15-740/18-740 Computer Architecture Lecture 4: ISA Tradeoffs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Comparison of Parallel and Pipelined CORDIC Algorithm Using RCA and CSA
Comparison of Parallel and Pipelined CORDIC algorithm using RCA and CSA Diego Barragan´ Guerrero Lu´ıs Geraldo P. Meloni FEEC - UNICAMP FEEC - UNICAMP Campinas, Sao˜ Paulo, Brazil, 13083-852 Campinas, Sao˜ Paulo, Brazil, 13083-852 +5519 9308-9952 +5519 9778-1523 [email protected] [email protected] Abstract— This paper presents an implementation of the algorithm has two modes of operation: the rotational mode CORDIC algorithm in digital hardware using two types of (RM) where the vector (xi; yi) is rotated by an angle θ to algebraic adders: Ripple-Carry Adder (RCA) and Carry-Select obtain a new vector (x ; y ), and the vectoring mode (VM) Adder (CSA), both in parallel and pipelined architectures. Anal- N N ysis of time performance and resources utilization was carried in which the algorithm computes the modulus R and phase α out by changing the algorithm number of iterations. These results from the x-axis of the vector (x0; y0). The basic principle of demonstrate the efficiency in operating frequency of the pipelined the algorithm is shown in Figure 1. architecture with respect to the parallel architecture. Also it is shown that the use of CSA reduce the timing processing without significantly increasing the slice use. The code was synthesized us- ing FPGA development tools for the Xilinx Spartan-3E xc3s500e ' ' E N y family. N E N Index Terms— CORDIC, pipelined, parallel, RCA, CSA, y N trigonometrics functions. Rotação Pseudo-rotação R N I. INTRODUCTION E i In Digital Signal Processing with FPGA, trigonometric y i R i functions are used in many signal algorithms, for instance N synchronization and equalization [12]. -

Instruction-Level Distributed Processing
COVER FEATURE Instruction-Level Distributed Processing Shifts in hardware and software technology will soon force designers to look at microarchitectures that process instruction streams in a highly distributed fashion. James E. or nearly 20 years, microarchitecture research In short, the current focus on instruction-level Smith has emphasized instruction-level parallelism, parallelism will shift to instruction-level distributed University of which improves performance by increasing the processing (ILDP), emphasizing interinstruction com- Wisconsin- number of instructions per cycle. In striving munication with dynamic optimization and a tight Madison F for such parallelism, researchers have taken interaction between hardware and low-level software. microarchitectures from pipelining to superscalar pro- cessing, pushing toward increasingly parallel proces- TECHNOLOGY SHIFTS sors. They have concentrated on wider instruction fetch, During the next two or three technology generations, higher instruction issue rates, larger instruction win- processor architects will face several major challenges. dows, and increasing use of prediction and speculation. On-chip wire delays are becoming critical, and power In short, researchers have exploited advances in chip considerations will temper the availability of billions of technology to develop complex, hardware-intensive transistors. Many important applications will be object- processors. oriented and multithreaded and will consist of numer- Benefiting from ever-increasing transistor budgets ous separately -

Basics of Logic Design Arithmetic Logic Unit (ALU) Today's Lecture
Basics of Logic Design Arithmetic Logic Unit (ALU) CPS 104 Lecture 9 Today’s Lecture • Homework #3 Assigned Due March 3 • Project Groups assigned & posted to blackboard. • Project Specification is on Web Due April 19 • Building the building blocks… Outline • Review • Digital building blocks • An Arithmetic Logic Unit (ALU) Reading Appendix B, Chapter 3 © Alvin R. Lebeck CPS 104 2 Review: Digital Design • Logic Design, Switching Circuits, Digital Logic Recall: Everything is built from transistors • A transistor is a switch • It is either on or off • On or off can represent True or False Given a bunch of bits (0 or 1)… • Is this instruction a lw or a beq? • What register do I read? • How do I add two numbers? • Need a method to reason about complex expressions © Alvin R. Lebeck CPS 104 3 Review: Boolean Functions • Boolean functions have arguments that take two values ({T,F} or {0,1}) and they return a single or a set of ({T,F} or {0,1}) value(s). • Boolean functions can always be represented by a table called a “Truth Table” • Example: F: {0,1}3 -> {0,1}2 a b c f1f2 0 0 0 0 1 0 0 1 1 1 0 1 0 1 0 0 1 1 0 0 1 0 0 1 0 1 1 0 0 1 1 1 1 1 1 © Alvin R. Lebeck CPS 104 4 Review: Boolean Functions and Expressions F(A, B, C) = (A * B) + (~A * C) ABCF 0000 0011 0100 0111 1000 1010 1101 1111 © Alvin R. Lebeck CPS 104 5 Review: Boolean Gates • Gates are electronics devices that implement simple Boolean functions Examples a a AND(a,b) OR(a,b) a NOT(a) b b a XOR(a,b) a NAND(a,b) b b a NOR(a,b) a XNOR(a,b) b b © Alvin R. -

