Central Processing Unit (CPU)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
The Instruction Set Architecture
Quiz 0 Lecture 2: The Instruction Set Architecture COS / ELE 375 Computer Architecture and Organization Princeton University Fall 2015 Prof. David August 1 2 Quiz 0 CD 3 Miles of Music 3 4 Pits and Lands Interpretation 0 1 1 1 0 1 0 1 As Music: 011101012 = 117/256 position of speaker As Number: Transition represents a bit state (1/on/red/female/heads) 01110101 = 1 + 4 + 16 + 32 + 64 = 117 = 75 No change represents other state (0/off/white/male/tails) 2 10 16 (Get comfortable with base 2, 8, 10, and 16.) As Text: th 011101012 = 117 character in the ASCII codes = “u” 5 6 Interpretation – ASCII Princeton Computer Science Building West Wall 7 8 Interpretation Binary Code and Data (Hello World!) • Programs consist of Code and Data • Code and Data are Encoded in Bits IA-64 Binary (objdump) As Music: 011101012 = 117/256 position of speaker As Number: 011101012 = 1 + 4 + 16 + 32 + 64 = 11710 = 7516 As Text: th 011101012 = 117 character in the ASCII codes = “u” CAN ALSO BE INTERPRETED AS MACHINE INSTRUCTION! 9 Interfaces in Computer Systems Instructions Sequential Circuit!! Software: Produce Bits Instructing Machine to Manipulate State or Produce I/O Computers process information State Applications • Input/Output (I/O) Operating System • State (memory) • Computation (processor) Compiler Firmware Instruction Set Architecture Input Output Instruction Set Processor I/O System Datapath & Control Computation Digital Design Circuit Design • Instructions instruct processor to manipulate state Layout • Instructions instruct processor to produce I/O in the same way Hardware: Read and Obey Instruction Bits 12 State State – Main Memory Typical modern machine has this architectural state: Main Memory (AKA: RAM – Random Access Memory) 1. -

Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and Power
Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and power ITSC 3181 Introduction to Computer Architecture https://passlaB.githuB.io/ITSC3181/ Department of Computer Science Yonghong Yan [email protected] https://passlab.github.io/yanyh/ Lectures for Chapter 1 and C Basics Computer Abstractions and Technology • Lecture 01: Chapter 1 – 1.1 – 1.4: Introduction, great ideas, Moore’s law, aBstraction, computer components, and program execution • Lecture 02: C Basics; Memory and Binary Systems • Lecture 03: Number System, Compilation, Assembly, Linking and Program Execution ☛• Lecture 04: Chapter 1 – 1.6 – 1.7: Performance, power and technology trends • Lecture 05: – 1.8 - 1.9: Multiprocessing and Benchmarking 2 § 1.6 Performance 1.6 Defining Performance • Which airplane has the best performance? Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 100 200 300 400 500 0 2000 4000 6000 8000 10000 Passenger Capacity Cruising Range (miles) Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 500 1000 1500 0 100000 200000 300000 400000 Cruising Speed (mph) Passengers x mph 3 Response Time and Throughput • Response time çè Latency – How long it takes to do a task • Throughput çè Bandwidth – Total work done per unit time • e.g., tasks/transactions/… per hour • How are response time and throughput affected by – Replacing the processor with a faster version? – Adding more processors? • We’ll focus on response time for now… 4 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y”, i.e. -

