Beemo, a Monte Carlo Simulation Agent for Playing Parameterized Poker Squares
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Daguerreian Annual 1990-2015: a Complete Index of Subjects
Daguerreian Annual 1990–2015: A Complete Index of Subjects & Daguerreotypes Illustrated Subject / Year:Page Version 75 Mark S. Johnson Editor of The Daguerreian Annual, 1997–2015 © 2018 Mark S. Johnson Mark Johnson’s contact: [email protected] This index is a work in progress, and I’m certain there are errors. Updated versions will be released so user feedback is encouraged. If you would like to suggest possible additions or corrections, send the text in the body of an email, formatted as “Subject / year:page” To Use A) Using Adobe Reader, this PDF can be quickly scrolled alphabetically by sliding the small box in the window’s vertical scroll bar. - or - B) PDF’s can also be word-searched, as shown in Figure 1. Many index citations contain keywords so trying a word search will often find other instances. Then, clicking these icons Figure 1 Type the word(s) to will take you to another in- be searched in this Adobe Reader Window stance of that word, either box. before or after. If you do not own the Daguerreian Annual this index refers you to, we may be able to help. Contact us at: [email protected] A Acuna, Patricia 2013: 281 1996: 183 Adams, Soloman; microscopic a’Beckett, Mr. Justice (judge) Adam, Hans Christian d’types 1995: 176 1995: 194 2002/2003: 287 [J. A. Whipple] Abbot, Charles G.; Sec. of Smithso- Adams & Co. Express Banking; 2015: 259 [ltr. in Boston Daily nian Institution deposit slip w/ d’type engraving Evening Transcript, 1/7/1847] 2015: 149–151 [letters re Fitz] 2014: 50–51 Adams, Zabdiel Boylston Abbott, J. -

The Penguin Book of Card Games
PENGUIN BOOKS The Penguin Book of Card Games A former language-teacher and technical journalist, David Parlett began freelancing in 1975 as a games inventor and author of books on games, a field in which he has built up an impressive international reputation. He is an accredited consultant on gaming terminology to the Oxford English Dictionary and regularly advises on the staging of card games in films and television productions. His many books include The Oxford History of Board Games, The Oxford History of Card Games, The Penguin Book of Word Games, The Penguin Book of Card Games and the The Penguin Book of Patience. His board game Hare and Tortoise has been in print since 1974, was the first ever winner of the prestigious German Game of the Year Award in 1979, and has recently appeared in a new edition. His website at http://www.davpar.com is a rich source of information about games and other interests. David Parlett is a native of south London, where he still resides with his wife Barbara. The Penguin Book of Card Games David Parlett PENGUIN BOOKS PENGUIN BOOKS Published by the Penguin Group Penguin Books Ltd, 80 Strand, London WC2R 0RL, England Penguin Group (USA) Inc., 375 Hudson Street, New York, New York 10014, USA Penguin Group (Canada), 90 Eglinton Avenue East, Suite 700, Toronto, Ontario, Canada M4P 2Y3 (a division of Pearson Penguin Canada Inc.) Penguin Ireland, 25 St Stephen’s Green, Dublin 2, Ireland (a division of Penguin Books Ltd) Penguin Group (Australia) Ltd, 250 Camberwell Road, Camberwell, Victoria 3124, Australia -

JAM-BOX Retro PACK 16GB AMSTRAD
