SUPPLEMENTARY INFORMATION Gotree/Goalign
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Appendix 2. Significantly Differentially Regulated Genes in Term Compared with Second Trimester Amniotic Fluid Supernatant
Appendix 2. Significantly Differentially Regulated Genes in Term Compared With Second Trimester Amniotic Fluid Supernatant Fold Change in term vs second trimester Amniotic Affymetrix Duplicate Fluid Probe ID probes Symbol Entrez Gene Name 1019.9 217059_at D MUC7 mucin 7, secreted 424.5 211735_x_at D SFTPC surfactant protein C 416.2 206835_at STATH statherin 363.4 214387_x_at D SFTPC surfactant protein C 295.5 205982_x_at D SFTPC surfactant protein C 288.7 1553454_at RPTN repetin solute carrier family 34 (sodium 251.3 204124_at SLC34A2 phosphate), member 2 238.9 206786_at HTN3 histatin 3 161.5 220191_at GKN1 gastrokine 1 152.7 223678_s_at D SFTPA2 surfactant protein A2 130.9 207430_s_at D MSMB microseminoprotein, beta- 99.0 214199_at SFTPD surfactant protein D major histocompatibility complex, class II, 96.5 210982_s_at D HLA-DRA DR alpha 96.5 221133_s_at D CLDN18 claudin 18 94.4 238222_at GKN2 gastrokine 2 93.7 1557961_s_at D LOC100127983 uncharacterized LOC100127983 93.1 229584_at LRRK2 leucine-rich repeat kinase 2 HOXD cluster antisense RNA 1 (non- 88.6 242042_s_at D HOXD-AS1 protein coding) 86.0 205569_at LAMP3 lysosomal-associated membrane protein 3 85.4 232698_at BPIFB2 BPI fold containing family B, member 2 84.4 205979_at SCGB2A1 secretoglobin, family 2A, member 1 84.3 230469_at RTKN2 rhotekin 2 82.2 204130_at HSD11B2 hydroxysteroid (11-beta) dehydrogenase 2 81.9 222242_s_at KLK5 kallikrein-related peptidase 5 77.0 237281_at AKAP14 A kinase (PRKA) anchor protein 14 76.7 1553602_at MUCL1 mucin-like 1 76.3 216359_at D MUC7 mucin 7, -

Looking for Missing Proteins in the Proteome Of
Looking for Missing Proteins in the Proteome of Human Spermatozoa: An Update Yves Vandenbrouck, Lydie Lane, Christine Carapito, Paula Duek, Karine Rondel, Christophe Bruley, Charlotte Macron, Anne Gonzalez de Peredo, Yohann Coute, Karima Chaoui, et al. To cite this version: Yves Vandenbrouck, Lydie Lane, Christine Carapito, Paula Duek, Karine Rondel, et al.. Looking for Missing Proteins in the Proteome of Human Spermatozoa: An Update. Journal of Proteome Research, American Chemical Society, 2016, 15 (11), pp.3998-4019. 10.1021/acs.jproteome.6b00400. hal-02191502 HAL Id: hal-02191502 https://hal.archives-ouvertes.fr/hal-02191502 Submitted on 19 Mar 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Journal of Proteome Research 1 2 3 Looking for missing proteins in the proteome of human spermatozoa: an 4 update 5 6 Yves Vandenbrouck1,2,3,#,§, Lydie Lane4,5,#, Christine Carapito6, Paula Duek5, Karine Rondel7, 7 Christophe Bruley1,2,3, Charlotte Macron6, Anne Gonzalez de Peredo8, Yohann Couté1,2,3, 8 Karima Chaoui8, Emmanuelle Com7, Alain Gateau5, AnneMarie Hesse1,2,3, Marlene 9 Marcellin8, Loren Méar7, Emmanuelle MoutonBarbosa8, Thibault Robin9, Odile Burlet- 10 Schiltz8, Sarah Cianferani6, Myriam Ferro1,2,3, Thomas Fréour10,11, Cecilia Lindskog12,Jérôme 11 1,2,3 7,§ 12 Garin , Charles Pineau . -

