Bike-Share Systems: Accessibility and Availability
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Transit App Moovit Expands Crowdsourcing to Masses
Transit App Moovit Expands Crowdsourcing to Masses Version 4.13 for Android Further Empowers Users to Contribute Real-Time Transit Information, Such As Station Location Closures and Track Maintenance Updates SAN FRANCISCO – August 4, 2016 Moovit, the world’s leading local transit app, is taking its foundation in crowdsourced data one step further by opening editing capabilities to all. Previously only available to members of the Moovit Community program, the new feature allows transit riders to help others to have the most up-to-date transportation information so that the transit experience is better for all. The newly-released Moovit version 4.13 for Android is available for immediate download. Now, any Moovit user can help to suggest edits to data within the app, including edits to many attributes of a station, like its location on the map, name and whether it is permanently inoperative. Due to the way some data is collected, occasionally a station icon will be shown on the map near where the station is located (across the street, or a few yards away, for example), but not actually in its precise location. When planning a trip via the app, the station icon location on the map is taken into consideration in the routes a user will receive. If the station is actually located across the street from where the icon is seen on the map, the user may find their route inaccurate if they have to walk longer than expected to find the entrance. The new update, coupled with Moovit’s existing level of service reporting capabilities – such as elevator malfunction, cleanliness or crowdedness updates – gives users a comprehensive ability to quickly spot discrepancies and make changes that can help to improve the overall experience of their fellow transit riders, and even potentially avoid transit congestion, maintenance delays or other issues. -

FARGO MOORHEAD BUS ROUTES ANDROID APPLICATION a Paper
FARGO MOORHEAD BUS ROUTES ANDROID APPLICATION A Paper Submitted to the Graduate Faculty of the North Dakota State University of Agriculture and Applied Science By Avijeet Tomer In Partial Fulfillment of the Requirements For the Degree of MASTER OF SCIENCE Major Department: Computer Science January 2013 Fargo, North Dakota North Dakota State University Graduate School Title FARGO MOORHEAD BUS ROUTES ANDROID APPLICATION By AVIJEET TOMER The Supervisory Committee certifies that this disquisition complies with North Dakota State University’s regulations and meets the accepted standards for the degree of MASTER OF SCIENCE SUPERVISORY COMMITTEE: Dr. Gursimran Walia Chair Dr. Kendall E. Nygard Dr. Simone Ludwig Dr. Joseph G. Szmerekovsky Approved by Department Chair: 1/28/2013 Dr. Kenneth Magel Date Signature ABSTRACT Fargo and Moorhead have good public transportation provided by Metro Area Transit bus service. Google Maps Navigation, which provides public transportation routes and directions in several major cities, is not available in Fargo or Moorhead, so bus users have to either carry and use printed maps provided by MATBUS to determine the bus routes they need to take to reach their destination, or if they have a smartphone with internet connectivity, they can visit MATBUS website to view the maps on their device. This paper examines the inconveniences of both procedures like using a big printed map outside in Fargo winter, or panning across an approximately A0 sized PDF (actual dimensions are 30.67 inches width and 46.67 inches height) on the small screen of a smartphone and presents a tool for Android-based smartphone users to alleviate some of those inconveniences. -

Page Moovit Partners with GO Bg Transit And
Moovit partners with GO bg Transit and Token Transit to make trip planning and paying easier and safer for Bowling Green riders Public transit riders can plan, pay, and navigate journeys - all from within the Moovit app Bowling Green - March 2021 - GO bg Transit is announcing its partnership with Moovit, an Intel company, a leading Mobility as a Service (MaaS) solutions provider and creator of the world’s #1 urban mobility app, and Token Transit, a mobile ticketing platform for public transit. Starting today, GO bg Transit riders in Bowling Green and the surrounding areas, can seamlessly and safely purchase and validate transit tickets - all from within the Moovit app. Mobile ticketing offers a significant benefit in keeping both passengers and transit agency employees safe. By providing contactless fare payment that can be visually inspected or scanned at validation units, public transportation riders, and transit agency employees, no longer need to handle cash, cards, or interact with ticketing infrastructure, enabling them to maintain social distancing regulations. That’s why GO bg Transit is encouraging Bowling Green’s estimated 70,000 (U.S. Census Bureau) citizens to plan their transit trips, and pay for them too, using the free Moovit app, which has helped 950 million users conveniently and confidently get around 3,400 cities across 112 countries since its launch in 2012. Purchasing and validating transit tickets, via Moovit, has been enabled using Token Transit’s integrated and robust mobile ticketing platform. Once a user launches -

