Erasure Coding and Cache Tiering
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Storage Administration Guide Storage Administration Guide SUSE Linux Enterprise Server 12 SP4
SUSE Linux Enterprise Server 12 SP4 Storage Administration Guide Storage Administration Guide SUSE Linux Enterprise Server 12 SP4 Provides information about how to manage storage devices on a SUSE Linux Enterprise Server. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents About This Guide xii 1 Available Documentation xii 2 Giving Feedback xiv 3 Documentation Conventions xiv 4 Product Life Cycle and Support xvi Support Statement for SUSE Linux Enterprise Server xvii • Technology Previews xviii I FILE SYSTEMS AND MOUNTING 1 1 Overview -
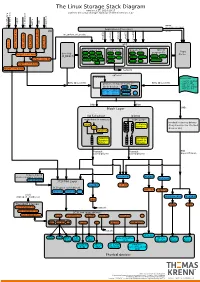
The Linux Storage Stack Diagram
The Linux Storage Stack Diagram version 3.17, 2014-10-17 outlines the Linux storage stack as of Kernel version 3.17 ISCSI USB mmap Fibre Channel Fibre over Ethernet Fibre Channel Fibre Virtual Host Virtual FireWire (anonymous pages) Applications (Processes) LIO malloc vfs_writev, vfs_readv, ... ... stat(2) read(2) open(2) write(2) chmod(2) VFS tcm_fc sbp_target tcm_usb_gadget tcm_vhost tcm_qla2xxx iscsi_target_mod block based FS Network FS pseudo FS special Page ext2 ext3 ext4 proc purpose FS target_core_mod direct I/O NFS coda sysfs Cache (O_DIRECT) xfs btrfs tmpfs ifs smbfs ... pipefs futexfs ramfs target_core_file iso9660 gfs ocfs ... devtmpfs ... ceph usbfs target_core_iblock target_core_pscsi network optional stackable struct bio - sector on disk BIOs (Block I/O) BIOs (Block I/O) - sector cnt devices on top of “normal” - bio_vec cnt block devices drbd LVM - bio_vec index - bio_vec list device mapper mdraid dm-crypt dm-mirror ... dm-cache dm-thin bcache BIOs BIOs Block Layer BIOs I/O Scheduler blkmq maps bios to requests multi queue hooked in device drivers noop Software (they hook in like stacked ... Queues cfq devices do) deadline Hardware Hardware Dispatch ... Dispatch Queue Queues Request Request BIO based Drivers based Drivers based Drivers request-based device mapper targets /dev/nullb* /dev/vd* /dev/rssd* dm-multipath SCSI Mid Layer /dev/rbd* null_blk SCSI upper level drivers virtio_blk mtip32xx /dev/sda /dev/sdb ... sysfs (transport attributes) /dev/nvme#n# /dev/skd* rbd Transport Classes nvme skd scsi_transport_fc network -

Unbreakable Enterprise Kernel Release Notes for Unbreakable Enterprise Kernel Release 3
Unbreakable Enterprise Kernel Release Notes for Unbreakable Enterprise Kernel Release 3 E48380-10 June 2020 Oracle Legal Notices Copyright © 2013, 2020, Oracle and/or its affiliates. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/or adaptation of i) Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oracle computer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in the license contained in the applicable contract. -

Parallel NFS (Pnfs)
Red Hat Enterprise 7 Beta File Systems New Scale, Speed & Features Ric Wheeler Director Red Hat Kernel File & Storage Team Red Hat Storage Engineering Agenda •Red Hat Enterprise Linux 7 Storage Features •Red Hat Enterprise Linux 7 Storage Management Features •Red Hat Enterprise Linux 7 File Systems •What is Parallel NFS? •Red Hat Enterprise Linux 7 NFS Red Hat Enterprise Linux 7 Storage Foundations Red Hat Enterprise Linux 6 File & Storage Foundations •Red Hat Enterprise Linux 6 provides key foundations for Red Hat Enterprise Linux 7 • LVM Support for Scalable Snapshots • Device Mapper Thin Provisioned Storage • Expanded options for file systems •Large investment in performance enhancements •First in industry support for Parallel NFS (pNFS) LVM Thinp and Snapshot Redesign •LVM thin provisioned LV (logical volume) • Eliminates the need to pre-allocate space • Logical Volume space allocated from shared pool as needed • Typically a high end, enterprise storage array feature • Makes re-sizing a file system almost obsolete! •New snapshot design, based on thinp • Space efficient and much more scalable • Blocks are allocated from the shared pool for COW operations • Multiple snapshots can have references to same COW data • Scales to many snapshots, snapshots of snapshots RHEL Storage Provisioning Improved Resource Utilization & Ease of Use Avoids wasting space Less administration * Lower costs * Traditional Provisioning RHEL Thin Provisioning Free Allocated Unused Volume 1 Space Available Allocation Storage { Data Pool { Volume 1 Volume 2 Allocated -

