TIME-BASED APPROACH to INTRUSION DETECTION USING MULTIPLE SELF-ORGANIZING MAPS a Thesis Presented to the Faculty of the College
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
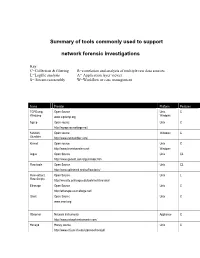
Network Forensic Tools Sidebar
Summary of tools commonly used to support network forensic investigations Key: C=Collection & filtering R=correlation and analysis of multiple raw data sources L=Logfile analysis A= Application layer viewer S= Stream reassembly W=Workflow or case management Name Provider Platform Features TCPDump, Open Source Unix, C Windump www.tcpdump.org Windows Ngrep Open source Unix C http://ngrep.sourceforge.net/ Network Open source Windows C Stumbler http://www.netstumbler.com/ Kismet Open source Unix C http://www.kismetwireless.net Windows Argus Open Source Unix CL http://www.qosient.com/argus/index.htm Flow-tools Open Source Unix CL http://www.splintered.net/sw/flow-tools/ Flow-extract, Open Source Unix L Flow Scripts http://security.uchicago.edu/tools/net-forensics/ Etherape Open Source Unix C http://etherape.sourceforge.net/ Snort Open Source Unix C www.snort.org Observer Network Instruments Appliance C http://www.networkinstruments.com/ Honeyd Honey source Unix C http://www.citi.umich.edu/u/provos/honeyd/ Ethereal Open Source Windows CLS www.Ethereal.com Unix Etherpeek Wild Packets, Inc. Windows CLS www.wildpackets.com SecureNet Intrusion Inc. Windows with CS http://www.intrusion.com collector appliance FLAG Open Source Unix L Forensic and http://www.dsd.gov.au/library/software/flag/ Log Analysis GUI ACID Analysis Console for Intrusion Databases Unix L http://www.andrew.cmu.edu/~rdanyliw/snort/snortacid.html Shadow http://www.nswc.navy.mil/ISSEC/CID/index.html Unix LS DeepNines and http://www.deepnines.com/sleuth9.html Unix CSR Sleuth9 Infinistream -

Guide to Computer Forensics and Investigations Fourth Edition
Guide to Computer Forensics and Investigations Fourth Edition Chapter 11 Virtual Machines, Network Forensics, and Live Acquisitions Objectives • Describe primary concerns in conducting forensic examinations of virtual machines • Describe the importance of network forensics • Explain standard procedures for performing a live acquisition • Explain standard procedures for network forensics • Describe the use of network tools Guide to Computer Forensics and Investigations 2 Virtual Machines Overview • Virtual machines are important in today’s networks. • Investigators must know how to detect a virtual machine installed on a host, acquire an image of a virtual machine, and use virtual machines to examine malware. Virtual Machines Overview (cont.) • Check whether virtual machines are loaded on a host computer. • Check Registry for clues that virtual machines have been installed or uninstalled. Network Forensics Overview • Network forensics – Systematic tracking of incoming and outgoing traffic • To ascertain how an attack was carried out or how an event occurred on a network • Intruders leave trail behind • Determine the cause of the abnormal traffic – Internal bug – Attackers Guide to Computer Forensics and Investigations 5 Securing a Network • Layered network defense strategy – Sets up layers of protection to hide the most valuable data at the innermost part of the network • Defense in depth (DiD) – Similar approach developed by the NSA – Modes of protection • People • Technology • Operations Guide to Computer Forensics and Investigations -