JAM-BOX retro PACK 16GB BMX Simulator (UK) (1987).zip BMX Simulator 2 (UK) (19xx).zip Baby Jo Going Home (UK) (1991).zip Bad Dudes Vs Dragon Ninja (UK) (1988).zip Barbarian 1 (UK) (1987).zip Barbarian 2 (UK) (1989).zip Bards Tale (UK) (1988) (Disk 1 of 2).zip Barry McGuigans Boxing (UK) (1985).zip Batman (UK) (1986).zip Batman - The Movie (UK) (1989).zip Beachhead (UK) (1985).zip Bedlam (UK) (1988).zip Beyond the Ice Palace (UK) (1988).zip Blagger (UK) (1985).zip Blasteroids (UK) (1989).zip Bloodwych (UK) (1990).zip Bomb Jack (UK) (1986).zip Bomb Jack 2 (UK) (1987).zip AMSTRAD CPC Bonanza Bros (UK) (1991).zip 180 Darts (UK) (1986).zip Booty (UK) (1986).zip 1942 (UK) (1986).zip Bravestarr (UK) (1987).zip 1943 (UK) (1988).zip Breakthru (UK) (1986).zip 3D Boxing (UK) (1985).zip Bride of Frankenstein (UK) (1987).zip 3D Grand Prix (UK) (1985).zip Bruce Lee (UK) (1984).zip 3D Star Fighter (UK) (1987).zip Bubble Bobble (UK) (1987).zip 3D Stunt Rider (UK) (1985).zip Buffalo Bills Wild West Show (UK) (1989).zip Ace (UK) (1987).zip Buggy Boy (UK) (1987).zip Ace 2 (UK) (1987).zip Cabal (UK) (1989).zip Ace of Aces (UK) (1985).zip Carlos Sainz (S) (1990).zip Advanced OCP Art Studio V2.4 (UK) (1986).zip Cauldron (UK) (1985).zip Advanced Pinball Simulator (UK) (1988).zip Cauldron 2 (S) (1986).zip Advanced Tactical Fighter (UK) (1986).zip Championship Sprint (UK) (1986).zip After the War (S) (1989).zip Chase HQ (UK) (1989).zip Afterburner (UK) (1988).zip Chessmaster 2000 (UK) (1990).zip Airwolf (UK) (1985).zip Chevy Chase (UK) (1991).zip Airwolf 2 (UK) -
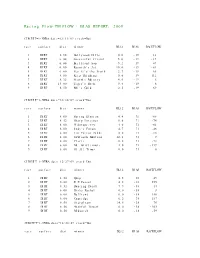
Racing Flow-TM FLOW + BIAS REPORT: 2009
Racing Flow-TM FLOW + BIAS REPORT: 2009 CIRCUIT=1-NYRA date=12/31/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 5.50 Hollywood Hills 0.0 -19 13 2 DIRT 6.00 Successful friend 5.0 -19 -19 3 DIRT 6.00 Brilliant Son 5.2 -19 47 4 DIRT 6.00 Raynick's Jet 10.6 -19 -61 5 DIRT 6.00 Yes It's the Truth 2.7 -19 65 6 DIRT 8.00 Keep Thinking 0.0 -19 -112 7 DIRT 8.32 Storm's Majesty 4.0 -19 6 8 DIRT 13.00 Tiger's Rock 9.4 -19 6 9 DIRT 8.50 Mel's Gold 2.5 -19 69 CIRCUIT=1-NYRA date=12/30/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 8.00 Spring Elusion 4.4 71 -68 2 DIRT 8.32 Sharp Instinct 0.0 71 -74 3 DIRT 6.00 O'Sotopretty 4.0 71 -61 4 DIRT 6.00 Indy's Forum 4.7 71 -46 5 DIRT 6.00 Ten Carrot Nikki 0.0 71 -18 6 DIRT 8.00 Sawtooth Moutain 12.1 71 9 7 DIRT 6.00 Cleric 0.6 71 -73 8 DIRT 6.00 Mt. Glittermore 4.0 71 -119 9 DIRT 6.00 Of All Times 0.0 71 0 CIRCUIT=1-NYRA date=12/27/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 8.50 Quip 4.5 -38 49 2 DIRT 6.00 E Z Passer 4.2 -38 255 3 DIRT 8.32 Dancing Daisy 7.9 -38 14 4 DIRT 6.00 Risky Rachel 0.0 -38 8 5 DIRT 6.00 Kaffiend 0.0 -38 150 6 DIRT 6.00 Capridge 6.2 -38 187 7 DIRT 8.50 Stargleam 14.5 -38 76 8 DIRT 8.50 Wishful Tomcat 0.0 -38 -203 9 DIRT 8.50 Midwatch 0.0 -38 -59 CIRCUIT=1-NYRA date=12/26/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 6.00 Papaleo 7.0 108 129 2 DIRT 6.00 Overcommunication 1.0 108 -72 3 DIRT 6.00 Digger 0.0 108 -211 4 DIRT 6.00 Bryan Kicks 0.0 108 136 5 DIRT 6.00 We Get It 16.8 108 129 6 DIRT 6.00 Yawanna Trust 4.5 108 -21 7 DIRT 6.00 Smarty Karakorum 6.5 108 83 8 DIRT 8.32 Almighty Silver 18.7 108 133 9 DIRT 8.32 Offlee Cool 0.0 108 -60 CIRCUIT=1-NYRA date=12/13/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 8.32 Crafty Bear 3.0 -158 -139 2 DIRT 6.00 Cheers Darling 0.5 -158 61 3 DIRT 6.00 Iberian Gate 3.0 -158 154 4 DIRT 6.00 Pewter 0.5 -158 8 5 DIRT 6.00 Wolfson 6.2 -158 86 6 DIRT 6.00 Mr. -

