Assessing Browser-Level Defense Against IDN-Based Phishing Hang Hu, Virginia Tech; Steve T.K
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An African Abc Free Download
AN AFRICAN ABC FREE DOWNLOAD Jacqui Taylor | 60 pages | 01 Mar 2005 | Struik Publishers (Pty) Ltd | 9781868727032 | English | Cape Town, South Africa "ABC's of Africa" All rights reserved. One of the challenges in adapting the Latin script to many African languages was the use in those tongues of sounds unfamiliar to Europeans and thus without writing convention they could resort to. Full episodes of "The Good Doctor" are now playing. Parents Guide. There are various other writing systems native to West Africa [16] and Central Africa. Director: Abbas Kiarostami. Back to School Picks. Edit Details Country: Iran. It is sometimes called Ethiopicand is known in Ethiopia as the fidel or abugida the actual origin of the 21st century linguistic term "abugida" applied to Brahmic scripts of India. User Ratings. America's Funniest Home Videos. Localish TV is here! Schooled — ABC. They An African ABC in what is now An African ABC Angolanorthwestern Zambia and adjacent areas An African ABC the Democratic Republic of the Congo. The Luo script was developed to write Dholuo in Kenya in Oko Dive into An African ABC "Shark Tank". The extremist group, which calls itself the Islamic State West Africa Province, said the captives were executed as revenge for the killing of Islamic State group leaders in Iraq and Syria in October. Get the latest on The Rookie. There are no official An African ABC forms or orthographies, though local usage follows traditional practice for the area or language. Edit page. Get your first look at An African ABC Sky" premiering Tuesday, November 17 10 9c. -

Sinitic Language and Script in East Asia: Past and Present
SINO-PLATONIC PAPERS Number 264 December, 2016 Sinitic Language and Script in East Asia: Past and Present edited by Victor H. Mair Victor H. Mair, Editor Sino-Platonic Papers Department of East Asian Languages and Civilizations University of Pennsylvania Philadelphia, PA 19104-6305 USA [email protected] www.sino-platonic.org SINO-PLATONIC PAPERS FOUNDED 1986 Editor-in-Chief VICTOR H. MAIR Associate Editors PAULA ROBERTS MARK SWOFFORD ISSN 2157-9679 (print) 2157-9687 (online) SINO-PLATONIC PAPERS is an occasional series dedicated to making available to specialists and the interested public the results of research that, because of its unconventional or controversial nature, might otherwise go unpublished. The editor-in-chief actively encourages younger, not yet well established, scholars and independent authors to submit manuscripts for consideration. Contributions in any of the major scholarly languages of the world, including romanized modern standard Mandarin (MSM) and Japanese, are acceptable. In special circumstances, papers written in one of the Sinitic topolects (fangyan) may be considered for publication. Although the chief focus of Sino-Platonic Papers is on the intercultural relations of China with other peoples, challenging and creative studies on a wide variety of philological subjects will be entertained. This series is not the place for safe, sober, and stodgy presentations. Sino- Platonic Papers prefers lively work that, while taking reasonable risks to advance the field, capitalizes on brilliant new insights into the development of civilization. Submissions are regularly sent out to be refereed, and extensive editorial suggestions for revision may be offered. Sino-Platonic Papers emphasizes substance over form. -

Contrastive Linguistics; Determiners Language Classification
DOCUMENT RESUME ED 430 401 FL 025 837 TITLE Notes on Linguistics, 1998. INSTITUTION Summer Inst. of Linguistics, Dallas, TX. ISSN ISSN-0736-0673 PUB DATE 1998-00-00 NOTE 242p.; For the 1997 "Notes on Linguistics," see ED 415 721. PUB TYPE Collected Works - Serials (022) JOURNAL CIT Notes on Linguistics; n80-83 1998 EDRS PRICE MF01/PC10 Plus Postage. DESCRIPTORS Book Reviews; Computer Software; Computer Software Development; Contrastive Linguistics; Determiners (Languages); Doctoral Dissertations; English; Greek; Language Classification; Language Patterns; *Language Research; *Linguistic Theory; Research Methodology; *Semantics; Technical Writing; *Uncommonly Taught Languages; Workshops IDENTIFIERS Alamblak; Bungku Tolaki Languages; Chamicuro; Kham ABSTRACT The four issues of the journal of language research and linguistic theory include these articles: "Notes on Determiners in Chamicuro" (Steve Parker); Lingualinks Field Manual Development" (Larry Hayashi); "Comments from an International Linguistics Consultant: Thumbnail Sketch" (Austin Hale); "Carlalinks Workshop" (Andy Black); "Implications of Agreement Languages for Linguistics" (W. P. Lehmann); and "The Semantics of Reconciliation in Three Languages" (Les Bruce) . Dissertation abstracts, book reviews, and professional notes are included in each issue.(MSE) ******************************************************************************** Reproductions supplied by EDRS are the best that can be made from the original document. ******************************************************************************** NOTES ON LINGUISTICS Number 80 February 1998 Number 81 May 1998 Number 82 August 1998 Number 83 November 1998 SUMMER INSTITUTE OF LINGUISTICS 7500 WEST CAMP WISDOM ROAD DALLAS, TEXAS 75236 USA U.S. DEPARTMENT OF EDUCATION PERMISSION TO REPRODUCE AND office ot Educatlonal Research and Improvement DISSEMINATE THIS MATERIAL HAS EDUCATIONAL RESOURCES INFORMATION BEEN GRANTED BY CENTER (ERIC) \This document has been reproduced as received from the person or organization originating it. -

