(PI-Net): Facial Image Obfuscation with Manipulable Semantics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

January 2019 Edition
Tunkhannock Area High School Tunkhannock, Pennsylvania The Prowler January 2019 Volume XIV, Issue XLVII Local Subst itute Teacher in Trouble Former TAHS substitute teacher, Zachary Migliori, faces multiple charges. By MADISON NESTOR Former substitute teacher Wyoming County Chief out, that she did not report it originally set for December at Tunkhannock Area High Detective David Ide, started to anyone. 18 was moved to March 18. School, Zachary Migliori, on October 11 when the When Detective Ide asked If he is convicted, he will was charged with three felony parents of a 15-year old Migliori if he knew that one face community service, and counts of distributing obscene student found pornographic of the girls he sent explicit mandatory counseling. material, three misdemeanor images and sexual texts messages to was a 15-year- Tunkhannock Area High counts of open lewdness, and on their daughter’s phone. old, he explained that he School took action right away three misdemeanor counts of The parent then contacted thought she was 18-years-old to ensure students’ safety, unlawful contact with minors. Detective Ide, who found because she hung out with and offers counseling to any This comes after the results after investigating that the many seniors. After being students who need it. of an investigation suspecting substitute teacher was using informed of one victim being Sources:WNEP, lewd contact with students a Snapchat account with the 15-years-old, Migliori said he WCExaminer, CitizensVoice proved to be true. According name ‘Zach Miggs.’ was disgusted with himself. to court documents, Migliori Two 17-year old females Judge Plummer set used Facebook Messenger also came forward, one of Migliori’s bail at $50,000. -

S.Ha.R.K. Installation Howto Tools Knoppix Live CD Linux Fdisk HD
S.Ha.R.K. Installation Tools HowTo • Linux fdisk utility • A copy of Linux installation CD • A copy of Windows® installation CD Tullio Facchinetti University of Pavia - Italy • Some FreeDOS utilities • A copy of S.Ha.R.K. S.Ha.R.K. Workshop S.Ha.R.K. Workshop Knoppix live CD Linux fdisk Command action a toggle a bootable flag Download ISO from b edit bsd disklabel c toggle the dos compatibility flag d delete a partition http://www.knoppix.org l list known partition types m print this menu n add a new partition o create a new empty DOS partition table p print the partition table q quit without saving changes • boot from CD s create a new empty Sun disklabel t change a partition's system id • open a command shell u change display/entry units v verify the partition table • type “su” (become root ), password is empty w write table to disk and exit x extra functionality (experts only) • start fdisk (ex. fdisk /dev/hda ) Command (m for help): S.Ha.R.K. Workshop S.Ha.R.K. Workshop HD partitioning HD partitioning 1st FreeDOS FAT32 FreeDOS must be installed Primary 2nd Windows® FAT32 into the first partition of your HD or it may not boot 3rd Linux / extX Data 1 FAT32 format data partitions as ... Extended FAT32, so that you can share Data n FAT32 your data between Linux, last Linux swap swap Windows® and FreeDOS S.Ha.R.K. Workshop S.Ha.R.K. Workshop 1 HD partitioning Windows ® installation FAT32 Windows® partition type Install Windows®.. -

NETSTAT Command
NETSTAT Command | NETSTAT Command | Use the NETSTAT command to display network status of the local host. | | ┌┐────────────── | 55──NETSTAT─────6─┤ Option ├─┴──┬────────────────────────────────── ┬ ─ ─ ─ ────────────────────────────────────────5% | │┌┐───────────────────── │ | └─(──SELect───6─┤ Select_String ├─┴ ─ ┘ | Option: | ┌┐─COnn────── (1, 2) ──────────────── | ├──┼─────────────────────────── ┼ ─ ──────────────────────────────────────────────────────────────────────────────┤ | ├─ALL───(2)──────────────────── ┤ | ├─ALLConn─────(1, 2) ────────────── ┤ | ├─ARp ipaddress───────────── ┤ | ├─CLients─────────────────── ┤ | ├─DEvlinks────────────────── ┤ | ├─Gate───(3)─────────────────── ┤ | ├─┬─Help─ ┬─ ───────────────── ┤ | │└┘─?──── │ | ├─HOme────────────────────── ┤ | │┌┐─2ð────── │ | ├─Interval─────(1, 2) ─┼───────── ┼─ ┤ | │└┘─seconds─ │ | ├─LEVel───────────────────── ┤ | ├─POOLsize────────────────── ┤ | ├─SOCKets─────────────────── ┤ | ├─TCp serverid───(1) ─────────── ┤ | ├─TELnet───(4)───────────────── ┤ | ├─Up──────────────────────── ┤ | └┘─┤ Command ├───(5)──────────── | Command: | ├──┬─CP cp_command───(6) ─ ┬ ────────────────────────────────────────────────────────────────────────────────────────┤ | ├─DELarp ipaddress─ ┤ | ├─DRop conn_num──── ┤ | └─RESETPool──────── ┘ | Select_String: | ├─ ─┬─ipaddress────(3) ┬ ─ ───────────────────────────────────────────────────────────────────────────────────────────┤ | ├─ldev_num─────(4) ┤ | └─userid────(2) ─── ┘ | Notes: | 1 Only ALLCON, CONN and TCP are valid with INTERVAL. | 2 The userid -

