Unicodemath a Nearly Plain-Text Encoding of Mathematics Version 3.1 Murray Sargent III Microsoft Corporation 16-Nov-16
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Unicode Nearly Plain-Text Encoding of Mathematics Murray Sargent III Office Authoring Services, Microsoft Corporation 4-Apr-06
Unicode Nearly Plain Text Encoding of Mathematics Unicode Nearly Plain-Text Encoding of Mathematics Murray Sargent III Office Authoring Services, Microsoft Corporation 4-Apr-06 1. Introduction ............................................................................................................ 2 2. Encoding Simple Math Expressions ...................................................................... 3 2.1 Fractions .......................................................................................................... 4 2.2 Subscripts and Superscripts........................................................................... 6 2.3 Use of the Blank (Space) Character ............................................................... 7 3. Encoding Other Math Expressions ........................................................................ 8 3.1 Delimiters ........................................................................................................ 8 3.2 Literal Operators ........................................................................................... 10 3.3 Prescripts and Above/Below Scripts........................................................... 11 3.4 n-ary Operators ............................................................................................. 11 3.5 Mathematical Functions ............................................................................... 12 3.6 Square Roots and Radicals ........................................................................... 13 3.7 Enclosures..................................................................................................... -

Customizing and Extending Powerdesigner SAP Powerdesigner Documentation Collection Content
User Guide PUBLIC SAP PowerDesigner Document Version: 16.6.2 – 2017-01-05 Customizing and Extending PowerDesigner SAP PowerDesigner Documentation Collection Content 1 PowerDesigner Resource Files.................................................... 9 1.1 Opening Resource Files in the Editor.................................................10 1.2 Navigating and Searching in Resource Files............................................ 11 1.3 Editing Resource Files........................................................... 13 1.4 Saving Changes................................................................13 1.5 Sharing and Embedding Resource Files...............................................13 1.6 Creating and Copying Resource Files.................................................14 1.7 Specifying Directories to Search for Resource Files.......................................15 1.8 Comparing Resource Files........................................................ 15 1.9 Merging Resource Files.......................................................... 16 2 Extension Files................................................................18 2.1 Creating an Extension File.........................................................19 2.2 Attaching Extensions to a Model....................................................20 2.3 Exporting an Embedded Extension File for Sharing.......................................21 2.4 Extension File Properties......................................................... 21 2.5 Example: Adding a New Attribute from a Property -

IPBES Workshop on Biodiversity and Pandemics Report
IPBES Workshop on Biodiversity and Pandemics WORKSHOP REPORT *** Strictly Confidential and Embargoed until 3 p.m. CET on 29 October 2020 *** Please note: This workshop report is provided to you on condition of strictest confidentiality. It must not be shared, cited, referenced, summarized, published or commented on, in whole or in part, until the embargo is lifted at 3 p.m. CET/2 p.m. GMT/10 a.m. EDT on Thursday, 29 October 2020 This workshop report is released in a non-laid out format. It will undergo minor editing before being released in a laid-out format. Intergovernmental Platform on Biodiversity and Ecosystem Services 1 The IPBES Bureau and Multidisciplinary Expert Panel (MEP) authorized a workshop on biodiversity and pandemics that was held virtually on 27-31 July 2020 in accordance with the provisions on “Platform workshops” in support of Plenary- approved activities, set out in section 6.1 of the procedures for the preparation of Platform deliverables (IPBES-3/3, annex I). This workshop report and any recommendations or conclusions contained therein have not been reviewed, endorsed or approved by the IPBES Plenary. The workshop report is considered supporting material available to authors in the preparation of ongoing or future IPBES assessments. While undergoing a scientific peer-review, this material has not been subjected to formal IPBES review processes. 2 Contents 4 Preamble 5 Executive Summary 12 Sections 1 to 5 14 Section 1: The relationship between people and biodiversity underpins disease emergence and provides opportunities -