Wireless Networking in the Developing World
Wireless Networking in the Developing World Second Edition A practical guide to planning and building low-cost telecommunications infrastructure Wireless Networking in the Developing World For more information about this project, visit us online at http://wndw.net/ First edition, January 2006 Second edition, December 2007 Many designations used by manufacturers and vendors to distinguish their products are claimed as trademarks. Where those designations appear in this book, and the authors were aware of a trademark claim, the designations have been printed in all caps or initial caps. All other trademarks are property of their respective owners. The authors and publisher have taken due care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information contained herein. © 2007 Hacker Friendly LLC, http://hackerfriendly.com/ This work is released under the Creative Commons Attribution-ShareAlike 3.0 license. For more details regarding your rights to use and redistribute this work, see http://creativecommons.org/licenses/by-sa/3.0/ Contents Where to Begin 1 Purpose of this book........................................................................................................................... 2 Fitting wireless into your existing network.......................................................................................... 3 Wireless -

Use Style: Paper Title
COMPARATIVE ANALYSIS OF PACKET SNIFFERS : A STUDY Jyoti Senior Engineer, Bharat Electronics Limited (India) ABSTRACT Today everything is being centralized through a common dedicated network to ease its use, make it more user friendly and increase its efficiency. The size of these centric networks is also increasing rapidly. So the management, maintenance and monitoring of these networks is important to keep network smooth and improve economic efficiency. Packet sniffing or packet analysis is the process of capturing data passed over the local network and looking for any information that may be useful. There is a wide variety of packet sniffers available in the market that can be exploited for this purpose. This paper focuses on the basics of packet sniffer, its working principle and a comparative study of various packet sniffers. Keywords: Packet Capture; Packet Sniffer; network monitoring; wireshark; NIC I INTRODUCTION A packet sniffer is a program that can see all of the information passing over the network it is connected to. As data steams back and forth on the network the program looks at it or „sniffs‟ each packet. A packet is a part of a message that has been broken up. Packet analysis can help us understand network characteristics, learn who is on network, determine who or what is utilizing available bandwidth, identify peak network usage times, identify possible attacks or malicious activity, and find unsecured and bloated applications[1]. II WORKING There are two modes in which a network interface of a machine work i.e Promiscuous and Non-promiscuous. Promiscuous mode in one in which the NIC of the machine can take over all packets and a frame it receives on network, namely this machine (involving its software) is sniffer. -

Using the Ethereal and Tcpdump Protocol Analyzers
Using the Ethereal and tcpdump Protocol Analyzers Doug Toppin Nov 2003 toppin.com Ethereal - 1 What is Ethereal? “ Ethereal is a free network protocol analyzer for Unix and Windows. It allows you to examine data from a live network or from a capture file on disk. You can interactively browse the capture data, viewing summary and detail information for each packet. Ethereal has several powerful features, including a rich display filter language and the ability to view the reconstructed stream of a TCP session.” Ethereal - 2 Similar Tools ● tethereal - textual version of ethereal ● tcpdump - textual protocol analyzer These tools use the pcap (libpcap) packet capture library (which can be used to generate custom capture apps) Ethereal - 3 What does ethereal look like? ● gui composed of 4-fields: – Menu bar – List of captured packets – Top-level info on selected packet – Detail of selected packet – See following slide for example Ethereal - 4 captured packet list Illus-1 overhead gui of selected packet detail of selected packet Ethereal - 5 Illus-2 Capture initiator Ethereal - 6 uses for these tools ● find messages that have errors in them without modifying code (adding debug prints) ● monitor/analyze lan traffic for activity/load/latency measurement ● save captured packets for later analysis (“ evidence” attached to an bug report) ● frequently used for passive intrusion detection and monitoring ● just to see what your network is up to Ethereal - 7 Illus-3 capture with payload selected (http) Ethereal - 8 Illus-4 note http text Ethereal - -

