R Papers at Core.Ac.Uk Brought to You by CORE
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

T3 Sandhi Rules of Different Prosodic Hierarchies
T3 Sandhi rules of different prosodic hierarchies Abstract This study conducts acoustic analysis on T3 sandhi of two characters across different boundaries of prosodic hierarchies. The experimental data partly support Chen (2000)’s view about sandhi domain that “T3 sandhi takes place obligatorily within MRU”, and “sandhi rule can not apply cross intonation phrase boundary”. Nonetheless, the results do not support his claim that “there are no intermediate sandhi hierarchies between MRU and intonation phrase”. On the contrary, it is found that, although T3 sandhi could occur across all kinds of hierarchical boundaries between MRU and intonation phrase, T3 sandhi rules within a foot (prosodic word), or between foots without pause, or between pauses without intonation (phonology phrase) are very different in terms of acoustic properties. Furthermore, based on the facts that (1) T3 sandhi could occur cross boundary of pauses and (2) phrase-final sandhi could be significantly lengthening, it is argued that T3 sandhi is due to dissimilation of low tones, rather than duration reduction within MRU domain. It is also demonstrated that tone sandhi and prosodic hierarchies may not be equivalently evaluated in Chinese phonology. Prosodic hierarchies are determined by pause and lengthening, not by tone sandhi. Key words: tone sandhi; prosodic hierarchies; boundary; Mandarin Chinese 1 Introduction So-called T3 sandhi in mandarin Chinese has been widely discussed in Chinese Phonology. Mandarin Chinese has four tones: T1 (level 55), T2 (rising 35), T3 (low-rise 214), T4 (falling 51).Generally, when a T3 is followed by another T3, it turns into T2. The rule could be simply stated as: 214->35/ ___214. -

Long-Distance /R/-Dissimilation in American English
Long-Distance /r/-Dissimilation in American English Nancy Hall August 14, 2009 1 Introduction In many varieties of American English, it is possible to drop one /r/ from cer- tain words that contain two /r/s, such as su(r)prise, pa(r)ticular, gove(r)nor, and co(r)ner. This type of /r/-deletion is done by speakers who are basically ‘rhotic’; that is, who generally do not drop /r/ in any other position. It is a type of dissimi- lation, because it avoids the presence of multiple rhotics within a word.1 This paper has two goals. The first is to expand the description of American /r/-dissimilation by bringing together previously published examples of the process with new examples from an elicitation study and from corpora. This data set reveals new generalizations about the phonological environments that favor dissimilation. The second goal is to contribute to the long-running debate over why and how dissimilation happens, and particularly long-distance dissimilation. There is dis- pute over whether long-distance dissimilation is part of the grammar at all, and whether its functional grounding is a matter of articulatory constraints, processing constraints, or perception. Data from American /r/-dissimilation are especially im- portant for this debate, because the process is active, it is not restricted to only a few morphemes, and it occurs in a living language whose phonetics can be studied. Ar- guments in the literature are more often based on ancient diachronic dissimilation processes, or on processes that apply synchronically only in limited morphological contexts (and hence are likely fossilized remnants of once wider patterns). -

Prosody of Tone Sandhi in Vietnamese Reduplications
Prosody of Tone Sandhi in Vietnamese Reduplications Authors Thu Nguyen Linguistics program E.M.S.A.H. University of Queensland St Lucia, QLD 4072, Australia Email: [email protected] John Ingram Linguistics program E.M.S.A.H. University of Queensland St Lucia, QLD 4072, Australia Email: [email protected] Abstract In this paper we take advantage of the segmental control afforded by full and partial Vietnamese reduplications on a constant carrier phrase to obtain acoustic evidence of assymetrical prominence relations (van der Hulst 2005), in support of a hypothesis that Vietnamese reduplications are phonetically right headed and that tone sandhi is a reduction phenomenon occurring on prosodically weak positions (Shih, 2005). Acoustic parameters of syllable duration (onset, nucleus and coda), F0 range, F0 contour, vowel intensity, spectral tilt and vowel formant structure are analyzed to determine: (1) which syllable of the two (base or reduplicant) is more prominent and (2) how the tone sandhi forms differ from their full reduplicated counterparts. Comparisons of full and partial reduplicant syllables in tone sandhi forms provide additional support for this analysis. Key words: tone sandhi, prosody, stress, reduplication, Vietnamese, acoustic analysis ____________________________ We would like to thank our subjects for offering their voices for the analysis, Dr. Nguyen Hong Nguyen for statistical advice and the anonymous reviewers for their valuable comments and suggestions. The Postdoctoral research fellowship granted to the first author by the University of Queensland is acknowledged. Prosody of tone sandhi in Vietnamese reduplications 2 1. Introduction Vietnamese is a contour tone language, which is strongly syllabic in its phonological organization and morphology. -
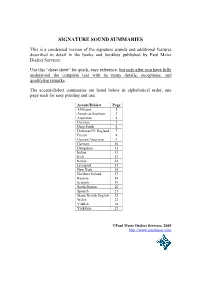
Signature Sound Summaries
SIGNATURE SOUND SUMMARIES This is a condensed version of the signature sounds and additional features described in detail in the books and booklets published by Paul Meier Dialect Services. Use this “cheat sheet” for quick, easy reference, but only after you have fully understood the complete text with its many details, exceptions, and qualifying remarks. The accent/dialect summaries are listed below in alphabetical order, one page each for easy printing and use. Accent/Dialect Page Afrikaans 2 American Southern 3 Australian 4 Cockney 5 Deep South 6 Downeast N. England 7 French 8 General American 9 German 10 Hampshire 11 Indian 12 Irish 13 Italian 14 Liverpool 15 New York 16 Northern Ireland 17 Russian 18 Scottish 19 South Boston 20 Spanish 21 Stand. British English 22 Welsh 23 Yiddish 24 Yorkshire 25 ©Paul Meier Dialect Services, 2009 http://www.paulmeier.com SIGNATURE SOUND SUMMARIES AFRIKAANS SIGNATURE SOUNDS 1. kit [ə] sometimes [i] if [p, t, or k] follows 2. dress [e or ɪ] 3. trap [ɛ] 4. lot/cloth [ɒ̹] 5. foot [u] 6. bath [ɑ̹] 7. non-rhotic; /r/ following vowel is silent 8. nurse [ɞ] 9. face [aɪ] 10. thought [ɔ]̹ 11. goat [ɐɘ] 12. goose [ʉ]; [j] used before the vowel following alveolar consonants 13. /h/ elided 14. pre-vocalic /r/ [ɾ or r] 15. voiced /th/ [d̪]; unvoiced /th/ [f] ADDITIONAL FEATURES a. no aspiration for [p, t, k], esp. initially in word or syllable b. final voiced obstruents devoiced c. unstressed /-et/, /-ed/ endings [ət, əd], e.g. pocketed [ˈpɒ̹kətəd] d. pure vowel, not schwa in initial unstressed syllables. -

Is Phonological Consonant Epenthesis Possible? a Series of Artificial Grammar Learning Experiments
Is Phonological Consonant Epenthesis Possible? A Series of Artificial Grammar Learning Experiments Rebecca L. Morley Abstract Consonant epenthesis is typically assumed to be part of the basic repertoire of phonological gram- mars. This implies that there exists some set of linguistic data that entails epenthesis as the best analy- sis. However, a series of artificial grammar learning experiments found no evidence that learners ever selected an epenthesis analysis. Instead, phonetic and morphological biases were revealed, along with individual variation in how learners generalized and regularized their input. These results, in combi- nation with previous work, suggest that synchronic consonant epenthesis may only emerge very rarely, from a gradual accumulation of changes over time. It is argued that the theoretical status of epenthesis must be reconsidered in light of these results, and that investigation of the sufficient learning conditions, and the diachronic developments necessary to produce those conditions, are of central importance to synchronic theory generally. 1 Introduction Epenthesis is defined as insertion of a segment that has no correspondent in the relevant lexical, or un- derlying, form. There are various types of epenthesis that can be defined in terms of either the insertion environment, the features of the epenthesized segment, or both. The focus of this paper is on consonant epenthesis and, more specifically, default consonant epenthesis that results in markedness reduction (e.g. Prince and Smolensky (1993/2004)). Consonant -

Hearing R-Sandhi: the Role of Past Experience Jennifer Hay Katie Drager Andy Gibson
HEARING R-SANDHI: THE ROLE OF PAST EXPERIENCE JENNIFER HAY KATIE DRAGER ANDY GIBSON University of Canterbury University of Hawai‘i University of Canterbury at Mānoa This article reports on patterns in the production and perception of New Zealand English r-san - dhi. We report on two phoneme-monitoring experiments that examine whether listeners from three regions are sensitive to the distribution of r- presence in linking and intrusive environments. The results provide evidence that sound perception is affected by a listener’s experience-driven expec - tations: greater prior experience with a sound in a given context increases the likelihood of per - ceiving the sound in that context, regardless of whether the sound is present in the stimulus. For listeners with extremely limited prior exposure to a variant, the variant is especially salient and we also observe an experiment-internal effect of experience. We argue that our results support models that incorporate both word-specific and abstract probabilistic representations.* Keywords : salience, listener expectations, r-sandhi, sociophonetics, phoneme monitoring, speech perception, rhoticity 1. Introduction . Speech perception involves the extraction of words and sounds from a continuous speech signal. This normally occurs with little difficulty for the lis - tener, despite a great deal of variability in the acoustic properties of sounds. Listeners’ perception is informed by a large amount of information, including phonological con - text (Mann & Repp 1981), prior exposure in lexically relevant contexts (Norris et al. 2003, Maye et al. 2008), the lexical status of the word (Magnuson et al. 2003), the speaker who produced the sound (Kraljic & Samuel 2005, 2007), social characteristics attributed to the speaker (Strand & Johnson 1996, Hay et al. -