\0-9\0 and X ... \0-9\0 Grad Nord ... \0-9\0013 ... \0-9\007 Car Chase ... \0-9\1 X 1 Kampf ... \0-9\1, 2, 3
... \0-9\0 and X ... \0-9\0 Grad Nord ... \0-9\0013 ... \0-9\007 Car Chase ... \0-9\1 x 1 Kampf ... \0-9\1, 2, 3 ... \0-9\1,000,000 ... \0-9\10 Pin ... \0-9\10... Knockout! ... \0-9\100 Meter Dash ... \0-9\100 Mile Race ... \0-9\100,000 Pyramid, The ... \0-9\1000 Miglia Volume I - 1927-1933 ... \0-9\1000 Miler ... \0-9\1000 Miler v2.0 ... \0-9\1000 Miles ... \0-9\10000 Meters ... \0-9\10-Pin Bowling ... \0-9\10th Frame_001 ... \0-9\10th Frame_002 ... \0-9\1-3-5-7 ... \0-9\14-15 Puzzle, The ... \0-9\15 Pietnastka ... \0-9\15 Solitaire ... \0-9\15-Puzzle, The ... \0-9\17 und 04 ... \0-9\17 und 4 ... \0-9\17+4_001 ... \0-9\17+4_002 ... \0-9\17+4_003 ... \0-9\17+4_004 ... \0-9\1789 ... \0-9\18 Uhren ... \0-9\180 ... \0-9\19 Part One - Boot Camp ... \0-9\1942_001 ... \0-9\1942_002 ... \0-9\1942_003 ... \0-9\1943 - One Year After ... \0-9\1943 - The Battle of Midway ... \0-9\1944 ... \0-9\1948 ... \0-9\1985 ... \0-9\1985 - The Day After ... \0-9\1991 World Cup Knockout, The ... \0-9\1994 - Ten Years After ... \0-9\1st Division Manager ... \0-9\2 Worms War ... \0-9\20 Tons ... \0-9\20.000 Meilen unter dem Meer ... \0-9\2001 ... \0-9\2010 ... \0-9\21 ... \0-9\2112 - The Battle for Planet Earth ... \0-9\221B Baker Street ... \0-9\23 Matches .. -

A Sampling of Card Games
A Sampling of Card Games Todd W. Neller Introduction • Classifications of Card Games • A small, diverse, simple sample of card games using the standard (“French”) 52-card deck: – Trick-Taking: Oh Hell! – Shedding: President – Collecting: Gin Rummy – Patience/Solitaire: Double Freecell Card Game Classifications • Classification of card games is difficult, but grouping by objective/mechanism clarifies similarities and differences. • Best references: – http://www.pagat.com/ by John McLeod (1800+ games) – “The Penguin Book of Card Games” by David Parlett (250+) Parlett’s Classification • Trick-Taking (or Trick-Avoiding) Games: – Plain-Trick Games: aim for maximum tricks or ≥/= bid tricks • E.g. Bridge, Whist, Solo Whist, Euchre, Hearts*, Piquet – Point-Trick Games: aim for maximum points from cards in won tricks • E.g. Pitch, Skat, Pinochle, Klabberjass, Tarot games *While hearts is more properly a point-trick game, many in its family have plain-trick scoring elements. Piquet is another fusion of scoring involving both tricks and cards. Parlett’s Classification (cont.) • Card-Taking Games – Catch-and-collect Games (e.g. GOPS), Fishing Games (e.g. Scopa) • Adding-Up Games (e.g. Cribbage) • Shedding Games – First-one-out wins (Stops (e.g. Newmarket), Eights (e.g. Crazy 8’s, Uno), Eleusis, Climbing (e.g. President), last-one-in loses (e.g. Durak) • Collecting Games – Forming sets (“melds”) for discarding/going out (e.g. Gin Rummy) or for scoring (e.g. Canasta) • Ordering Games, i.e. Competitive Patience/Solitaire – e.g. Racing Demon (a.k.a. Race/Double Canfield), Poker Squares • Vying Games – Claiming (implicitly via bets) that you have the best hand (e.g. -

HEADLINE NEWS • 11/1/09 • PAGE 2 of 10