Detecting Remote, Functional Conserved Domains in Entire Genomes by Combining Relaxed Sequence-Database Searches with Fold Recognition
HMMerThread: Detecting Remote, Functional Conserved Domains in Entire Genomes by Combining Relaxed Sequence-Database Searches with Fold Recognition Charles Richard Bradshaw1¤a, Vineeth Surendranath1, Robert Henschel2,3, Matthias Stefan Mueller2, Bianca Hermine Habermann1,4*¤b 1 Bioinformatics Laboratory, Max Planck Institute of Molecular Cell Biology and Genetics, Dresden, Saxony, Germany, 2 Center for Information Services and High Performance Computing (ZIH), Technical University, Dresden, Saxony, Germany, 3 High Performance Applications, Pervasive Technology Institute, Indiana University, Bloomington, Indiana, United States of America, 4 Bioinformatics Laboratory, Scionics c/o Max Planck Institute of Molecular Cell Biology and Genetics, Dresden, Saxony, Germany Abstract Conserved domains in proteins are one of the major sources of functional information for experimental design and genome-level annotation. Though search tools for conserved domain databases such as Hidden Markov Models (HMMs) are sensitive in detecting conserved domains in proteins when they share sufficient sequence similarity, they tend to miss more divergent family members, as they lack a reliable statistical framework for the detection of low sequence similarity. We have developed a greatly improved HMMerThread algorithm that can detect remotely conserved domains in highly divergent sequences. HMMerThread combines relaxed conserved domain searches with fold recognition to eliminate false positive, sequence-based identifications. With an accuracy of 90%, our software is able to automatically predict highly divergent members of conserved domain families with an associated 3-dimensional structure. We give additional confidence to our predictions by validation across species. We have run HMMerThread searches on eight proteomes including human and present a rich resource of remotely conserved domains, which adds significantly to the functional annotation of entire proteomes. -

Figure S1. HAEC ROS Production and ML090 NOX5-Inhibition
Figure S1. HAEC ROS production and ML090 NOX5-inhibition. (a) Extracellular H2O2 production in HAEC treated with ML090 at different concentrations and 24 h after being infected with GFP and NOX5-β adenoviruses (MOI 100). **p< 0.01, and ****p< 0.0001 vs control NOX5-β-infected cells (ML090, 0 nM). Results expressed as mean ± SEM. Fold increase vs GFP-infected cells with 0 nM of ML090. n= 6. (b) NOX5-β overexpression and DHE oxidation in HAEC. Representative images from three experiments are shown. Intracellular superoxide anion production of HAEC 24 h after infection with GFP and NOX5-β adenoviruses at different MOIs treated or not with ML090 (10 nM). MOI: Multiplicity of infection. Figure S2. Ontology analysis of HAEC infected with NOX5-β. Ontology analysis shows that the response to unfolded protein is the most relevant. Figure S3. UPR mRNA expression in heart of infarcted transgenic mice. n= 12-13. Results expressed as mean ± SEM. Table S1: Altered gene expression due to NOX5-β expression at 12 h (bold, highlighted in yellow). N12hvsG12h N18hvsG18h N24hvsG24h GeneName GeneDescription TranscriptID logFC p-value logFC p-value logFC p-value family with sequence similarity NM_052966 1.45 1.20E-17 2.44 3.27E-19 2.96 6.24E-21 FAM129A 129. member A DnaJ (Hsp40) homolog. NM_001130182 2.19 9.83E-20 2.94 2.90E-19 3.01 1.68E-19 DNAJA4 subfamily A. member 4 phorbol-12-myristate-13-acetate- NM_021127 0.93 1.84E-12 2.41 1.32E-17 2.69 1.43E-18 PMAIP1 induced protein 1 E2F7 E2F transcription factor 7 NM_203394 0.71 8.35E-11 2.20 2.21E-17 2.48 1.84E-18 DnaJ (Hsp40) homolog. -
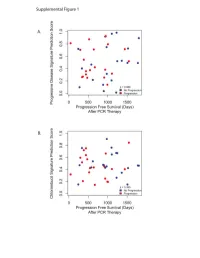
Supplementary Data
Progressive Disease Signature Upregulated probes with progressive disease U133Plus2 ID Gene Symbol Gene Name 239673_at NR3C2 nuclear receptor subfamily 3, group C, member 2 228994_at CCDC24 coiled-coil domain containing 24 1562245_a_at ZNF578 zinc finger protein 578 234224_at PTPRG protein tyrosine phosphatase, receptor type, G 219173_at NA NA 218613_at PSD3 pleckstrin and Sec7 domain containing 3 236167_at TNS3 tensin 3 1562244_at ZNF578 zinc finger protein 578 221909_at RNFT2 ring finger protein, transmembrane 2 1552732_at ABRA actin-binding Rho activating protein 59375_at MYO15B myosin XVB pseudogene 203633_at CPT1A carnitine palmitoyltransferase 1A (liver) 1563120_at NA NA 1560098_at AKR1C2 aldo-keto reductase family 1, member C2 (dihydrodiol dehydrogenase 2; bile acid binding pro 238576_at NA NA 202283_at SERPINF1 serpin peptidase inhibitor, clade F (alpha-2 antiplasmin, pigment epithelium derived factor), m 214248_s_at TRIM2 tripartite motif-containing 2 204766_s_at NUDT1 nudix (nucleoside diphosphate linked moiety X)-type motif 1 242308_at MCOLN3 mucolipin 3 1569154_a_at NA NA 228171_s_at PLEKHG4 pleckstrin homology domain containing, family G (with RhoGef domain) member 4 1552587_at CNBD1 cyclic nucleotide binding domain containing 1 220705_s_at ADAMTS7 ADAM metallopeptidase with thrombospondin type 1 motif, 7 232332_at RP13-347D8.3 KIAA1210 protein 1553618_at TRIM43 tripartite motif-containing 43 209369_at ANXA3 annexin A3 243143_at FAM24A family with sequence similarity 24, member A 234742_at SIRPG signal-regulatory protein gamma -

