Blind Image Denoising Using Supervised and Unsupervised Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

NTGAN: Learning Blind Image Denoising Without Clean Reference
RUI ZHAO, DANIEL P.K. LUN, KIN-MAN LAM: NTGAN 1 NTGAN: Learning Blind Image Denoising without Clean Reference Rui Zhao Department of Electronic and [email protected] Information Engineering, Daniel P.K. Lun The Hong Kong Polytechnic University, [email protected] Hong Kong, China Kin-Man Lam [email protected] Abstract Recent studies on learning-based image denoising have achieved promising perfor- mance on various noise reduction tasks. Most of these deep denoisers are trained ei- ther under the supervision of clean references, or unsupervised on synthetic noise. The assumption with the synthetic noise leads to poor generalization when facing real pho- tographs. To address this issue, we propose a novel deep unsupervised image-denoising method by regarding the noise reduction task as a special case of the noise transference task. Learning noise transference enables the network to acquire the denoising ability by only observing the corrupted samples. The results on real-world denoising benchmarks demonstrate that our proposed method achieves state-of-the-art performance on remov- ing realistic noises, making it a potential solution to practical noise reduction problems. 1 Introduction Convolutional neural networks (CNNs) have been widely studied over the past decade in various computer vision applications, including image classification [13], object detection [29], and image restoration [35]. In spite of high effectiveness, CNN models always require a large-scale dataset with reliable reference for training. However, in terms of low-level vision tasks, such as image denoising and image super-resolution, the reliable reference data is generally hard to access, which makes these tasks more challenging and difficult. -

10S Johnson-Nyquist Noise Masatsugu Sei Suzuki Department of Physics, SUNY at Binghamton (Date: January 02, 2011)
Chapter 10S Johnson-Nyquist noise Masatsugu Sei Suzuki Department of Physics, SUNY at Binghamton (Date: January 02, 2011) Johnson noise Johnson-Nyquist theorem Boltzmann constant Parseval relation Correlation function Spectral density Wiener-Khinchin (or Khintchine) Flicker noise Shot noise Poisson distribution Brownian motion Fluctuation-dissipation theorem Langevin function ___________________________________________________________________________ John Bertrand "Bert" Johnson (October 2, 1887–November 27, 1970) was a Swedish-born American electrical engineer and physicist. He first explained in detail a fundamental source of random interference with information traveling on wires. In 1928, while at Bell Telephone Laboratories he published the journal paper "Thermal Agitation of Electricity in Conductors". In telecommunication or other systems, thermal noise (or Johnson noise) is the noise generated by thermal agitation of electrons in a conductor. Johnson's papers showed a statistical fluctuation of electric charge occur in all electrical conductors, producing random variation of potential between the conductor ends (such as in vacuum tube amplifiers and thermocouples). Thermal noise power, per hertz, is equal throughout the frequency spectrum. Johnson deduced that thermal noise is intrinsic to all resistors and is not a sign of poor design or manufacture, although resistors may also have excess noise. http://en.wikipedia.org/wiki/John_B._Johnson 1 ____________________________________________________________________________ Harry Nyquist (February 7, 1889 – April 4, 1976) was an important contributor to information theory. http://en.wikipedia.org/wiki/Harry_Nyquist ___________________________________________________________________________ 10S.1 Histrory In 1926, experimental physicist John Johnson working in the physics division at Bell Labs was researching noise in electronic circuits. He discovered random fluctuations in the voltages across electrical resistors, whose power was proportional to temperature. -