Biomechanics & Cardio Scores HEADLINE for Yearlings, 2YOs, Racehorses, Mares & Stallions NEWS BreezeFigs™ at the Two-Year-Old Sales For information about TDN, DATATRACK call 732-747-8060. www.biodatatrack.com www.thoroughbreddailynews.com SUNDAY, NOVEMBER 1, 2009 Bob Fierro • Jay Kilgore • Frank Mitchell STARS OF TOMORROW, TAKE 1 BREEDERS’ CUP The 2009 Fall Meet at Churchill Downs kicks off today with the Stars of Tomorrow I card, featuring 11 races for juveniles. Dublin BULLETIN (Afleet Alex), who hit the national radar with a sharp win in the GI Three Chim- ZENYATTA GETS IN THE GROOVE neys Hopeful S. on Labor Day at Unbeaten Zenyatta (Street Cry {Ire}) tuned up for her Saratoga, saw his Breeders= Cup--and date with destiny by breezing six furlong in 1:12.40 at championship--hopes dashed when he Hollywood Park yesterday morning. Regular rider Mike was a flat fifth at 3-5 in the GI Cham- Smith piloted the big pagne S. at Belmont Oct. 10. The chest- mare, who moved nut colt has two solid works under the Horsephotos past stablemate Twin Spires in the interim, and adds Green Cat (Stormin blinkers this time. AHe has done very well since the Fever) with ease in Champagne,@ said Hall of Fame trainer D. Wayne Lukas. the lane (video). AShe AI did not consider the Breeders= Cup with him, because went very well and I did not want to run him on the artificial [Pro-Ride everyone was surface at Santa Anita].@ Lukas added, AHe=s my best pleased,@ said trainer two-year-old, and he may be one of the best in the John Shirreffs. -

Vol. 14, No. 5 July 2006
Cockaigne (In London Town) • Concert Allegro • Grania and Diarmid • May Song • Dream Children • Coronation Ode • Weary Wind of the West • Skizze • Offertoire • The Apostles • In The South (Alassio) • Introduction and Allegro • Evening Scene • In Smyrna • The Kingdom • Wand of Youth • How Calmly the Evening • Pleading • Go, Song of Mine • Elegy • Violin Concerto in BElgar minor •Society Romance • Symphony No.2 • O Hearken Thou • Coronation March • Crown of India • Great is ournalthe Lord • Cantique • The Music Makers • Falstaff • Carissima • Sospiri • The Birthright • The Windlass • Death on the Hills • Give Unto the Lord • Carillon • Polonia • Une Voix dans le Desert • The Starlight Express • Le Drapeau Belge • The Spirit of England • The Fringes of the Fleet • The Sanguine Fan • Violin Sonata in E minor • String Quartet in E minor • Piano Quintet in A minor • Cello Concerto in E minor • King Arthur • The Wanderer • Empire March • The Herald • Beau Brummel • Severn Suite • Soliloquy • Nursery Suite • Adieu • Organ Sonata • Mina • The Spanish Lady • Chantant • Reminiscences • Harmony Music • Promenades • Evesham Andante • Rosemary (That's for Remembrance) • Pastourelle • Virelai • Sevillana • Une Idylle • Griffinesque • Gavotte • Salut d'Amour • Mot d'Amour • Bizarrerie • O Happy Eyes • My Love Dwelt in a Northern Land • Froissart • Spanish Serenade • La Capricieuse • Serenade • The Black Knight • Sursum Corda • The Snow • Fly, SingingJULY Bird 2006 • FromVol. 14, No.the 5 Bavarian Highlands • The Light of Life • King Olaf • Imperial March • The Banner of St George • Te Deum and Benedictus • Caractacus • Variations on an Original Theme (Enigma) • The Elgar Society The Elgar Society Journal Founded 1951 362 Leymoor Road, Golcar, Huddersfield, West Yorkshire HD7 4QF Telephone & Fax: 01484 649108 Email: [email protected] President Richard Hickox, CBE July 2006 Vol. -

The Birds of a Feather Research Challenge