Package Mathfont V. 1.6 User Guide Conrad Kosowsky December 2019 [email protected]
Package mathfont v. 1.6 User Guide Conrad Kosowsky December 2019 [email protected] For easy, off-the-shelf use, type the following in your docu- ment preamble and compile using X LE ATEX or LuaLATEX: \usepackage[hfont namei]{mathfont} Abstract The mathfont package provides a flexible interface for changing the font of math- mode characters. The package allows the user to specify a default unicode font for each of six basic classes of Latin and Greek characters, and it provides additional support for unicode math and alphanumeric symbols, including punctuation. Crucially, mathfont is compatible with both X LE ATEX and LuaLATEX, and it provides several font-loading commands that allow the user to change fonts locally or for individual characters within math mode. Handling fonts in TEX and LATEX is a notoriously difficult task. Donald Knuth origi- nally designed TEX to support fonts created with Metafont, and while subsequent versions of TEX extended this functionality to postscript fonts, Plain TEX's font-loading capabilities remain limited. Many, if not most, LATEX users are unfamiliar with the fd files that must be used in font declaration, and the minutiae of TEX's \font primitive can be esoteric and confusing. LATEX 2"'s New Font Selection System (nfss) implemented a straightforward syn- tax for loading and managing fonts, but LATEX macros overlaying a TEX core face the same versatility issues as Plain TEX itself. Fonts in math mode present a double challenge: after loading a font either in Plain TEX or through the nfss, defining math symbols can be unin- tuitive for users who are unfamiliar with TEX's \mathcode primitive. -

Writing Mathematical Expressions in Plain Text – Examples and Cautions Copyright © 2009 Sally J
Writing Mathematical Expressions in Plain Text – Examples and Cautions Copyright © 2009 Sally J. Keely. All Rights Reserved. Mathematical expressions can be typed online in a number of ways including plain text, ASCII codes, HTML tags, or using an equation editor (see Writing Mathematical Notation Online for overview). If the application in which you are working does not have an equation editor built in, then a common option is to write expressions horizontally in plain text. In doing so you have to format the expressions very carefully using appropriately placed parentheses and accurate notation. This document provides examples and important cautions for writing mathematical expressions in plain text. Section 1. How to Write Exponents Just as on a graphing calculator, when writing in plain text the caret key ^ (above the 6 on a qwerty keyboard) means that an exponent follows. For example x2 would be written as x^2. Example 1a. 4xy23 would be written as 4 x^2 y^3 or with the multiplication mark as 4*x^2*y^3. Example 1b. With more than one item in the exponent you must enclose the entire exponent in parentheses to indicate exactly what is in the power. x2n must be written as x^(2n) and NOT as x^2n. Writing x^2n means xn2 . Example 1c. When using the quotient rule of exponents you often have to perform subtraction within an exponent. In such cases you must enclose the entire exponent in parentheses to indicate exactly what is in the power. x5 The middle step of ==xx52− 3 must be written as x^(5-2) and NOT as x^5-2 which means x5 − 2 . -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

The Braillemathcodes Repository
Proceedings of the 4th International Workshop on "Digitization and E-Inclusion in Mathematics and Science 2021" DEIMS2021, February 18–19, 2021, Tokyo _________________________________________________________________________________________ The BrailleMathCodes Repository Paraskevi Riga1, Theodora Antonakopoulou1, David Kouvaras1, Serafim Lentas1, and Georgios Kouroupetroglou1 1National and Kapodistrian University of Athens, Greece Speech and Accessibility Laboratory, Department of Informatics and Telecommunications [email protected], [email protected], [email protected], [email protected], [email protected] Abstract Math notation for the sighted is a global language, but this is not the case with braille math, as different codes are in use worldwide. In this work, we present the design and development of a math braille-codes' repository named BrailleMathCodes. It aims to constitute a knowledge base as well as a search engine for both students who need to find a specific symbol code and the editors who produce accessible STEM educational content or, in general, the learner of math braille notation. After compiling a set of mathematical braille codes used worldwide in a database, we assigned the corresponding Unicode representation, when applicable, matched each math braille code with its LaTeX equivalent, and forwarded with Presentation MathML. Every math symbol is accompanied with a characteristic example in MathML and Nemeth. The BrailleMathCodes repository was designed following the Web Content Accessibility Guidelines. Users or learners of any code, both sighted and blind, can search for a term and read how it is rendered in various codes. The repository was implemented as a dynamic e-commerce website using Joomla! and VirtueMart. 1 Introduction Braille constitutes a tactile writing system used by people who are visually impaired. -

