and 2006. Electoral systems that use low-magnitude multimember districts produce disproportionality indices almost on par with those of pure PR systems while limiting party system fragmentation and producing simpler government coalitions. An Ideal Electoral System? seek to soften the representation-accountability trade-off and achieve both objectives. For example, some electoral t is widely argued by social scientists of electoral sys- systems have small multimember districts, others have tems that there is no such thing as the ideal electoral high legal thresholds below which parties cannot win system. Although many scholars harbor strong pref- seats, while others have “parallel” mixed-member sys- I tems, where the PR seats do not compensate for dispro- erences for one type of system over another, in published work and in the teaching of electoral systems it is standard portional outcomes in the single-member seats. -

A Generalization of the Minisum and Minimax Voting Methods
A Generalization of the Minisum and Minimax Voting Methods Shankar N. Sivarajan Undergraduate, Department of Physics Indian Institute of Science Bangalore 560 012, India [email protected] Faculty Advisor: Prof. Y. Narahari Deparment of Computer Science and Automation Revised Version: December 4, 2017 Abstract In this paper, we propose a family of approval voting-schemes for electing committees based on the preferences of voters. In our schemes, we calcu- late the vector of distances of the possible committees from each of the ballots and, for a given p-norm, choose the one that minimizes the magni- tude of the distance vector under that norm. The minisum and minimax methods suggested by previous authors and analyzed extensively in the literature naturally appear as special cases corresponding to p = 1 and p = 1; respectively. Supported by examples, we suggest that using a small value of p; such as 2 or 3, provides a good compromise between the minisum and minimax voting methods with regard to the weightage given to approvals and disapprovals. For large but finite p; our method reduces to finding the committee that covers the maximum number of voters, and this is far superior to the minimax method which is prone to ties. We also discuss extensions of our methods to ternary voting. 1 Introduction In this paper, we consider the problem of selecting a committee of k members out of n candidates based on preferences expressed by m voters. The most common way of conducting this election is to allow each voter to select his favorite candidate and vote for him/her, and we select the k candidates with the most number of votes. -

Proxy Voting Guidelines Benchmark Policy Recommendations TITLE
UNITED STATES Proxy Voting Guidelines Benchmark Policy Recommendations TITLE Effective for Meetings on or after February 1, 2021 Published November 19, 2020 ISS GOVERNANCE .COM © 2020 | Institutional Shareholder Services and/or its affiliates UNITED STATES PROXY VOTING GUIDELINES TABLE OF CONTENTS Coverage ................................................................................................................................................................ 7 1. Board of Directors ......................................................................................................................................... 8 Voting on Director Nominees in Uncontested Elections ........................................................................................... 8 Independence ....................................................................................................................................................... 8 ISS Classification of Directors – U.S. ................................................................................................................. 9 Composition ........................................................................................................................................................ 11 Responsiveness ................................................................................................................................................... 12 Accountability .................................................................................................................................................... -

Are Condorcet and Minimax Voting Systems the Best?1
1 Are Condorcet and Minimax Voting Systems the Best?1 Richard B. Darlington Cornell University Abstract For decades, the minimax voting system was well known to experts on voting systems, but was not widely considered to be one of the best systems. But in recent years, two important experts, Nicolaus Tideman and Andrew Myers, have both recognized minimax as one of the best systems. I agree with that. This paper presents my own reasons for preferring minimax. The paper explicitly discusses about 20 systems. Comments invited. [email protected] Copyright Richard B. Darlington May be distributed free for non-commercial purposes Keywords Voting system Condorcet Minimax 1. Many thanks to Nicolaus Tideman, Andrew Myers, Sharon Weinberg, Eduardo Marchena, my wife Betsy Darlington, and my daughter Lois Darlington, all of whom contributed many valuable suggestions. 2 Table of Contents 1. Introduction and summary 3 2. The variety of voting systems 4 3. Some electoral criteria violated by minimax’s competitors 6 Monotonicity 7 Strategic voting 7 Completeness 7 Simplicity 8 Ease of voting 8 Resistance to vote-splitting and spoiling 8 Straddling 8 Condorcet consistency (CC) 8 4. Dismissing eight criteria violated by minimax 9 4.1 The absolute loser, Condorcet loser, and preference inversion criteria 9 4.2 Three anti-manipulation criteria 10 4.3 SCC/IIA 11 4.4 Multiple districts 12 5. Simulation studies on voting systems 13 5.1. Why our computer simulations use spatial models of voter behavior 13 5.2 Four computer simulations 15 5.2.1 Features and purposes of the studies 15 5.2.2 Further description of the studies 16 5.2.3 Results and discussion 18 6. -