The Birds of a Feather Research Challenge Todd W. Neller Gettysburg College November 9th, 2017 Outline • Backstories: – Rook Jumping Mazes – Parameterized Poker Squares – FreeCell • Birds of a Feather – Rules – 4x4 Single Stack Play – Experiments – Brainstorming Rook Jumping Maze Design • Rook Jumping Mazes - logic mazes with simple rules based on Chess rook moves • Few maze designers in history had the skill to create these. • We worked together to create a metric to rate the quality of mazes and performed combinatorial optimization to generate high quality mazes. Example Maze Specification: grid size, start state (square), goal state, jump numbers for each non-goal state. Jump number: Move exactly that many squares up, down, left, right. (Not diagonally.) Objectives: ◦ Find a path from start to goal. ◦ Find the shortest of these paths. Publication in van den Herik, H. Jaap, Iida, Hiroyuki, and Plaat, Aske, eds., LNCS 6515: Computers and Games, 7th International Conference, CG 2010, Kanazawa, Japan, September 24-26, 2010, Revised Selected Papers, Springer, 2011, pp. 188-198. Parameterized Poker Squares • Materials: – shuffled standard (French) 52-card deck, – paper with 5-by-5 grid, and – pencil • Each turn, a player draws a card and writes the card rank and suit in an empty grid position. • After 25 turns, the grid is full and the player scores each grid row and column as a 5-card poker hand according to a point system. American Point System Poker Hand Points Description Example Royal Flush 100 A 10-J-Q-K-A sequence all of the 10., J., Q., K., A. same suit Five cards in sequence all of the Straight Flush 75 same suit A , 2 , 3 , 4 , 5 Four of a Kind 50 Four cards of the same rank 9., 9, 9, 9, 6 Three cards of one rank with two Full House 25 cards of another rank 7, 7., 7, 8, 8 Flush 20 Five cards all of the same suit A, 2, 3, 5, 8 Five cards in sequence; Aces may Straight 15 be high or low but not both 8., 9, 10, J, Q. -

2005 Minigame Multicart 32 in 1 Game Cartridge 3-D Tic-Tac-Toe Acid Drop Actionauts Activision Decathlon, the Adventure A
2005 Minigame Multicart 32 in 1 Game Cartridge 3-D Tic-Tac-Toe Acid Drop Actionauts Activision Decathlon, The Adventure Adventures of TRON Air Raid Air Raiders Airlock Air-Sea Battle Alfred Challenge (France) (Unl) Alien Alien Greed Alien Greed 2 Alien Greed 3 Allia Quest (France) (Unl) Alligator People, The Alpha Beam with Ernie Amidar Aquaventure Armor Ambush Artillery Duel AStar Asterix Asteroid Fire Asteroids Astroblast Astrowar Atari Video Cube A-Team, The Atlantis Atlantis II Atom Smasher A-VCS-tec Challenge AVGN K.O. Boxing Bachelor Party Bachelorette Party Backfire Backgammon Bank Heist Barnstorming Base Attack Basic Math BASIC Programming Basketball Battlezone Beamrider Beany Bopper Beat 'Em & Eat 'Em Bee-Ball Berenstain Bears Bermuda Triangle Berzerk Big Bird's Egg Catch Bionic Breakthrough Blackjack BLiP Football Bloody Human Freeway Blueprint BMX Air Master Bobby Is Going Home Boggle Boing! Boulder Dash Bowling Boxing Brain Games Breakout Bridge Buck Rogers - Planet of Zoom Bugs Bugs Bunny Bump 'n' Jump Bumper Bash BurgerTime Burning Desire (Australia) Cabbage Patch Kids - Adventures in the Park Cakewalk California Games Canyon Bomber Carnival Casino Cat Trax Cathouse Blues Cave In Centipede Challenge Challenge of.... Nexar, The Championship Soccer Chase the Chuckwagon Checkers Cheese China Syndrome Chopper Command Chuck Norris Superkicks Circus Atari Climber 5 Coco Nuts Codebreaker Colony 7 Combat Combat Two Commando Commando Raid Communist Mutants from Space CompuMate Computer Chess Condor Attack Confrontation Congo Bongo -

