A Public Data Set for Energy Disaggregation Research
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Block B Album Download Block B Members Profile
block b album download Block B Members Profile. Block B (블락비) currently consists of: Zico, Taeil, B-Bomb, Jaehyo, U-Kwon, Kyung, and P.O . Leader Zico left the company on November 23, 2018, however according to Seven Seasons , the future of the band as a 7-members band is still under discussion. The band debuted on April 13, 2011, under Stardom Entertainment. In 2013, they left their agency and signed with Seven Seasons, a subsidiary label to KQ Entertainment. Block B Fandom Name: BBC (Block B Club) Block B Official Fan Color: Black and Yellow Stripes. Block B Official Accounts: Twitter: @blockb_official Facebook: BlockBOfficial Instagram: @blockb_official_ Fan cafe: BB-Club. Block B Members Profile: Zico Stage Name: Zico (지코) Birth Name: Woo Ji Ho (우지호) Position: Leader, Main Rapper, Vocalist, Face of the Group Birthday: September 14, 1992 Zodiac Sign: Virgo Birthplace: Seoul, South Korea Height: 181 cm (5’11”) Weight: 65 kg (143 lbs) Blood Type: O Twitter: @ZICO92 Instagram: @woozico0914. Zico Facts: – He was born in Mapo, Seoul, South Korea. – He has an older brother, Woo Taewoon, who was a former member of idol group Speed. – He was a Vocal Performance major at Seoul Music High School. – Zico studied at the Dong-Ah Institute of Media and Arts University (between 2013 -2015). – Specialties: Freestyle rap, composing, weaving melody lines. – He auditioned for S.M. Entertainment as a teenager. – He joined Stardom Entertainment in 2009. – Zico lived abroad in Japan for three years. – On November 7, 2014, Zico released his official solo debut single entitled “Tough Cookie” featuring the rapper Don Mills – He, along with Kyung have produced all of Block B’s albums. -

Hip-Hop and Cultural Interactions: South Korean and Western Interpretations
HIP-HOP AND CULTURAL INTERACTIONS: SOUTH KOREAN AND WESTERN INTERPRETATIONS. by Danni Aileen Lopez-Rogina, B.A. A thesis submitted to the Graduate Council of Texas State University in partial fulfillment of the requirements for the degree of Master of Arts with a Major in Sociology May 2017 Committee Members: Nathan Pino, Chair Rachel Romero Rafael Travis COPYRIGHT by Danni Aileen Lopez-Rogina 2017 FAIR USE AND AUTHOR’S PERMISSION STATEMENT Fair Use This work is protected by the Copyright Laws of the United States (Public Law 94-553, section 107). Consistent with fair use as defined in the Copyright Laws, brief quotations from this material are allowed with proper acknowledgement. Use of this material for financial gain without the author’s express written permission is not allowed. Duplication Permission As the copyright holder of this work I, Danni Aileen Lopez-Rogina, refuse permission to copy in excess of the “Fair Use” exemption without my written permission. DEDICATION To Frankie and Holly for making me feel close to normal. ACKNOWLEDGEMENTS I want to acknowledge my mom, dad, and sister first and foremost. Without their love and support over the years, I would not have made it this far. They are forever my cheerleaders, no matter how sassy I may be. Professor Nathan Pino was my chosen mentor who took me under his wing when I chose him like a stray cat. His humor and dedication to supporting me helped me keep my head up even when I felt like I was drowning. Professor Rachel Romero was the one to inspire me to not only study sociology, but also to explore popular culture as a key component of society. -

Roots and Routes 188
Fendler / Roots and Routes 188 ROOTS AND ROUTES Hip-Hop from South Korea Ute Fendler University of Bayreuth [email protected] Abstract With the growing success of hip-hop in South Korea, the discussions about the authenticity of this genre increase and create cleavages between the mainstream and the underground rappers. The paper intends to analyze three examples of the contemporary music scene that are representative of different positions. Taking Simon Frith’s work on popular music as a means to construct identity, the paper suggests questioning the concept of authenticity (“roots”) and proposes instead conceiving hip-hop in South Korea as a movement at the crossroads (“routes”) of various influences and practices. Keywords Authenticity, Identity, Music videos, Performance, R&B, Rap About the Author Ute Fendler is chair of romance cultural and comparative cultural studies at the University of Bayreuth (Germany). Her research interests include intermedial and intercultural phenomenon, popular culture, migration, iconographies, music video, and performance. Kritika Kultura 29 (2017): –213 © Ateneo de Manila University <http://journals.ateneo.edu/ojs/kk/> Fendler / Roots and Routes 189 In the ongoing process of reaching out to global markets, pop music in South Korea undergoes fast changes, mainly under the influence of US-American and Western European markets, as literature on K-pop highlights (Choi and Maliangkay). John Lie dealt with the question of K-pop as music positioned between different influences: K-pop is symptomatic of the cultural transformation of South Korea: at once the almost complete repudiation of traditional cultures—both Confucian and folk—and the repeated rhetorical stress on the continuities between the past and the present: the nearly empty signifier that is South Korean cultural-national identity. -

