Automated Subtitling Workflows
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

LIVA - a Software Live Video & Audio Production Framework Team’S Presentation
Presentation of the Stars4Media Initiative: LIVA - a software live video & audio production framework Team’s presentation Video Snackbar Hub: exchanging knowledge on new technologies, ideas and workflows to support content creators and part of the Future Media Hubs. An international network of media companies that strengthen each other and collaborate on innovative and/or strategic topics. Chosen representatives for the Stars4Media-project were: ● Morten Brandstrup, Head of news technology – TV2 Denmark ● Hugo Ortiz, IP Broadcast Coach – RTBF ● Floris Daelemans, Innovation Researcher – VRT ● Henrik Vandeput, Software developer (freelancer) – VRT ● Sarah Geeroms, Strategic partnerships and Head of FMH – VRT ● Coralie Villeret, Software engineer and UX designer – RTBF [email protected] Initiative’s summary ● To explore the boundaries of standard broadcast technology ● Building custom components in a creative software (TouchDesigner) ● Exploring the significant profit of a new workflow (both financially and creatively) ● Learning some interesting insights and different approaches from junior profiles ● Expanding our skill-sets https://www.videosnackbarhub.com [email protected] Initiative’s results ● Added experience to the junior profiles within our media organizations ● Resourced our community of like-minded media players ● Resulting components with lots of possibilities ● Helped us explore Github and TouchDesigner in-depth ● Applied new and creative software to our broadcast ● Received constructive feedback from our international -
Nhk World Tv | Asia 7 Days
NHK WORLD TV | ASIA 7 DAYS Home News TV Radio & Podcast Japanese Select language Lessons Corporate Info Sitemap Contact Us FAQ Home > TV > ASIA 7 DAYS TV Programs ASIA 7 DAYS TV Schedule TV Schedule View Full Schedule Program Info Archives How to Watch Other TV Program Anchors & Programs by Genre Reporters Program A-Z Sun. 14:10 - 14:40 (UTC) etc. FAQ Recommended Asia is a region of multiple ethnicities and What kind of channel is diverse culture. Each region has its own social NHK WORLD TV? / What structures and political systems, differs in the kind of channel is NHK stages of their development. ASIA 7 DAYS WORLD PREMIUM? / What wraps up major issues of Asia, in relation to is the difference between Hosted by Susumu Shimokawa the news occurred in that week. NHK WORLD TV and NHK English WORLD PREMIUM? NEWSLINE How Can I receive NHK Topics of the Week: Broadcasting every WORLD TV and NHK day on the hour WORLD PREMIUM? Mar. 27, Sun. 14:30 - 15:00 (UTC) etc. every hour Great Japan Quake: View from Asia Broadcast every day, FAQ List NEWSLINE provides Many foreigners from other parts of Asia are affected by the March 11 earthquake and detailed updates on the tsunami. Tens of thousands of Chinese, Filipinos and Thais live in the Tohoku disaster zone, ever-changing news in an easy-to-follow manner, where 25,000 people are so far believed dead or missing. For many of the foreign survivors -- focusing mainly on Japan workers, students and spouses -- the ordeal is far from over. -

Giovanni Ridolfi RAI – Technological Strategies
Global Forum - Shaping the future Venezia, 5-6 November 2007 “Towards HDTV and beyond …” Giovanni Ridolfi RAI – Technological Strategies Strategie Tecnologiche 1 Summary 9From TV to HDTV 9Technological developments 9Value chain impacts 9Beyond HDTV Strategie Tecnologiche 2 TV is a long-standing improving technology Berlin Olympic games (1936): 180 rows HD BBC (1937): 405 rows NTSC (1949): 525 rows PAL (1963): 625 rows SD HDTV: 1000 rows Strategie Tecnologiche 3 HDTV facts 9 Spatial resolution: ) 576 x 768 → 1080 x 1920 9 Wide format: ) 4/3 → 16/9 9 Rich audio: 9 Uncompressed = 1.5Gbps ) Stereo → Multichannel 9 Compressed 9 Stability of images: ) MPEG-2 = 18 Mbps ) MPEG-4 AVC = 9 Mbps ) 25 → 50 fps ) Interlaced → progressive HDTV experience requires high bandwith and new equipments to be really enjoyed ! Strategie Tecnologiche 4 Public Broadcasters are supposed to pioneer technology 9 In early 80s RAI pioneered HDTV production: ) 1983: “Arlecchino” (cinematography by Vittorio Storaro); ) 1986: “Giulia and Giulia” (directed by Peter Del Monte); 9 In 1986, RAI and NHK jointly performed technical tests and demonstrations with early HDTV system; 9 In 1990 (Italia-90 World Soccer Cup) RAI transmitted 17 games in HDTV with the first digital compression system via satellite (joint project Rai Research Center – Telettra)); 9 In 2006 (Turin Olympic Winter Games) RAI was the first worldwide broadcaster to transmit HDTV and Mobile TV combined on a single digital terrestrial channel. Strategie Tecnologiche 5 RAI for HDTV now 9 High quality productions, -