Etude Et Développements De Jeux Vidéo Sonores Accessibles Aux Personnes Aveugles
Conservatoire National des Arts et Métier Thèse pour obtenir le grade de docteur du CNAM Discipline : Informatique Présentée et soutenue publiquement par Thomas Gaudy le 3 Juillet 2008 Etude et développements de jeux vidéo sonores accessibles aux personnes aveugles Stéphane Directeur de Thèse Centre de Recherche en Informatique du CNAM Natkin Dominique Laboratoire Interfaces Non Visuelles et Codirecteur de Thèse Archambault Accessibilité de l’Université Pierre et Marie Curie Gilles Responsable Industriel Entreprise CECIAA Candotti Jury : Jaime López-Krahe (président), Jaime López-Krahe (rapporteur), Noëlle Carbonell (rapporteur), Eliana Sampaio, Cécile Le Prado, Pierre Cubaud, Claude Liard. N° attribué par la bibliothèque : │__ │__ │__ │__ │__ │__ │__ │__ │__ │__ │__ │ 1 Résumé Les jeux vidéo sont un divertissement qui touche un public de plus en plus large. Cependant, le concept même de jeux basés sur la perception visuelle exclue toute une catégorie de joueurs: les personnes déficientes visuelles. Nous avons effectué un état de l’art des jeux sonores sous leurs différentes formes dans la première partie de cette thèse. Les jeux sonores souffrent d’une prise en main difficile. L’explication des règles par l’utilisation du langage n’est pas assez efficace et nuit au rythme de l’interaction. Nous nous demandons s’il est possible d’inclure un système non langagier permettant un démarrage rapide de la partie dans un jeu sonore accessible aux personnes non voyantes. La seconde partie constitue une réflexion théorique sur les qualités que doivent présenter les jeux pour permettre une prise en main rapide. Nous expliquons comment une personne devient joueur progressivement en suivant un processus d’apprentissage basé sur l’interaction. -

The Amazing Marriage
The Amazing Marriage George Meredith The Amazing Marriage Table of Contents The Amazing Marriage.............................................................................................................................................1 George Meredith............................................................................................................................................1 CHAPTER I. ENTER DAME GOSSIP AS CHORUS.................................................................................1 CHAPTER II. MISTRESS GOSSIP TELLS OF THE ELOPEMENT OF THE COUNTESS OF CRESSETT WITH THE OLD BUCCANEER, AND OF CHARLES DUMP THE POSTILLION CONDUCTING THEM, AND OF A GREAT COUNTY FAMILY...........................................................7 CHAPTER III. CONTINUATION OF THE INTRODUCTORY MEANDERINGS OF DAME GOSSIP, TOGETHER WITH HER SUDDEN EXTINCTION.................................................................11 CHAPTER IV. MORNING AND FAREWELL TO AN OLD HOME......................................................14 CHAPTER V. A MOUNTAIN WALK IN MIST AND SUNSHINE.........................................................19 CHAPTER VI. THE NATURAL PHILOSOPHER....................................................................................25 CHAPTER VII. THE LADY'S LETTER....................................................................................................31 CHAPTER VIII. OF THE ENCOUNTER OF TWO STRANGE YOUNG MEN AND THEIR CONSORTING: IN WHICH THE MALE READER IS REQUESTED TO BEAR IN MIND WHAT WILD CREATURE HE WAS