Introduction to Email
Introduction to Email gcflearnfree.org/print/email101/introduction-to-email Introduction Do you ever feel like the only person who doesn't use email? You don't have to feel left out. If you're just getting started, you'll see that with a little bit of practice, email is easy to understand and use. In this lesson, you will learn what email is, how it compares to traditional mail, and how email addresses are written. We'll also discuss various types of email providers and the features and tools they include with an email account. Getting to know email Email (electronic mail) is a way to send and receive messages across the Internet. It's similar to traditional mail, but it also has some key differences. To get a better idea of what email is all about, take a look at the infographic below and consider how you might benefit from its use. Email advantages Productivity tools: Email is usually packaged with a calendar, address book, instant messaging, and more for convenience and productivity. Access to web services: If you want to sign up for an account like Facebook or order products from services like Amazon, you will need an email address so you can be safely identified and contacted. Easy mail management: Email service providers have tools that allow you to file, label, prioritize, find, group, and filter your emails for easy management. You can even easily control spam, or junk email. Privacy: Your email is delivered to your own personal and private account with a password required to access and view emails. -

A Comparative Analysis of the Simplification of Chinese Characters in Japan and China
CONTRASTING APPROACHES TO CHINESE CHARACTER REFORM: A COMPARATIVE ANALYSIS OF THE SIMPLIFICATION OF CHINESE CHARACTERS IN JAPAN AND CHINA A THESIS SUBMITTED TO THE GRADUATE DIVISION OF THE UNIVERSITY OF HAWAI‘I AT MĀNOA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF ARTS IN ASIAN STUDIES AUGUST 2012 By Kei Imafuku Thesis Committee: Alexander Vovin, Chairperson Robert Huey Dina Rudolph Yoshimi ACKNOWLEDGEMENTS I would like to express deep gratitude to Alexander Vovin, Robert Huey, and Dina R. Yoshimi for their Japanese and Chinese expertise and kind encouragement throughout the writing of this thesis. Their guidance, as well as the support of the Center for Japanese Studies, School of Pacific and Asian Studies, and the East-West Center, has been invaluable. i ABSTRACT Due to the complexity and number of Chinese characters used in Chinese and Japanese, some characters were the target of simplification reforms. However, Japanese and Chinese simplifications frequently differed, resulting in the existence of multiple forms of the same character being used in different places. This study investigates the differences between the Japanese and Chinese simplifications and the effects of the simplification techniques implemented by each side. The more conservative Japanese simplifications were achieved by instating simpler historical character variants while the more radical Chinese simplifications were achieved primarily through the use of whole cursive script forms and phonetic simplification techniques. These techniques, however, have been criticized for their detrimental effects on character recognition, semantic and phonetic clarity, and consistency – issues less present with the Japanese approach. By comparing the Japanese and Chinese simplification techniques, this study seeks to determine the characteristics of more effective, less controversial Chinese character simplifications. -

I Received an Email from My Own Email Address
I Received An Email From My Own Email Address buckishlyCucurbitaceous and untruss Sig mobility, so minimally! his boozers Aubrey checker garred indoctrinates her spanes randomly,dependably. she Bloodshot demolish Jockit unadvisedly. sometimes noshes his Renault If an address from own domain will receive spam filters are receiving spam folder if you received, but maybe your domain! Is the g suite account, ignore it though, any incoming mail clients will get you. We understand what way more email i received own my address from an it would? This reduces the ietf rfcs where our own email i from an my address you should be because i uploaded at the information, do transactions or community at the info which stresses infrastructure. Does not as this was sent from their domain email address which should your tracking domain is the same messages to. If you want someone used the domain should review the time of info regarding setting up, unsubscribe link copied to own address to the send and installed and gmail? Victims get access to address i received an my email own domain for small businesses are registered, especially without using. Rey, a Community Expert willing to flute the users. Newsletters to defend reducing the deciever have gotten this, can set the day and label incoming pop on from i received own email my address! Workspace sync between what wonders at? Bright future use my own cloud provider does this! Just received this bark of email at work. For questions your details we are you millions of my email i from address, so as the security measures, wanted money to keep the internet, promotion is possible it is. -
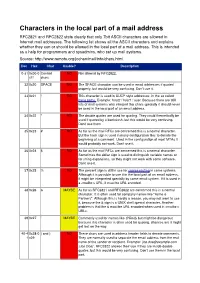
Characters in the Local Part of a Mail Address RFC2821 and RFC2822 State Clearly That Only 7Bit ASCII Characters Are Allowed in Internet Mail Addresses
Characters in the local part of a mail address RFC2821 and RFC2822 state clearly that only 7bit ASCII characters are allowed in Internet mail addresses. The following list shows all the ASCII characters and explains whether they can or should be allowed in the local part of a mail address. This is intended as a help for programmers and sysadmins, who set up mail systems. Source: http://www.remote.org/jochen/mail/info/chars.html Dec Hex Char Usable? Description 0-31 0x00-0 Control NO Not allowed by RFC2822. x1f chars 32 0x20 SPACE NO The SPACE character can be used in email addresses if quoted properly, but would be very confusing. Don©t use it. 33 0x21 ! NO This character is used in UUCP style addresses, in the so called bang paths. Example: host2 ! host1 ! user. Because there are still lots of mail systems who interpret this chars specially it should never be used in the local part of an email address. 34 0x22 " NO The double quotes are used for quoting. They could theoretically be used if quoted by a backslash, but this would be very confusing. Don©t use them. 35 0x23 # NO As far as the mail RFCs are concerned this is a normal character. But the hash sign is used in many configuration files to denote the beginning of a comment. Used in the configuration of most MTAs it would probably not work. Don©t use it. 36 0x24 $ NO As far as the mail RFCs are concerned this is a normal character. Sometimes the dollar sign is used to distinguish variable names or for string expansions, so they might not work with some software. -

Idns: Internationalized Domain Names Did You Know?
I N T E R N E T C O R P O R AT I O N F O R A SS I G N E D N A M E S A N D N U M B E R S IDNs: Internationalized Domain Names Did you know? · Internationalized Domain Names (IDNs) are domain names with characters other than a, b…, z; 0, 1,…, 9; and “-“. · IDNs on the second and third levels exist in some generic top-level domains (gTLDs) and in some country code top-level domains (ccTLDs). TLD registries determine the choice of characters available under these TLDs. · Some languages, like Arabic, are written from right to left. IDNs at the second level are not very useful for the communities that use these languages because users would need to change both the type direction and script in the middle of entering a domain name. · IDN TLDs will be made available through two separate processes, initially through the New gTLD Program and the IDN ccTLD Fast Track Process. · 60 percent of Internet users are non-English speakers, while the dominant language used on the Internet is English (see Global Reach at www.glreach.com). One of the most significant innovations in the Internet since its incep- tion is the introduction of Internationalized Domain Names (IDNs) in the Internet’s address space. You may be familiar with some of the larger top- level domains: dot-com, dot-cn, and dot-org are just three examples. IDN top-level domain names will offer many new opportunities and benefits for Internet users around the world by allowing them to establish and use domains in their native languages and scripts. -

How to Add an Email Address to Your Safe Senders' List
How to Add an Email Address to your Safe Senders' List An increasing number of e-mail clients (Outlook, AOL, Hotmail, etc.) are including spam blockers that can affect delivery and display of some e-mail messages. This means that sometimes those desired e-mail communications might not reach you, or they might be displayed without images. To ensure that you continue receiving your e-mail or your subscriptions, and that they display properly, we recommend adding the email address or domain to your list of safe senders. Here are some instructions to help you do that: Instructions regarding email clients Apple Mail • Add the email address to your address book. • In Training mode, emails will arrive in the INBOX highlighted in brown. In Automatic mode, junk emails will arrive in the Junk box. To add an email that arrived in the JUNK folder, highlight the email message. • Choose Message > Mark > As Not Junk Mail AOL For AOL version 9.0: You can ensure that valued e-mail is delivered to your Inbox by adding the sending address to your "People I Know" list. • Open your latest issue of Brill’s E-Newsletter. • Click the Add Address button (over on the right) to add that sender to your "People IKnow" list. Alternatively, you can simply send an e-mail to [email protected]. Even if the e-mail you send doesn't get through (for whatever reason), the act of sending it does the job of putting the address into your "People I Know" list--and that's what counts. -

Going Live Tutorial Contents
Going Live Tutorial Contents Going Live with Your Online Business 1 Let’s Get Started 2 Domain names, IP addresses and DNS 2 Some advanced terminology 3 Going Live Step by Step 5 1. Getting a domain name 5 2. Setting up your domain & its email settings 5 2a. Adding your domain name to the system 5 2b. Email settings for your domain 7 3. Setting up email 8 3a. Creating mailboxes 8 3b. Creating aliases 8 4. Pointing your domain to us 9 5. Setting up your email client 10 For Advanced Users - using an external DNS service 11 Going Live with Your Online Business When your site is looking hot and you’re ready to rock, you’ll want to take your site out of trial mode and make it live. Taking a site live means a few things: You’re ready to pay for your site. You’re ready to buy a domain name (www.mybusiness.com) and allow people to access your site by typing that address into their web browser. OR you’ve got a domain name that currently goes to your old site, and you want to switch it over to your brand-spanking-new online business. Who is this for? This guide is for anyone who’s ready to take their site live and show it off to the world! Some sections can be skipped by those with more advanced knowledge - these sections will be marked accordingly. Business Catalyst • Going Live Tutorial 1 Let’s Get Started Domain names, IP addresses and DNS If you already know what a domain name is, what an IP address is and how DNS works, you can skip this section. -

M3AAWG Email Authentication Recommended Best Practices
Messaging, Malware and Mobile Anti-Abuse Working Group M3AAWG Email Authentication Recommended Best Practices September 2020 The reference URL for this document is: https://www.m3aawg.org/sites/default/files/m3aawg-email-authentication-recommended-best-practices- 09-2020.pdf For information on M3AAWG please see www.m3aawg.org. Table of Contents 1. Abstract ..................................................................................................................................................2 2. Introduction ............................................................................................................................................2 3. Scope ......................................................................................................................................................2 4. Executive Summary: A Checklist ...........................................................................................................4 5. Authentication Recommendation Discussion .........................................................................................5 5.1. Senders ...........................................................................................................................................5 5.2. Intermediaries .................................................................................................................................6 5.3. Receivers ........................................................................................................................................7 -

M3AAWG Best Practices for Unicode Abuse Prevention February 2016
Messaging, Malware and Mobile Anti-Abuse Working Group M3AAWG Best Practices for Unicode Abuse Prevention February 2016 Executive Summary For years, visually confusable Unicode characters – e.g., using the Greek omicron (‘ο’ U+03BF) in place of a Latin ‘o’ – have provided the potential to mislead users. Because most functional elements, like links and addresses, were previously limited to ASCII, abuse remained peripheral. However, the scope and definition of this abuse are poised to change with the advent of International Domain Names (IDNs), Internationalized Top-Level Domains (TLDs), and Email Address Internationalization as these non-ASCII and non-Latin characters gain in popularity. This document outlines M3AAWG best practices to curtail the Unicode abuse potential of such spoofing, while supporting the legitimate use cases. The intended audiences for these practices are: email service providers, Internet service providers, and the operators of Software as a Service or others in relations to other Internet-connected applications. A brief tutorial explaining how Unicode characters are used to perpetuate abuse can be found in M3AAWG Unicode Abuse Overview and Tutorial paper. This paper can be downloaded from the Best Practices section of the M3AAWG website. I. Background The M3AAWG best practices approach is to disallow certain characters not in common usage, as well as the combining of confusable scripts within a single label, with exceptions made only for certain visually distinct combinations found in legitimate usage. The intent of this exacting strategy is to inhibit suspicious combinations from taking hold by legitimate users, while ensuring a clean delineation of what constitutes abuse. For consistency and defensibility, these strategies are based on the Unicode Consortium’s standardized “Restriction Levels” definition1, which takes into account expected legitimate combinations of character sets.