European Public Service Broadcasting Online
UNIVERSITY OF HELSINKI, COMMUNICATIONS RESEARCH CENTRE (CRC) European Public Service Broadcasting Online Services and Regulation JockumHildén,M.Soc.Sci. 30November2013 ThisstudyiscommissionedbytheFinnishBroadcastingCompanyǡYle.Theresearch wascarriedoutfromAugusttoNovember2013. Table of Contents PublicServiceBroadcasters.......................................................................................1 ListofAbbreviations.....................................................................................................3 Foreword..........................................................................................................................4 Executivesummary.......................................................................................................5 ͳIntroduction...............................................................................................................11 ʹPre-evaluationofnewservices.............................................................................15 2.1TheCommission’sexantetest...................................................................................16 2.2Legalbasisofthepublicvaluetest...........................................................................18 2.3Institutionalresponsibility.........................................................................................24 2.4Themarketimpactassessment.................................................................................31 2.5Thequestionofnewservices.....................................................................................36 -

Download This PDF File
internet resources John H. Barnett Global voices, global visions International radio and television broadcasts via the Web he world is calling—are you listening? used international broadcasting as a method of THere’s how . Internet radio and tele communicating news and competing ideologies vision—tuning into information, feature, during the Cold War. and cultural programs broadcast via the In more recent times, a number of reli Web—piqued the interest of some educators, gious broadcasters have appeared on short librarians, and instructional technologists in wave radio to communicate and evangelize the 1990s. A decade ago we were still in the to an international audience. Many of these early days of multimedia content on the Web. media outlets now share their programming Then, concerns expressed in the professional and their messages free through the Internet, literature centered on issues of licensing, as well as through shortwave radio, cable copyright, and workable business models.1 television, and podcasts. In my experiences as a reference librar This article will help you find your way ian and modern languages selector trying to to some of the key sources for freely avail make Internet radio available to faculty and able international Internet radio and TV students, there were also information tech programming, focusing primarily on major nology concerns over bandwidth usage and broadcasters from outside the United States, audio quality during that era. which provide regular transmissions in What a difference a decade makes. Now English. Nonetheless, one of the benefi ts of with the rise of podcasting, interest in Web tuning into Internet radio and TV is to gain radio and TV programming has recently seen access to news and knowledge of perspec resurgence. -

Minority-Language Related Broadcasting and Legislation in the OSCE
University of Pennsylvania ScholarlyCommons Other Publications from the Center for Global Center for Global Communication Studies Communication Studies (CGCS) 4-2003 Minority-Language Related Broadcasting and Legislation in the OSCE Tarlach McGonagle Bethany Davis Noll Monroe Price University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/cgcs_publications Part of the Critical and Cultural Studies Commons Recommended Citation McGonagle, Tarlach; Davis Noll, Bethany; and Price, Monroe. (2003). Minority-Language Related Broadcasting and Legislation in the OSCE. Other Publications from the Center for Global Communication Studies. Retrieved from https://repository.upenn.edu/cgcs_publications/3 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/cgcs_publications/3 For more information, please contact [email protected]. Minority-Language Related Broadcasting and Legislation in the OSCE Abstract There are a large number of language-related regulations (both prescriptive and proscriptive) that affect the shape of the broadcasting media and therefore have an impact on the life of persons belonging to minorities. Of course, language has been and remains an important instrument in State-building and maintenance. In this context, requirements have also been put in place to accommodate national minorities. In some settings, there is legislation to assure availability of programming in minority languages.1 Language rules have also been manipulated for restrictive, sometimes punitive ends. A language can become or be made a focus of loyalty for a minority community that thinks itself suppressed, persecuted, or subjected to discrimination. Regulations relating to broadcasting may make language a target for attack or suppression if the authorities associate it with what they consider a disaffected or secessionist group or even just a culturally inferior one. -