Croatia: Three Elections and a Funeral
Conflict Studies Research Centre G83 REPUBLIC OF CROATIA Three Elections and a Funeral The Dawn of Democracy at the Millennial Turn? Dr Trevor Waters Introduction 2 President Tudjman Laid To Rest 2 Parliamentary Elections 2/3 January 2000 5 • Background & Legislative Framework • Political Parties & the Political Climate • Media, Campaign, Public Opinion Polls and NGOs • Parliamentary Election Results & International Reaction Presidential Elections - 24 January & 7 February 2000 12 Post Tudjman Croatia - A New Course 15 Annex A: House of Representatives Election Results October 1995 Annex B: House of Counties Election Results April 1997 Annex C: Presidential Election Results June 1997 Annex D: House of Representatives Election Results January 2000 Annex E: Presidential Election Results January/February 2000 1 G83 REPUBLIC OF CROATIA Three Elections and a Funeral The Dawn of Democracy at the Millennial Turn? Dr Trevor Waters Introduction Croatia's passage into the new millennium was marked by the death, on 10 December 1999, of the self-proclaimed "Father of the Nation", President Dr Franjo Tudjman; by make or break Parliamentary Elections, held on 3 January 2000, which secured the crushing defeat of the former president's ruling Croatian Democratic Union, yielded victory for an alliance of the six mainstream opposition parties, and ushered in a new coalition government strong enough to implement far-reaching reform; and by two rounds, on 24 January and 7 February, of Presidential Elections which resulted in a surprising and spectacular victory for the charismatic Stipe Mesić, Yugoslavia's last president, nonetheless considered by many Croats at the start of the campaign as an outsider, a man from the past. -
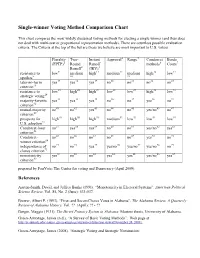
Single-Winner Voting Method Comparison Chart
Single-winner Voting Method Comparison Chart This chart compares the most widely discussed voting methods for electing a single winner (and thus does not deal with multi-seat or proportional representation methods). There are countless possible evaluation criteria. The Criteria at the top of the list are those we believe are most important to U.S. voters. Plurality Two- Instant Approval4 Range5 Condorcet Borda (FPTP)1 Round Runoff methods6 Count7 Runoff2 (IRV)3 resistance to low9 medium high11 medium12 medium high14 low15 spoilers8 10 13 later-no-harm yes17 yes18 yes19 no20 no21 no22 no23 criterion16 resistance to low25 high26 high27 low28 low29 high30 low31 strategic voting24 majority-favorite yes33 yes34 yes35 no36 no37 yes38 no39 criterion32 mutual-majority no41 no42 yes43 no44 no45 yes/no 46 no47 criterion40 prospects for high49 high50 high51 medium52 low53 low54 low55 U.S. adoption48 Condorcet-loser no57 yes58 yes59 no60 no61 yes/no 62 yes63 criterion56 Condorcet- no65 no66 no67 no68 no69 yes70 no71 winner criterion64 independence of no73 no74 yes75 yes/no 76 yes/no 77 yes/no 78 no79 clones criterion72 81 82 83 84 85 86 87 monotonicity yes no no yes yes yes/no yes criterion80 prepared by FairVote: The Center for voting and Democracy (April 2009). References Austen-Smith, David, and Jeffrey Banks (1991). “Monotonicity in Electoral Systems”. American Political Science Review, Vol. 85, No. 2 (June): 531-537. Brewer, Albert P. (1993). “First- and Secon-Choice Votes in Alabama”. The Alabama Review, A Quarterly Review of Alabama History, Vol. ?? (April): ?? - ?? Burgin, Maggie (1931). The Direct Primary System in Alabama. -

Who Gains from Apparentments Under D'hondt?
CIS Working Paper No 48, 2009 Published by the Center for Comparative and International Studies (ETH Zurich and University of Zurich) Who gains from apparentments under D’Hondt? Dr. Daniel Bochsler University of Zurich Universität Zürich Who gains from apparentments under D’Hondt? Daniel Bochsler post-doctoral research fellow Center for Comparative and International Studies Universität Zürich Seilergraben 53 CH-8001 Zürich Switzerland Centre for the Study of Imperfections in Democracies Central European University Nador utca 9 H-1051 Budapest Hungary [email protected] phone: +41 44 634 50 28 http://www.bochsler.eu Acknowledgements I am in dept to Sebastian Maier, Friedrich Pukelsheim, Peter Leutgäb, Hanspeter Kriesi, and Alex Fischer, who provided very insightful comments on earlier versions of this paper. Manuscript Who gains from apparentments under D’Hondt? Apparentments – or coalitions of several electoral lists – are a widely neglected aspect of the study of proportional electoral systems. This paper proposes a formal model that explains the benefits political parties derive from apparentments, based on their alliance strategies and relative size. In doing so, it reveals that apparentments are most beneficial for highly fractionalised political blocs. However, it also emerges that large parties stand to gain much more from apparentments than small parties do. Because of this, small parties are likely to join in apparentments with other small parties, excluding large parties where possible. These arguments are tested empirically, using a new dataset from the Swiss national parliamentary elections covering a period from 1995 to 2007. Keywords: Electoral systems; apparentments; mechanical effect; PR; D’Hondt. Apparentments, a neglected feature of electoral systems Seat allocation rules in proportional representation (PR) systems have been subject to widespread political debate, and one particularly under-analysed subject in this area is list apparentments. -

Legislature by Lot: Envisioning Sortition Within a Bicameral System
PASXXX10.1177/0032329218789886Politics & SocietyGastil and Wright 789886research-article2018 Special Issue Article Politics & Society 2018, Vol. 46(3) 303 –330 Legislature by Lot: Envisioning © The Author(s) 2018 Article reuse guidelines: Sortition within a Bicameral sagepub.com/journals-permissions https://doi.org/10.1177/0032329218789886DOI: 10.1177/0032329218789886 System* journals.sagepub.com/home/pas John Gastil Pennsylvania State University Erik Olin Wright University of Wisconsin–Madison Abstract In this article, we review the intrinsic democratic flaws in electoral representation, lay out a set of principles that should guide the construction of a sortition chamber, and argue for the virtue of a bicameral system that combines sortition and elections. We show how sortition could prove inclusive, give citizens greater control of the political agenda, and make their participation more deliberative and influential. We consider various design challenges, such as the sampling method, legislative training, and deliberative procedures. We explain why pairing sortition with an elected chamber could enhance its virtues while dampening its potential vices. In our conclusion, we identify ideal settings for experimenting with sortition. Keywords bicameral legislatures, deliberation, democratic theory, elections, minipublics, participation, political equality, sortition Corresponding Author: John Gastil, Department of Communication Arts & Sciences, Pennsylvania State University, 232 Sparks Bldg., University Park, PA 16802, USA. Email: [email protected] *This special issue of Politics & Society titled “Legislature by Lot: Transformative Designs for Deliberative Governance” features a preface, an introductory anchor essay and postscript, and six articles that were presented as part of a workshop held at the University of Wisconsin–Madison, September 2017, organized by John Gastil and Erik Olin Wright. -

Single Transferable Vote Resists Strategic Voting
Single Transferable Vote Resists Strategic Voting John J. Bartholdi, III School of Industrial and Systems Engineering Georgia Institute of Technology, Atlanta, GA 30332 James B. Orlin Sloan School of Management Massachusetts Institute of Technology, Cambridge, MA 02139 November 13, 1990; revised April 4, 2003 Abstract We give evidence that Single Tranferable Vote (STV) is computation- ally resistant to manipulation: It is NP-complete to determine whether there exists a (possibly insincere) preference that will elect a favored can- didate, even in an election for a single seat. Thus strategic voting under STV is qualitatively more difficult than under other commonly-used vot- ing schemes. Furthermore, this resistance to manipulation is inherent to STV and does not depend on hopeful extraneous assumptions like the presumed difficulty of learning the preferences of the other voters. We also prove that it is NP-complete to recognize when an STV elec- tion violates monotonicity. This suggests that non-monotonicity in STV elections might be perceived as less threatening since it is in effect “hid- den” and hard to exploit for strategic advantage. 1 1 Strategic voting For strategic voting the fundamental problem for any would-be manipulator is to decide what preference to claim. We will show that this modest task can be impractically difficult under the voting scheme known as Single Transferable Vote (STV). Furthermore this difficulty pertains even in the ideal situation in which the manipulator knows the preferences of all other voters and knows that they will vote their complete and sincere preferences. Thus STV is apparently unique among voting schemes in actual use today in that it is computationally resistant to manipulation. -
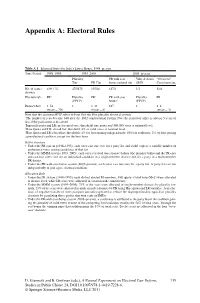
Appendix A: Electoral Rules
Appendix A: Electoral Rules Table A.1 Electoral Rules for Italy’s Lower House, 1948–present Time Period 1948–1993 1993–2005 2005–present Plurality PR with seat Valle d’Aosta “Overseas” Tier PR Tier bonus national tier SMD Constituencies No. of seats / 6301 / 32 475/475 155/26 617/1 1/1 12/4 districts Election rule PR2 Plurality PR3 PR with seat Plurality PR (FPTP) bonus4 (FPTP) District Size 1–54 1 1–11 617 1 1–6 (mean = 20) (mean = 6) (mean = 4) Note that the acronym FPTP refers to First Past the Post plurality electoral system. 1The number of seats became 630 after the 1962 constitutional reform. Note the period of office is always 5 years or less if the parliament is dissolved. 2Imperiali quota and LR; preferential vote; threshold: one quota and 300,000 votes at national level. 3Hare Quota and LR; closed list; threshold: 4% of valid votes at national level. 4Hare Quota and LR; closed list; thresholds: 4% for lists running independently; 10% for coalitions; 2% for lists joining a pre-electoral coalition, except for the best loser. Ballot structure • Under the PR system (1948–1993), each voter cast one vote for a party list and could express a variable number of preferential votes among candidates of that list. • Under the MMM system (1993–2005), each voter received two separate ballots (the plurality ballot and the PR one) and cast two votes: one for an individual candidate in a single-member district; one for a party in a multi-member PR district. • Under the PR-with-seat-bonus system (2005–present), each voter cast one vote for a party list. -

Mapping and Responding to the Rising Culture and Politics of Fear in the European Union…”
“ Mapping and responding to the rising culture and politics of fear in the European Union…” NOTHING TO FEAR BUT FEAR ITSELF? Demos is Britain’s leading cross-party think tank. We produce original research, publish innovative thinkers and host thought-provoking events. We have spent over 20 years at the centre of the policy debate, with an overarching mission to bring politics closer to people. Demos has always been interested in power: how it works, and how to distribute it more equally throughout society. We believe in trusting people with decisions about their own lives and solving problems from the bottom-up. We pride ourselves on working together with the people who are the focus of our research. Alongside quantitative research, Demos pioneers new forms of deliberative work, from citizens’ juries and ethnography to ground-breaking social media analysis. Demos is an independent, educational charity, registered in England and Wales (Charity Registration no. 1042046). Find out more at www.demos.co.uk First published in 2017 © Demos. Some rights reserved Unit 1, Lloyds Wharf, 2–3 Mill Street London, SE1 2BD, UK ISBN 978–1–911192–07–7 Series design by Modern Activity Typeset by Soapbox Set in Gotham Rounded and Baskerville 10 NOTHING TO FEAR BUT FEAR ITSELF? Open access. Some rights reserved. As the publisher of this work, Demos wants to encourage the circulation of our work as widely as possible while retaining the copyright. We therefore have an open access policy which enables anyone to access our content online without charge. Anyone can download, save, perform or distribute this work in any format, including translation, without written permission. -

The Many Faces of Strategic Voting
Revised Pages The Many Faces of Strategic Voting Strategic voting is classically defined as voting for one’s second pre- ferred option to prevent one’s least preferred option from winning when one’s first preference has no chance. Voters want their votes to be effective, and casting a ballot that will have no influence on an election is undesirable. Thus, some voters cast strategic ballots when they decide that doing so is useful. This edited volume includes case studies of strategic voting behavior in Israel, Germany, Japan, Belgium, Spain, Switzerland, Canada, and the United Kingdom, providing a conceptual framework for understanding strategic voting behavior in all types of electoral systems. The classic definition explicitly considers strategic voting in a single race with at least three candidates and a single winner. This situation is more com- mon in electoral systems that have single- member districts that employ plurality or majoritarian electoral rules and have multiparty systems. Indeed, much of the literature on strategic voting to date has considered elections in Canada and the United Kingdom. This book contributes to a more general understanding of strategic voting behavior by tak- ing into account a wide variety of institutional contexts, such as single transferable vote rules, proportional representation, two- round elec- tions, and mixed electoral systems. Laura B. Stephenson is Professor of Political Science at the University of Western Ontario. John Aldrich is Pfizer- Pratt University Professor of Political Science at Duke University. André Blais is Professor of Political Science at the Université de Montréal. Revised Pages Revised Pages THE MANY FACES OF STRATEGIC VOTING Tactical Behavior in Electoral Systems Around the World Edited by Laura B.