SOW) – PROCUREMENT of TESTING VENDOR for GOPASS MOBILE APP V2.5, February 2018 Statement of Work (SOW) – Procurement of Testing Vendor for Gopass Mobile App
STATEMENT OF WORK (SOW) – PROCUREMENT OF TESTING VENDOR FOR GOPASS MOBILE APP v2.5, February 2018 Statement of Work (SOW) – Procurement of Testing Vendor for GoPass Mobile App Table of Contents Background ................................................................................................................................................... 2 Current Mobile Ticketing .......................................................................................................................... 2 Updated Mobile Ticketing ......................................................................................................................... 2 GoPass Mobile App High Level Specifications .......................................................................................... 2 Agency Objective .......................................................................................................................................... 4 Scope / Deliverables and Schedules ............................................................................................................. 4 Scope / Deliverables ................................................................................................................................. 4 Proposed Testing Schedule ....................................................................................................................... 5 Proposed DART Payment Schedule .......................................................................................................... 6 Contractor / Vendor Capabilities -

Real-Time Transit Information Benefits, Technologies, Components, Experiences and Recommendations
Real-time transit information Benefits, technologies, components, experiences and recommendations White paper prepared by Trillium Solutions, Inc. for Oregon Dept of Transportation (ODOT) Table of Contents About this white paper.................................................................................................................................................... 2 Summary ............................................................................................................................................................................. 4 Definition of real-time transit information .................................................................................................................................... 4 Components.................................................................................................................................................................................................. 4 Benefits ........................................................................................................................................................................................................... 4 Recommendations ..................................................................................................................................................................................... 5 Recommendations to transit providers ..................................................................................................................................... 5 Planning ......................................................................................................................................................................................................................... -

Crowdsourcing Transportation Systems Data
CROWDSOURCING TRANSPORTATION SYSTEMS DATA February 2015 MICHIGAN DEPARTMENT OF TRANSPORTATION AND THE CENTER FOR AUTOMOTIVE RESEARCH ii CROWDSOURCING TRANSPORTATION SYSTEMS DATA FEBRUARY 2015 Sponsoring Organization: Michigan Department of Transportation (MDOT) 425 Ottawa Street P.O. Box 30050 Lansing, MI 48909 Performing Organization(s): Center for Automotive Research (CAR) Parsons Brinkerhoff (PB) 3005 Boardwalk, Ste. 200 100 S. Charles Street Ann Arbor, MI 48108 Baltimore, MD 21201 Report Title: Crowdsourcing Transportation Systems Data MDOT REQ. NO. 1259, Connected and Automated Industry Coordination Sequence D 02 Crowd Sourced Mobile Applications February 11, 2015 Author(s): Eric Paul Dennis, P.E. (CAR) Richard Wallace, M.S. (Director, Transportation Systems Analysis, CAR) Brian Reed, MCSE, CCNP/CCNA, CISSP (PB) Managing Editor(s): Matt Smith, P.E., PTOE (Statewide ITS Program Manager, MDOT) Collin Castle, P.E. (MDOT) Bill Tansil (MDOT) Additional Contributor(s): Josh Cregger, M.S. (CAR) MICHIGAN DEPARTMENT OF TRANSPORTATION AND THE CENTER FOR AUTOMOTIVE RESEARCH iii ACKNOWLEDGMENTS This document is a product of the Center for Automotive Research and Parsons Brinkerhoff, Inc. under a State Planning and Research Grant administered by the Michigan Department of Transportation. This document benefited significantly from the participation of representatives at transportation operations centers (TOCs). The authors thank the following individuals for their valuable contributions: Lee Nederveld from the MDOT Statewide TOC (STOC) John -

TRANSIT TRANSFORMATION: from Operators to Mobility Integrators
TRANSIT TRANSFORMATION: From Operators to Mobility Integrators TRANSIT TRANSFORMATION: From Operators to Mobility Integrators Final Report August 2020 For: Public Transit Office Florida Department of Transportation www.fdot.gov/transit “The opinions, findings, and conclusions expressed in this publication are those of the authors and not necessarily those of the State of Florida Department of Transportation.” ACKNOWLEDGMENTS The study team extends its sincerest appreciation to the following contributors who work diligently each day to “transform” the mobility ecosystem of their own communities for the better. During these unprecedented times, we would additionally like to thank the University of South Florida’s Center for Urban Transportation Research (CUTR) for hosting the virtual “scenario planning” workshop and express gratitude to each participant whose thoughtful perspective and insight helped shape the recommendations of this study. AGENCY SURVEY AND INTERVIEW PARTICIPANTS Broward County Transit LYNX Tara Crawford, Luis Ortiz Sanchez Tomika Monterville, Myles O’Keefe, Patricia Whitton Broward Metropolitan Planning MetroPlan Orlando Organization Nick Lepp, Sarah Larsen Peter Gies, Renee Cross Palm Beach Transportation Planning City of West Palm Beach Agency Uyen Dang Valerie Neilson Collier Area Transit Pinellas Suncoast Transit Authority Zachary Karto Heather Sobush, Jacob Labutka Downtown Fort Lauderdale Transportation St. Lucie Transportation Planning Management Association Organization Robyn Chiarelli Marceia Lathou Gainesville Regional Transit System StarMetro Jesus Gomez Andrea Rosser, Ronnie Lee Shelly, Jr. Hernando/Citrus Metropolitan Planning Tampa Bay Area Regional Transit Authority Organization Brian Pessaro Steve Diez Jacksonville Transportation Authority Suraya Teeple, Paul Tiseo, Jeremy Norsworthy STUDY TEAM Michael Baker International Fred Jones, Brad Thoburn, Catherine Koval, Dara Osher GLOSSARY OF TERMS Application (App) An application, especially as downloaded by a user to a mobile device (smart phone, tablet, laptop) (NCMM, 2020). -

Designing a Transit-Feeder System Using Bikesharing and Peer-To-Peer Ridesharing
University of California Center for Economic Competitiveness in Transportation Designing a Transit-Feeder System Using Bikesharing and Peer-to-Peer Ridesharing Final Report Jay Jayakrishnan, UC Irvine Sponsored by 2017 University of California Center on Economic Competitiveness in Transportation Designing a Transit-Feeder System Using Bikesharing and Peer-to-Peer Ridesharing Final Report on Caltrans Task Order: 2964, Task Order: 46, Contract No: 65A0529 R. Jayakrishnan Michael G. McNally Jiangbo Gabriel Yu Daisik Nam Dingtong Yang Sunghi An The Institute of Transportation Studies, University of California, Irvine, CA 92697 May 2017 1 1. Introduction 5 2. Related Research 7 2.1 Bikesharing program 7 2.2 Ridesharing and its matching algorithm 10 2.3 Bike rebalancing 12 3. Bikesharing and Ridesharing as Transit Feeders 13 3.1 Multi-modal ridesharing 13 3.1.1 Matching algorithm 13 3.1.2 Network expansion 14 3.1.3 Demand generation 15 3.1.4 Dynamic connectors 16 3.2 System performance analysis 19 3.2.1 Metro rail stations accessibility 20 3.2.3 Matching rates 24 3.2.4 Effectiveness on transit demand and bike usage 24 3.2.5. Analysis of number of transfers 26 4. Bike Rebalancing 28 4.1 Introduction and Overview 28 4.2 Problem Formulation 30 4.3 Solution Algorithm 31 4.3.1 Procedure 31 4.3.2 Parameter Estimation 34 4.4 Results and Discussion 36 4.4.1 Results Analysis 36 4.4.2 Why The Proposed Solution Algorithm Is More Efficient And Tractable 38 4.4.3 Future Extension 38 5. Mode Shift Study 40 5.1 Demand Model Overview 40 5.2 Incorporating P2P and Bike Share Service 40 5.3 Results and Discussion 41 6. -

Can Uber and Lyft Save Public Transit?
Claremont Colleges Scholarship @ Claremont Pomona Senior Theses Pomona Student Scholarship 2019 Can Uber and Lyft Save Public Transit? Emily Zheng Follow this and additional works at: https://scholarship.claremont.edu/pomona_theses Part of the Econometrics Commons, Economic Policy Commons, Environmental Policy Commons, Policy Design, Analysis, and Evaluation Commons, Public Affairs Commons, Public Economics Commons, Public Policy Commons, Science and Technology Policy Commons, Science and Technology Studies Commons, Transportation Commons, and the Urban Studies Commons Can Uber and Lyft save Public Transit? Emily Zheng Pomona College Claremont, California April 26, 2019 Presented to: Bowman Cutter Associate Professor of Economics, Pomona College Jennifer Ward-Batts Lecturer in Economics, Pomona College Submitted in partial fulfillment of the requirements for a Bachelor of Arts degree with a major in Economics/Public Policy Analysis Acknowledgements Thank you to my readers, Bowman Cutter and Jennifer Ward-Batts, for their advising and guidance throughout the thesis writing process. I would also like to thank Warren Lee and Sebastian Hack for their valuable feedback and coding expertise. Finally, a big thank you to my family for their continuous, unwavering support over the years. Table of Contents SECTION I: INTRODUCTION 1 CHAPTER 1: LITERATURE REVIEW 4 NATIONAL RIDERSHIP TRENDS 4 SHARED MOBILITY, TECHNOLOGY, AND TRANSIT RIDERSHIP 9 CONCLUSION 10 SECTION II: HOW TNCS CURRENTLY AFFECT PUBLIC TRANSIT RIDERSHIP 12 CHAPTER 2: THEORY 13 CHAPTER -
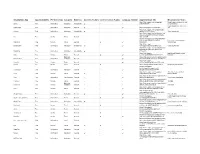
Smartphone App App Availability Provision Type Category Main Use
Smartphone App App Availability Provision Type Category Main Use Assistive Feature Cost-conscious Feature Language Options App Download Site Miscellaneous Notes https://itunes.apple.com/us/app/abil. Simplified presentation for easy abil.io Free Information Navigation Accessibility ✔ - - io/id980873789 comprehension Visual impairment, voice from Apple Maps Free Information Navigation General ✔ - ✔ https://www.apple.com/ios/maps/ Siri https://itunes.apple.com/us/app/ariadne- Ariadne Paid Information Navigation Accessibility ✔ - - gps/id441063072?mt=8 Visual impairment https://itunes.apple.com/us/app/arro-your- taxi-your-way/id979943889?mt=8&ign- Arro Free Service Travel General - - - mpt=uo%3D4 https://itunes.apple.com/fr/app/blablacar- trusted-carpooling/id341329033? Peer-to-peer carsharing for BlaBlaCar Free Service Travel General - ✔ ✔ l=en&mt=8 long journeys https://itunes.apple. BlindSquare Paid Information Navigation Accessibility ✔ - ✔ com/app/blindsquare/id500557255 Visual impairment https://itunes.apple.com/us/app/blindways- bus-stop-navigation/id1146615175? BlindWays Free Information Navigation Accessibility ✔ - - ls=1&mt=8 https://itunes.apple. English and Spanish, mass Bridj Free Service Travel General - ✔ ✔ com/us/app/bridj/id938140457?mt=8 transport Maps and https://play.google.com/store/apps/details? Bus Checker Free Information navigation General - - ✔ id=com.fatattitude.buscheckermta&hl=en https://itunes.apple. Car2GO Free Service Travel General - ✔ com/us/app/car2go/id514921710?mt=8 Carma Free Service Travel General - ✔ -

The Data Transit Riders Want
001000100110010010100010100100101010001010100 101001000010010101111101001000100010011001001 010001010010010101000101010010100100001001010 111110100100010001001100100101000101001001010 100010101001010010000100101011111010010`001000 100110010010100010100100101010001010100101001The Data Transit 000010010101111101001000100010011001001010001Placehold for cover 010010010101000101010010100100001001010111110 100100010001001100100101000101001001010100010Riders Want 101001010010000100101011111010010001000100110 010010100010100100101010001010100101001000010 010101111101001000100010011001001010001010010 010101000101010010100100001001010111110100101 001010111110100100010001001100100101000101001 001010100010101001010010000100101011111010010 001000100110010010100010100100101010001010100 101001000010010101111101001010010010010111100 011100101010110010101111101001000100010011001 001010001010010010101000101010010100100001001 010111110100100010001001100100101000101001001 010100010101001010010000100101011111010010100 100010001001100100101000101001001010100010101 001010010000100101011111010010001000100110010 010100010100100101010001010100101001000010010 101111101001000100010011001001010001010010010 10100010101001010010000100101011111010010`0010A Shared Agenda for 001001100100101000101001001010100010101001010Public Agencies and Transit 010000100101011111010010001000100110010010100Application Developers 010100100101010001010100101001000010010101111 101001000100010011001001010001010010010101000 101010010100100001001010111110100100010001001 The Data Transit Riders -

Trip Planning for Employees June 23, 2021
Trip Planning for Employees June 23, 2021 Ross and Alex intro Alex - Community Programs Specialist working on some non traditional transit solutions focused on Lynnwood currently 1 Agenda • Why Trip Plan? • Commute Options • Transit • Biking/Walking • Carpool/Vanpool • Questions/Comments 2 Why Trip Plan? • Compare modes, times estimates, cost • Good to double check different tools sometimes 3 Why Trip Plan? Fill the gaps! • Knowledge • Misinformation • Outdated information Removing barriers promotes Image credit: Verywell Mind “6 stages of behavior change” behavior change 4 Commute Options Transit • Community Transit Trip Planner • Alerts for any route • Bus Finder • Bus Seat Availability • Bus Plus • Calling our Customer Care or visiting our Lynnwood RideStore • What about Swift Bus Rapid Transit? • What about DART paratransit? • Community Transit Trip Planner – Plan a trip • Bus Alerts for any route – Get alerts for your bus • Bus Finder – Find your bus in real time • Bus Seat Availability – See how crowded or not your bus is • Bus Plus – PDF of our schedule book if you prefer to plan this way. Let us know if you need hard copies. • Customer Care – Call or email for trip planning, customer comments, transit information • Lynnwood RideStore – ORCA assistance, lost and found • Fares and Pass information – Contact us with any questions about ORCA for Business solutions • Swift – Two Swift lines, Blue and Green and schedules not needed because frequency - Buses arrive every 10 minutes on weekdays and every 15–20 minutes on early mornings, evenings, and weekends. You don’t even need a schedule. Just get on and get moving. I still like to check so I can time my wait appropriately.