Simple Computer Example Register Structure
Simple Computer Example Register Structure Read pp. 27-85 Simple Computer • To illustrate how a computer operates, let us look at the design of a very simple computer • Specifications 1. Memory words are 16 bits in length 2. 2 12 = 4 K words of memory 3. Memory can be accessed in one clock cycle 4. Single Accumulator for ALU (AC) 5. Registers are fully connected Simple Computer Continued 4K x 16 Memory MAR 12 MDR 16 X PC 12 ALU IR 16 AC Simple Computer Specifications (continued) 6. Control signals • INCPC – causes PC to increment on clock edge - [PC] +1 PC •ACin - causes output of ALU to be stored in AC • GMDR2X – get memory data register to X - [MDR] X • Read (Write) – Read (Write) contents of memory location whose address is in MAR To implement instructions, control unit must break down the instruction into a series of register transfers (just like a complier must break down C program into a series of machine level instructions) Simple Computer (continued) • Typical microinstruction for reading memory State Register Transfer Control Line(s) Next State 1 [[MAR]] MDR Read 2 • Timing State 1 State 2 During State 1, Read set by control unit CLK - Data is read from memory - MDR changes at the Read beginning of State 2 - Read is completed in one clock cycle MDR Simple Computer (continued) • Study: how to write the microinstructions to implement 3 instructions • ADD address • ADD (address) • JMP address ADD address: add using direct addressing 0000 address [AC] + [address] AC ADD (address): add using indirect addressing 0001 address [AC] + [[address]] AC JMP address 0010 address address PC Instruction Format for Simple Computer IR OP 4 AD 12 AD = address - Two phases to implement instructions: 1. -

The Central Processing Unit(CPU). the Brain of Any Computer System Is the CPU
Computer Fundamentals 1'stage Lec. (8 ) College of Computer Technology Dept.Information Networks The central processing unit(CPU). The brain of any computer system is the CPU. It controls the functioning of the other units and process the data. The CPU is sometimes called the processor, or in the personal computer field called “microprocessor”. It is a single integrated circuit that contains all the electronics needed to execute a program. The processor calculates (add, multiplies and so on), performs logical operations (compares numbers and make decisions), and controls the transfer of data among devices. The processor acts as the controller of all actions or services provided by the system. Processor actions are synchronized to its clock input. A clock signal consists of clock cycles. The time to complete a clock cycle is called the clock period. Normally, we use the clock frequency, which is the inverse of the clock period, to specify the clock. The clock frequency is measured in Hertz, which represents one cycle/second. Hertz is abbreviated as Hz. Usually, we use mega Hertz (MHz) and giga Hertz (GHz) as in 1.8 GHz Pentium. The processor can be thought of as executing the following cycle forever: 1. Fetch an instruction from the memory, 2. Decode the instruction (i.e., determine the instruction type), 3. Execute the instruction (i.e., perform the action specified by the instruction). Execution of an instruction involves fetching any required operands, performing the specified operation, and writing the results back. This process is often referred to as the fetch- execute cycle, or simply the execution cycle. -

Computer Organization and Architecture Designing for Performance Ninth Edition
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION William Stallings Boston Columbus Indianapolis New York San Francisco Upper Saddle River Amsterdam Cape Town Dubai London Madrid Milan Munich Paris Montréal Toronto Delhi Mexico City São Paulo Sydney Hong Kong Seoul Singapore Taipei Tokyo Editorial Director: Marcia Horton Designer: Bruce Kenselaar Executive Editor: Tracy Dunkelberger Manager, Visual Research: Karen Sanatar Associate Editor: Carole Snyder Manager, Rights and Permissions: Mike Joyce Director of Marketing: Patrice Jones Text Permission Coordinator: Jen Roach Marketing Manager: Yez Alayan Cover Art: Charles Bowman/Robert Harding Marketing Coordinator: Kathryn Ferranti Lead Media Project Manager: Daniel Sandin Marketing Assistant: Emma Snider Full-Service Project Management: Shiny Rajesh/ Director of Production: Vince O’Brien Integra Software Services Pvt. Ltd. Managing Editor: Jeff Holcomb Composition: Integra Software Services Pvt. Ltd. Production Project Manager: Kayla Smith-Tarbox Printer/Binder: Edward Brothers Production Editor: Pat Brown Cover Printer: Lehigh-Phoenix Color/Hagerstown Manufacturing Buyer: Pat Brown Text Font: Times Ten-Roman Creative Director: Jayne Conte Credits: Figure 2.14: reprinted with permission from The Computer Language Company, Inc. Figure 17.10: Buyya, Rajkumar, High-Performance Cluster Computing: Architectures and Systems, Vol I, 1st edition, ©1999. Reprinted and Electronically reproduced by permission of Pearson Education, Inc. Upper Saddle River, New Jersey, Figure 17.11: Reprinted with permission from Ethernet Alliance. Credits and acknowledgments borrowed from other sources and reproduced, with permission, in this textbook appear on the appropriate page within text. Copyright © 2013, 2010, 2006 by Pearson Education, Inc., publishing as Prentice Hall. All rights reserved. Manufactured in the United States of America. -

The Microarchitecture of a Low Power Register File
The Microarchitecture of a Low Power Register File Nam Sung Kim and Trevor Mudge Advanced Computer Architecture Lab The University of Michigan 1301 Beal Ave., Ann Arbor, MI 48109-2122 {kimns, tnm}@eecs.umich.edu ABSTRACT Alpha 21464, the 512-entry 16-read and 8-write (16-r/8-w) ports register file consumed more power and was larger than The access time, energy and area of the register file are often the 64 KB primary caches. To reduce the cycle time impact, it critical to overall performance in wide-issue microprocessors, was implemented as two 8-r/8-w split register files [9], see because these terms grow superlinearly with the number of read Figure 1. Figure 1-(a) shows the 16-r/8-w file implemented and write ports that are required to support wide-issue. This paper directly as a monolithic structure. Figure 1-(b) shows it presents two techniques to reduce the number of ports of a register implemented as the two 8-r/8-w register files. The monolithic file intended for a wide-issue microprocessor without hardly any register file design is slow because each memory cell in the impact on IPC. Our results show that it is possible to replace a register file has to drive a large number of bit-lines. In register file with 16 read and 8 write ports, intended for an eight- contrast, the split register file is fast, but duplicates the issue processor, with a register file with just 8 read and 8 write contents of the register file in two memory arrays, resulting in ports so that the impact on IPC is a few percent. -

PIC Family Microcontroller Lesson 02
Chapter 13 PIC Family Microcontroller Lesson 02 Architecture of PIC 16F877 Internal hardware for the operations in a PIC family MCU direct Internal ID, control, sequencing and reset circuits address 7 14-bit Instruction register 8 MUX program File bus Select 8 Register 14 8 8 W Register (Accumulator) ADDR Status Register MUX Flash Z, C and DC 9 Memory Data Internal EEPROM RAM 13 Peripherals 256 Byte Program Registers counter Ports data 368 Byte 13 bus 2011 Microcontrollers-... 2nd Ed. Raj KamalA to E 3 8-level stack (13-bit) Pearson Education 8 ALU Features • Supports 8-bit operations • Internal data bus is of 8-bits 2011 Microcontrollers-... 2nd Ed. Raj Kamal 4 Pearson Education ALU Features • ALU operations between the Working (W) register (accumulator) and register (or internal RAM) from a register-file • ALU operations can also be between the W and 8-bits operand from instruction register (IR) • The operations also use three flags Z, C and DC/borrow. [Zero flag, Carry flag and digit (nibble) carry flag] 2011 Microcontrollers-... 2nd Ed. Raj Kamal 5 Pearson Education ALU features • The destination of result from ALU operations can be either W or register (f) in file • The flags save at status register (STATUS) • PIC CPU is a one-address machine (one operand specified in the instruction for ALU) 2011 Microcontrollers-... 2nd Ed. Raj Kamal 6 Pearson Education ALU features • Two operands are used in an arithmetic or logic operations • One is source operand from one a register file/RAM (or operand from instruction) and another is W-register • Advantage—ALU directly operates on a register or memory similar to 8086 CPU 2011 Microcontrollers-.. -

The Intel Microprocessors: Architecture, Programming and Interfacing Introduction to the Microprocessor and Computer
Microprocessors (0630371) Fall 2010/2011 – Lecture Notes # 1 The Intel Microprocessors: Architecture, Programming and Interfacing Introduction to the Microprocessor and computer Outline of the Lecture Evolution of programming languages. Microcomputer Architecture. Instruction Execution Cycle. Evolution of programming languages: Machine language - the programmer had to remember the machine codes for various operations, and had to remember the locations of the data in the main memory like: 0101 0011 0111… Assembly Language - an instruction is an easy –to- remember form called a mnemonic code . Example: Assembly Language Machine Language Load 100100 ADD 100101 SUB 100011 We need a program called an assembler that translates the assembly language instructions into machine language. High-level languages Fortran, Cobol, Pascal, C++, C# and java. We need a compiler to translate instructions written in high-level languages into machine code. Microprocessor-based system (Micro computer) Architecture Data Bus, I/O bus Memory Storage I/O I/O Registers Unit Device Device Central Processing Unit #1 #2 (CPU ) ALU CU Clock Control Unit Address Bus The figure shows the main components of a microprocessor-based system: CPU- Central Processing Unit , where calculations and logic operations are done. CPU contains registers , a high-frequency clock , a control unit ( CU ) and an arithmetic logic unit ( ALU ). o Clock : synchronizes the internal operations of the CPU with other system components using clock pulsing at a constant rate (the basic unit of time for machine instructions is a machine cycle or clock cycle) One cycle A machine instruction requires at least one clock cycle some instruction require 50 clocks. o Control Unit (CU) - generate the needed control signals to coordinate the sequencing of steps involved in executing machine instructions: (fetches data and instructions and decodes addresses for the ALU). -

1.1.2. Register File
國 立 交 通 大 學 資訊科學與工程研究所 碩 士 論 文 同步多執行緒架構中可彈性切割與可延展的暫存 器檔案設計之研究 Design of a Flexibly Splittable and Stretchable Register File for SMT Architectures 研 究 生:鐘立傑 指導教授:單智君 教授 中 華 民 國 九 十 六 年 八 月 I II III IV 同步多執行緒架構中可彈性切割與可延展的暫存 器檔案設計之研究 學生:鐘立傑 指導教授:單智君 博士 國立交通大學資訊科學與工程研究所 碩士班 摘 要 如何利用最少的硬體資源來支援同步多執行緒是一個很重要的研究議題,暫存 器檔案(Register file)在微處理器晶片面積中佔有顯著的比例。而且為了支援同步多 執行緒,每一個執行緒享有自己的一份暫存器檔案,這樣的設計會增加晶片的面積。 在本篇論文中,我們提出了一份可彈性切割與可延展的暫存器檔案設計,在這 個設計裡:1.我們可以在需要的時候彈性切割一份暫存器檔案給兩個執行緒來同時 使用,2.適當的延伸暫存器檔案的大小來增加兩個執行緒共用的機會。 藉由我們設計可以得到的益處有:1.增加硬體資源的使用率,2. 減少對於記憶 體的存取以及 3.提升系統的效能。此外我們設計概念可以任意的滿足不同的應用程 式的需求。 V Design of a Flexibly Splittable and Stretchable Register File for SMT Architectures Student:Li-Jie Jhing Advisor:Dr, Jean Jyh-Jiun Shann Institute of Computer Science and Engineering National Chiao-Tung University Abstract How to support simultaneous multithreading (SMT) with minimum resource hence becomes a critical research issue. The register file in a microprocessor typically occupies a significant portion of the chip area, and in order to support SMT, each thread will have a copy of register file. That will increase the area overhead. In this thesis, we propose a register file design techniques that can 1. Split a copy of physical register file flexibly into two independent register sets when required, simultaneously operable for two independent threads. 2. Stretch the size of the physical register file arbitrarily, to increase probability of sharing by two threads. Benefits of these designs are: 1. Increased hardware resource utilization. 2. Reduced memory -