The American Intrusive L
THE AMERICAN INTRUSIVE L BRYAN GICK University of British Columbia The well-known sandhi phenomenon known as intrusive r has been one of the longest-standing problems in English phonology. Recent work has brought to light a uniquely American contribution to this discussion: the intrusive l (as in draw[l]ing for drawing and bra[l] is for bra is in southern Pennsylvania, compared to draw[r]ing and bra[r] is, respectively, in British Received Pronunciation [RP]). In both instances of intrusion, a historically unattested liquid consonant (r or l) intervenes in the hiatus between a morpheme-final nonhigh vowel and a following vowel, either across or within words. Not surprisingly, this process interacts crucially with the well- known cases of /r/-vocalization (e.g., Kurath and McDavid 1961; Labov 1966; Labov, Yaeger, and Steiner 1972; Fowler 1986) and /l/-vocalization (e.g., Ash 1982a, 1982b), which have been identified as important markers of sociolinguistic stratification in New York City, Philadelphia, and else- where. However, previous discussion of the intrusive l (Gick 1999) has focused primarily on its phonological implications, with almost no attempt to describe its geographic, dialectal, and sociolinguistic context. This study marks such an attempt. In particular, it argues that the intrusive l is an instance of phonological change in progress. Descriptively, the intrusive l parallels the intrusive r in many respects. Intrusive r may be viewed simplistically as the extension by analogy of a historically attested final /r/ to words historically ending in a vowel (gener- ally this applies only to the set of non-glide-final vowels: /@, a, O/). -

Between-Word Junctures in Early Multi-Word Speech
This is a repository copy of Between-word junctures in early multi-word speech. White Rose Research Online URL for this paper: http://eprints.whiterose.ac.uk/1571/ Article: Newton, C. and Wells, B. (2002) Between-word junctures in early multi-word speech. Journal of Child Language, 29 (2). pp. 275-299. ISSN 0305-0009 https://doi.org/10.1017/S0305000902005044 Reuse Unless indicated otherwise, fulltext items are protected by copyright with all rights reserved. The copyright exception in section 29 of the Copyright, Designs and Patents Act 1988 allows the making of a single copy solely for the purpose of non-commercial research or private study within the limits of fair dealing. The publisher or other rights-holder may allow further reproduction and re-use of this version - refer to the White Rose Research Online record for this item. Where records identify the publisher as the copyright holder, users can verify any specific terms of use on the publisher’s website. Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ J. Child Lang. (), –. # Cambridge University Press DOI: .\S Printed in the United Kingdom Between-word junctures in early multi-word speech* CAROLINE NEWTON Department of Human Communication Science, University College London, UK BILL WELLS Department of Human Communication Sciences, University of Sheffield, UK (Received February . Revised April ) Most children aged ; to ; begin to use utterances of two words or more. -

Morphophonology of Magahi
International Journal of Science and Research (IJSR) ISSN: 2319-7064 SJIF (2019): 7.583 Morphophonology of Magahi Saloni Priya Jawaharlal Nehru University, SLL & CS, New Delhi, India Salonipriya17[at]gmail.com Abstract: Every languages has different types of word formation processes and each and every segment of morphology has a sound. The following paper is concerned with the sound changes or phonemic changes that occur during the word formation process in Magahi. Magahi is an Indo- Aryan Language spoken in eastern parts of Bihar and also in some parts of Jharkhand and West Bengal. The term Morphophonology refers to the interaction of word formation with the sound systems of a language. The paper finds out the phonetic rules interacting with the morphology of lexicons of Magahi. The observations shows that he most frequent morphophonological process are Sandhi, assimilation, Metathesis and Epenthesis. Whereas, the process of Dissimilation, Lenition and Fortition are very Uncommon in nature. Keywords: Morphology, Phonology, Sound Changes, Word formation process, Magahi, Words, Vowels, Consonants 1. Introduction 3.1 The Sources of Magahi Glossary Morphophonology refers to the interaction between Magahi has three kind of vocabulary sources; morphological and phonological or its phonetic processes. i) In the first category, it has those lexemes which has The aim of this paper is to give a detailed account on the been processed or influenced by Sanskrit, Prakrit, sound changes that take place in morphemes, when they Apbhransh, ect. Like, combine to form new words in the language. धमम> ध륍म> धरम, स셍म> सꥍ셍> सााँ셍 ii) In the second category, it has those words which are 2. -

From "RP" to "Estuary English"
From "RP" to "Estuary English": The concept 'received' and the debate about British pronunciation standards Hamburg 1998 Author: Gudrun Parsons Beckstrasse 8 D-20357 Hamburg e-mail: [email protected] Table of Contents Foreword .................................................................................................i List of Abbreviations............................................................................... ii 0. Introduction ....................................................................................1 1. Received Pronunciation .................................................................5 1.1. The History of 'RP' ..................................................................5 1.2. The History of RP....................................................................9 1.3. Descriptions of RP ...............................................................14 1.4. Summary...............................................................................17 2. Change and Variation in RP.............................................................18 2.1. The Vowel System ................................................................18 2.1.1. Diphthongisation of Long Vowels ..................................18 2.1.2. Fronting of /!/ and Lowering of /"/................................21 2.2. The Consonant System ........................................................23 2.2.1. The Glottal Stop.............................................................23 2.2.2. Vocalisation of [#]...........................................................26 -

Word-Level Distributions and Structural Factors Codetermine GOOSE Fronting
Word-level distributions and structural factors codetermine GOOSE fronting Márton Sóskuthy1, Paul Foulkes1, Bill Haddican2, Jen Hay3, Vincent Hughes1 1University of York, 2CUNY – Queens College, 3NZILBB – University of Canterbury {marton.soskuthy|paul.foulkes|vincent.hughes}@york.ac.uk, [email protected], [email protected] ABSTRACT examples of GOOSE in these classes derive historically from different monophthongs and We analyse dynamic formant data from a corpus of diphthongs, mainly Middle English /oː/, /iu/ and /ɛu/. Derby English spanning three generations, focusing GOOSE words containing /j/ are subject to variation on the relationship between yod-dropping and in most dialects of present-day English. The /j/ may GOOSE (/uː/)-fronting. Derby English exhibits a undergo a process of ‘coalescence’ with adjacent stable but variable pattern of yod-dropping in post- consonants (thus issue may be /ɪsjuː/ or /ɪʃuː/), or coronal position (e.g. new [njuː]~[nuː]), and an deletion. The latter process is often referred to as ongoing process of /uː/-fronting. The degree of /uː/- yod-dropping (i.e. new may be /njuː/ or /nuː/). fronting is highest in words which categorically Deletion varies markedly across dialects, include yod (e.g. cube) and lower in words which particularly in stressed positions [20]. Historical /j/ never show a yod (e.g. noodle). Words with variable was lost earliest after palatals, /r/ and /l/ (chew, rude, yod-dropping exhibit intermediate degrees of blue), and is now almost universally absent in these fronting. The degree of fronting in variable words is contexts [20]. Most contemporary British and North partly determined by how frequent the lexical item American dialects show variation according to is: frequent words undergo more fronting than preceding context. -

Analogy in the Emergence of Intrusive-R in English MÁRTON SÓSKUTHY University of Edinburgh 2
Analogy in the emergence of intrusive-r in English MÁRTON SÓSKUTHY University of Edinburgh 2 ABSTRACT This paper presents a novel approach to the phenomenon of intrusive-r in English based on analogy. The main claim of the paper is that intrusive-r in non-rhotic ac- cents of English is the result of the analogical extension of the r∼zero alternation shown by words such as far, more and dear. While this idea has been around for a long time, this is the first paper that explores this type of analysis in detail. More specifically, I provide an overview of the developments that led to the emergence of intrusive-r and show that they are fully compatible with an analogical approach. This includes the analysis of frequency data taken from an 18th century corpus of English compiled specifically for the purposes of this paper and the discussion of a related development, namely intrusive-l. To sharpen the predictions of the analog- ical approach, I also provide a mathematically explicit definition of analogy and run a computer simulation of the emergence of the phenomenon based on a one million word extract from the 18th century corpus mentioned above. The results of the simulation confirm the predictions of the analogical approach. A further advantage of the analysis presented here is that it can account for the historical development and synchronic variability of intrusive-r in a unified framework. 3 1 INTRODUCTION The phenomenon of intrusive-r in various accents of English has inspired a large number of generative analyses and is surrounded by considerable controversy, mainly because of the theoretical challenges that it poses to Optimality The- ory and markedness-based approaches to phonology (e.g.