Supplementary Figures
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Global-Scale Analysis of the Dynamic Transcriptional Adaptations Within Skeletal Muscle During Hypertrophic Growth
University of Kentucky UKnowledge Theses and Dissertations--Physiology Physiology 2015 GLOBAL-SCALE ANALYSIS OF THE DYNAMIC TRANSCRIPTIONAL ADAPTATIONS WITHIN SKELETAL MUSCLE DURING HYPERTROPHIC GROWTH Tyler Kirby University of Kentucky, [email protected] Right click to open a feedback form in a new tab to let us know how this document benefits ou.y Recommended Citation Kirby, Tyler, "GLOBAL-SCALE ANALYSIS OF THE DYNAMIC TRANSCRIPTIONAL ADAPTATIONS WITHIN SKELETAL MUSCLE DURING HYPERTROPHIC GROWTH" (2015). Theses and Dissertations--Physiology. 22. https://uknowledge.uky.edu/physiology_etds/22 This Doctoral Dissertation is brought to you for free and open access by the Physiology at UKnowledge. It has been accepted for inclusion in Theses and Dissertations--Physiology by an authorized administrator of UKnowledge. For more information, please contact [email protected]. STUDENT AGREEMENT: I represent that my thesis or dissertation and abstract are my original work. Proper attribution has been given to all outside sources. I understand that I am solely responsible for obtaining any needed copyright permissions. I have obtained needed written permission statement(s) from the owner(s) of each third-party copyrighted matter to be included in my work, allowing electronic distribution (if such use is not permitted by the fair use doctrine) which will be submitted to UKnowledge as Additional File. I hereby grant to The University of Kentucky and its agents the irrevocable, non-exclusive, and royalty-free license to archive and make accessible my work in whole or in part in all forms of media, now or hereafter known. I agree that the document mentioned above may be made available immediately for worldwide access unless an embargo applies. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Supplementary Material
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Neurol Neurosurg Psychiatry Page 1 / 45 SUPPLEMENTARY MATERIAL Appendix A1: Neuropsychological protocol. Appendix A2: Description of the four cases at the transitional stage. Table A1: Clinical status and center proportion in each batch. Table A2: Complete output from EdgeR. Table A3: List of the putative target genes. Table A4: Complete output from DIANA-miRPath v.3. Table A5: Comparison of studies investigating miRNAs from brain samples. Figure A1: Stratified nested cross-validation. Figure A2: Expression heatmap of miRNA signature. Figure A3: Bootstrapped ROC AUC scores. Figure A4: ROC AUC scores with 100 different fold splits. Figure A5: Presymptomatic subjects probability scores. Figure A6: Heatmap of the level of enrichment in KEGG pathways. Kmetzsch V, et al. J Neurol Neurosurg Psychiatry 2021; 92:485–493. doi: 10.1136/jnnp-2020-324647 BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Neurol Neurosurg Psychiatry Appendix A1. Neuropsychological protocol The PREV-DEMALS cognitive evaluation included standardized neuropsychological tests to investigate all cognitive domains, and in particular frontal lobe functions. The scores were provided previously (Bertrand et al., 2018). Briefly, global cognitive efficiency was evaluated by means of Mini-Mental State Examination (MMSE) and Mattis Dementia Rating Scale (MDRS). Frontal executive functions were assessed with Frontal Assessment Battery (FAB), forward and backward digit spans, Trail Making Test part A and B (TMT-A and TMT-B), Wisconsin Card Sorting Test (WCST), and Symbol-Digit Modalities test. -

(P -Value<0.05, Fold Change≥1.4), 4 Vs. 0 Gy Irradiation