JES3 Commands
z/OS Version 2 Release 3 JES3 Commands IBM SA32-1008-30 Note Before using this information and the product it supports, read the information in “Notices” on page 431. This edition applies to Version 2 Release 3 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2019-02-16 © Copyright International Business Machines Corporation 1997, 2017. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents List of Figures....................................................................................................... ix List of Tables........................................................................................................ xi About this document...........................................................................................xiii Who should use this document.................................................................................................................xiii Where to find more information................................................................................................................ xiii How to send your comments to IBM......................................................................xv If you have a technical problem.................................................................................................................xv Summary of changes...........................................................................................xvi -

System Analysis and Tuning Guide System Analysis and Tuning Guide SUSE Linux Enterprise Server 15 SP1
SUSE Linux Enterprise Server 15 SP1 System Analysis and Tuning Guide System Analysis and Tuning Guide SUSE Linux Enterprise Server 15 SP1 An administrator's guide for problem detection, resolution and optimization. Find how to inspect and optimize your system by means of monitoring tools and how to eciently manage resources. Also contains an overview of common problems and solutions and of additional help and documentation resources. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents About This Guide xii 1 Available Documentation xiii -
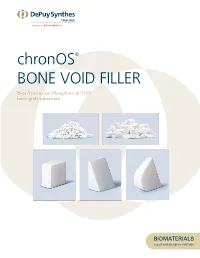
Chronos® Bone Void Filler Beta-Tricalcium Phosphate (B-TCP) Bone Graft Substitute Chronos® Bone Void Filler
chronOS® BONE VOID FILLER Beta-Tricalcium Phosphate (b-TCP) bone graft substitute chronOS® BONE VOID FILLER OSTEOCONDUCTIVE • RESORBABLE • SYNTHETIC chronOS® Granules and Preforms are synthetic, porous, osteoconductive, resorbable calcium phosphate bone substitutes, which can replace autogenous bone. chronOS Bone Graft Substitute eliminates the need for autologous bone harvesting, thus reducing overall patient morbidity. chronOS Granules and Preforms are manufactured in a clean-room environment from a biocompatible, radiopaque material, beta-tricalcium phosphate (b-TCP). This material contains two of the main mineral constituents of bone, calcium and phosphorous. chronOS Bone Graft Substitute has been clinically used in Europe for more than 20 years under the name CEROS 82. Replaced with bone in 6 to 18 months, chronOS Bone Graft Substitute is suitable for many bone void filler applications. Due to its synthetic manufacturing process, chronOS Beta-Tricalcium Phosphate shows reliable and standardized biomechanical properties. The compressive strength of chronOS Beta-Tricalcium Phosphate averages ~5 MPa, and is similar to that of human cancellous bone. Postoperative, 6 weeks Postoperative, 12 months High tibial osteotomy treated with a proximal tibial plate and chronOS Preforms (Dr. Wymengy, Nijmegen, Netherlands) DePuy Synthes Trauma chronOS Bone Void Filler INDICATIONS AND CONTRAINDICATIONS Indications chronOS is indicated for use in bony voids or gaps that are not intrinsic to the stability of the bony structure. chronOS is indicated for use in the treatment of bony defects created surgically or through traumatic injury. chronOS is intended to be gently packed or placed into bony voids or gaps of the skeletal system (i.e., the extremities, spine, and pelvis) and may be combined with autogenous blood and/or bone marrow. -
Mapping a Network Drive in Windows Command Line Mapping a Network
Mapping a WebDAV network drive Once your server meets the requirements, you need to map a network drive in your operation system that will be pointing to your web server. There are two ways how this can be done: Mapping the network drive in Windows command line Mapping the network drive in Windows Mapping a network drive in Windows command line 1. Open Windows command line (press [window]+R, type cmd and click OK). 2. Type the following command: net use x: http://<your_domain>/cms/files The x: part of the command determines which letter will be used for identification of the network drive in your system. Instead of x, you can use any letter that is not used for another drive yet.The <your_domain> part of the command needs to be replaced with the domain name of your website. So, for example, if your website is running on http://www.example. com, you would need to enter 'net use x: http://www.example.com/cms/files'. Similarly, for http://localhost/Kentico, you would need to enter 'net use x: http://localhost/Kentico/cms/files'. Mapping a network drive in Windows The following procedure is demonstrated on Windows 7. In other versions of Windows, it may be slightly different, while the principles and the entered values remain the same. 1. Open Windows Explorer. 2. Rightclick the Computer in the left menu and select Map network drive. Alternatively, you can click the Computer and select the Map network drive action from the top menu. 3. In the Map Network Drive dialog, adjust the following values: Drive - select the letter that will be assigned to the network drive in Windows. -

Label Formatting Commands
TSPL/TSPL2 Programming Language TSC BAR CODE PRINTER SERIES PROGRAMMING MANUAL TABLE OF CONTENTS How to Read .......................................................................................................................................... VI Document Conventions......................................................................................................................... VII Object Position Calculation .................................................................................................................. VIII Printer Model List ................................................................................................................................... X Setup and System Commands ................................................................................................................. 1 SIZE ....................................................................................................................................................... 1 GAP ...................................................................................................................................................... 2 GAPDETECT .......................................................................................................................................... 4 BLINEDETECT ........................................................................................................................................ 5 AUTODETECT ....................................................................................................................................... -

Ip COMMAND CHEAT SHEET
ip COMMAND MODIFYING ADDRESS AND LINK PROPERTIES CHEAT SHEET SUBCOMMAND DESCRIPTIONS AND TASKS addr add Add an address for Red Hat Enterprise Linux ip addr add 192.168.1.1/24 dev em1 Add address 192.168.1.1 with netmask 24 to device em1 addr del Delete an address IP QUERIES ip addr del 192.168.1.1/24 dev em1 SUBCOMMAND DESCRIPTIONS AND TASKS Remove address 192.168.1.1/24 from device em1 addr Display IP Addresses and property information link set Alter the status of the interface (abbreviation of address) ip link set em1 up ip addr Bring em1 online Show information for all addresses ip link set em1 down ip addr show dev em1 Bring em1 offline Display information only for device em1 ip link set em1 mtu 9000 Set the MTU on em1 to 9000 link Manage and display the state of all network interfaces ip link set em1 promisc on Enable promiscuous mode for em1 ip link Show information for all interfaces ip link show dev em1 Display information only for device em1 ADJUSTING AND VIEWING ROUTES ip -s link SUBCOMMAND DESCRIPTIONS AND TASKS Display interface statistics route add Add an entry to the routing table Display and alter the routing table route ip route add default via 192.168.1.1 dev em1 ip route Add a default route (for all addresses) via the local gateway List all of the route entries in the kernel 192.168.1.1 that can be reached on device em1 ip route add 192.168.1.0/24 via 192.168.1.1 maddr Manage and display multicast IP addresses Add a route to 192.168.1.0/24 via the gateway at 192.168.1.1 ip maddr ip route add 192.168.1.0/24 dev em1 Display -

Substitute Teacher Handbook (2014 – 2015)
!"#$%&&'(( )*+(( (( ,-%,./.-.0(.0"1!02,!! ! #03(4&2'(1/.4($05"2.60#.(&7(0$-1"./&#( $898:8*;(*)(!<=>;(1>?8@>A(( &))8BC(*)(!2(,BD**A(,<??*+@(E(,<F1C;@+>A( !"#$%&'(#)('**(+#"(,#-.%%'+#/%%0#"12# 3'%%4.56+#78#99:19# ;<9=>#?@"#A#2219# ,((BCDDEF,%%.EG65FGH%I# # # ## /*IG#1!J:19?# Office of HR School Support Peter Ianniello, PhD., Executive Director Pamela Conroy, Deputy Executive Director 2 Dear Colleague: Welcome to the exciting challenge of becoming a Substitute Teacher with the New York City Department of Education (NYCDOE). You have chosen a path that will be challenging but also highly rewarding. In addition, you are taking on a role that is being shaped to meet the increasing rigor and expectations required by New York City Public Schools. The New York City public school system is our nation’s largest: over 1.1 million registered students; more than 1,800 schools in operation, citywide; 80,000 Teachers and Teacher- related positions, assisted by over 23,000 Paraprofessionals, all of whom share the goal of improving outcomes for students. The role of a Substitute Teacher has evolved from being merely a coverage person, to one that provides quality classroom instruction in an on-going basis. You are an integral part of the student learning process. The same high standards and accountability expected from permanently assigned Teachers, are also expected from you. The following understandings and expectations should guide you as you take on assignments: • Continuation of student learning, along a continuum established by the permanent Teachers and school leaders, as your primary focus; • Establishment of your professional presence and exuding self-confidence in your role; and • Demonstration of effective instruction, consistent with school norms and classroom management. -

Network Troubleshooting Commands for Windows
Network troubleshooting commands for Windows The Windows troubleshooting commands discussed in this document fall into three categories: Determine which groups a user belongs To generate a list of groups that a user belongs, open a command prompt and enter the following commands: net user <username> /domain Replace <username> with an actual user name. For example: net user jdoe /domain Helpful commands entered from the Start > Run dialog box Select Start > Run to execute any of the following commands. mstsc Opens the Remote Desktop (RDP) tool winmsd Opens the System Information dialog box inetcpl.cpil Opens the Internet Explorer Properties dialog box odbccp32.cpl Opens the ODBC Data Source Administrator mmc Opens the Microsoft Management Console (MMC) services.msc Opens the Windows Services dialog box eventvwr.msc Opens the Windows Event Viewer dsa.msc Opens the Active Directory User and Computers management console dssite.msc Opens the Active Directory Sites and Services management console adminpak.msi Launches the Administration Tools Pack installer dxdiag Opens the DirectX Diagnostic Tool \\< Name or IP>\C$ Opens a UNC to the C: share cmd Opens the Windows Command Prompt using the 32-bit cmd shell Command-line tools for troubleshooting network connectivity This list contains some common commands for troubleshooting network connectivity. Select Start > Runand then type cmd to access the appropriate command prompt. Activating a command window viaStart > Programs > Accessories does not allow all of the following tools to run correctly. arp -a Shows gateway MAC address. gpresult Starts the Operating System Group Policy Result tool ipconfig /all Displays the full TCP/IP configuration for all adapters Flushes the DNS resolver cache. -
NET Command Line Application Note
Application Note: NP-660S/NP-800S/NP-612S NET Command line Usage The net command is used to update, fix, or view the network or network settings. Listed in the Syntax we have listed each of net commands. Note: The net command line settings are not persistent and will need to be established on each boot. A batch file executes on boot is the best solution. NET USE Net use [<local name>|*] [<remote name>] {/user:<username>] [/d] <local name> Specifies the name you wish to assign to a shared directory. <remote name> Specifies the name of the computer sharing the resource. /user:<user name> Specifies the name of the user using the recource. Net VIEW Net view <computername> | /DOMAIN:<domainname> <computername> - Specifies the name of the computer whose shared resources you want to see listed. /DOMAIN:<domainname> Specifies the name of the domain whose computer names you want to view. www.ivcdisplays.com Page 1 Support: (734) 786-8259 Application Note: NP-660S/NP-800S/NP-612S NET Command line Usage NET /? – Displays help for usage of the net command. www.ivcdisplays.com Page 2 Support: (734) 786-8259 Application Note: NP-660S/NP-800S/NP-612S NET Command line Usage Net view ken-xp - will display the shared names are available on shared resources ken- xp. Disk drives and printers are both listed and may be attached to with the net use command. www.ivcdisplays.com Page 3 Support: (734) 786-8259 Application Note: NP-660S/NP-800S/NP-612S NET Command line Usage Net use c: \\ken-xp\ken /user:guest – is a request to the systems to assign the name c: to the shared resource ken found on the shared resource name ken-xp.