Soft Machines Targets Ipcbottleneck
SOFT MACHINES TARGETS IPC BOTTLENECK New CPU Approach Boosts Performance Using Virtual Cores By Linley Gwennap (October 27, 2014) ................................................................................................................... Coming out of stealth mode at last week’s Linley Pro- president/CTO Mohammad Abdallah. Investors include cessor Conference, Soft Machines disclosed a new CPU AMD, GlobalFoundries, and Samsung as well as govern- technology that greatly improves performance on single- ment investment funds from Abu Dhabi (Mubdala), Russia threaded applications. The new VISC technology can con- (Rusnano and RVC), and Saudi Arabia (KACST and vert a single software thread into multiple virtual threads, Taqnia). Its board of directors is chaired by Global Foun- which it can then divide across multiple physical cores. dries CEO Sanjay Jha and includes legendary entrepreneur This conversion happens inside the processor hardware Gordon Campbell. and is thus invisible to the application and the software Soft Machines hopes to license the VISC technology developer. Although this capability may seem impossible, to other CPU-design companies, which could add it to Soft Machines has demonstrated its performance advan- their existing CPU cores. Because its fundamental benefit tage using a test chip that implements a VISC design. is better IPC, VISC could aid a range of applications from Without VISC, the only practical way to improve single-thread performance is to increase the parallelism Application (sequential code) (instructions per cycle, or IPC) of the CPU microarchi- Single Thread tecture. Taken to the extreme, this approach results in massive designs such as Intel’s Haswell and IBM’s Power8 OS and Hypervisor that deliver industry-leading performance but waste power Standard ISA and die area. -

Computer Organization & Architecture Eie
COMPUTER ORGANIZATION & ARCHITECTURE EIE 411 Course Lecturer: Engr Banji Adedayo. Reg COREN. The characteristics of different computers vary considerably from category to category. Computers for data processing activities have different features than those with scientific features. Even computers configured within the same application area have variations in design. Computer architecture is the science of integrating those components to achieve a level of functionality and performance. It is logical organization or designs of the hardware that make up the computer system. The internal organization of a digital system is defined by the sequence of micro operations it performs on the data stored in its registers. The internal structure of a MICRO-PROCESSOR is called its architecture and includes the number lay out and functionality of registers, memory cell, decoders, controllers and clocks. HISTORY OF COMPUTER HARDWARE The first use of the word ‘Computer’ was recorded in 1613, referring to a person who carried out calculation or computation. A brief History: Computer as we all know 2day had its beginning with 19th century English Mathematics Professor named Chales Babage. He designed the analytical engine and it was this design that the basic frame work of the computer of today are based on. 1st Generation 1937-1946 The first electronic digital computer was built by Dr John V. Atanasoff & Berry Cliford (ABC). In 1943 an electronic computer named colossus was built for military. 1946 – The first general purpose digital computer- the Electronic Numerical Integrator and computer (ENIAC) was built. This computer weighed 30 tons and had 18,000 vacuum tubes which were used for processing. -
Clock Rate Improves Roughly Proportional to Improvement in L • Number of Transistors Improves Proportional to L2 (Or Faster)
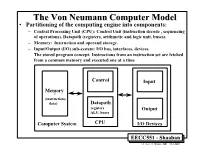
TheThe VonVon NeumannNeumann ComputerComputer ModelModel • Partitioning of the computing engine into components: – Central Processing Unit (CPU): Control Unit (instruction decode , sequencing of operations), Datapath (registers, arithmetic and logic unit, buses). – Memory: Instruction and operand storage. – Input/Output (I/O) sub-system: I/O bus, interfaces, devices. – The stored program concept: Instructions from an instruction set are fetched from a common memory and executed one at a time Control Input Memory - (instructions, data) Datapath registers Output ALU, buses Computer System CPU I/O Devices EECC551 - Shaaban #1 Lec # 1 Winter 2001 12-3-2001 Generic CPU Machine Instruction Execution Steps Instruction Obtain instruction from program storage Fetch Instruction Determine required actions and instruction size Decode Operand Locate and obtain operand data Fetch Execute Compute result value or status Result Deposit results in storage for later use Store Next Determine successor or next instruction Instruction EECC551 - Shaaban #2 Lec # 1 Winter 2001 12-3-2001 HardwareHardware ComponentsComponents ofof AnyAny ComputerComputer Five classic components of all computers: 1. Control Unit; 2. Datapath; 3. Memory; 4. Input; 5. Output } Processor Computer Keyboard, Mouse, etc. Processor Memory Devices (active) (passive) Control Input (where Unit programs, data Disk Datapath live when Output running) Display, Printer, etc. EECC551 - Shaaban #3 Lec # 1 Winter 2001 12-3-2001 CPUCPU OrganizationOrganization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): • (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram).