The Parallel
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Game Developers’ Census, the Big Three at E3, and More
>>PRODUCT REVIEWS PHOTOSHOP CS3 EXTENDED * SPACENAVIGATOR AUGUST 2007 THE LEADING GAME INDUSTRY MAGAZINE >>CASE FOR THE TECH ARTIST >>CODERS MOUTH OFF >>THE INNER PRODUCT HOW AND WHY STUDIOS EXCLUSIVE ROUNDTABLE PAINTING WITH DOMAIN NEED THESE OXYMORONS WITH FIVE PROGRAMMERS SPECIFIC LANGUAGES Using Autodeskodesk® HumanIK® middle-middle- Autodesk® ware, Ubisoftoft MotionBuilder™ grounded ththee software enabled assassin inn his In Assassin’s Creed, th the assassin to 12 centuryy boots Ubisoft used and his run-time-time ® ® fl uidly jump Autodesk 3ds Max environment.nt. software to create from rooftops to a hero character so cobblestone real you can almost streets with ease. feel the coarseness of his tunic. HOW UBISOFT GAVE AN ASSASSIN HIS SOUL. autodesk.com/Games IImmagge cocouru tteesyy of Ubiisofft Autodesk, MotionBuilder, HumanIK and 3ds Max are registered trademarks of Autodesk, Inc., in the USA and/or other countries. All other brand names, product names, or trademarks belong to their respective holders. © 2007 Autodesk, Inc. All rights reserved. []CONTENTS AUGUST 2007 VOLUME 14, NUMBER 7 FEATURES 7 PROGRAMMERS’ ROUNDTABLE In this exclusive roundtable interview, five top technophiles discuss what’s right and wrong with game programming these days, from in-house procedures to multi-processor systems to code reuse. With Brad Bulkley, Stuart Denman, Chris Hecker, Clinton Keith, and Bruce Rogers 17 THE CODE/ART DIVIDE: 7 HOW TECHNICAL ARTISTS BRIDGE THE GAP Game studio Volition (THE PUNISHER, SAINTS ROW) makes a case for hiring a few technical artists, their value 22 ranging from time savings to smoother in-house communication. As linchpins, technical artists keep programmers and artists bonded in their mutual POSTMORTEM cause, helping to ensure that each department gets what it needs from the 22 FINAL FANTASY XII other—and within reason according to The twelfth installment in Square Enix’s wildly popular series was developed the project’s schedule. -

Installing the Klocwork Server Package
Installation and Upgrade Klocwork Insight 10.0 SR6 Document version 1.6 Klocwork Installation and Upgrade Version 10.0 PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Tue, 12 Aug 2014 15:19:51 EST Contents Articles Before you install 1 System requirements 1 Release Notes 11 About the Klocwork packages and components 24 Upgrading from a previous version 26 Upgrading from a previous version 26 Import your existing projects into a new projects root 27 Migrate your projects root directory 31 Installing the Klocwork Server package on Windows -- Upgrade only 36 Installing the Klocwork Server package on Unix -- Upgrade only 37 Installing the Klocwork Server package on Mac -- Upgrade only 40 Get a license 42 Getting a license 42 Installing the Server package 45 Installing Klocwork Insight 45 Installing the Klocwork Server package on Windows 46 Installing the Klocwork Server package on Unix 49 Installing the Klocwork Server package on Mac 52 Viewing and changing Klocwork server settings 54 Downloading and deploying the desktop analysis plug-ins 56 kwupdate 57 Installing a desktop analysis plug-in or command line utility 59 Installing a desktop analysis plug-in 59 Installing the Klocwork plug-in from the Eclipse update site 62 Running a custom installation for new or upgraded IDEs 63 Installing the Distributed Analysis package 64 Installing the Distributed Analysis package 64 Configuring and starting the Klocwork servers 67 Viewing and changing Klocwork server settings 67 -
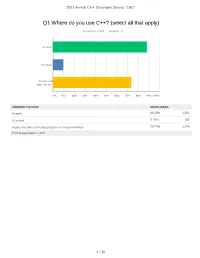
Q1 Where Do You Use C++? (Select All That Apply)
2021 Annual C++ Developer Survey "Lite" Q1 Where do you use C++? (select all that apply) Answered: 1,870 Skipped: 3 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 88.29% 1,651 At school 9.79% 183 In personal time, for hobby projects or to try new things 73.74% 1,379 Total Respondents: 1,870 1 / 35 2021 Annual C++ Developer Survey "Lite" Q2 How many years of programming experience do you have in C++ specifically? Answered: 1,869 Skipped: 4 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 7.60% 142 3-5 years 20.60% 385 6-10 years 20.71% 387 10-20 years 30.02% 561 >20 years 21.08% 394 TOTAL 1,869 2 / 35 2021 Annual C++ Developer Survey "Lite" Q3 How many years of programming experience do you have overall (all languages)? Answered: 1,865 Skipped: 8 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 1.02% 19 3-5 years 12.17% 227 6-10 years 22.68% 423 10-20 years 29.71% 554 >20 years 34.42% 642 TOTAL 1,865 3 / 35 2021 Annual C++ Developer Survey "Lite" Q4 What types of projects do you work on? (select all that apply) Answered: 1,861 Skipped: 12 Gaming (e.g., console and.. -

Visual C++ Team Is at Cppcon 2016 Take the Survey, Attend a Talk, and Drop by Our Booth to Say Hello
Visual C++ Team is at CppCon 2016 Take the survey, attend a talk, and drop by our booth to say hello. Talks by Microsoft (https://blogs.msdn.microsoft.com/vcblog) Tuple: What's New, And How It Works An Introduction to C++ Coroutines C++ Modules: The State of The Union Iterator Haiku (Range-v3) C++ Coroutines: Under the covers The Guideline Support Library: One Year Later Putting Coroutines to Work with C++ for the Latest and greatest from the Visual Studio family Windows Runtime for C++ developers Visual C++ Compiler Toolset (http://aka.ms/cppbuildtools) Improved C++11/14/17 feature support, targeting C++ 11/14 Standards complete in early 2017 Faster builds with improved linking; Free IncrediBuild extension with tools to find bottlenecks New expression optimizer; CFG improvements; Real World Code daily runs for additional reliability Visual Studio Code and the C/C++ Extension (http://aka.ms/cppvscode) Editor: Free, cross-platform, lightweight, keyboard focused Great code-editing experience with code-formatting, auto-completion, go-to-definition, peek definition Powerful debugging with call stack, breakpoints, expression evaluation, conditional breakpoints and more Integration to source-control with Git commands built-in Extensible to easily allow for building, testing, and running external tasks Visual Studio “15” (http://aka.ms/cppvsnext) Minimal C++-only Visual Studio workload installs in minutes through the new setup experience Performance improvements in startup time, project load time, and IntelliSense New predictive IntelliSense mode that provides C++ type matching based on context Enhanced refactoring with rename, extract function, move definition, and change signature Debugger improvements: edit-and-continue, natvis, memory profiler and access violation information Built-in support for CMake – no more round-tripping between your CMakeLists.txt and VS projects Large ecosystem of Visual Studio extensions, e.g. -

Game-Tech-Whitepaper
Type & Color October, 2020 INSIGHTS Game Tech How Technology is Transforming Gaming, Esports and Online Gambling Elena Marcus, Partner Sean Tucker, Partner Jonathan Weibrecht,AGC Partners Partner TableType of& ContentsColor 1 Game Tech Defined & Market Overview 2 Game Development Tools Landscape & Segment Overview 3 Online Gambling & Esports Landscape & Segment Overview 4 Public Comps & Investment Trends 5 Appendix a) Game Tech M&A Activity 2015 to 2020 YTD b) Game Tech Private Placement Activity 2015 to 2020 YTD c) AGC Update AGCAGC Partners Partners 2 ExecutiveType & Color Summary During the COVID-19 pandemic, as people are self-isolating and socially distancing, online and mobile entertainment is booming: gaming, esports, and online gambling . According to Newzoo, the global games market is expected to reach $159B in revenue in 2020, up 9.3% versus 5.3% growth in 2019, a substantial acceleration for a market this large. Mobile gaming continues to grow at an even faster pace and is expected to reach $77B in 2020, up 13.3% YoY . According to Research and Markets, the global online gambling market is expected to grow to $66 billion in 2020, an increase of 13.2% vs. 2019 spurred by the COVID-19 crisis . Esports is projected to generate $974M of revenue globally in 2020 according to Newzoo. This represents an increase of 2.5% vs. 2019. Growth was muted by the cancellation of live events; however, the explosion in online engagement bodes well for the future Tectonic shifts in technology and continued innovation have enabled access to personalized digital content anywhere . Gaming and entertainment technologies has experienced amazing advances in the past few years with billions of dollars invested in virtual and augmented reality, 3D computer graphics, GPU and CPU processing power, and real time immersive experiences Numerous disruptors are shaking up the market . -

Der Turbolader Für Die C++ Entwicklungspipeline 8 X Schnellere Builds
Datenblatt Der Turbolader für die C++ Entwicklungspipeline 8 x schnellere Builds. 80 % kürzere Release-Zyklen. 800 % weniger Frust. Für die Entwicklung und das Testen von Software zuständige Teams haben Schwierigkeiten, die stetig wachsende Abhängigkeit von CPU-intensiven Workloads sowie die damit verbundenen immer längeren Wartezeiten zu handhaben. Teammitglieder verschwenden wertvolle Zeit mit dem Warten auf Code Builds und den Abschluss verschiedener Aufgaben der CI-Pipeline. Das Ergebnis sind häufig ineffiziente Abläufe, hohe F&E-Kosten und eine langsamere Bereitstellung. Vor allem aber haben Entwickler, die viel Zeit mit Warten verbringen, immer weniger Zeit für Testen, Verbesserung und Fehlerbehebung. Incredibuild ist der Turbolader für Kompilierung, Testen und andere rechenintensive Workloads der Software-Entwicklungspipeline. Das wird möglich, indem Prozesse nahtlos und zeitgleich auf inaktive SOFTWARE DEVOPS QA CPUs in Ihrem lokalen Netzwerk oder in der Cloud verteilt werden, ENGINEERS ENGINEERS ENGINEERS während Ihre lokale Umgebung transparent auf entfernten Rechnern emuliert wird. Im Grunde verwandelt unsere Technologie jeden Host in einen Supercomputer mit Hunderten von Kernen und Giga-Bytes an Speicherplatz. Das Endresultat: Erheblich verkürzte Rechenzeiten für nahezu jede Workload unter Nutzung des gleichen Codes sowie GAME FINANCIAL EMBEDDED DEVELOPMENT QUANTITATIVE der gleichen Prozesse und Tools, die Ihr Team derzeit verwendet. ANALYSIS Schnellere Build und Tests mit weniger Infrastruktur ©2020 | Alle Rechte vorbehalten. -

Enlighten Global Illumination Releases Version 3.10
PRESS RELEASE Media Contact [email protected] |+81 (0)3 5488 7070 Enlighten global illumination releases version 3.10 Tokyo, Japan, (Nov. 18, 2019) – Silicon Studio; developer of technology solutions for middleware, gaming, automotive, video production and other digital content; is excited to announce the release of the highly anticipated update to Enlighten global illumination, version 3.10. This release marks a culmination of the first stage of work the Enlighten team has been developing since the acquisition of the technology in 2017. Although there have been a large number of releases of Unreal Engine updates with a number of features introduced, this is the first update to the technology overall. The team believes it is a highly impactful step forward that will benefit custom engine users and Unreal users alike. It should also be noted that this is only the beginning of the team’s efforts with even more features such as ray tracing to come. The emphasis on this update was the usability and accessibility of the technology for users of every aspect, providing more resources to understand the functions and integration as well as strong new features to enhance development capability and results. The released features can be seen below: Enlighten 3.10 SDK ⚫ The prebuilt libraries for VS2017 (15.7 and later) are now provided to access building internally. ⚫ Out-of-core Precompute: limits memory usage when precomputing a massive world. ⚫ Automatic system generation during HLBS precompute to simplify Enlighten integration for SDK users. 1 | (Pipeline library to simplify Enlighten integration for SDK users) (The Enlighten Pipeline library will be released in 3.10 as early access. -

View the Revised S2018 Advance Program
PLAN YOUR EXPERIENCE ADVANCE PROGRAM The 45th International Conference & Exhibition on Computer Graphics and Interactive Techniques TABLE OF CONTENTS SCHEDULE AT A GLANCE ................................................... 3 CURATED CONTENT REASONS TO ATTEND ......................................................... 6 SIGGRAPH 2018 offers several events and sessions that are individually chosen by program chairs to CONFERENCE OVERVIEW ...................................................7 address specific topics in computer graphics and interactive techniques. CONFERENCE SCHEDULE ................................................ 10 Curated content is not selected through the regular APPY HOUR ..........................................................................19 channels of a comprehensive jury. ART GALLERY ......................................................................20 ART PAPERS........................................................................23 INTEREST AREAS SIGGRAPH brings together a wide variety of BUSINESS SYMPOSIUM ...................................................25 professionals who approach computer graphics and COMPUTER ANIMATION FESTIVAL: interactive techniques from different perspectives. ELECTONIC THEATER ........................................................26 Our programs and events align with five broad interest areas (listed below). Use these interest areas to help COMPUTER ANIMATION FESTIVAL: VR THEATER ........ 27 guide you through the content at SIGGRAPH 2018. COURSES .............................................................................28 -

Coverity 2018.09 Command Reference Reference for Coverity Analysis, Coverity Platform, and Coverity Desktop
Coverity 2018.09 Command Reference Reference for Coverity Analysis, Coverity Platform, and Coverity Desktop. Copyright 2018, Synopsys, Inc. All rights reserved worldwide. Table of Contents I. Coverity Analysis Commands ........................................................................................................ 1 cov-analyze .............................................................................................................................. 2 cov-blame .............................................................................................................................. 45 cov-build, cov-build-sbox ......................................................................................................... 50 cov-collect-models .................................................................................................................. 80 cov-commit-defects ................................................................................................................. 82 cov-configure, cov-configure-sbox ........................................................................................... 94 cov-copy-overrun-triage (Deprecated) .................................................................................... 109 cov-count-lines ..................................................................................................................... 111 cov-dotnet-aot ...................................................................................................................... 114 cov-emit .............................................................................................................................. -