High-Quality Self-Supervised Deep Image Denoising
High-Quality Self-Supervised Deep Image Denoising Samuli Laine Tero Karras Jaakko Lehtinen Timo Aila NVIDIA∗ NVIDIA NVIDIA, Aalto University NVIDIA Abstract We describe a novel method for training high-quality image denoising models based on unorganized collections of corrupted images. The training does not need access to clean reference images, or explicit pairs of corrupted images, and can thus be applied in situations where such data is unacceptably expensive or im- possible to acquire. We build on a recent technique that removes the need for reference data by employing networks with a “blind spot” in the receptive field, and significantly improve two key aspects: image quality and training efficiency. Our result quality is on par with state-of-the-art neural network denoisers in the case of i.i.d. additive Gaussian noise, and not far behind with Poisson and impulse noise. We also successfully handle cases where parameters of the noise model are variable and/or unknown in both training and evaluation data. 1 Introduction Denoising, the removal of noise from images, is a major application of deep learning. Several architectures have been proposed for general-purpose image restoration tasks, e.g., U-Nets [23], hierarchical residual networks [20], and residual dense networks [31]. Traditionally, the models are trained in a supervised fashion with corrupted images as inputs and clean images as targets, so that the network learns to remove the corruption. Lehtinen et al. [17] introduced NOISE2NOISE training, where pairs of corrupted images are used as training data. They observe that when certain statistical conditions are met, a network faced with the impossible task of mapping corrupted images to corrupted images learns, loosely speaking, to output the “average” image. -
![Arxiv:2003.13216V1 [Cs.CV] 30 Mar 2020](https://docslib.b-cdn.net/cover/3269/arxiv-2003-13216v1-cs-cv-30-mar-2020-263269.webp)
Arxiv:2003.13216V1 [Cs.CV] 30 Mar 2020
Learning to Learn Single Domain Generalization Fengchun Qiao Long Zhao Xi Peng University of Delaware Rutgers University University of Delaware [email protected] [email protected] [email protected] Abstract : Source domain(s) <latexit sha1_base64="glUSn7xz2m1yKGYjqzzX12DA3tk=">AAAB8nicjVDLSsNAFL3xWeur6tLNYBFclaQKdllw47KifUAaymQ6aYdOJmHmRiihn+HGhSJu/Rp3/o2TtgsVBQ8MHM65l3vmhKkUBl33w1lZXVvf2Cxtlbd3dvf2KweHHZNkmvE2S2SieyE1XArF2yhQ8l6qOY1Dybvh5Krwu/dcG5GoO5ymPIjpSIlIMIpW8vsxxTGjMr+dDSpVr+bOQf4mVViiNai894cJy2KukElqjO+5KQY51SiY5LNyPzM8pWxCR9y3VNGYmyCfR56RU6sMSZRo+xSSufp1I6exMdM4tJNFRPPTK8TfPD/DqBHkQqUZcsUWh6JMEkxI8X8yFJozlFNLKNPCZiVsTDVlaFsq/6+ETr3mndfqNxfVZmNZRwmO4QTOwINLaMI1tKANDBJ4gCd4dtB5dF6c18XoirPcOYJvcN4+AY5ZkWY=</latexit> <latexit sha1_base64="9X8JvFzvWSXuFK0x/Pe60//G3E4=">AAACD3icbVDLSsNAFJ3UV62vqks3g0Wpm5LW4mtVcOOyUvuANpTJZNIOnUzCzI1YQv/Ajb/ixoUibt26829M2iBqPTBwOOfeO/ceOxBcg2l+GpmFxaXllexqbm19Y3Mrv73T0n6oKGtSX/iqYxPNBJesCRwE6wSKEc8WrG2PLhO/fcuU5r68gXHALI8MJHc5JRBL/fxhzyMwpEREjQnuAbuD6AI3ptOx43uEy6I+muT6+YJZMqfA86SckgJKUe/nP3qOT0OPSaCCaN0tmwFYEVHAqWCTXC/ULCB0RAasG1NJPKataHrPBB/EioNdX8VPAp6qPzsi4mk99uy4Mtle//US8T+vG4J7ZkVcBiEwSWcfuaHA4OMkHOxwxSiIcUwIVTzeFdMhUYRCHOEshPMEJ98nz5NWpVQ+LlWvq4VaJY0ji/bQPiqiMjpFNXSF6qiJKLpHj+gZvRgPxpPxarzNSjNG2rOLfsF4/wJA4Zw6</latexit> S S : Target domain(s) <latexit sha1_base64="ssITTP/Vrn2uchq9aDxvcfruPQc=">AAACD3icbVDLSgNBEJz1bXxFPXoZDEq8hI2Kr5PgxWOEJAaSEHonnWTI7Owy0yuGJX/gxV/x4kERr169+TfuJkF8FTQUVd10d3mhkpZc98OZmp6ZnZtfWMwsLa+srmXXN6o2iIzAighUYGoeWFRSY4UkKayFBsH3FF57/YvUv75BY2WgyzQIselDV8uOFECJ1MruNnygngAVl4e8QXhL8Rkvg+ki8Xbgg9R5uzfMtLI5t+COwP+S4oTk2ASlVva90Q5E5KMmocDaetENqRmDISkUDjONyGIIog9drCdUg4+2GY/+GfKdRGnzTmCS0sRH6veJGHxrB76XdKbX299eKv7n1SPqnDRjqcOIUIvxok6kOAU8DYe3pUFBapAQEEYmt3LRAwOCkgjHIZymOPp6+S+p7heKB4XDq8Pc+f4kjgW2xbZZnhXZMTtnl6zEKkywO/bAntizc+88Oi/O67h1ypnMbLIfcN4+ATKRnDE=</latexit> -
Next Topic: NOISE
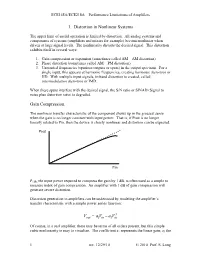
ECE145A/ECE218A Performance Limitations of Amplifiers 1. Distortion in Nonlinear Systems The upper limit of useful operation is limited by distortion. All analog systems and components of systems (amplifiers and mixers for example) become nonlinear when driven at large signal levels. The nonlinearity distorts the desired signal. This distortion exhibits itself in several ways: 1. Gain compression or expansion (sometimes called AM – AM distortion) 2. Phase distortion (sometimes called AM – PM distortion) 3. Unwanted frequencies (spurious outputs or spurs) in the output spectrum. For a single input, this appears at harmonic frequencies, creating harmonic distortion or HD. With multiple input signals, in-band distortion is created, called intermodulation distortion or IMD. When these spurs interfere with the desired signal, the S/N ratio or SINAD (Signal to noise plus distortion ratio) is degraded. Gain Compression. The nonlinear transfer characteristic of the component shows up in the grossest sense when the gain is no longer constant with input power. That is, if Pout is no longer linearly related to Pin, then the device is clearly nonlinear and distortion can be expected. Pout Pin P1dB, the input power required to compress the gain by 1 dB, is often used as a simple to measure index of gain compression. An amplifier with 1 dB of gain compression will generate severe distortion. Distortion generation in amplifiers can be understood by modeling the amplifier’s transfer characteristic with a simple power series function: 3 VaVaVout=−13 in in Of course, in a real amplifier, there may be terms of all orders present, but this simple cubic nonlinearity is easy to visualize. -

Learning Deep Image Priors for Blind Image Denoising
Learning Deep Image Priors for Blind Image Denoising Xianxu Hou 1 Hongming Luo 1 Jingxin Liu 1 Bolei Xu 1 Ke Sun 2 Yuanhao Gong 1 Bozhi Liu 1 Guoping Qiu 1,3 1 College of Information Engineering and Guangdong Key Lab for Intelligent Information Processing, Shenzhen University, China 2 School of Computer Science, The University of Nottingham Ningbo China 3 School of Computer Science, The University of Nottingham, UK Abstract ods comes from the effective image prior modeling over the input images [5, 14, 20]. State of the art model-based meth- Image denoising is the process of removing noise from ods such as BM3D [12] and WNNM [20] can be further noisy images, which is an image domain transferring task, extended to remove unknown noises. However, there are a i.e., from a single or several noise level domains to a photo- few drawbacks of these methods. First, these methods usu- realistic domain. In this paper, we propose an effective im- ally involve a complex and time-consuming optimization age denoising method by learning two image priors from process in the testing stage. Second, the image priors em- the perspective of domain alignment. We tackle the domain ployed in most of these approaches are hand-crafted, such alignment on two levels. 1) the feature-level prior is to learn as nonlocal self-similarity and gradients, which are mainly domain-invariant features for corrupted images with differ- based on the internal information of the input image without ent level noise; 2) the pixel-level prior is used to push the any external information. -

Thermal-Noise.Pdf
Thermal Noise Introduction One might naively believe that if all sources of electrical power are removed from a circuit that there will be no voltage across any of the components, a resistor for example. On average this is correct but a close look at the rms voltage would reveal that a "noise" voltage is present. This intrinsic noise is due to thermal fluctuations and can be calculated as may be done in your second year thermal physics course! The main goal of this experiment is to measure and characterize this noise: Johnson noise. In order to measure the intrinsic noise of a component one must first reduce the extrinsic sources of noise, i.e. interference. You have probably noticed that if you touch the input lead to an oscilloscope a large signal appears. Try this now and characterize the signal you see. Note that you are acting as an antenna! Make sure you look at both long time scales, say 10 ms, and shorter time scales, say 1 s. What are the likely sources of the signals you see? You may recall seeing this before in the First Year Laboratory. This interference is characterized by two features. First, the noise voltage is characterized by a spectrum, i.e. the noise voltage Vn ( f ) is a function of frequency. 2 Since noise usually has a time average of zero, the power spectrum Vn ( f ) is specified in each frequency interval df . Second, the measuring instrument is also characterized by a spectral response or bandwidth. In our case the bandwidth of the oscilloscope is from fL =0 (when input is DC coupled) to an upper frequency fH usually noted on the scope (beware of bandwidth limiting switches). -