Implementation of Carry Tree Adders and Compare with RCA and CSLA
International Journal of Emerging Engineering Research and Technology Volume 4, Issue 1, January 2016, PP 1-11 ISSN 2349-4395 (Print) & ISSN 2349-4409 (Online) Implementation of Carry Tree Adders and Compare with RCA and CSLA 1 2 G. Venkatanaga Kumar , C.H Pushpalatha Department of ECE, GONNA INSTITUTE OF TECHNOLOGY, Vishakhapatnam, India (PG Scholar) Department of ECE, GONNA INSTITUTE OF TECHNOLOGY, Vishakhapatnam, India (Associate Professor) ABSTRACT The binary adder is the critical element in most digital circuit designs including digital signal processors (DSP) and microprocessor data path units. As such, extensive research continues to be focused on improving the power delay performance of the adder. In VLSI implementations, parallel-prefix adders are known to have the best performance. Binary adders are one of the most essential logic elements within a digital system. In addition, binary adders are also helpful in units other than Arithmetic Logic Units (ALU), such as multipliers, dividers and memory addressing. Therefore, binary addition is essential that any improvement in binary addition can result in a performance boost for any computing system and, hence, help improve the performance of the entire system. Parallel-prefix adders (also known as carry-tree adders) are known to have the best performance in VLSI designs. This paper investigates three types of carry-tree adders (the Kogge- Stone, sparse Kogge-Stone, Ladner-Fischer and spanning tree adder) and compares them to the simple Ripple Carry Adder (RCA) and Carry Skip Adder (CSA). In this project Xilinx-ISE tool is used for simulation, logical verification, and further synthesizing. This algorithm is implemented in Xilinx 13.2 version and verified using Spartan 3e kit. -
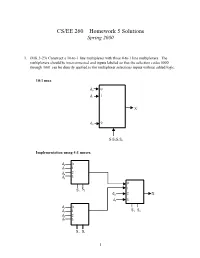
CS/EE 260 – Homework 5 Solutions Spring 2000
CS/EE 260 – Homework 5 Solutions Spring 2000 1. (MK 3-23) Construct a 10-to-1 line multiplexer with three 4-to-1 line multiplexers. The multiplexers should be interconnected and inputs labeled so that the selection codes 0000 through 1001 can be directly applied to the multiplexer selections inputs without added logic. 10:1 mux d0 0 1 d1 1 X d9 9 S3S2S1S0 Implementation using 4:1 muxes. d0 0 d2 1 d4 2 d6 3 0 S 1 S2 1 d8 2 X d9 3 d 0 1 S S d3 1 3 0 d5 2 d7 3 S2 S1 1 2. (MK 3-27) Implement a binary full adder with a dual 4-to-1 line multiplexer and a single inverter. AB Ci S Co 00 0 0 0 C 0 00 1 1 i 0 01 0 1 0 C ´ C 01 1 0 i 1 i 10 0 1 0 10 1 0Ci´ 1 Ci 11 0 0 1 C 1 11 1 1 i 1 0 C 1 i 4:1 2 S 3 mux S1 S0 A B 0 0 1 4:1 Co 2 mux 1 3 S1S0 2 3. (MK 3-34) Design a combinational circuit that forms the 2-bit binary sum S1S0 of two 2-bit numbers A1A0 and B1B0 and has both input C0 and a carry output C2. Do not use half adders or full adders, but instead use a two-level circuit plus inverters for the input variables, as needed. Design the circuit by starting with the following equations for each of the two bits of the adder. -