Application of Microrna Database Mining in Biomarker Discovery and Identification of Therapeutic Targets for Complex Disease
Article Application of microRNA Database Mining in Biomarker Discovery and Identification of Therapeutic Targets for Complex Disease Jennifer L. Major, Rushita A. Bagchi * and Julie Pires da Silva * Department of Medicine, Division of Cardiology, University of Colorado Anschutz Medical Campus, Aurora, CO 80045, USA; [email protected] * Correspondence: [email protected] (R.A.B.); [email protected] (J.P.d.S.) Supplementary Tables Methods Protoc. 2021, 4, 5. https://doi.org/10.3390/mps4010005 www.mdpi.com/journal/mps Methods Protoc. 2021, 4, 5. https://doi.org/10.3390/mps4010005 2 of 25 Table 1. List of all hsa-miRs identified by Human microRNA Disease Database (HMDD; v3.2) analysis. hsa-miRs were identified using the term “genetics” and “circulating” as input in HMDD. Targets CAD hsa-miR-1 Targets IR injury hsa-miR-423 Targets Obesity hsa-miR-499 hsa-miR-146a Circulating Obesity Genetics CAD hsa-miR-423 hsa-miR-146a Circulating CAD hsa-miR-149 hsa-miR-499 Circulating IR Injury hsa-miR-146a Circulating Obesity hsa-miR-122 Genetics Stroke Circulating CAD hsa-miR-122 Circulating Stroke hsa-miR-122 Genetics Obesity Circulating Stroke hsa-miR-26b hsa-miR-17 hsa-miR-223 Targets CAD hsa-miR-340 hsa-miR-34a hsa-miR-92a hsa-miR-126 Circulating Obesity Targets IR injury hsa-miR-21 hsa-miR-423 hsa-miR-126 hsa-miR-143 Targets Obesity hsa-miR-21 hsa-miR-223 hsa-miR-34a hsa-miR-17 Targets CAD hsa-miR-223 hsa-miR-92a hsa-miR-126 Targets IR injury hsa-miR-155 hsa-miR-21 Circulating CAD hsa-miR-126 hsa-miR-145 hsa-miR-21 Targets Obesity hsa-mir-223 hsa-mir-499 hsa-mir-574 Targets IR injury hsa-mir-21 Circulating IR injury Targets Obesity hsa-mir-21 Targets CAD hsa-mir-22 hsa-mir-133a Targets IR injury hsa-mir-155 hsa-mir-21 Circulating Stroke hsa-mir-145 hsa-mir-146b Targets Obesity hsa-mir-21 hsa-mir-29b Methods Protoc. -

Supplementary Table 2
Supplementary Table 2. Differentially Expressed Genes following Sham treatment relative to Untreated Controls Fold Change Accession Name Symbol 3 h 12 h NM_013121 CD28 antigen Cd28 12.82 BG665360 FMS-like tyrosine kinase 1 Flt1 9.63 NM_012701 Adrenergic receptor, beta 1 Adrb1 8.24 0.46 U20796 Nuclear receptor subfamily 1, group D, member 2 Nr1d2 7.22 NM_017116 Calpain 2 Capn2 6.41 BE097282 Guanine nucleotide binding protein, alpha 12 Gna12 6.21 NM_053328 Basic helix-loop-helix domain containing, class B2 Bhlhb2 5.79 NM_053831 Guanylate cyclase 2f Gucy2f 5.71 AW251703 Tumor necrosis factor receptor superfamily, member 12a Tnfrsf12a 5.57 NM_021691 Twist homolog 2 (Drosophila) Twist2 5.42 NM_133550 Fc receptor, IgE, low affinity II, alpha polypeptide Fcer2a 4.93 NM_031120 Signal sequence receptor, gamma Ssr3 4.84 NM_053544 Secreted frizzled-related protein 4 Sfrp4 4.73 NM_053910 Pleckstrin homology, Sec7 and coiled/coil domains 1 Pscd1 4.69 BE113233 Suppressor of cytokine signaling 2 Socs2 4.68 NM_053949 Potassium voltage-gated channel, subfamily H (eag- Kcnh2 4.60 related), member 2 NM_017305 Glutamate cysteine ligase, modifier subunit Gclm 4.59 NM_017309 Protein phospatase 3, regulatory subunit B, alpha Ppp3r1 4.54 isoform,type 1 NM_012765 5-hydroxytryptamine (serotonin) receptor 2C Htr2c 4.46 NM_017218 V-erb-b2 erythroblastic leukemia viral oncogene homolog Erbb3 4.42 3 (avian) AW918369 Zinc finger protein 191 Zfp191 4.38 NM_031034 Guanine nucleotide binding protein, alpha 12 Gna12 4.38 NM_017020 Interleukin 6 receptor Il6r 4.37 AJ002942 -

LN-EPC Vs CEPC List
Supplementary Information Table 5. List of genes upregulated on LN-EPC (LCB represents the variation of gene expression comparing LN-EPC with CEPC) Gene dystrophin (muscular dystrophy, Duchenne and Becker types) regulator of G-protein signalling 13 chemokine (C-C motif) ligand 8 vascular cell adhesion molecule 1 matrix metalloproteinase 9 (gelatinase B, 92kDa gelatinase, 92kDa type IV collagenase) chemokine (C-C motif) ligand 2 solute carrier family 2 (facilitated glucose/fructose transporter), member 5 eukaryotic translation initiation factor 1A, Y-linked regulator of G-protein signalling 1 ubiquitin D chemokine (C-X-C motif) ligand 3 transcription factor 4 chemokine (C-X-C motif) ligand 13 (B-cell chemoattractant) solute carrier family 7, (cationic amino acid transporter, y+ system) member 11 transcription factor 4 apolipoprotein D RAS guanyl releasing protein 3 (calcium and DAG-regulated) matrix metalloproteinase 1 (interstitial collagenase) DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked /// DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked transcription factor 4 regulator of G-protein signalling 1 B-cell linker interleukin 8 POU domain, class 2, associating factor 1 CD24 antigen (small cell lung carcinoma cluster 4 antigen) Consensus includes gb:AK000168.1 /DEF=Homo sapiens cDNA FLJ20161 fis, clone COL09252, highly similar to L33930 Homo sapiens CD24 signal transducer mRNA. /FEA=mRNA /DB_XREF=gi:7020079 /UG=Hs.332045 Homo sapiens cDNA FLJ20161 fis, clone COL09252, highly similar to L33930 Homo sapiens CD24 signal transducer mRNA -

Supplementary Table 1
Supplementary Table 1. 492 genes are unique to 0 h post-heat timepoint. The name, p-value, fold change, location and family of each gene are indicated. Genes were filtered for an absolute value log2 ration 1.5 and a significance value of p ≤ 0.05. Symbol p-value Log Gene Name Location Family Ratio ABCA13 1.87E-02 3.292 ATP-binding cassette, sub-family unknown transporter A (ABC1), member 13 ABCB1 1.93E-02 −1.819 ATP-binding cassette, sub-family Plasma transporter B (MDR/TAP), member 1 Membrane ABCC3 2.83E-02 2.016 ATP-binding cassette, sub-family Plasma transporter C (CFTR/MRP), member 3 Membrane ABHD6 7.79E-03 −2.717 abhydrolase domain containing 6 Cytoplasm enzyme ACAT1 4.10E-02 3.009 acetyl-CoA acetyltransferase 1 Cytoplasm enzyme ACBD4 2.66E-03 1.722 acyl-CoA binding domain unknown other containing 4 ACSL5 1.86E-02 −2.876 acyl-CoA synthetase long-chain Cytoplasm enzyme family member 5 ADAM23 3.33E-02 −3.008 ADAM metallopeptidase domain Plasma peptidase 23 Membrane ADAM29 5.58E-03 3.463 ADAM metallopeptidase domain Plasma peptidase 29 Membrane ADAMTS17 2.67E-04 3.051 ADAM metallopeptidase with Extracellular other thrombospondin type 1 motif, 17 Space ADCYAP1R1 1.20E-02 1.848 adenylate cyclase activating Plasma G-protein polypeptide 1 (pituitary) receptor Membrane coupled type I receptor ADH6 (includes 4.02E-02 −1.845 alcohol dehydrogenase 6 (class Cytoplasm enzyme EG:130) V) AHSA2 1.54E-04 −1.6 AHA1, activator of heat shock unknown other 90kDa protein ATPase homolog 2 (yeast) AK5 3.32E-02 1.658 adenylate kinase 5 Cytoplasm kinase AK7 -

Supplementary Figures
Supplementary Figures Supplementary Figure 1 | Sampling locality, genome size estimation, and GC content. (a) Sampling locality in Amami Island (i.e., Amami Oshima, Japan) and its relative location to Okinawa are shown with coordinates (adapted from Google Maps). (b) Sperm cells collected from gravid male gonads were stained with DAPI and subjected to fluorescence-activated cell sorting (FACS) flow cytometry analysis. Sperm with known genome size from zebrafish (Danio rerio) were used as an internal standard to estimate the Lingula genome size. (c) The analysis of stepwise assembly shows that the saturation point is achieved when input sequences reach 10 Gbp from 454 and Illumina reads. (d) K-mer analysis (17-mer) using Illumina reads shows two peaks, in which the homozygous peak coverage is twice the heterozygous peak. The estimated heterozygosity rate calculating the ratio of the peaks, is 1.6%. (e) Distribution of GC content calculated from 3,830 scaffolds. (f) Comparison of GC content in selected lophotrochozoans. Error bars, standard deviation. Supplementary Figure 2 | Schematic flow of sequencing and assembly of the Lingula genome. (a) Genomic DNA from a male gonad was extracted for genome sequencing using Roche 454, Illumina, and PacBio platforms. A total of 96-Gb of data was obtained with approximately 226- fold coverage of the 425-Mb Lingula genome. (b) Ten embryonic stages from egg to larva and seven adult tissues were collected for RNA-seq and reads were assembled de novo using Trinity. (c) Transcript information from RNA-seq was used to generate hints by spliced alignment with PASA and BLAT. Gene models were predicted with trained AUGUSTUS. -

CX3CR1 Engagement by Respiratory Syncytial Virus Leads to Induction of Nucleolin And
bioRxiv preprint doi: https://doi.org/10.1101/2020.07.29.227967; this version posted July 30, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 RESEARCH ARTICLE 2 3 CX3CR1 Engagement by Respiratory Syncytial Virus Leads to Induction of Nucleolin and 4 Dysregulation of Cilia-related Genes 5 6 Christopher S. Andersona*, Tatiana Chirkovab*, Christopher G. Slaunwhite, Xing Qiuc, Edward E. Walshd, 7 Larry J. Andersonb# and Thomas J. Mariania# 8 9 aDepartments of Pediatrics, University of Rochester Medical Center, Rochester, NY. 10 bEmory University Department of Pediatrics and Children’s Healthcare of Atlanta, Atlanta, GA. 11 cDepartment of Biostatistics and Computational Biology 12 dDepartment of Medicine, University of Rochester Medical Center, Rochester, NY. 13 *contributed equally to this work 14 #corresponding authors 15 16 Address for Correspondence: 17 Thomas J. Mariani, PhD 18 Professor of Pediatrics 19 Division of Neonatology and 20 Pediatric Molecular and Personalized Medicine Program 21 University of Rochester Medical Center 22 601 Elmwood Ave, Box 850 23 Rochester, NY 14642, USA. 24 Phone: 585-276-4616; Fax: 585-276-2643; 25 E-mail: [email protected] 26 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.07.29.227967; this version posted July 30, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity.