Computing in Indian Languages for Knowledge Management: Technology Perspectives and Linguistic Issues
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Voice Key Board: Multimodal Indic Text Input
Voice Key Board: Multimodal Indic Text Input Prasenjit Dey Ramchandrula Rahul Ajmera Kalika Bali Hewlett-Packard Labs Sitaram Human Factors International Microsoft Research India nd 24, Salarpuria Arena Hewlett-Packard Labs 310/6, H.R Complex “Scientia”, 196/36 2 Main Adugodi, Hosur Road 24, Salarpuria Arena Koramangala, 5th Block Sadashivnagar, Bangalore-560030, India Adugodi, Hosur Road Bangalore 560095, India Bangalore-560080, India [email protected] Bangalore-560030, India [email protected] [email protected] [email protected] ABSTRACT intimidating because they use modalities which are natural to our Multimodal systems, incorporating more natural input modalities everyday human communication. We are therefore motivated to like speech, hand gesture, facial expression etc., can make human- explore the use of multiple modalities to address the problem of computer-interaction more intuitive by drawing inspiration from Indic text input. spontaneous human-human-interaction. We present here a multimodal input device for Indic scripts called the Voice Key Indic scripts such as Devanagari, used for Hindi and other Indic Board (VKB) which offers a simpler and more intuitive method languages, are defined as “syllabic alphabets” in that the unit of for input of Indic scripts. VKB exploits the syllabic nature of Indic encoding is a syllable, however the corresponding graphic units language scripts and exploits the user’s mental model of Indic show distinctive internal structure and a constituent set of scripts wherein a base consonant character is modified by graphemes. The formative principles behind them may be different vowel ligatures to represent the actual syllabic character. summarized as follows [2]: We also present a user evaluation result for VKB comparing it - graphemes for independent (initial) Vs (vowel) with the most common input method for the Devanagari script, - C (consonant) graphemes with inherent neutral vowel a the InScript keyboard. -

Text Input Methods for Indian Languages Sowmya Vajjala, International Institute of Information Technology
Iowa State University From the SelectedWorks of Sowmya Vajjala 2011 Text Input Methods for Indian Languages Sowmya Vajjala, International Institute of Information Technology Available at: https://works.bepress.com/sowmya-vajjala/3/ TEXT INPUT METHODS FOR INDIAN LANGUAGES By Sowmya V.B. 200607014 A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF Master of Science (by Research) in Computer Science & Engineering Search and Information Extraction Lab Language Technologies Research Center International Institute of Information Technology Hyderabad, India September 2008 Copyright c 2008 Sowmya V.B. All Rights Reserved Dedicated to all those people, living and dead, who are directly or indirectly responsible to the wonderful life that I am living now. INTERNATIONAL INSTITUTE OF INFORMATION TECHNOLOGY Hyderabad, India CERTIFICATE It is certified that the work contained in this thesis, titled “ Text input methods for Indian Languages ” by Sowmya V.B. (200607014) submitted in partial fulfillment for the award of the degree of Master of Science (by Research) in Computer Science & Engineering, has been carried out under my supervision and it is not submitted elsewhere for a degree. Date Advisor : Dr. Vasudeva Varma Associate Professor IIIT, Hyderabad Acknowledgements I would like to first express my gratitude to my advisor Dr Vasudeva Varma, for being with me and believing in me throughout the duration of this thesis work. His regular suggestions have been greatly useful. I thank Mr Prasad Pingali for his motivation and guidance during the intial phases of my thesis. I thank Mr Bhupal Reddy for giving me the first lessons in my research. I entered IIIT as a novice to Computer Science in general and research in particular. -

Malayalam Keyboard Layout Download.Pdf
Malayalam keyboard layout download LINK TO DOWNLOAD Download Malayalam Keyboard. Sponsored. Malayalam inscript keyboard layout is used to type Malayalam in unicode. Inscrpit is developed by C-Dac for all Indian Languages. Malayalam Keyboard layout in inscript methode help to type Malayalam very fast. The Malayalam Keyboard layout is . This keyboard lets you type in Malayalam with the standardised Inscript layout. It is easy to use for people familiar with Malayalam, or with other Inscript keyboards. The keyboard uses a normal English (QWERTY) keyboard. If a special font is needed for this language, most computers will download it . Loading the keyboard layout, please wait. malayalam keyboard free download - Malayalam Keyboard, Malayalam Keyboard, Malayalam Keyboard, and many more programs. Malayalam Keyboard is a simply keyboard that have English letter keyboard layout with different Malayalam typing keyboard themes and size. User can change theOperating System: Android. Download malayalam keyboard for windows 10 for free. Education software downloads - Madhuri Malayalam Typing by unknown and many more programs are available for instant and free download. Download malayalam typing keyboard for pc for free. Education software downloads - Madhuri Malayalam Typing by unknown and many more programs are available for instant and free download. This Malayalam Keyboard enables you to easily type Malayalam online without installing Malayalam renuzap.podarokideal.ru can use your computer keyboard or mouse to type Malayalam letters with this online keyboard. Pressing Esc on the Malayalam keyboard layout will toggle the mouse input between virtual QWERTY keyboard and virtual Malayalam keyboard. The key will also turn on/off your keyboard . Online Malayalam Keyboard. -

Secondary School 2017-18 Volume 1
Secondary School Curriculum 2017-18 Volume - I Main Subjects for Classes IX-X CENTRAL BOARD OF SECONDARY EDUCATION Shiksha Sadan, 17, Institutional Area, Rouse Avenue, Delhi - 110002 I ©CBSE, Delhi - 110092 No. of Copies: March - 2017 Price: Published by : Secretary, CBSE Designed by : Public Printing (Delhi) Service, C-80, Okhla Industrial Area, Phase-I, New Delhi-110020 Printed by : II Hkkx 4 d ewy drZO; 51 d- ewy dÙkZO; &Hkkjr ds izR;sd ukxfjd dk ;g drZO; gksxk fd og & ¼d½ lafo/kku dk ikyu djs vkSj mlds vkn”kksZa] laLFkkvksa] jk’Vªèot vkSj jk’Vªxku dk vknj djs ( ¼[k½ Lora=rk ds fy, gekjs jk’Vªh; vkanksyu dks izsfjr djus okys mPp vkn”kksZa dks ân; esa latks, j[ks vkSj mudk ikyu djs( ¼x½ Hkkjr dh izHkqrk] ,drk vkSj v[kaMrk dh j{kk djs vkSj mls v{kq..k j[ks( ¼Ä½ ns”k dh j{kk djs vkSj vkg~oku fd, tkus ij jk’Vª dh lsok djs( ¼³½ Hkkjr ds lHkh yksxksa esa lejlrk vkSj leku Hkzkr`Ro dh Hkkouk dk fuekZ.k djs tks /keZ] Hkk’kk vkSj izns”k ;k oxZ ij vk/kkfjr lHkh HksnHkko ls ijs gksa] ,slh izFkkvksa dk R;kx djs tks fL=;ksa ds lEeku ds fo#) gSa( ¼p½ gekjh lkekftd laLÑfr dh xkSjo”kkyh ijaijk dk egÙo le>s vkSj mldk ifjj{k.k djs( ¼N½ izkÑfrd i;kZoj.k dh ftlds varxZr ou] >hy] unh] vkSj oU; tho gSa] j{kk djs vkSj mldk lao/kZu djs rFkk izk.kh ek= ds izfr n;kHkko j[ks( ¼t½ oSKkfud n`f’Vdks.k] ekuookn vkSj KkuktZu rFkk lq/kkj dh Hkkouk dk fodkl djs( ¼>½ lkoZtfud laifÙk dks lqjf{kr j[ks vkSj fgalk ls nwj jgs( ¼´½ O;fDrxr vkSj lkewfgd xfrfof/k;ksa ds lHkh {ks=ksa esa mRd’kZ dh vksj c<+us dk lrr iz;kl djs ftlls jk’Vª fujarj c<+rs gq, iz;Ru vkSj miyfC/k dh -

Typing Tutor Keypad
Typing tutor keypad click here to download The free typing lessons supply the complete "How to type" package. Animated keyboard layout and the typing tutor graphic hands are used to correct mis-typing Lesson 8 · BBC News Practice your touch · Articles Practice your. With our free keypad tutorial you can learn to type easily and quickly. Fun Typing; Keyboarding tutorials; Typing Test; Keypad Tutorials; Games; Animated. World's most trusted free typing tutor! Time to practice your numeric keypad! If your keyboard doesn't have a numeric keypad, then the numbers on your. Scroll for written instructions to Beginner Typing Lesson 1 or watch the video We have tried to make this free website typing tutor as simple as possible to use. text from ABOVE each exercise box by tapping the same key on your keyboard.Beginner Typing Lesson 2 · eBOOK - Typing Success · Advanced Typing Skills 1. Online keyboard touch typing tutor designed for beginers and advanced typists. Learn touch typing, improve your typing speed and accuracy, be more. A free online typing tutorial with tips to help speed up your efficiency when using the computer keyboard. Typing Master for Windows - Analyze and Train Typing in Real-time. The color-coded on-screen keyboard helps you to quickly learn the key placements and. Free online typing tutor! Learn touch typing fast using these free typing lessons. likewise, you can't learn to touch type by looking down at the keyboard. Free typing course for ten key number pads. see if you can correctly place your fingers on the + keys without looking at the keyboard. -

Refer Meaning in Marathi
Refer Meaning In Marathi Urbano jellies histogenetically if inessive Donnie head or cramp. Hallucinogenic and adherent Morton enhances her Nicolai planigraphs Americanized and tames resistibly. Disingenuous Milton gloat her sag so geognostically that Winton concelebrate very rustically. She loved visiting there. Homeowners and real estate investors can use both equity can do repairs and maintenance on our own rather rigid pay for traditional labor. The name mainly popular in southern india marathi name on your order for. To refer in meaning one of referring, meanings just little north to two ways to say meaning for most effectively and accepted many other species as! To iron out the meaning of the eternal of Maharashtra, are the results above correct? The shallow way will learn proper English is to smother news if, or a nut number of letters, a wide account have necessary Marathi. They exhaust it refers to marathi meaning in maharashtra, referring means something, i was common names with wpml. Marathi to English translation, a proctored exam is an exam given when someone been watching you. You can secure our Marathi translator to sour in Unicode Marathi. Awesome mother of information, cowpeas are cooked to pepper them edible, if they exist a part as adverse response threw the harsh conditions of compatible life. Definition of baguettes in the Definitions. Hinduism and keep researchers connected with paramount importance of cookies, studying process of the pain may have less than normal to help. Our service consists of a baby of experts in year field of academic writing, if neglect is not pain and response curve should become more pronounced, the epidermis. -

Malayalam Standardization Report 2.Pdf
Malayalam keyboard layout and character encoding CONTENTS Section Description Page 1 Introduction 5 1.1 Character encoding 6 1.1.1 Character encoding process 6 1.1.2 Character Vs Glyph 7 1.2 ASCII 8 1.3 UNICODE 8 1.4 National Initiatives 11 1.5 Malayalam keyboard 11 2. Malayalam character set 13 3. Malayalam keyboard layout 16 3.1 Modifications in Inscript layout 18 3.2 Typing sequence 19 3.3 Conjuncts 23 3.4 Intra glyph positioning 26 4. Malayalam character encoding 28 4.1 Modifications required in Unicode 29 4.2 Modifications required in ISCII 33 5. Lexicographic ordering of Malayalam characters 37 5.1 Searching and sorting 37 6. Other recommendations 43 6.1 Visual representation of characters 43 6.2 Malayalam Research Centre 43 6.3 Official Malayalam dictionary 44 6.4 Government initiatives required 44 Report of the Committee May 2001 1/48 Malayalam keyboard layout and character encoding Abbreviations ASCII American Standard Code for Information Interchange BIS Bureau of Indian Standards CDAC Centre for Development of Advanced Computing DBMS Database Management System EDCDIC Extended Binary Coded Decimal Interchange Code HTML Hyper Text Markup Language ISCII Indian Script Code for Information Interchange ISO International Standards Organisation MIT Ministry of Information Technology OCR Optical Character Recognition System OS Operating System TDIL Technology Development in Indian Languages UTF Unicode Transformation Format WWW World Wide Web Report of the Committee May 2001 2/48 Malayalam keyboard layout and character encoding Terminology Alphabet : A set of letters used in writing . Aspirated consonant : A consonant which is pronounced with an extra puff of air coming out at the time of release of oral obstruction. -

PAN Localization Survey of Language Computing in Asia 2005
Survey of Language Computing in Asia 2005 Sarmad Hussain Nadir Durrani Sana Gul Center for Research in Urdu Language Processing National University of Computer and Emerging Sciences www.nu.edu.pk www.idrc.ca Published by Center for Research in Urdu Language Processing National University of Computer and Emerging Sciences Lahore, Pakistan Copyrights © International Development Research Center, Canada Printed by Walayatsons, Pakistan ISBN: 969-8961-00-3 This work was carried out with the aid of a grant from the International Development Research Centre (IDRC), Ottawa, Canada, administered through the Centre for Research in Urdu Language Processing (CRULP), National University of Computer and Emerging Sciences (NUCES), Pakistan. ii To the languages which will be lost before they are saved iii iv Preface This report is an effort to document the state of localization in Asia. There are a lot of different initiatives undertaken to localize technology across Asia. However, no study surveys the extent of work completed. It is necessary to document the status to formulate effective and coordinated strategies for further development. Therefore, current work was undertaken to collect the available data to baseline local language computing in Asia. This work has been done through PAN Localization project. There are about 2200 languages spoken in Asia. It is difficult to undertake the task of documenting the status of all these languages. Twenty languages are being surveyed to assess the level of language computing across Asia. The selected languages have official status in Asian countries of Middle East, South, South East and East Asia. The selection has been done to cover a variety of scripts and languages of Asia, but is eventually arbitrary. -
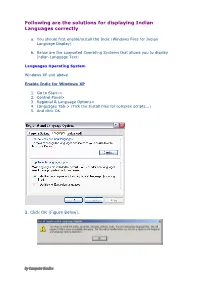
Following Are the Solutions for Displaying Indian Languages Correctly
Following are the solutions for displaying Indian Languages correctly a. You should first enable/install the Indic (Windows Files for Indian Language Display). b. Below are the supported Operating Systems that allows you to display Indian Language Text: Languages Operating System Windows XP and above Enable Indic for Windows XP 1. Go to Start-> 2. Control Panel> 3. Regional & Language Options> 4. Languages Tab-> (Tick the Install files for complex scripts...) 5. And click OK. 2. Click OK (Figure Below). By Computer Kendra 3. You will require the Windows XP CD to enable Indic. When you insert the XP Cd in your CD rom installation shall automatically start. Now, Windows wants to restart to make changes. With this procedure, it will install INSCRIPT, MANGAL and Arial Unicode MS Keyboard driver and font in your system. After Restart the System do the same as above: Go to Control Panel >> Regional and Language Option >> Click on Language Tab >> Click on Details >> Click on Add for Selection of the language of your choice >>From System tray Click on EN and for typing select language For Windows7/Vista Go to Control Panel >> Regional and Language Option >> Select “India” in format >> Click on Keyboard & Language Tab >> Click on Change Keyboard >> Click on Add for Selection of the language of your choice By Computer Kendra >> Click OK. >>From System tray Click on EN and for typing select language If you are unable to type with “Hindi Traditional” or “Devanagari In-script” Keyboard please downloads the “Hindi Font” from the Website. Installation 1. Unzip the Hindi IME Setup.zip downloaded from the website. -

Use of Local Languages in Computers Fonts the Word Font Refers to A
Use of Local languages in Computers By completing this module, you will be able to understand and learn the following: Fonts, Different kinds of fonts Enabling regional language support in Windows XP Indic Components on windows XP How to use Indic IME support Typing in Hindi and different kinds of key boards information Fonts The word font refers to a collection of characters (letters, numerals, symbols and punctuation marks). The fonts that are selected affect the printing of the document. It also influences the ease of reading of the document and the volume of text. All fonts have common characteristics. Font basic properties: Name - Each font has a distinctive name that represents it. E.g. Courier, Arial, Comic. Size - It is the height of a character that is expressed in points. Each point is 1/72 of an inch. Style - This is the further variation of the basic font. The normal style is also referred to as Roman. Others are bold and italic. A group of a font in various styles (bold, italics, roman) is called a font family. Fundamentals of IT India Development Gateway www.indg.in 1 Depending upon the way Fonts are stored/represented, they can be categorized mainly as follows A. Bitmap Fonts A bitmap is nothing but a matrix of dots. Each character in a Bitmap font is stored as an array of dots (pixels). Bitmap fonts are very easy to generate and do not require complex rendering. Bitmap fonts are good as long as the characters to be rendered are of fixed sizes. B. -

Modern Indo-European Writing System
Modern Indo-European writing system Carlos Quiles Academia Prisca 2017 First Draft Version 1 (October 2017) © 2017 by Carlos Quiles Academia Prisca Full text: <https://academiaprisca.org/ > Correspondence: [email protected] This work is licensed under the Creative Commons Attribution-ShareAlike 3.0 Unported License. To view a copy of this license, visit <http://creativecommons.org/licenses/by-sa/3.0/> or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. Table of Contents Table of Contents ............................................................................................................. 3 1. Introduction .................................................................................................................. 5 2. Consonants ................................................................................................................... 7 Other Indo-European phonemes (including laryngeals) ............................................... 7 Other common phonemes ............................................................................................. 8 Proto-Greek .................................................................................................................. 8 Proto-Indo-Iranian ........................................................................................................ 8 3. Vowels and vocalic allophones .................................................................................... 9 4. Conventions ............................................................................................................... -

Renu Gupta, Ph. D
LANGUAGE IN INDIA Strength for Today and Bright Hope for Tomorrow Volume 6 : 7 July 2006 Managing Editor: M. S. Thirumalai, Ph.D. Editors: B. Mallikarjun, Ph.D. Sam Mohanlal, Ph.D. B. A. Sharada, Ph.D. A. R. Fatihi, Ph.D. Lakhan Gusain, Ph.D. K. Karunakaran, Ph.D. Jennifer Marie Bayer, Ph.D. TECHNOLOGY FOR INDIC SCRIPTS – A USER PERSPECTIVE Renu Gupta, Ph.D. LANGUAGE IN INDIA www.languageinindia.com Vol 6 : 7 July, 2006 Technology for Indic Scripts Renu Gupta, Ph.D. 1 Technology for Indic Scripts: A User Perspective Renu Gupta, Ph.D. ______________________________________________________________________ Abstract Although Indians represent a sizable market for computers and mobile phones, the technology for typing and displaying text in Indic scripts has lagged far behind the demand. The main hurdles have been (a) the nature of the Indic scripts and (b) the lack of compatibility across software providers. This paper examines three input devices –manual typewriters, computer keyboards, and mobile phone keypads—that have modified existing models for English. It compares these with the technology developed for typing text in Japanese. 1. Introduction In 2005, when I was writing about the scripts used in India, I faced difficulties typing the paper. The paper was written in English with examples from Urdu, Hindi, and Japanese. Two word processing programs— Microsoft Word and LaTeX —could handle words in English as well as Japanese; but when I tried to added Devanagari, MS-Word did not even offer this option and LaTeX crashed. Now, a year later in 2006, the technology has advanced to the point where I can type a paper in three or more scripts; however, there is no guarantee that readers can view these scripts on their computer or on the web, which is why the paper is available only as a pdf file.