UNIT 8B a Full Adder
UNIT 8B Computer Organization: Levels of Abstraction 15110 Principles of Computing, 1 Carnegie Mellon University - CORTINA A Full Adder C ABCin Cout S in 0 0 0 A 0 0 1 0 1 0 B 0 1 1 1 0 0 1 0 1 C S out 1 1 0 1 1 1 15110 Principles of Computing, 2 Carnegie Mellon University - CORTINA 1 A Full Adder C ABCin Cout S in 0 0 0 0 0 A 0 0 1 0 1 0 1 0 0 1 B 0 1 1 1 0 1 0 0 0 1 1 0 1 1 0 C S out 1 1 0 1 0 1 1 1 1 1 ⊕ ⊕ S = A B Cin ⊕ ∧ ∨ ∧ Cout = ((A B) C) (A B) 15110 Principles of Computing, 3 Carnegie Mellon University - CORTINA Full Adder (FA) AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 4 Carnegie Mellon University - CORTINA 2 Another Full Adder (FA) http://students.cs.tamu.edu/wanglei/csce350/handout/lab6.html AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 5 Carnegie Mellon University - CORTINA 8-bit Full Adder A7 B7 A2 B2 A1 B1 A0 B0 1-bit 1-bit 1-bit 1-bit ... Cout Full Full Full Full Cin Adder Adder Adder Adder S7 S2 S1 S0 AB 8 ⁄ ⁄ 8 C 8-bit C out FA in ⁄ 8 S 15110 Principles of Computing, 6 Carnegie Mellon University - CORTINA 3 Multiplexer (MUX) • A multiplexer chooses between a set of inputs. D1 D 2 MUX F D3 D ABF 4 0 0 D1 AB 0 1 D2 1 0 D3 1 1 D4 http://www.cise.ufl.edu/~mssz/CompOrg/CDAintro.html 15110 Principles of Computing, 7 Carnegie Mellon University - CORTINA Arithmetic Logic Unit (ALU) OP 1OP 0 Carry In & OP OP 0 OP 1 F 0 0 A ∧ B 0 1 A ∨ B 1 0 A 1 1 A + B http://cs-alb-pc3.massey.ac.nz/notes/59304/l4.html 15110 Principles of Computing, 8 Carnegie Mellon University - CORTINA 4 Flip Flop • A flip flop is a sequential circuit that is able to maintain (save) a state. -

Design of High Speed and Low Power Six Transistor Full Adder Using Two Transistor Xor Gate
International Journal of Electronics, Communication & Instrumentation Engineering Research and Development (IJECIERD) ISSN 2249-684X Vol. 3, Issue 1, Mar 2013, 87-96 © TJPRC Pvt. Ltd. DESIGN OF HIGH SPEED AND LOW POWER SIX TRANSISTOR FULL ADDER USING TWO TRANSISTOR XOR GATE B. DILLI KUMAR, K. CHARAN KUMAR & T. NAVEEN KUMAR M. Tech (VLSI), Department of ECE, Sree Vidyanikethan Engineering College (Autonomous), Tirupati, India ABSTRACT Full adder is one of the major components in the design of many sophisticated hardware circuits. In this paper the full adder has been designed by using a new efficient design with less number of transistors. A 2 transistor XOR gate has been proposed with the help of two PMOS (Positive Metal Oxide Semiconductor) transistors. By using this 2T XOR gate the size of the full adder has been decreased to a large extent which can be implemented with only 6 transistors. The proposed full adder has a significant improvement in silicon area and power delay product when compared to the previous 8T full adder circuits. Further the proposed adder requires less area to perform a required logic function. Further, the proposed full adder has less power dissipation which makes it suitable for many of the low power applications and because of less area requirement the proposed design can be used in many of the portable applications also . KEYWORDS: Full Adder, XOR, Less Area, Speed, Low Power, Delay, Less Transistor Count, Low Power VLSI INTRODUCTION Full adder is one of the basic building blocks of many of the digital VLSI circuits. Several refinements has been made regarding its structure since its invention. -