Disruption in Platform-Based Ecosystems
This is a repository copy of Disruption in Platform-Based Ecosystems. White Rose Research Online URL for this paper: http://eprints.whiterose.ac.uk/130511/ Version: Accepted Version Article: Ozalp, H orcid.org/0000-0003-4811-6072, Cennamo, C and Gawer, A (2018) Disruption in Platform-Based Ecosystems. Journal of Management Studies, 55 (7). pp. 1203-1241. ISSN 0022-2380 https://doi.org/10.1111/joms.12351 This article is protected by copyright. This is the peer reviewed version of the following article: Ozalp, H, Cennamo, C and Gawer, A (2018) Disruption in Platform-Based Ecosystems. Journal of Management Studies. ISSN 0022-2380, which has been published in final form at https://doi.org/10.1111/joms.12351. This article may be used for non-commercial purposes in accordance with Wiley Terms and Conditions for Use of Self-Archived Versions. Reuse Items deposited in White Rose Research Online are protected by copyright, with all rights reserved unless indicated otherwise. They may be downloaded and/or printed for private study, or other acts as permitted by national copyright laws. The publisher or other rights holders may allow further reproduction and re-use of the full text version. This is indicated by the licence information on the White Rose Research Online record for the item. Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ -

Latest and Greatest in Visual Studio for C++ Developers Steve.Carroll & Daniel.Moth @Microsoft.Com
Latest and Greatest in Visual Studio for C++ developers Steve.Carroll & Daniel.Moth @microsoft.com https://blogs.msdn.microsoft.com/vcblog/ Win an Xbox One S Forza Horizon 3 + Destiny 2 Bundle! Take this survey: https://aka.ms/cppcon Mission of C++ Product Team at Microsoft (DevDiv) Make the lives of all C++ developers on the planet better 1. by participating with the C++ Standards committee 2. by investing in the Microsoft Visual C++ (MSVC) Compiler 3. by improving the Visual Studio IDE 4. by continuing to enhance the C++ extension for Visual Studio Code Visual Studio Code: C/C++ Extension • Lightweight, keyboard focused • Git integration • Code Editing • IntelliSense, Code Browsing, Switch header/source, Code formatting (clang-format) • Debugging • Core-dump debugging, launch, attach, breakpoints (incl. conditional and function), stepping, threads, call stack, watch, GDB and MI commands • Easily run, build, test, and run external tasks https://code.visualstudio.com/docs/languages/cpp AGENDA • Microsoft Visual C++ (MSVC) Compiler and Libraries • Conformance • Compiler Diagnostics • Code Analysis • Code Gen Quality • Build Throughput • Visual Studio 2017 • Faster installation and your disk will thank you • Pain-free upgrade • Just point Visual Studio to your code • Use Visual Studio for all your projects and target platforms • Be more productive than ever MSVC Conformance Two-phase Name Lookup (partial support) under /permissive- default/deleted func, Inline namespaces, User-defined literals, noexcept, char16_t/char32_t, alignas/alignof, -
JUN-JULY- EDUSUP2011.Pdf
houdiniad_education.pdf 1 11-07-12 3:45 PM C M Y CM MY CY CMY K Light a Fire for your Students with Film-Quality VFX Skills Demand for Houdini talent is at an all-time high and top film, broadcast, and gaming production studios are looking for graduates with strong VFX skills and a creative mind-set. Putting Houdini in your school curriculum will give your students the edge they deserve - a deeper understanding of computer graphics and the problem-solving skills essential for the reality of industry production. Schools that teach Houdini’s node-based procedural workflow find that they produce smarter and more efficient visual effects and animation graduates - graduates that studios would love to meet. Visit us at Booth #712 at SIGGRAPH 2011 to learn how your institution can benefit from going procedural with Houdini. www.sidefx.com/education houdiniad_education.pdf 1 11-07-12 3:45 PM Beyond the Basics Faculty and industry combine efforts and resources to deliver novel, nontraditional tools for an advanced educational experience By Courtney E. Howard A basic, or general, education is no longer enough. As those in the industry to provide unique opportunities and the computer graphics industry and its various market invest in future generations of digital artists. segments—from visual effects, animation and its many “We provide computer graphics training aimed at giv- nuances, and game development, to computer-aided de- ing aspiring CG artists the skills and tools they need to C sign, digital art, motion graphics, and more—continue to get straight to work in the VFX and CG industries,” explains evolve, educational facilities are keeping pace through the Dominic Davenport, CEO and founder of Escape Studios.