Layered Neural Rendering for Retiming People in Video
Layered Neural Rendering for Retiming People in Video ERIKA LU, University of Oxford, Google Research FORRESTER COLE, Google Research TALI DEKEL, Google Research WEIDI XIE, University of Oxford ANDREW ZISSERMAN, University of Oxford DAVID SALESIN, Google Research WILLIAM T. FREEMAN, Google Research MICHAEL RUBINSTEIN, Google Research Input Video Frame t Frame t1 (child I jumps) Frame t2 (child II jumps) Frame t3 (child III jumps) Our Retiming Result Our Output Layers Frame t1 (all stand) Frame t2 (all jump) Frame t3 (all in water) Fig. 1. Making all children jump into the pool together — in post-processing! In the original video (left, top) each child is jumping into the poolata different time. In our computationally retimed video (left, bottom), the jumps of children I and III are time-aligned with that of child II, such thattheyalljump together into the pool (notice that child II remains unchanged in the input and output frames). In this paper, we present a method to produce this and other people retiming effects in natural, ordinary videos. Our method is based on a novel deep neural network that learns a layered decomposition oftheinput video (right). Our model not only disentangles the motions of people in different layers, but can also capture the various scene elements thatare correlated with those people (e.g., water splashes as the children hit the water, shadows, reflections). When people are retimed, those related elements get automatically retimed with them, which allows us to create realistic and faithful re-renderings of the video for a variety of retiming effects. The full input and retimed sequences are available in the supplementary video. -

Deep Image Prior for Undersampling High-Speed Photoacoustic Microscopy
Photoacoustics 22 (2021) 100266 Contents lists available at ScienceDirect Photoacoustics journal homepage: www.elsevier.com/locate/pacs Deep image prior for undersampling high-speed photoacoustic microscopy Tri Vu a,*, Anthony DiSpirito III a, Daiwei Li a, Zixuan Wang c, Xiaoyi Zhu a, Maomao Chen a, Laiming Jiang d, Dong Zhang b, Jianwen Luo b, Yu Shrike Zhang c, Qifa Zhou d, Roarke Horstmeyer e, Junjie Yao a a Photoacoustic Imaging Lab, Duke University, Durham, NC, 27708, USA b Department of Biomedical Engineering, Tsinghua University, Beijing, 100084, China c Division of Engineering in Medicine, Department of Medicine, Brigham and Women’s Hospital, Harvard Medical School, Cambridge, MA, 02139, USA d Department of Biomedical Engineering and USC Roski Eye Institute, University of Southern California, Los Angeles, CA, 90089, USA e Computational Optics Lab, Duke University, Durham, NC, 27708, USA ARTICLE INFO ABSTRACT Keywords: Photoacoustic microscopy (PAM) is an emerging imaging method combining light and sound. However, limited Convolutional neural network by the laser’s repetition rate, state-of-the-art high-speed PAM technology often sacrificesspatial sampling density Deep image prior (i.e., undersampling) for increased imaging speed over a large field-of-view. Deep learning (DL) methods have Deep learning recently been used to improve sparsely sampled PAM images; however, these methods often require time- High-speed imaging consuming pre-training and large training dataset with ground truth. Here, we propose the use of deep image Photoacoustic microscopy Raster scanning prior (DIP) to improve the image quality of undersampled PAM images. Unlike other DL approaches, DIP requires Undersampling neither pre-training nor fully-sampled ground truth, enabling its flexible and fast implementation on various imaging targets. -
Noise Is Widespread
NoiseNoise A definition (not mine) Electrical Noise S. Oberholzer and E. Bieri (Basel) T. Kontos and C. Hoffmann (Basel) A. Hansen and B-R Choi (Lund and Basel) ¾ Electrical noise is defined as any undesirable electrical energy (?) T. Akazaki and H. Takayanagi (NTT) E.V. Sukhorukov and D. Loss (Basel) C. Beenakker (Leiden) and M. Büttiker (Geneva) T. Heinzel and K. Ensslin (ETHZ) M. Henny, T. Hoss, C. Strunk (Basel) H. Birk (Philips Research and Basel) Effect of noise on a signal. (a) Without noise (b) With noise ¾ we like it though (even have a whole conference on it) National Center on Nanoscience Swiss National Science Foundation 1 2 Noise may have been added to by ... Introduction: Noise is widespread Noise (audio, sound, HiFi, encodimg, MPEG) Electrical Noise Noise (industrial, pollution) Noise (in electronic circuits) Noise (images, video, encoding) Noise (environment, pollution) it may be in the “source” signal from the start Noise (radio) it may have been introduced by the electronics Noise (economic => theory of pricing with fluctuating it may have been added to by the envirnoment source terms) it may have been generated in your computer Noise (astronomy, big-bang, cosmic background) Noise figure Shot noise Thermal noise for the latter, e.g. sampling noise Quantum noise Neuronal noise Standard quantum limit and more ... 3 4 Introduction: Noise is widespread Introduction (Wikipedia) Noise (audio, sound, HiFi, encodimg, MPEG) Electronic Noise (from Wikipedia) Noise (industrial, pollution) Noise (in electronic circuits) Noise (images, video, encoding) Electronic noise exists in any electronic circuit as a result of random variations in current or voltage caused by the random movement of the Noise (environment, pollution) electrons carrying the current as they are jolted around by thermal energy.energy Noise (radio) The lower the temperature the lower is this thermal noise. -