UC Riverside Electronic Theses and Dissertations
UC Riverside UC Riverside Electronic Theses and Dissertations Title K- Popping: Korean Women, K-Pop, and Fandom Permalink https://escholarship.org/uc/item/5pj4n52q Author Kim, Jungwon Publication Date 2017 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA RIVERSIDE K- Popping: Korean Women, K-Pop, and Fandom A Dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Music by Jungwon Kim December 2017 Dissertation Committee: Dr. Deborah Wong, Chairperson Dr. Kelly Y. Jeong Dr. René T.A. Lysloff Dr. Jonathan Ritter Copyright by Jungwon Kim 2017 The Dissertation of Jungwon Kim is approved: Committee Chairperson University of California, Riverside Acknowledgements Without wonderful people who supported me throughout the course of my research, I would have been unable to finish this dissertation. I am deeply grateful to each of them. First, I want to express my most heartfelt gratitude to my advisor, Deborah Wong, who has been an amazing scholarly mentor as well as a model for living a humane life. Thanks to her encouragement in 2012, after I encountered her and gave her my portfolio at the SEM in New Orleans, I decided to pursue my doctorate at UCR in 2013. Thank you for continuously encouraging me to carry through my research project and earnestly giving me your critical advice and feedback on this dissertation. I would like to extend my warmest thanks to my dissertation committee members, Kelly Jeong, René Lysloff, and Jonathan Ritter. Through taking seminars and individual studies with these great faculty members at UCR, I gained my expertise in Korean studies, popular music studies, and ethnomusicology. -