Table S1: Significant differentially expressed genes (P -Value<0.05, Fold Change≥1.4), 4 vs. 0 Gy irradiation Genbank Fold Change P -Value Gene Symbol Description Accession Q9F8M7_CARHY (Q9F8M7) DTDP-glucose 4,6-dehydratase (Fragment), partial (9%) 6.70 0.017399678 THC2699065 [THC2719287] 5.53 0.003379195 BC013657 BC013657 Homo sapiens cDNA clone IMAGE:4152983, partial cds. [BC013657] 5.10 0.024641735 THC2750781 Ciliary dynein heavy chain 5 (Axonemal beta dynein heavy chain 5) (HL1). 4.07 0.04353262 DNAH5 [Source:Uniprot/SWISSPROT;Acc:Q8TE73] [ENST00000382416] 3.81 0.002855909 NM_145263 SPATA18 Homo sapiens spermatogenesis associated 18 homolog (rat) (SPATA18), mRNA [NM_145263] AA418814 zw01a02.s1 Soares_NhHMPu_S1 Homo sapiens cDNA clone IMAGE:767978 3', 3.69 0.03203913 AA418814 AA418814 mRNA sequence [AA418814] AL356953 leucine-rich repeat-containing G protein-coupled receptor 6 {Homo sapiens} (exp=0; 3.63 0.0277936 THC2705989 wgp=1; cg=0), partial (4%) [THC2752981] AA484677 ne64a07.s1 NCI_CGAP_Alv1 Homo sapiens cDNA clone IMAGE:909012, mRNA 3.63 0.027098073 AA484677 AA484677 sequence [AA484677] oe06h09.s1 NCI_CGAP_Ov2 Homo sapiens cDNA clone IMAGE:1385153, mRNA sequence 3.48 0.04468495 AA837799 AA837799 [AA837799] Homo sapiens hypothetical protein LOC340109, mRNA (cDNA clone IMAGE:5578073), partial 3.27 0.031178378 BC039509 LOC643401 cds. [BC039509] Homo sapiens Fas (TNF receptor superfamily, member 6) (FAS), transcript variant 1, mRNA 3.24 0.022156298 NM_000043 FAS [NM_000043] 3.20 0.021043295 A_32_P125056 BF803942 CM2-CI0135-021100-477-g08 CI0135 Homo sapiens cDNA, mRNA sequence 3.04 0.043389246 BF803942 BF803942 [BF803942] 3.03 0.002430239 NM_015920 RPS27L Homo sapiens ribosomal protein S27-like (RPS27L), mRNA [NM_015920] Homo sapiens tumor necrosis factor receptor superfamily, member 10c, decoy without an 2.98 0.021202829 NM_003841 TNFRSF10C intracellular domain (TNFRSF10C), mRNA [NM_003841] 2.97 0.03243901 AB002384 C6orf32 Homo sapiens mRNA for KIAA0386 gene, partial cds. -

Detecting Remote, Functional Conserved Domains in Entire Genomes by Combining Relaxed Sequence-Database Searches with Fold Recognition
HMMerThread: Detecting Remote, Functional Conserved Domains in Entire Genomes by Combining Relaxed Sequence-Database Searches with Fold Recognition Charles Richard Bradshaw1¤a, Vineeth Surendranath1, Robert Henschel2,3, Matthias Stefan Mueller2, Bianca Hermine Habermann1,4*¤b 1 Bioinformatics Laboratory, Max Planck Institute of Molecular Cell Biology and Genetics, Dresden, Saxony, Germany, 2 Center for Information Services and High Performance Computing (ZIH), Technical University, Dresden, Saxony, Germany, 3 High Performance Applications, Pervasive Technology Institute, Indiana University, Bloomington, Indiana, United States of America, 4 Bioinformatics Laboratory, Scionics c/o Max Planck Institute of Molecular Cell Biology and Genetics, Dresden, Saxony, Germany Abstract Conserved domains in proteins are one of the major sources of functional information for experimental design and genome-level annotation. Though search tools for conserved domain databases such as Hidden Markov Models (HMMs) are sensitive in detecting conserved domains in proteins when they share sufficient sequence similarity, they tend to miss more divergent family members, as they lack a reliable statistical framework for the detection of low sequence similarity. We have developed a greatly improved HMMerThread algorithm that can detect remotely conserved domains in highly divergent sequences. HMMerThread combines relaxed conserved domain searches with fold recognition to eliminate false positive, sequence-based identifications. With an accuracy of 90%, our software is able to automatically predict highly divergent members of conserved domain families with an associated 3-dimensional structure. We give additional confidence to our predictions by validation across species. We have run HMMerThread searches on eight proteomes including human and present a rich resource of remotely conserved domains, which adds significantly to the functional annotation of entire proteomes. -
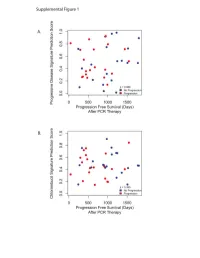
Supplementary Data
Progressive Disease Signature Upregulated probes with progressive disease U133Plus2 ID Gene Symbol Gene Name 239673_at NR3C2 nuclear receptor subfamily 3, group C, member 2 228994_at CCDC24 coiled-coil domain containing 24 1562245_a_at ZNF578 zinc finger protein 578 234224_at PTPRG protein tyrosine phosphatase, receptor type, G 219173_at NA NA 218613_at PSD3 pleckstrin and Sec7 domain containing 3 236167_at TNS3 tensin 3 1562244_at ZNF578 zinc finger protein 578 221909_at RNFT2 ring finger protein, transmembrane 2 1552732_at ABRA actin-binding Rho activating protein 59375_at MYO15B myosin XVB pseudogene 203633_at CPT1A carnitine palmitoyltransferase 1A (liver) 1563120_at NA NA 1560098_at AKR1C2 aldo-keto reductase family 1, member C2 (dihydrodiol dehydrogenase 2; bile acid binding pro 238576_at NA NA 202283_at SERPINF1 serpin peptidase inhibitor, clade F (alpha-2 antiplasmin, pigment epithelium derived factor), m 214248_s_at TRIM2 tripartite motif-containing 2 204766_s_at NUDT1 nudix (nucleoside diphosphate linked moiety X)-type motif 1 242308_at MCOLN3 mucolipin 3 1569154_a_at NA NA 228171_s_at PLEKHG4 pleckstrin homology domain containing, family G (with RhoGef domain) member 4 1552587_at CNBD1 cyclic nucleotide binding domain containing 1 220705_s_at ADAMTS7 ADAM metallopeptidase with thrombospondin type 1 motif, 7 232332_at RP13-347D8.3 KIAA1210 protein 1553618_at TRIM43 tripartite motif-containing 43 209369_at ANXA3 annexin A3 243143_at FAM24A family with sequence similarity 24, member A 234742_at SIRPG signal-regulatory protein gamma -

Supporting Information Structure and Protein Interaction-Based Gene
Supporting Information Structure and Protein Interaction-based Gene Ontology Annotations Reveal Likely Functions of Uncharacterized Proteins on Human Chromosome 17 Chengxin Zhang, Xiaoqiong Wei, Gilbert S. Omenn, and Yang Zhang Table of Contents Text S1. SPARQL query for curating the list of uPE1 proteins from neXtProt database version 2018-01-17 ................................................................................................................................... S2 Text S1. SPARQL query for curating the initial list of unannotated proteins from neXtProt database ......................................................................................................................................... S3 Text S3. Benchmark set of 100 well annotated PE1 proteins randomly selected from chromosome 17 ............................................................................................................................. S4 Table S1. Fmax of different programs for GO prediction using UniProt and neXtProt annotation as gold standard for the benchmark set of 100 chromosome 17 PE1 proteins ............................ S5 Table S2. Fmax of “structure” component and the final consensus prediction in COFACTOR for a benchmark set of 59 proteins with experimental structure covering at least 30% of target sequence ....................................................................................................................................... S6 Table S3. COFACTOR predicted functions for 66 uPE1 protein on chromosome 17 ............... -

Supplementary Table 2
Supplementary Table 2. Differentially Expressed Genes following Sham treatment relative to Untreated Controls Fold Change Accession Name Symbol 3 h 12 h NM_013121 CD28 antigen Cd28 12.82 BG665360 FMS-like tyrosine kinase 1 Flt1 9.63 NM_012701 Adrenergic receptor, beta 1 Adrb1 8.24 0.46 U20796 Nuclear receptor subfamily 1, group D, member 2 Nr1d2 7.22 NM_017116 Calpain 2 Capn2 6.41 BE097282 Guanine nucleotide binding protein, alpha 12 Gna12 6.21 NM_053328 Basic helix-loop-helix domain containing, class B2 Bhlhb2 5.79 NM_053831 Guanylate cyclase 2f Gucy2f 5.71 AW251703 Tumor necrosis factor receptor superfamily, member 12a Tnfrsf12a 5.57 NM_021691 Twist homolog 2 (Drosophila) Twist2 5.42 NM_133550 Fc receptor, IgE, low affinity II, alpha polypeptide Fcer2a 4.93 NM_031120 Signal sequence receptor, gamma Ssr3 4.84 NM_053544 Secreted frizzled-related protein 4 Sfrp4 4.73 NM_053910 Pleckstrin homology, Sec7 and coiled/coil domains 1 Pscd1 4.69 BE113233 Suppressor of cytokine signaling 2 Socs2 4.68 NM_053949 Potassium voltage-gated channel, subfamily H (eag- Kcnh2 4.60 related), member 2 NM_017305 Glutamate cysteine ligase, modifier subunit Gclm 4.59 NM_017309 Protein phospatase 3, regulatory subunit B, alpha Ppp3r1 4.54 isoform,type 1 NM_012765 5-hydroxytryptamine (serotonin) receptor 2C Htr2c 4.46 NM_017218 V-erb-b2 erythroblastic leukemia viral oncogene homolog Erbb3 4.42 3 (avian) AW918369 Zinc finger protein 191 Zfp191 4.38 NM_031034 Guanine nucleotide binding protein, alpha 12 Gna12 4.38 NM_017020 Interleukin 6 receptor Il6r 4.37 AJ002942 -

LN-EPC Vs CEPC List
Supplementary Information Table 5. List of genes upregulated on LN-EPC (LCB represents the variation of gene expression comparing LN-EPC with CEPC) Gene dystrophin (muscular dystrophy, Duchenne and Becker types) regulator of G-protein signalling 13 chemokine (C-C motif) ligand 8 vascular cell adhesion molecule 1 matrix metalloproteinase 9 (gelatinase B, 92kDa gelatinase, 92kDa type IV collagenase) chemokine (C-C motif) ligand 2 solute carrier family 2 (facilitated glucose/fructose transporter), member 5 eukaryotic translation initiation factor 1A, Y-linked regulator of G-protein signalling 1 ubiquitin D chemokine (C-X-C motif) ligand 3 transcription factor 4 chemokine (C-X-C motif) ligand 13 (B-cell chemoattractant) solute carrier family 7, (cationic amino acid transporter, y+ system) member 11 transcription factor 4 apolipoprotein D RAS guanyl releasing protein 3 (calcium and DAG-regulated) matrix metalloproteinase 1 (interstitial collagenase) DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked /// DEAD (Asp-Glu-Ala-Asp) box polypeptide 3, Y-linked transcription factor 4 regulator of G-protein signalling 1 B-cell linker interleukin 8 POU domain, class 2, associating factor 1 CD24 antigen (small cell lung carcinoma cluster 4 antigen) Consensus includes gb:AK000168.1 /DEF=Homo sapiens cDNA FLJ20161 fis, clone COL09252, highly similar to L33930 Homo sapiens CD24 signal transducer mRNA. /FEA=mRNA /DB_XREF=gi:7020079 /UG=Hs.332045 Homo sapiens cDNA FLJ20161 fis, clone COL09252, highly similar to L33930 Homo sapiens CD24 signal transducer mRNA -

Transdifferentiation of Human Mesenchymal Stem Cells
Transdifferentiation of Human Mesenchymal Stem Cells Dissertation zur Erlangung des naturwissenschaftlichen Doktorgrades der Julius-Maximilians-Universität Würzburg vorgelegt von Tatjana Schilling aus San Miguel de Tucuman, Argentinien Würzburg, 2007 Eingereicht am: Mitglieder der Promotionskommission: Vorsitzender: Prof. Dr. Martin J. Müller Gutachter: PD Dr. Norbert Schütze Gutachter: Prof. Dr. Georg Krohne Tag des Promotionskolloquiums: Doktorurkunde ausgehändigt am: Hiermit erkläre ich ehrenwörtlich, dass ich die vorliegende Dissertation selbstständig angefertigt und keine anderen als die von mir angegebenen Hilfsmittel und Quellen verwendet habe. Des Weiteren erkläre ich, dass diese Arbeit weder in gleicher noch in ähnlicher Form in einem Prüfungsverfahren vorgelegen hat und ich noch keinen Promotionsversuch unternommen habe. Gerbrunn, 4. Mai 2007 Tatjana Schilling Table of contents i Table of contents 1 Summary ........................................................................................................................ 1 1.1 Summary.................................................................................................................... 1 1.2 Zusammenfassung..................................................................................................... 2 2 Introduction.................................................................................................................... 4 2.1 Osteoporosis and the fatty degeneration of the bone marrow..................................... 4 2.2 Adipose and bone