Clock Gating for Power Optimization in ASIC Design Cycle: Theory & Practice
Clock Gating for Power Optimization in ASIC Design Cycle: Theory & Practice Jairam S, Madhusudan Rao, Jithendra Srinivas, Parimala Vishwanath, Udayakumar H, Jagdish Rao SoC Center of Excellence, Texas Instruments, India (sjairam, bgm-rao, jithendra, pari, uday, j-rao) @ti.com 1 AGENDA • Introduction • Combinational Clock Gating – State of the art – Open problems • Sequential Clock Gating – State of the art – Open problems • Clock Power Analysis and Estimation • Clock Gating In Design Flows JS/BGM – ISLPED08 2 AGENDA • Introduction • Combinational Clock Gating – State of the art – Open problems • Sequential Clock Gating – State of the art – Open problems • Clock Power Analysis and Estimation • Clock Gating In Design Flows JS/BGM – ISLPED08 3 Clock Gating Overview JS/BGM – ISLPED08 4 Clock Gating Overview • System level gating: Turn off entire block disabling all functionality. • Conditions for disabling identified by the designer JS/BGM – ISLPED08 4 Clock Gating Overview • System level gating: Turn off entire block disabling all functionality. • Conditions for disabling identified by the designer • Suspend clocks selectively • No change to functionality • Specific to circuit structure • Possible to automate gating at RTL or gate-level JS/BGM – ISLPED08 4 Clock Network Power JS/BGM – ISLPED08 5 Clock Network Power • Clock network power consists of JS/BGM – ISLPED08 5 Clock Network Power • Clock network power consists of – Clock Tree Buffer Power JS/BGM – ISLPED08 5 Clock Network Power • Clock network power consists of – Clock Tree Buffer -

Saber Eletrônica, Designers Pois Precisamos Comprovar Ao Meio Anunciante Estes Números E, Assim, Carlos C
editorial Editora Saber Ltda. Digital Freemium Edition Diretor Hélio Fittipaldi Nesta edição comemoramos o fantástico número de 258.395 downloads da edição 460 digital em PDF que tivemos nos primeiros 50 dias de circu- www.sabereletronica.com.br lação. Assim, esperamos atingir meio milhão em twitter.com/editora_saber seis meses. Na fase de teste, no ano passado, com Editor e Diretor Responsável a Edição Digital Gratuita que chamamos de “Digital Hélio Fittipaldi Conselho Editorial Freemium (Free + Premium) Edition”, já atingimos João Antonio Zuffo este marco e até ultrapassamos. Redação Fica aqui nosso agradecimento a todos os que Hélio Fittipaldi Augusto Heiss seguiram nosso apelo, para somente fazerem Revisão Técnica Eutíquio Lopez download das nossas edições através do link do Portal Saber Eletrônica, Designers pois precisamos comprovar ao meio anunciante estes números e, assim, Carlos C. Tartaglioni, Diego M. Gomes obtermos patrocínio para manter a edição digital gratuita. Publicidade Aproveitamos também para avisar aos nossos leitores de Portugal, Caroline Ferreira, cerca de 6.000 pessoas, que infelizmente os custos para enviarmos as Nikole Barros revistas impressas em papel têm sido altos e, por solicitação do nosso Colaboradores Alexandre Capelli, distribuidor, não enviaremos mais os exemplares impressos em papel Bruno Venâncio, para distribuição no mercado português e ex-colônias na África. César Cassiolato, Dante J. S. Conti, Em junho teremos a edição especial deste semestre e o assunto prin- Edriano C. de Araújo, cipal é a eletrônica embutida (embedded electronic), ou como dizem os Eutíquio Lopez, Tsunehiro Yamabe espanhóis e portugueses: electrónica embebida. Como marco teremos também no Centro de Exposições Transamérica em São Paulo, a 2ª edição da ESC Brazil 2012 e a 1ª MD&M, o maior evento de tecnologia para o mercado de design eletrônico que, neste ano, estará sendo promovido PARA ANUNCIAR: (11) 2095-5339 pela UBM junto com o primeiro evento para o setor médico/odontoló- [email protected] gico (a MD&M Brazil). -

Analysis of Body Bias Control Using Overhead Conditions for Real Time Systems: a Practical Approach∗
IEICE TRANS. INF. & SYST., VOL.E101–D, NO.4 APRIL 2018 1116 PAPER Analysis of Body Bias Control Using Overhead Conditions for Real Time Systems: A Practical Approach∗ Carlos Cesar CORTES TORRES†a), Nonmember, Hayate OKUHARA†, Student Member, Nobuyuki YAMASAKI†, Member, and Hideharu AMANO†, Fellow SUMMARY In the past decade, real-time systems (RTSs), which must in RTSs. These techniques can improve energy efficiency; maintain time constraints to avoid catastrophic consequences, have been however, they often require a large amount of power since widely introduced into various embedded systems and Internet of Things they must control the supply voltages of the systems. (IoTs). The RTSs are required to be energy efficient as they are used in embedded devices in which battery life is important. In this study, we in- Body bias (BB) control is another solution that can im- vestigated the RTS energy efficiency by analyzing the ability of body bias prove RTS energy efficiency as it can manage the tradeoff (BB) in providing a satisfying tradeoff between performance and energy. between power leakage and performance without affecting We propose a practical and realistic model that includes the BB energy and the power supply [4], [5].Itseffect is further endorsed when timing overhead in addition to idle region analysis. This study was con- ducted using accurate parameters extracted from a real chip using silicon systems are enabled with silicon on thin box (SOTB) tech- on thin box (SOTB) technology. By using the BB control based on the nology [6], which is a novel and advanced fully depleted sili- proposed model, about 34% energy reduction was achieved. -

Half Adder, Which Finds the Sum of Two Bits
CMSC 313 COMPUTER ORGANIZATION & ASSEMBLY LANGUAGE PROGRAMMING LECTURE 21, SPRING 2013 TOPICS TODAY • Circuits for Addition • Standard Logic Components • Logisim Demo CIRCUITS FOR ADDITION 3.5 Combinational Circuits • Combinational logic circuits give us many useful devices. • One of the simplest is the half adder, which finds the sum of two bits. • We can gain some insight as to the construction of a half adder by looking at its truth table, shown at the right. 30 Half Adder • Inputs: A and B • Outputs: S = lower bit of A + B, cout = carry bit A B S cout 0 0 0 0 0 1 1 0 1 0 1 0 1 1 0 1 • Using Sum-of-Products: S = AB + AB, cout = AB. • Alternatively, we could use XOR: S = A ⊕ B. ! ! ! ! 1 3.5 Combinational Circuits • As we see, the sum can be found using the XOR operation and the carry using the AND operation. 31 3.5 Combinational Circuits • We can change our half adder into to a full adder by including gates for processing the carry bit. • The truth table for a full adder is shown at the right. 32 Full Adder • Inputs: A, B and cin • Outputs: S = lower bit of A + B, cout = carry bit A B cin S cout 0 0 0 0 0 0 0 1 1 0 0 1 0 1 0 0 1 1 0 1 1 0 0 1 0 1 0 1 0 1 1 1 0 0 1 1 1 1 1 1 • S = A BC + ABC + AB C + ABC = A ⊕ B ⊕ C. -

Register Allocation and VDD-Gating Algorithms for Out-Of-Order
Register Allocation and VDD-Gating Algorithms for Out-of-Order Architectures Steven J. Battle and Mark Hempstead Drexel University Philadelphia, PA USA Email: [email protected], [email protected] Abstract—Register Files (RF) in modern out-of-order micro- 100 avg Int avg FP processors can account for up to 30% of total power consumed INT → → by the core. The complexity and size of the RF has increased due 80 FP to the transition from ROB-based to MIPSR10K-style physical register renaming. Because physical registers are dynamically 60 allocated, the RF is not fully occupied during every phase of the application. In this paper, we propose a comprehensive power 40 management strategy of the RF through algorithms for register allocation and register-bank power-gating that are informed by % of runtime 20 both microarchitecture details and circuit costs. We investigate algorithms to control where to place registers in the RF, when to 0 disable banks in the RF, and when to re-enable these banks. We 60 80 100 120 140 160 include detailed circuit models to estimate the cost for banking Num. Registers Occupied and power-gating the RF. We are able to save up to 50% of the leakage energy vs. a baseline monolithic RF, and save 11% more Fig. 1. Average Reg File occupancy CDF for SPEC2006 workloads. leakage energy than fine-grained VDD-gating schemes. 1 1 Index Terms—Computer architecture, Gate leakage, Registers, SRAM cells 0.8 0.8 I. INTRODUCTION 0.6 0.6 F.cactus I.astar 0.4 0.4 Out-of-order superscalar processors, historically found only F.gems I.libq in high-performance computing environments, are now used in F.milc I.go 0.2 F.pov 0.2 Imcf a diverse range of energy-constrained applications from smart- F.zeus Iomn phones to data-centers.