Case 1:11-Cv-05580-JPO D Ument 15 Filed 10/31/11 Page 1 of 36
Case 1:11-cv-05580-JPO D ument 15 Filed 10/31/11 Page 1 of 36 %.;OPY UNITED STATES DISTRICT COURT SOUTHERN DISTRICT OF NEW YORK } STACEY B. FISHBEIN, KATRINA GARCIA, } Case No. 11-Civ-S CATALINA SALDARRIAGA and RUSSELL } MARCHEWKA, on Behalf of Themselves and All ) Others Similarly Situated, ) AMENDED CLASS ACTION } COMPLAINT Plaintiffs, ) vs. ) JURY TRIAL DEMANDED ALL MARKET INC. d/b/a VITA COCO, } } Defendant. } } AMENDED CLASS ACTION COMPLAINT Plaintiffs Stacey B. Fishbein , Katrina Garcia, Catalina Saldarriaga , and Russell Marchewka ("Plaintiffs "), by and through their undersigned counsel, upon personal knowledge as to themselves and upon information and belief as to all other matters, allege as follows: I. Plaintiffs bring this action against defendant All Market Inc . d/b/a Vita Coco ("All Market" or "Defendant") on behalf of themselves and all other similarly situated individuals and entities who purchased, for personal use, "Vita Coco Coconut Water" products (collectively, "Vita Coco Products") during the period between August 10, 2007 and the date of the final disposition of this action (as defined below, the "Classes"). BACKGROUND 2. Defendant manufactures, markets and sells Vita Coco Products throughout the United States and North America. Case 1:11-cv-05580-JPO Document 15 Filed 10/31/11 Page 2 of 36 UNITED STATES DISTRICT COURT SOUTHERN DISTRICT OF NEW YORK STACEY B. FISHBEIN, KATRINA GARCIA, } Case No. 11-Civ-5580 CATALINA SALDARRIAGA and RUSSELL } MARCHEWKA, on Behalf of Themselves and All ) Others Similarly Situated, } AMENDED CLASS ACTION } COMPLAINT Plaintiffs, ) vs. ) JURY TRIAL DEMANDED ALL MARKET INC. d/b/a VITA COCO, } } Defendant. -
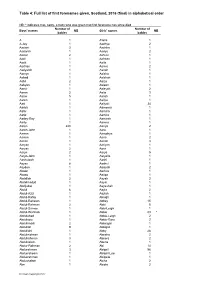
Table 4: Full List of First Forenames Given, Scotland, 2016 (Final) in Alphabetical Order
Table 4: Full list of first forenames given, Scotland, 2016 (final) in alphabetical order NB: * indicates that, sadly, a baby who was given that first forename has since died Number of Number of Boys' names NB Girls' names NB babies babies A 1 A'lelia 1 A-Jay 1 Aadhya 2 Aadam 3 Aadrika 1 Aadarsh 1 Aadya 2 Aaden 2 Aafeen 1 Aadi 1 Aafreen 1 Aadit 1 Aaila 1 Aadrian 1 Aaima 2 Aadyanth 1 Aairah 1 Aaeryn 1 Aaisha 1 Aahad 1 Aaishah 1 Aahil 2 Aaiza 1 Aahyan 1 Aaleen 1 Aamir 1 Aaleyah 2 Aaran 2 Aalia 3 Aarav 5 Aaliah 1 Aaren 1 Aaliya 1 Aari 1 Aaliyah 34 Aarick 1 Aameera 1 Aariv 1 Aamina 1 Aariz 1 Aamira 1 Aarley-Ray 1 Aamirah 1 Aarlo 1 Aamna 1 Aaron 240 Aanya 2 Aaron-John 1 Aara 1 Aarran 1 Aaradhya 1 Aarron 1 Aaria 2 Aarvin 1 Aariah 3 Aaryan 1 Aariyah 1 Aaryav 2 Aarvi 1 Aaryn 2 Aarya 5 Aaryn-John 1 Aaryella 1 Aashutosh 1 Aashi 1 Aayan 8 Aashvi 1 Aayden 1 Aasiyah 2 Abaan 1 Aathira 1 Abaas 1 Aatiqa 1 Abdallah 2 Aayah 2 Abdelmadjid 1 Aayat 1 Abdijabar 1 Aayeshah 1 Abdul 6 Aayla 2 Abdul-Aziz 1 Aaylah 1 Abdul-Rafay 1 Abaigh 1 Abdul-Raheem 1 Abbey 15 Abdul-Rahman 2 Abbi 5 Abdul-Samee 1 Abbi-Leigh 1 Abdul-Wahhab 1 Abbie 83 * Abdulahad 1 Abbie-Leigh 2 Abdulaziz 1 Abbie-Rose 2 Abdulhaadi 2 Abbiegail 1 Abdullah 9 Abbigail 1 Abdullahi 1 Abby 28 Abdulmohsen 1 Abeeha 2 Abdulrahman 3 Abeera 2 Abdulsalam 1 Abena 1 Abdur-Rahman 2 Abi 14 Abdurahman 3 Abigail 96 Abdurraheem 1 Abigail-Lee 1 Abdurrahman 1 Abigaile 1 Abdussalam 1 Abiha 2 Abe 1 Abiola 2 © Crown Copyright 2017 Table 4 (continued) NB: * indicates that, sadly, a baby who was given that first forename has -

Wellesley Ksa Presents
WELLESLEY KSA PRESENTS Wellesley College Korean Students Association presents SEOUL NIGHT LIVE Live from Wellesley, it’s Seoul Night Live! We’re very excited you’re joining us tonight for our biggest event of the year--the Annual KSA Culture Show! Follow our show hosts, Lily and Jen, as they take you through the exciting performances we have prepared for you tonight. Stay seated, and we hope you enjoy the show! Korean Student Association Executive Board Co Presidents Hajin Park & Rachel Seo Vice President Jackie Ha Treasurer Jane Lee Co Culture Chairs Jennifer Chung & Chloe Moon Secretary Denise Yoon Publicity Chair Jee Lee Multimedia Chair Sharon Cho Senator Soobean Jo Social Chair Julia Cho Community Service Chair Michelle Namkoong International Representative Chaerin Park Korean Program Liaison Sojin Ki First Year Representative Sandra Chung & Sue Lee Emcees Lily Kim & Jennifer Vogan Eboard Video Editor Rachel Utomo & Cathy Ye Technical Staff Denysha Jackson Videographer Jalena Keane-Lee Photographer Christine Yang PART 1 Eboard Introduction (Video) First-Year Dance Choreographed by Sue Lee ‘20, Annie Kang ‘20, Grace Chin ‘20 Esther Luo ‘20, Gemma Min ‘20, Chandler Pettigrew ‘20, Heidi Cho ‘20, Annie Kang ‘20 / Neri Min ‘20, Sue Lee ‘20, Stella Kim ‘20, Yebin Park ‘20, Yuna Gan ‘20, Casey Smith ‘20, Sandra Chung ‘20 / Grace Chin ‘20, Chloe Yichen Wang ‘20, Winnie Chen ‘20, Caitlyn Chung ‘20 The first-year dance has become a tradition of Wellesley KSA’s Culture Show. Every year our first-year members put together an act that showcases some of Korea’s most recent and popular hits. -

ZICO CAPITAL PTE. LTD. (Company Registration Number: 201613589E) (Incorporated in the Republic of Singapore)
CIRCULAR DATED 14 NOVEMBER 2019 THIS CIRCULAR IS IMPORTANT AND REQUIRES YOUR IMMEDIATE ATTENTION. PLEASE READ IT CAREFULLY. This Circular is issued by AsiaMedic Limited (the “Company”). If you are in any doubt about its contents or the action you should take, you should consult your legal, financial, tax or other professional adviser(s) immediately. The Company intends to list the securities which are the subject of the rights issue in this Circular and the acceptance of applications will be conditional upon the issue of securities and the receipt of the Singapore Exchange Securities Trading Limited’s (the “SGX-ST”) listing and quotation notice. Companies listed on Catalist may carry higher investment risk when compared with larger or more established companies listed on the Main Board of the SGX-ST. In particular, companies may list on Catalist without a track record of profitability and there is no assurance that there will be a liquid market in the shares or units of shares traded on Catalist. You should be aware of the risk of investing in such companies and should make the decision to invest only after careful consideration and, if appropriate, consultation with your professional adviser(s). If you have sold or transferred all your ordinary shares in the capital of the Company held through The Central Depository (Pte) Limited (“CDP”), you need not forward this Circular with the Notice of Extraordinary General Meeting and the accompanying Proxy Form to the purchaser or transferee as arrangements will be made by CDP for a separate Circular with the Notice of Extraordinary General Meeting and the accompanying Proxy Form to be sent to the purchaser or transferee. -

The Golden Bugle the Golden Bugle
TheThe Golden Golden Bugle Bugle ● Issue● Issue 3 ● Spring/Summer1 ● August 2020 Quarter 2021 In This Issue Greetings! Advice From The Editor I hope all is well with you and your families. As we are now in Cadet Deputy Commander the final quarter of the school year, I wanted to take a moment to reflect and share some advice to everyone. Behavioral Health Interview Brian Thompson, We’ve all done so much in this past year, some of us are still CPS Behavioral Health Manager applying to college, using our voices for social justice, and Surviving Stress & Depression making sure we take care of ourselves and our families from the Counselor Interview pandemic. We may be feeling burned out, ready to call it a day, Kirsten Perry, President but we need to remember that we aren’t done yet. There is a lot Illinois School Counselor Assoc. more work to be done, stages to be crossed, days crossed off, Surviving COVID19 and I know we can all do it. Class of 2021 My advice to you? Remember to take time for yourself, as you Our Senior Staff Members: Their Plans are the one who creates change in your life. Our mental health Financial Aid Administrator Interview is just as important as our future, remember to give yourself a Maureen Amos, Executive Director break, have a drink of water, and breathe in some fresh air. NEIU Financial Aid & Scholarships Spend some time by yourself, with a friend, family member or Financial Aid Tips pet. Don’t feel guilty about taking a break, you are the most important person, and sometimes we all need to recharge. -

Nfts Are Booming and the Music Biz Desperately Wants In
BILLBOARD COUNTRY UPDATE APRIL 13, 2020 | PAGE 4 OF 19 ON THE CHARTS JIM ASKER [email protected] Bulletin SamHunt’s Southside Rules Top Country YOURAlbu DAILYms; BrettENTERTAINMENT Young ‘Catc NEWSh UPDATE’-es Fifth AirplayMARCH 11, 2021 Page 1 of 43 Leader; Travis Denning Makes History INSIDE NFTs Are Booming and the Sam Hunt’s second studio full-length, and first in over five years, Southside sales (up 21%) in the tracking week. On Country Airplay, it hops 18-15 (11.9 mil- (MCA Nashville/Universal Music Group Nashville),Music debuts at No. 1 onBiz Billboard ’sDesperately lion audience impressions, up 16%). Wants In Top Country• Congress Albums Passes chart dated April 18. In its first week (ending April 9), it earned$1.9T 46,000 Relief equivalent Bill: album units, including 16,000 in album sales, ac- TRY TO ‘CATCH’ UP WITH YOUNG Brett Youngachieves his fifth consecutive cordingHere’s to What’s Nielsen in Music/MRC It for Data. andBY totalMICAH Country SINGLETON Airplay No. 1 as “Catch” (Big Machine Label Group) ascends SouthsideMusic marksWorkers Hunt’s second No. 1 on the 2-1, increasing 13% to 36.6 million impressions. chart and• A Seatfourth At top The 10. It follows“It freshman was one ofLP those moments in my life where I was NFT marketplaceYoung’s called first NBA of six Top chart Shot entries, where “Sleep it sells With - Montevallo(Kids), which Table: arrived at thelike, summit ‘Holy in shit,’”No - recalls DJ-producer 3LAU, “‘I think clips of highlightsout You,” and reached accepts No. -

K-Pop – What’S in a Name?
K-pop – What’s in a Name? ACADEMIC ARTICLE: ROUNDTABLE Ed. Dr. Candace Epps-Robertson Assistant Professor of English and Comparative Literature, University of North Carolina at Chapel Hill (United States) Ed. Katie Hulme Physicist by day, (amateur) poet by night (United States) Introduction What is a “Roundtable”? A rhizome consists of a multitude of interconnected nodes — and while those nodes might have more that connects than divides them, individual nodes don’t always agree. Learning means being in conversation with one another. Our perspectives are often shaped by our immediate networks and personal experiences, and it never hurts to take a step back and invite some voices to the table — especially those we might not otherwise hear, and those that bring wisdom, experience, and specialized knowledge into the conversation. “ ” 양극화 세상에서 가장 추한 꽃 “Polarization, the ugliest flower in the world” (Agust D, 2020) We have all witnessed heated and emotionally charged debates ignited by particular topics, fueled by the anonymity and speed afforded by social media. Discussions can quickly become polarized, and when polarization begins to play, discourse often begins to falter. Slowing down, taking time to pause, engaging with the ideas of others, and listening are essential to growth and creating new knowledge. The most famous roundtable is probably that of the legendary King Arthur, who insisted that his knights sit at a roundtable because such a table has no head — thus no designated leader. The purpose of a roundtable is to invite individuals into a space where the notion of “us” and “them” is temporarily dispelled, and each voice is given an equal platform to articulate itself. -
Seolhyun Dating Rumors Were False
Mar 15, · AOA’s Seolhyun Revealed What Dating Was Like When She Was A Rookie Idol – KpopHit March 15, While most idols usually hide their past relationships, AOA ‘s Seolhyun was very open about the fact that she had a boyfriend during her rookie years. Korean media outlet Dispatch recently released breaking news and photos of Block B‘s Zico and AOA‘s Seolhyun allegedly going on secret dates. Shortly after Dispatch released a set of photos featuring Seolhyun sneaking to visit Zico at his home and of the two going on dates together, the two singers’ respective agencies have released official statements regarding their relationship. Seohyun, who has a good girl image, is asked about how she didn't have any dating rumors or scandals throughout the past 12 years. The idol replied, "It was because I really didn't date. Work was. Block B leader Zico and AOA member Seolhyun has been rumored to be dating according to media outlet Dispatch, both of their agencies respond to the dating rumors. The media outlet released photos of Zico and Seolhyun and revealed that they have been dating for . Nam Joo Hyuk and Seolhyun are rumored to be dating - A new post says that they are in the middle of making love relationships because of this. Quite surprising gossip has recently circulated in the Pann online community. A post says that Nam Joo Hyuk and Seolhyun AOA are dating. Netter posts include proof that they are having a love affair. Kim Seolhyun’s Boyfriend. Kim Seolhyun is single. She is not dating anyone currently.