System Analysis and Tuning Guide System Analysis and Tuning Guide SUSE Linux Enterprise Server 15 SP1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Desktop Migration and Administration Guide
Red Hat Enterprise Linux 7 Desktop Migration and Administration Guide GNOME 3 desktop migration planning, deployment, configuration, and administration in RHEL 7 Last Updated: 2021-05-05 Red Hat Enterprise Linux 7 Desktop Migration and Administration Guide GNOME 3 desktop migration planning, deployment, configuration, and administration in RHEL 7 Marie Doleželová Red Hat Customer Content Services [email protected] Petr Kovář Red Hat Customer Content Services [email protected] Jana Heves Red Hat Customer Content Services Legal Notice Copyright © 2018 Red Hat, Inc. This document is licensed by Red Hat under the Creative Commons Attribution-ShareAlike 3.0 Unported License. If you distribute this document, or a modified version of it, you must provide attribution to Red Hat, Inc. and provide a link to the original. If the document is modified, all Red Hat trademarks must be removed. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. -
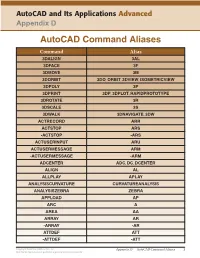
Autocad Command Aliases
AutoCAD and Its Applications Advanced Appendix D AutoCAD Command Aliases Command Alias 3DALIGN 3AL 3DFACE 3F 3DMOVE 3M 3DORBIT 3DO, ORBIT, 3DVIEW, ISOMETRICVIEW 3DPOLY 3P 3DPRINT 3DP, 3DPLOT, RAPIDPROTOTYPE 3DROTATE 3R 3DSCALE 3S 3DWALK 3DNAVIGATE, 3DW ACTRECORD ARR ACTSTOP ARS -ACTSTOP -ARS ACTUSERINPUT ARU ACTUSERMESSAGE ARM -ACTUSERMESSAGE -ARM ADCENTER ADC, DC, DCENTER ALIGN AL ALLPLAY APLAY ANALYSISCURVATURE CURVATUREANALYSIS ANALYSISZEBRA ZEBRA APPLOAD AP ARC A AREA AA ARRAY AR -ARRAY -AR ATTDEF ATT -ATTDEF -ATT Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 1 May not be reproduced or posted to a publicly accessible website. Command Alias ATTEDIT ATE -ATTEDIT -ATE, ATTE ATTIPEDIT ATI BACTION AC BCLOSE BC BCPARAMETER CPARAM BEDIT BE BLOCK B -BLOCK -B BOUNDARY BO -BOUNDARY -BO BPARAMETER PARAM BREAK BR BSAVE BS BVSTATE BVS CAMERA CAM CHAMFER CHA CHANGE -CH CHECKSTANDARDS CHK CIRCLE C COLOR COL, COLOUR COMMANDLINE CLI CONSTRAINTBAR CBAR CONSTRAINTSETTINGS CSETTINGS COPY CO, CP CTABLESTYLE CT CVADD INSERTCONTROLPOINT CVHIDE POINTOFF CVREBUILD REBUILD CVREMOVE REMOVECONTROLPOINT CVSHOW POINTON Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 2 May not be reproduced or posted to a publicly accessible website. Command Alias CYLINDER CYL DATAEXTRACTION DX DATALINK DL DATALINKUPDATE DLU DBCONNECT DBC, DATABASE, DATASOURCE DDGRIPS GR DELCONSTRAINT DELCON DIMALIGNED DAL, DIMALI DIMANGULAR DAN, DIMANG DIMARC DAR DIMBASELINE DBA, DIMBASE DIMCENTER DCE DIMCONSTRAINT DCON DIMCONTINUE DCO, DIMCONT DIMDIAMETER DDI, DIMDIA DIMDISASSOCIATE DDA DIMEDIT DED, DIMED DIMJOGGED DJO, JOG DIMJOGLINE DJL DIMLINEAR DIMLIN, DLI DIMORDINATE DOR, DIMORD DIMOVERRIDE DOV, DIMOVER DIMRADIUS DIMRAD, DRA DIMREASSOCIATE DRE DIMSTYLE D, DIMSTY, DST DIMTEDIT DIMTED DIST DI, LENGTH DIVIDE DIV DONUT DO DRAWINGRECOVERY DRM DRAWORDER DR Copyright Goodheart-Willcox Co., Inc. -

Shell Scripting with Bash
Introduction to Shell Scripting with Bash Charles Jahnke Research Computing Services Information Services & Technology Topics for Today ● Introductions ● Basic Terminology ● How to get help ● Command-line vs. Scripting ● Variables ● Handling Arguments ● Standard I/O, Pipes, and Redirection ● Control Structures (loops and If statements) ● SCC Job Submission Example Research Computing Services Research Computing Services (RCS) A group within Information Services & Technology at Boston University provides computing, storage, and visualization resources and services to support research that has specialized or highly intensive computation, storage, bandwidth, or graphics requirements. Three Primary Services: ● Research Computation ● Research Visualization ● Research Consulting and Training Breadth of Research on the Shared Computing Cluster (SCC) Me ● Research Facilitator and Administrator ● Background in biomedical engineering, bioinformatics, and IT systems ● Offices on both CRC and BUMC ○ Most of our staff on the Charles River Campus, some dedicated to BUMC ● Contact: [email protected] You ● Who has experience programming? ● Using Linux? ● Using the Shared Computing Cluster (SCC)? Basic Terminology The Command-line The line on which commands are typed and passed to the shell. Username Hostname Current Directory [username@scc1 ~]$ Prompt Command Line (input) The Shell ● The interface between the user and the operating system ● Program that interprets and executes input ● Provides: ○ Built-in commands ○ Programming control structures ○ Environment -

CS101 Lecture 9
How do you copy/move/rename/remove files? How do you create a directory ? What is redirection and piping? Readings: See CCSO’s Unix pages and 9-2 cp option file1 file2 First Version cp file1 file2 file3 … dirname Second Version This is one version of the cp command. file2 is created and the contents of file1 are copied into file2. If file2 already exits, it This version copies the files file1, file2, file3,… into the directory will be replaced with a new one. dirname. where option is -i Protects you from overwriting an existing file by asking you for a yes or no before it copies a file with an existing name. -r Can be used to copy directories and all their contents into a new directory 9-3 9-4 cs101 jsmith cs101 jsmith pwd data data mp1 pwd mp1 {FILES: mp1_data.m, mp1.m } {FILES: mp1_data.m, mp1.m } Copy the file named mp1_data.m from the cs101/data Copy the file named mp1_data.m from the cs101/data directory into the pwd. directory into the mp1 directory. > cp ~cs101/data/mp1_data.m . > cp ~cs101/data/mp1_data.m mp1 The (.) dot means “here”, that is, your pwd. 9-5 The (.) dot means “here”, that is, your pwd. 9-6 Example: To create a new directory named “temp” and to copy mv option file1 file2 First Version the contents of an existing directory named mp1 into temp, This is one version of the mv command. file1 is renamed file2. where option is -i Protects you from overwriting an existing file by asking you > cp -r mp1 temp for a yes or no before it copies a file with an existing name. -

Windows Command Prompt Cheatsheet
Windows Command Prompt Cheatsheet - Command line interface (as opposed to a GUI - graphical user interface) - Used to execute programs - Commands are small programs that do something useful - There are many commands already included with Windows, but we will use a few. - A filepath is where you are in the filesystem • C: is the C drive • C:\user\Documents is the Documents folder • C:\user\Documents\hello.c is a file in the Documents folder Command What it Does Usage dir Displays a list of a folder’s files dir (shows current folder) and subfolders dir myfolder cd Displays the name of the current cd filepath chdir directory or changes the current chdir filepath folder. cd .. (goes one directory up) md Creates a folder (directory) md folder-name mkdir mkdir folder-name rm Deletes a folder (directory) rm folder-name rmdir rmdir folder-name rm /s folder-name rmdir /s folder-name Note: if the folder isn’t empty, you must add the /s. copy Copies a file from one location to copy filepath-from filepath-to another move Moves file from one folder to move folder1\file.txt folder2\ another ren Changes the name of a file ren file1 file2 rename del Deletes one or more files del filename exit Exits batch script or current exit command control echo Used to display a message or to echo message turn off/on messages in batch scripts type Displays contents of a text file type myfile.txt fc Compares two files and displays fc file1 file2 the difference between them cls Clears the screen cls help Provides more details about help (lists all commands) DOS/Command Prompt help command commands Source: https://technet.microsoft.com/en-us/library/cc754340.aspx. -

Medi-Cal Dental EDI How-To Guide
' I edi Cal Dental _ Electronic Data Interchange HOW-TO GUIDE EDI EDI edi EDI Support Group Phone: (916) 853-7373 Email: [email protected] Revised November 2019 , ] 1 ,edi .. Cal Dental Medi-Cal Dental Program EDI How-To Guide 11/2019 Welcome to Medical Dental Program’s Electronic Data Interchange Program! This How-To Guide is designed to answer questions providers may have about submitting claims electronically. The Medi-Cal Dental Program's Electronic Data Interchange (EDI) program is an efficient alternative to sending paper claims. It will provide more efficient tracking of the Medi-Cal Dental Program claims with faster responses to requests for authorization and payment. Before submitting claims electronically, providers must be enrolled as an EDI provider to avoid rejection of claims. To enroll, providers must complete the Medi-Cal Dental Telecommunications Provider and Biller Application/Agreement (For electronic claim submission), the Provider Service Office Electronic Data Interchange Option Selection Form and Electronic Remittance Advice (ERA) Enrollment Form and return them to the address indicated on those forms. Providers should advise their software vendor that they would like to submit Medi-Cal Dental Program claims electronically, and if they are not yet enrolled in the EDI program, an Enrollment Packet should be requested from the EDI Support department. Enrollment forms are also available on the Medi-Cal Dental Program Web site (www.denti- cal.ca.gov) under EDI, located on the Providers tab. Providers may also submit digitized images of documentation to the Medi-Cal Dental Program. If providers choose to submit conventional radiographs and attachments through the mail, an order for EDI labels and envelopes will need to be placed using the Forms Reorder Request included in the Enrollment Packet and at the end of this How-To Guide. -

Plw Sc/Nt/Ntr/Ls
K Service Source PLW SC/NT/NTR/LS Personal LaserWriter SC, Personal LaserWriter NT, Personal LaserWriter NTR, Personal LaserWriter LS, Personal LaserWriter LS/L K Service Source Basics PLW SC/NT/NTR/LS Basics Product Information - 1 Product Information The printers covered in this manual are • Personal LaserWriter SC • Personal LaserWriter NT • Personal LaserWriter NTR • Personal LaserWriter LS • Personal LaserWriter LS/L Compatibility Not all parts are compatible among the five models. Refer to Illustrated Parts for compatibility cross references. The cassette feeder tray and its associated parts are optional on the LS, LS/L, and NTR models. Basics Paper Paths - 2 Paper Paths There are four paper paths in the Personal LaserWriter. Paper is fed from the cassette or multipurpose tray and delivered to the face-down or face-up delivery trays. Note: Face signifies image side. Default delivery is face- down at the top of the printer. Basics LS–LS/L Identification - 3 LS–LS/L Identification I/O Board Bracket The LS/L is a cost-reduced version of the LS but is sold and packaged under the same LS name. Parts are not necessarily interchangeable between the two models. Power Switch External distinguishing characteristics: • LS: The power switch is on the left rear of printer; the rear cover has an opening for an I/O board bracket and Personal LaserWriter LS displays the family number M2000. • LS/L: The power switch is on the right rear of printer; Solid Rear Cover the rear cover is solid plastic and displays the family number M2002. Power Switch Personal LaserWriter LS/L Basics Sensing System Theory - 4 Sensing System Theory There are six sensors in the PS11 Personal LaserWriter: four PS12 paper sensors and two printer-open sensors. -

Fragmentation in Large Object Repositories
Fragmentation in Large Object Repositories Experience Paper Russell Sears Catharine van Ingen University of California, Berkeley Microsoft Research [email protected] [email protected] ABSTRACT 1. INTRODUCTION Fragmentation leads to unpredictable and degraded application Application data objects continue to increase in size. performance. While these problems have been studied in detail Furthermore, the increasing popularity of web services and other for desktop filesystem workloads, this study examines newer network applications means that systems that once managed static systems such as scalable object stores and multimedia archives of “finished” objects now manage frequently modified repositories. Such systems use a get/put interface to store objects. versions of application data. Rather than updating these objects in In principle, databases and filesystems can support such place, typical archives either store multiple versions of the objects applications efficiently, allowing system designers to focus on (the V of WebDAV stands for “versioning” [25]), or simply do complexity, deployment cost and manageability. wholesale replacement (as in SharePoint Team Services [19]). Similarly, applications such as personal video recorders and Although theoretical work proves that certain storage policies media subscription servers continuously allocate and delete large, behave optimally for some workloads, these policies often behave transient objects. poorly in practice. Most storage benchmarks focus on short-term behavior or do not measure fragmentation. We compare SQL Applications store large objects as some combination of files in Server to NTFS and find that fragmentation dominates the filesystem and as BLOBs (binary large objects) in a database. performance when object sizes exceed 256KB-1MB. NTFS Only folklore is available regarding the tradeoffs. -

ECE 598 – Advanced Operating Systems Lecture 19
ECE 598 { Advanced Operating Systems Lecture 19 Vince Weaver http://web.eece.maine.edu/~vweaver [email protected] 7 April 2016 Announcements • Homework #7 was due • Homework #8 will be posted 1 Why use FAT over ext2? • FAT simpler, easy to code • FAT supported on all major OSes • ext2 faster, more robust filename and permissions 2 btrfs • B-tree fs (similar to a binary tree, but with pages full of leaves) • overwrite filesystem (overwite on modify) vs CoW • Copy on write. When write to a file, old data not overwritten. Since old data not over-written, crash recovery better Eventually old data garbage collected • Data in extents 3 • Copy-on-write • Forest of trees: { sub-volumes { extent-allocation { checksum tree { chunk device { reloc • On-line defragmentation • On-line volume growth 4 • Built-in RAID • Transparent compression • Snapshots • Checksums on data and meta-data • De-duplication • Cloning { can make an exact snapshot of file, copy-on- write different than link, different inodles but same blocks 5 Embedded • Designed to be small, simple, read-only? • romfs { 32 byte header (magic, size, checksum,name) { Repeating files (pointer to next [0 if none]), info, size, checksum, file name, file data • cramfs 6 ZFS Advanced OS from Sun/Oracle. Similar in idea to btrfs indirect still, not extent based? 7 ReFS Resilient FS, Microsoft's answer to brtfs and zfs 8 Networked File Systems • Allow a centralized file server to export a filesystem to multiple clients. • Provide file level access, not just raw blocks (NBD) • Clustered filesystems also exist, where multiple servers work in conjunction. -

A Brief Introduction to Unix-2019-AMS
Brief Intro to Linux/Unix Brief Intro to Unix (contd) A Brief Introduction to o Brief History of Unix o Compilers, Email, Text processing o Basics of a Unix session o Image Processing Linux/Unix – AMS 2019 o The Unix File System Pete Pokrandt o Working with Files and Directories o The vi editor UW-Madison AOS Systems Administrator o Your Environment [email protected] o Common Commands Twitter @PTH1 History of Unix History of Unix History of Unix o Created in 1969 by Kenneth Thompson and Dennis o Today – two main variants, but blended o It’s been around for a long time Ritchie at AT&T o Revised in-house until first public release 1977 o System V (Sun Solaris, SGI, Dec OSF1, AIX, o It was written by computer programmers for o 1977 – UC-Berkeley – Berkeley Software Distribution (BSD) linux) computer programmers o 1983 – Sun Workstations produced a Unix Workstation o BSD (Old SunOS, linux, Mac OSX/MacOS) o Case sensitive, mostly lowercase o AT&T unix -> System V abbreviations 1 Basics of a Unix Login Session Basics of a Unix Login Session Basics of a Unix Login Session o The Shell – the command line interface, o Features provided by the shell o Logging in to a unix session where you enter commands, etc n Create an environment that meets your needs n login: username n Some common shells n Write shell scripts (batch files) n password: tImpAw$ n Define command aliases (this Is my password At work $) Bourne Shell (sh) OR n Manipulate command history IHateHaving2changeMypasswordevery3weeks!!! C Shell (csh) n Automatically complete the command -

IBM Cognos Analytics - Reporting Version 11.1
IBM Cognos Analytics - Reporting Version 11.1 User Guide IBM © Product Information This document applies to IBM Cognos Analytics version 11.1.0 and may also apply to subsequent releases. Copyright Licensed Materials - Property of IBM © Copyright IBM Corp. 2005, 2021. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. IBM, the IBM logo and ibm.com are trademarks or registered trademarks of International Business Machines Corp., registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the Web at " Copyright and trademark information " at www.ibm.com/legal/copytrade.shtml. The following terms are trademarks or registered trademarks of other companies: • Adobe, the Adobe logo, PostScript, and the PostScript logo are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States, and/or other countries. • Microsoft, Windows, Windows NT, and the Windows logo are trademarks of Microsoft Corporation in the United States, other countries, or both. • Intel, Intel logo, Intel Inside, Intel Inside logo, Intel Centrino, Intel Centrino logo, Celeron, Intel Xeon, Intel SpeedStep, Itanium, and Pentium are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. • Linux is a registered trademark of Linus Torvalds in the United States, other countries, or both. • UNIX is a registered trademark of The Open Group in the United States and other countries. • Java and all Java-based trademarks and logos are trademarks or registered trademarks of Oracle and/or its affiliates. -

The GNOME Census: Who Writes GNOME?
The GNOME Census: Who writes GNOME? Dave Neary & Vanessa David, Neary Consulting © Neary Consulting 2010: Some rights reserved Table of Contents Introduction.........................................................................................3 What is GNOME?.............................................................................3 Project governance...........................................................................3 Why survey GNOME?.......................................................................4 Scope and methodology...................................................................5 Tools and Observations on Data Quality..........................................7 Results and analysis...........................................................................10 GNOME Project size.......................................................................10 The Long Tail..................................................................................11 Effects of commercialisation..........................................................14 Who does the work?.......................................................................15 Who maintains GNOME?................................................................17 Conclusions........................................................................................22 References.........................................................................................24 Appendix 1: Modules included in survey...........................................25 2 Introduction What