Image Deconvolution with Deep Image Prior: Final Report
Image deconvolution with deep image prior: Final Report Abstract tion kernel is given (Sezan & Tekalp, 1990), i.e. recovering Image deconvolution has always been a hard in- X with knowing K in Equation 1. This problem is ill-posed, verse problem because of its mathematically ill- because simply applying the inverse of the convolution op- −1 posed property (Chan & Wong, 1998). A recent eration on degraded image B with kernel K, i.e. B∗ K, −1 work (Ulyanov et al., 2018) proposed deep im- gives an inverted noise term E∗ K, which dominates the age prior (DIP) which uses neural net structures solution (Hansen et al., 2006). to represent image prior information. This work Blind deconvolution: In reality, we can hardly obtain the mainly focuses on the task of image deconvolu- detailed kernel information, in which case the deconvolu- tion, using DIP to express image prior informa- tion problem is formulated in a blind setting (Kundur & tion and ref ne the domain of its objectives. It Hatzinakos, 1996). More concisely, blind deconvolution is proposes new energy functions for kernel-known to recover X without knowing K. This task is much more and blind deconvolution respectively in terms of challenging than it is under non-blind settings, because the DIP, and uses hourglass ConvNet (Newell et al., observed information becomes less and the domains of the 2016) as the DIP structures to represent sharpness variables become larger (Chan & Wong, 1998). or other higher level priors of natural images, as well as the prior in degradation kernels. From the In image deconvolution, prior information on unknown results on 6 standard test images, we f rst prove images and kernels (in blind settings) can signif cantly im- that DIP with ConvNet structure is strongly ca- prove the deconvolved results. -

PROCEEDINGS of the ICA CONGRESS (Onl the ICA PROCEEDINGS OF
ine) - ISSN 2415-1599 ISSN ine) - PROCEEDINGS OF THE ICA CONGRESS (onl THE ICA PROCEEDINGS OF Page intentionaly left blank 22nd International Congress on Acoustics ICA 2016 PROCEEDINGS Editors: Federico Miyara Ernesto Accolti Vivian Pasch Nilda Vechiatti X Congreso Iberoamericano de Acústica XIV Congreso Argentino de Acústica XXVI Encontro da Sociedade Brasileira de Acústica 22nd International Congress on Acoustics ICA 2016 : Proceedings / Federico Miyara ... [et al.] ; compilado por Federico Miyara ; Ernesto Accolti. - 1a ed . - Gonnet : Asociación de Acústicos Argentinos, 2016. Libro digital, PDF Archivo Digital: descarga y online ISBN 978-987-24713-6-1 1. Acústica. 2. Acústica Arquitectónica. 3. Electroacústica. I. Miyara, Federico II. Miyara, Federico, comp. III. Accolti, Ernesto, comp. CDD 690.22 ISSN 2415-1599 ISBN 978-987-24713-6-1 © Asociación de Acústicos Argentinos Hecho el depósito que marca la ley 11.723 Disclaimer: The material, information, results, opinions, and/or views in this publication, as well as the claim for authorship and originality, are the sole responsibility of the respective author(s) of each paper, not the International Commission for Acoustics, the Federación Iberoamaricana de Acústica, the Asociación de Acústicos Argentinos or any of their employees, members, authorities, or editors. Except for the cases in which it is expressly stated, the papers have not been subject to peer review. The editors have attempted to accomplish a uniform presentation for all papers and the authors have been given the opportunity