This Is NHK 1976-77. INSTITUTION Japan Broadcasting Co., Tokyo PUB DATE 76 NOTE 36P
DOCUHENT RESUSE ED 129 272 IR 004 054 TITLE This is NHK 1976-77. INSTITUTION Japan Broadcasting Co., Tokyo PUB DATE 76 NOTE 36p. EDRS PRICE MF-$0.83 HC-$2.06 Plus Postage. DESCRIPTORS *Annual Peports; Audiences; *Broadcast Industry; Educational Radio; Foreign Countries; Production Techniques; Programing (Broadcast); *Public Television; Television Surveys IDENTIFIERS *Japan; NHK; *Nippon Hoso Kyokai ABSTRACT Nippon Hoso Kyokai (NHK), the Japanese Broadcasting Corporation, operates two public television, two medium wave radio and one VHF-FM public radio networks. NHK derives its support from receiver fees. Under the 1950 Broadcast Law which established NHK as a public broadcasting organization the Prime Minister appoints NHK's Board of Governors and the National Diet approves its budget. The government is restrained under the law from interfering with programing, however. NHK broadcasting standards are supplemented by extensive public surveying in making programing determinations. News, educational, cultural and entertainment programs plus special documentaries are presented over NHK stations. NHK's overseas system broadcasts in 21 languages. The network operates a Radio and TV Culture Research Institute and a Public Opinion Research Lab in addition to technical research division. Since 1972 NHK has had a budget deficit. New management techniques and higher fees have recently been instituted. Appendixes to the corporation report include public opinion data, technical descriptions, and a brief history of NHK. (KB) THIS IS NHK 1976-77 Nippon -

Media Industries You Will Need to Consider
Media Studies - TV Student Notes Media Industries You will need to consider: • Processes of production, distribution and circulation by organisations, groups and individuals in a global context. • The specialised and institutionalised nature of media production, distribution and circulation. • The significance of patterns of ownership and control including conglomerate ownership, vertical integration and diversification. • The significance of economic factors, including commercial and not-for-profit public funding, to media industries and their products. • How media organisations maintain, including through marketing, varieties of audiences nationally and globally. • The regulatory framework of contemporary media in the UK. • How processes of production, distribution and circulation shape media products. • The role of regulation in global production, distribution and circulation. • Regulation (including Livingstone and Lunt) at A level. • Cultural industries (including Hesmondhalgh) at A Level. No Burqas Behind Bars This should be linked where relevant to • Social, • Cultural, • Economic, • Political and • Historical contexts. • The significance of different ownership and/or funding models in the television industry (i.e. whether media companies are privately or publicly owned, whether they are publicly or commercially funded etc.) • The growing importance of co-productions (including international co-productions) in the television industry today Media Studies - TV 1 Media Studies - TV Student Notes • The way in which production values -

Accountability in Public Service Broadcasting: the Evolution of Promises and Assessments
Accountability in Public Service Broadcasting: The Evolution of Promises and Assessments NAKAMURA Yoshiko Today, the world’s public service broadcasters, including NHK in Japan, are increasingly called upon to define their remits and make them public, and to present the assessments as to whether they are indeed being carried out. Since public service broadcasters throughout the world operate with funds collected through license fees (receiving fees in Japan) or public funds such as govern- ment subsidies, they are obliged to be accountable to the audiences and citi- zens paying for the service. Until now, public service broadcasters have sought to ensure accountability by meeting institutional requirements such as publication of mandatory annual reports and accounts, handling of audience complaints, and responses to audience needs through broadcasting commit- tees. Public service broadcasters obviously need to be accountable in order to maintain trust with their audiences. This basic assumption is shared by European media scholars and researchers. Cultural Dilemmas in Public Service Broadcasting, by Gregory Ferrell Lowe and Per Jauert (Lowe and Jauert, 2005), which not only focuses on public service broadcasting quality, performance assessment, and the need for accountability but also suggests possible strategies for public service broadcasters in the face of a changing media environment, offers valuable thought on these issues. This paper will present case studies of the initiatives taken by public broadcasters in Sweden, Denmark, the U.K., and Japan regarding accountability and discuss mainly institutional reforms for strengthening accountability. REASONS FOR STRENGTHENING ACCOUNTABILITY Since the 1990s, advances in cable television technology and the availability of satellite broadcasting have made it possible for broadcasters across the world to provide multiple channels. -
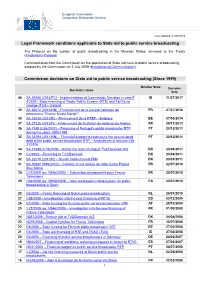
List of Public Broadcasting Decisions
European Commission Competition Directorate-General Last updated: 01/07/2019 Legal Framework conditions applicable to State aid to public service broadcasting The Protocol on the system of public broadcasting in the Member States, annexed to the Treaty (Amsterdam Protocol). Communication from the Commission on the application of State aid rules to public service broadcasting, adopted by the Commission on 2 July 2009 (Broadcasting Communication). Commission decisions on State aid to public service broadcasting (Since 1999) Member State Decision Decision name date 40 SA.39346 (2014/FC) - Implementation of Commission Decision in case E IE 11/07/2017 4/2005 - State financing of Radio Teilifís Éireann (RTÉ) and Teilifís na Gaeilge (TG4) - Ireland 39 SA.36672 (2013/NN) - Financement de la société nationale de FR 27/07/2016 programme "France Media Monde" 38 SA.32635 (2012/E) – Financement de la RTBF – Belgique BE 07/05/2014 37 SA.37136 (2013/N) - Financement de la station de radio locale France FR 08/11/2013 36 SA.7149 (C85/2001) – Financing of Portugal's public broadcaster RTP PT 20/12/2011 during the years 1992-1998 35 SA.33294 (2011/NN) – Financial support to restructure the accumulated PT 20/12/2011 debt of the public service broadcaster RTP – Amendment of decision NN 31/2006 34 SA.27688 (C19/2009) - Aid for the restructuring of TV2/Danmark A/S DK 20/04/2011 33 C2/2003 – Financing of TV2/Danmark DK 20/04/2011 32 SA.32019 (2010/N) – Danish radio channel FM4 DK 23/03/2011 31 SA.30587 (N95/2010) – Création d’une station de radio locale France FR 22/07/2010 Bleu Maine 30 C27/2009 (ex. -

DOCUMENT RESUME Educational Broadcasts Of
DOCUMENT RESUME ED 067 884 EM 010 375 TITLE Educational Broadcasts of NHK; Special Issue of NHK Today and Tomorrow. INSTITUTION Japanese National Commission for UNESCO, Tokyo. PUB DATE Oct 72 NOTE 42p. EDRS PRICE MF-$0.65 HC-$3.29 DESCRIPTORS Children; Correspondence Courses; *Educational Radio; Educational Television; *Home Study; *Instructional Television; *Programing (Broadcast); Telecourses; *Televised Instruction IDENTIFIERS Japan; NHK; Nippon Hoso Kyokai ABSTRACT Nippon Hoso Kyokai (MR), the Japan Broadcasting Corporation, is the only public service broadcasting organization in Japan. This booklet lists the schedule of courses offered by NHK on educational television and radio for 1972. A wide range of instructional broadcasts are offered. For school children from kindergarten through high school, programs cover the Japanese language, science, social studies, English, music, art, ethics, technical questions, and home economics. Programs are also offered for correspondence education at senior high school and college levels. There are also special programs for physically or mentally handicapped children. In addition, the networks present cultural and special interest classes which are not connected to formal courses. The goals of NHK programing in each of these areas is discussed briefly. (JK) U S DEPARTMENT OF HEALTH. EDUCATION & WELFARE OFFICE OF EDUCATION THIS DOCUMENT HAS BEEH REPRO DUCED EXACTLY AS RECEIVED FROM THE PERSON OR ORGANIZATION CMG INATING IT POINTS OF VIEW OR OPIN IONS STATED DO NOT NECESSARILY REPRESENT OFFICIAL OFFICE OF EDU CATION POSITION OR POLICY 1 A Special Issue of NHK TODAY AND TOMORROW OCTOBER 1972 PUBLIC RELATIONS BUREAU NIPPON HOSO KYOKAI (JAPAN BROADCASTING CORPORATION) TOKYO, JAPAN THE ANNUAL REPORT OF THE EDUCATIONAL BROADCASTS OF NHK FOR FISCAL YEAR 1972 PABLIC RELATIONS BUREAU NHK (JAPAN BROADCASTING CORPORATION) 2-2-3 UCHISAIWAI-CHO, CHIYODA-KU, TOKYO TEL. -

Ibc Accelerators
www.ibc.org IBC ACCELERATORS Supporting collaborative innovation across the Media Entertainment Ecosystem May 2021 W: show.ibc.org/accelerators E: [email protected] About IBC § IBC is an independent and authoritative international organisation serving the global Media, Entertainment & Technology industry. § For over 50 years IBC has run the world’s biggest, most influential annual event for the industry. § It is simply the must-attend event in the Media, Entertainment and Technology industry’s calendar! § IBC’s event in Amsterdam attracts more than 56,000+ attendees from 150 countries around the world, 1,700 exhibitors - the world’s key technology suppliers and has a thought-leading conference at the core § 6 leading international bodies form the ownership behind IBC, representing both Exhibitors and Visitors, these include IEEE, IABM, IET, RTS, SCTE and SMPTE 2 The Accelerator Framework for Media & Entertainment Innovation IBC created the Accelerator programme in 2019, to support the media & entertainment technology sector with a framework for agile, collaborative and fast-track innovation. The programme is designed to address a wide range of business and technology challenges disrupting the sector, for example… § Transition to software and IP across the content supply chain § Rapid evolution of new technologies e.g. AI, Voice, IoT, Cloud etc. § Potential for immersive & experiential tech e.g. VR/AR/ XR, 8K etc § Onset of 5G and a vast array of new creative, production & distribution opportunities § A boom in direct to consumer platform plays and an original content § Regulatory disparity with online platforms and the value of trust § Fragmenting audiences across platforms, screens and devices § Accelerated remote & distributed production strategies The IBC Accelerators take on ’bite size’ challenges in a project based, multi-company approach, developing innovative solutions to common pain points, with invaluable ‘hands on’ experimentation.