A Survey of Tools for Monitoring and Visualization of Network Traffic
MASARYK UNIVERSITY FACULTY}w¡¢£¤¥¦§¨ OF I !"#$%&'()+,-./012345<yA|NFORMATICS A Survey of Tools for Monitoring and Visualization of Network Traffic BACHELOR’S THESIS Jakub Šk ˚urek Brno, Fall 2015 Declaration Hereby I declare, that this paper is my original authorial work, which I have worked out by my own. All sources, references and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Jakub Šk ˚urek Advisor: doc. Ing. JiˇríSochor, CSc. ii Abstract The main goal of this thesis is to survey and categorize existing tools and applications for network traffic monitoring and visualization. This is accomplished by first dividing these into three main cate- gories, followed by additional subdivision into subcategories while presenting example tools and applications relevant to each category. iii Keywords network monitoring, network visualization, survey, traffic, monitor- ing iv Acknowledgement I would like to thank my advisor doc. Sochor for his advice and help- ful tips. A big thank you also goes to my family for the continued support and kind words given, and mainly for being understanding of my reclusive behaviour during the writing process. v Contents 1 Introduction ............................3 2 Computer Network Monitoring and Visualization .....5 2.1 Simple Network Management Protocol .........5 2.2 NetFlow/IPFIX Protocol ..................6 2.3 Internet Control Message Protocol ............6 2.4 Windows Management Instrumentation .........7 2.5 Packet Capture .......................7 3 Tools for Local Network Visualization ............9 3.1 Local Traffic and Performance Visualization .......9 3.1.1 NetGrok . .9 3.1.2 EtherApe . 11 3.2 Packet Capture and Visualization ............ -

Packet Analysis for Network Forensics: a Comprehensive Survey
Edith Cowan University Research Online ECU Publications Post 2013 1-1-2020 Packet analysis for network forensics: A comprehensive survey Leslie F. Sikos Edith Cowan University Follow this and additional works at: https://ro.ecu.edu.au/ecuworkspost2013 Part of the Physical Sciences and Mathematics Commons 10.1016/j.fsidi.2019.200892 Sikos, L. F. (2020). Packet analysis for network forensics: a comprehensive survey. Forensic Science International: Digital Investigation, 32, Article 200892. https://doi.org/10.1016/j.fsidi.2019.200892 This Journal Article is posted at Research Online. https://ro.ecu.edu.au/ecuworkspost2013/7605 Forensic Science International: Digital Investigation 32 (2020) 200892 Contents lists available at ScienceDirect Forensic Science International: Digital Investigation journal homepage: www.elsevier.com/locate/fsidi Packet analysis for network forensics: A comprehensive survey Leslie F. Sikos Edith Cowan University, Australia article info abstract Article history: Packet analysis is a primary traceback technique in network forensics, which, providing that the packet Received 16 May 2019 details captured are sufficiently detailed, can play back even the entire network traffic for a particular Received in revised form point in time. This can be used to find traces of nefarious online behavior, data breaches, unauthorized 27 August 2019 website access, malware infection, and intrusion attempts, and to reconstruct image files, documents, Accepted 1 October 2019 email attachments, etc. sent over the network. This paper is a comprehensive survey of the utilization of Available online xxx packet analysis, including deep packet inspection, in network forensics, and provides a review of AI- powered packet analysis methods with advanced network traffic classification and pattern identifica- Keywords: Packet analysis tion capabilities. -