The Nth Root of a Number Page 1
Lecture Notes The nth Root of a Number page 1 Caution! Currently, square roots are dened differently in different textbooks. In conversations about mathematics, approach the concept with caution and rst make sure that everyone in the conversation uses the same denition of square roots. Denition: Let A be a non-negative number. Then the square root of A (notation: pA) is the non-negative number that, if squared, the result is A. If A is negative, then pA is undened. For example, consider p25. The square-root of 25 is a number, that, when we square, the result is 25. There are two such numbers, 5 and 5. The square root is dened to be the non-negative such number, and so p25 is 5. On the other hand, p 25 is undened, because there is no real number whose square, is negative. Example 1. Evaluate each of the given numerical expressions. a) p49 b) p49 c) p 49 d) p 49 Solution: a) p49 = 7 c) p 49 = unde ned b) p49 = 1 p49 = 1 7 = 7 d) p 49 = 1 p 49 = unde ned Square roots, when stretched over entire expressions, also function as grouping symbols. Example 2. Evaluate each of the following expressions. a) p25 p16 b) p25 16 c) p144 + 25 d) p144 + p25 Solution: a) p25 p16 = 5 4 = 1 c) p144 + 25 = p169 = 13 b) p25 16 = p9 = 3 d) p144 + p25 = 12 + 5 = 17 . Denition: Let A be any real number. Then the third root of A (notation: p3 A) is the number that, if raised to the third power, the result is A. -

Math Symbol Tables
APPENDIX A I Math symbol tables A.I Hebrew letters Type: Print: Type: Print: \aleph ~ \beth :J \daleth l \gimel J All symbols but \aleph need the amssymb package. 346 Appendix A A.2 Greek characters Type: Print: Type: Print: Type: Print: \alpha a \beta f3 \gamma 'Y \digamma F \delta b \epsilon E \varepsilon E \zeta ( \eta 'f/ \theta () \vartheta {) \iota ~ \kappa ,.. \varkappa x \lambda ,\ \mu /-l \nu v \xi ~ \pi 7r \varpi tv \rho p \varrho (} \sigma (J \varsigma <; \tau T \upsilon v \phi ¢ \varphi 'P \chi X \psi 'ljJ \omega w \digamma and \ varkappa require the amssymb package. Type: Print: Type: Print: \Gamma r \varGamma r \Delta L\ \varDelta L.\ \Theta e \varTheta e \Lambda A \varLambda A \Xi ~ \varXi ~ \Pi II \varPi II \Sigma 2: \varSigma E \Upsilon T \varUpsilon Y \Phi <I> \varPhi t[> \Psi III \varPsi 1ft \Omega n \varOmega D All symbols whose name begins with var need the amsmath package. Math symbol tables 347 A.3 Y1EX binary relations Type: Print: Type: Print: \in E \ni \leq < \geq >'" \11 « \gg \prec \succ \preceq \succeq \sim \cong \simeq \approx \equiv \doteq \subset c \supset \subseteq c \supseteq \sqsubseteq c \sqsupseteq \smile \frown \perp 1- \models F \mid I \parallel II \vdash f- \dashv -1 \propto <X \asymp \bowtie [Xl \sqsubset \sqsupset \Join The latter three symbols need the latexsym package. 348 Appendix A A.4 AMS binary relations Type: Print: Type: Print: \leqs1ant :::::; \geqs1ant ): \eqs1ant1ess :< \eqs1antgtr :::> \lesssim < \gtrsim > '" '" < > \lessapprox ~ \gtrapprox \approxeq ~ \lessdot <:: \gtrdot Y \111 «< \ggg »> \lessgtr S \gtr1ess Z < >- \lesseqgtr > \gtreq1ess < > < \gtreqq1ess \lesseqqgtr > < ~ \doteqdot --;- \eqcirc = .2.. -

The Recent Trademarking of Pi: a Troubling Precedent
The recent trademarking of Pi: a troubling precedent Jonathan M. Borwein∗ David H. Baileyy July 15, 2014 1 Background Intellectual property law is complex and varies from jurisdiction to jurisdiction, but, roughly speaking, creative works can be copyrighted, while inventions and processes can be patented, and brand names thence protected. In each case the intention is to protect the value of the owner's work or possession. For the most part mathematics is excluded by the Berne convention [1] of the World Intellectual Property Organization WIPO [12]. An unusual exception was the successful patenting of Gray codes in 1953 [3]. More usual was the carefully timed Pi Day 2012 dismissal [6] by a US judge of a copyright infringement suit regarding π, since \Pi is a non-copyrightable fact." We mathematicians have largely ignored patents and, to the degree we care at all, have been more concerned about copyright as described in the work of the International Mathematical Union's Committee on Electronic Information and Communication (CEIC) [2].1 But, as the following story indicates, it may now be time for mathematicians to start paying attention to patenting. 2 Pi period (π:) In January 2014, the U.S. Patent and Trademark Office granted Brooklyn artist Paul Ingrisano a trademark on his design \consisting of the Greek letter Pi, followed by a period." It should be noted here that there is nothing stylistic or in any way particular in Ingrisano's trademark | it is simply a standard Greek π letter, followed by a period. That's it | π period. No one doubts the enormous value of Apple's partly-eaten apple or the MacDonald's arch. -
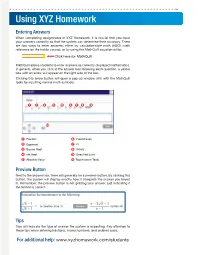
Using XYZ Homework
Using XYZ Homework Entering Answers When completing assignments in XYZ Homework, it is crucial that you input your answers correctly so that the system can determine their accuracy. There are two ways to enter answers, either by calculator-style math (ASCII math reference on the inside covers), or by using the MathQuill equation editor. Click here for MathQuill MathQuill allows students to enter answers as correctly displayed mathematics. In general, when you click in the answer box following each question, a yellow box with an arrow will appear on the right side of the box. Clicking this arrow button will open a pop-up window with with the MathQuill tools for inputting normal math symbols. 1 2 3 4 5 6 7 8 9 10 1 Fraction 6 Parentheses 2 Exponent 7 Pi 3 Square Root 8 Infinity 4 nth Root 9 Does Not Exist 5 Absolute Value 10 Touchscreen Tools Preview Button Next to the answer box, there will generally be a preview button. By clicking this button, the system will display exactly how it interprets the answer you keyed in. Remember, the preview button is not grading your answer, just indicating if the format is correct. Tips Tips will indicate the type of answer the system is expecting. Pay attention to these tips when entering fractions, mixed numbers, and ordered pairs. For additional help: www.xyzhomework.com/students ASCII Math (Calculator Style) Entry Some question types require a mathematical expression or equation in the answer box. Because XYZ Homework follows order of operations, the use of proper grouping symbols is necessary. -

Using Lexical Tools to Convert Unicode Characters to ASCII
Using Lexical Tools to Convert Unicode Characters to ASCII Chris J. Lu, Ph.D.1, Allen C. Browne2, Divita Guy1 1Lockheed Martin/MSD, Bethesda, MD; 2National Library of Medicine, Bethesda, MD Abstract 2-3. Recursive algorithm Some Unicode characters require multiple steps, combining Unicode is an industry standard allowing computers to the methods described above, in ASCII conversion. A consistently represent and manipulate text expressed in recursive algorithm is implemented in LVG flow, -f:q7, for most of the world’s writing systems. It is widely used in this purpose. multilingual NLP (natural language processing) projects. On the other hand, there are some NLP projects still only 2-4. Table lookup mapping and strip dealing with ASCII characters. This paper describes Some Unicode characters do not belong to categories methods of utilizing lexical tools to convert Unicode mentioned above. A local table of conversion values is characters (UTF-8) to ASCII (7-bit) characters. used to convert these to an ASCII representation. For example, Greek letters are converted into fully spelled out 1. Introduction forms. ‘α’ is converted to “alpha”. Non-defined Unicode The SPECIALIST Lexical tools, 2008, distributed by characters, (such as ™, ©, ®, etc.), are treated as National Library of Medicine (NLM) provide several stopwords and stripped out completely to ensure pure functions, called LVG (Lexical Variant Generation) flow ASCII conversion. This table lookup and strip function is components, to convert Unicode characters to ASCII. In represented by LVG flow, -f:q8. general, ASCII conversion either preserves semantic and/or 2-5. Pure ASCII conversions graphic representation or facilitates NLP.