Packet Sockets, BPF and Netsniff-NG
Packet Sockets, BPF and Netsniff-NG (Brief intro into finding the needle in the network haystack.) Daniel Borkmann <[email protected]> Open Source Days, Copenhagen, March 9, 2013 D. Borkmann (Red Hat) packet mmap(2), bpf, netsniff-ng March 9, 2013 1 / 9 Motivation and Users of PF PACKET Useful to have raw access to network packet data in user space Analysis of network problems Debugging tool for network (protocol-)development Traffic monitoring, security auditing and more libpcap and all tools that use this library Used only for packet reception in user space tcpdump, Wireshark, nmap, Snort, Bro, Ettercap, EtherApe, dSniff, hping3, p0f, kismet, ngrep, aircrack-ng, and many many more netsniff-ng toolkit (later on in this talk) Suricata and other projects, also in the proprietary industry Thus, this concerns a huge user base that PF PACKET is serving! D. Borkmann (Red Hat) packet mmap(2), bpf, netsniff-ng March 9, 2013 2 / 9 Motivation and Users of PF PACKET Useful to have raw access to network packet data in user space Analysis of network problems Debugging tool for network (protocol-)development Traffic monitoring, security auditing and more libpcap and all tools that use this library Used only for packet reception in user space tcpdump, Wireshark, nmap, Snort, Bro, Ettercap, EtherApe, dSniff, hping3, p0f, kismet, ngrep, aircrack-ng, and many many more netsniff-ng toolkit (later on in this talk) Suricata and other projects, also in the proprietary industry Thus, this concerns a huge user base that PF PACKET is serving! D. Borkmann (Red Hat) packet mmap(2), bpf, netsniff-ng March 9, 2013 2 / 9 Features of PF PACKET Normally sendto(2), recvfrom(2) calls for each packet Buffer copies between address spaces, context switches How can this be further improved (PF PACKET features)?1 Zero-copy RX/TX ring buffer (“packet mmap(2)”) “Avoid obvious waste” principle Socket clustering (“packet fanout”) with e.g. -

Comparative Study of Network Monitoring Tools Shrutika Suri, Vandna Batra
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-1 Issue-3, August 2012 Comparative Study of Network Monitoring Tools Shrutika Suri, Vandna Batra III. OPERATING SYSTEM SUPPORT Abstract: There are billions of packets flying around the web sky today. A significant number of them are of malicious intent. To segregate each tool on the basis of operating system they These packets help us to understand when there are notable support, will help the user to understand and use each tool security or performance events occurring on the network and also according to their requirements. to find out common network problems such as loss of Wireshark is cross-platform, using the GTK+ widget connectivity, slow network etc.This paper focus on the comparative study of different packet analyzers available in toolkit to implement its user interface, and using pcap to current market and how we can choose amongst them according capture packets; it runs on various Unix-like operating to our requirements. systems including Linux, Mac OS X, BSD, and Solaris, Keywords: Packetcapturing, Packetanalysis, Wireshark, and on Microsoft Windows[1]. Eherape, capsa, libpcap. Tcpdump works on most Unix-like operating systems: Linux, Solaris, BSD, Mac OS X, HP-UX and AIX I. INTRODUCTION among others[2]. Netsniff-ng is a free, performant Linux networking To provide a precise view on each tool we have toolkit. segregated them into different categories such as console EtherApe is a graphical network monitor for Unix and based, GUI based or both. We conducted a comprehensive Unix like operating systems [3]. -

Automating the Generation of Cyber Range Virtual Scenarios with VSDL
Automating the Generation of Cyber Range Virtual Scenarios with VSDL Gabriele Costa, Enrico Russo, Alessandro Armando DIBRIS, Universita` degli Studi di Genova Genova, Italy [email protected] Abstract A cyber range is an environment used for training security experts and testing attack and defence tools and procedures. Usually, a cyber range simulates one or more critical infrastructures that attack- ing (red) and defending (blue) teams must compromise and protect, respectively. The infrastructure can be physically assembled, but much more convenient is to rely on the Infrastructure as a Service (IaaS) paradigm. Although some modern technologies support the IaaS, the design and deployment of scenarios of interest is mostly a manual operation. As a consequence, it is a common practice to have a cyber range hosting few (sometimes only one), consolidated scenarios. However, reusing the same scenario may significantly reduce the effectiveness of the training and testing sessions. In this paper we propose a framework for automating the definition and deployment of arbitrarily complex cyber range scenarios. The framework relies on the virtual scenario description language (VSDL), i.e., a domain-specific language for defining high-level features of the desired infrastructure while hiding low-level details. The semantics of VSDL is given in terms of constraints that must be satisfied by the virtual infrastructure. These constraints are then submitted to a SMT solver for checking the satisfiability of the specification. If satisfiable, the specification gives rise to a model that is automatically converted to a set of deployment scripts to be submitted to the IaaS provider. 1 Introduction Cyber defence (as well as offence) rely on security experts that must be properly trained and equipped with adequate security tools. -

Network Capture Visualisation Integrated Design Project 3
Network Capture Visualisation Integrated Design Project 3 Euan McKerrow S1223475 Khalid Zeari S1312249 Nabeel Nabi S1222196 Tamar Everson S1226265 Published, April 28th 2015 1 | P a g e Content Page Abstract 1 Introduction 2 Literature Review 2.1 Network Comparison 2.2 Intrusion Detection 2.3 Visualisation Tools 2.4 Specific Tools 3 Method 3.1 Design 3.2 Apparatus & Software 3.3 Procedure 4 Results 4.1 RUMINT 4.2 Wireshark 4.3 EtherApe 4.4 Network Miner 4.5 Comparison 4.6 Our tool (ENVA) 5 Final Discussion & Conclusions 5.1 Discussion 5.2 Project critique 5.3 Further work 5.4 Conclusions References Bibliography 2 | P a g e Abstract: There have been many tools which have been created for visually analysing network traffic, these have been created to show visually the packets and the data about live PCAP files and captured PCAP files. These tools have made it easier for an analyst to view the data instead of reading it, because it is easier for them to comprehend the information. The tools created can do more that just display the information they can allow the analyst to filter certain packets so that the visual representation isn’t overwhelming. Keywords: PCAP, Network visualisation, unusual traffic detection. 1 Introduction for both manual and automated visualisation techniques we have PCAP There has been a growing interest visualisation techniques to bring human life in the visualisation of PCAP files and the into the investigative cycle. (Mehmet security of a network. Trying to detect Celenk, Member, IEEE, Thomas Conley, John malicious activity within a network is a Willis, Student Member, IEEE, and James difficult problem to face, made more Graham, Student Member, IEEE 2010) difficult by large scale databases and very Predictive Network Anomaly Detection and limited function of analysis tools. -

Anonymous Communications
Anonymous Communications Andrew Lewman [email protected] December 05, 2012 Andrew Lewman [email protected] () Anonymous Communications December 05, 2012 1 / 45 Who is this guy? 501(c)(3) non-profit organization dedicated to the research and development of technologies for online anonymity and privacy https://www.torproject.org Andrew Lewman [email protected] () Anonymous Communications December 05, 2012 2 / 45 Three hours of this guy talking? Let's hope not. Ask questions; early and often. Andrew Lewman [email protected] () Anonymous Communications December 05, 2012 3 / 45 Agenda Definitions and Concepts of Anonymity What data? Attacks against anonymity Deployed Systems (Centralized and Decentralized) Andrew Lewman [email protected] () Anonymous Communications December 05, 2012 4 / 45 What is Anonymity? Andrew Lewman [email protected] () Anonymous Communications December 05, 2012 5 / 45 Definitions: Anonymity a set of all possible subjects state of not being identifiable within anonymity set Andrew Lewman [email protected] () Anonymous Communications December 05, 2012 6 / 45 Definitions: Unlinkability unlinkability of two or more items of interest from the adversary's perspective I items can be messages, people, events, actions, etc Andrew Lewman [email protected] () Anonymous Communications December 05, 2012 7 / 45 Definitions: Unobservability state of items of interest being indistinguishable from any items of interest Andrew Lewman [email protected] () Anonymous Communications December 05, 2012 8 / 45 Definitions: Pseudonymity identifiers of sets of subjects Andrew Lewman [email protected] () Anonymous Communications December 05, 2012 9 / 45 Definitions: Traffic Analysis The who, what, when of traffic Think of the post office Andrew Lewman [email protected] () Anonymous Communications December 05, 2012 10 / 45 Definitions: Steganography the art and science of writing hidden messages in such a way that no one, apart from the sender and intended recipient, suspects the existence of the message, a form of security through obscurity.