Oracle® Linux 7 Release Notes for Oracle Linux 7
Oracle® Linux 7 Release Notes for Oracle Linux 7 E53499-20 March 2021 Oracle Legal Notices Copyright © 2011,2021 Oracle and/or its affiliates. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/or adaptation of i) Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oracle computer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in the license contained in the applicable contract. -

Reliable Storage for HA, DR, Clouds and Containers Philipp Reisner, CEO LINBIT LINBIT - the Company Behind It
Reliable Storage for HA, DR, Clouds and Containers Philipp Reisner, CEO LINBIT LINBIT - the company behind it COMPANY OVERVIEW TECHNOLOGY OVERVIEW • Developer of DRBD • 100% founder owned • Offices in Europe and US • Team of 30 highly experienced Linux experts • Partner in Japan REFERENCES 25 Linux Storage Gems LVM, RAID, SSD cache tiers, deduplication, targets & initiators Linux's LVM logical volume snapshot logical volume Volume Group physical volume physical volume physical volume 25 Linux's LVM • based on device mapper • original objects • PVs, VGs, LVs, snapshots • LVs can scatter over PVs in multiple segments • thinlv • thinpools = LVs • thin LVs live in thinpools • multiple snapshots became efficient! 25 Linux's LVM thin-LV thin-LV thin-sLV LV snapshot thinpool VG PV PV PV 25 Linux's RAID RAID1 • original MD code • mdadm command A1 A1 • Raid Levels: 0,1,4,5,6,10 A2 A2 • Now available in LVM as well A3 A3 A4 A4 • device mapper interface for MD code • do not call it ‘dmraid’; that is software for hardware fake-raid • lvcreate --type raid6 --size 100G VG_name 25 SSD cache for HDD • dm-cache • device mapper module • accessible via LVM tools • bcache • generic Linux block device • slightly ahead in the performance game 25 Linux’s DeDupe • Virtual Data Optimizer (VDO) since RHEL 7.5 • Red hat acquired Permabit and is GPLing VDO • Linux upstreaming is in preparation • in-line data deduplication • kernel part is a device mapper module • indexing service runs in user-space • async or synchronous writeback • Recommended to be used below LVM 25 Linux’s targets & initiators • Open-ISCSI initiator IO-requests • Ietd, STGT, SCST Initiator Target data/completion • mostly historical • LIO • iSCSI, iSER, SRP, FC, FCoE • SCSI pass through, block IO, file IO, user-specific-IO • NVMe-OF • target & initiator 25 ZFS on Linux • Ubuntu eco-system only • has its own • logic volume manager (zVols) • thin provisioning • RAID (RAIDz) • caching for SSDs (ZIL, SLOG) • and a file system! 25 Put in simplest form DRBD – think of it as .. -

Chelsio Unified Wire for Linux I
Chelsio Unified Wire for Linux i This document and related products are distributed under licenses restricting their use, copying, distribution, and reverse-engineering. No part of this document may be reproduced in any form or by any means without prior written permission by Chelsio Communications. All third-party trademarks are copyright of their respective owners. THIS DOCUMENTATION IS PROVIDED “AS IS” AND WITHOUT ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, WITHOUT LIMITATION, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE USE OF THE SOFTWARE AND ANY ASSOCIATED MATERIALS (COLLECTIVELY THE “SOFTWARE”) IS SUBJECT TO THE SOFTWARE LICENSE TERMS OF CHELSIO COMMUNICATIONS, INC. Chelsio Communications (Headquarters) Chelsio (India) Private Limited Subramanya Arcade, Floor 3, Tower B 209 North Fair Oaks Avenue, Sunnyvale, CA 94085 No. 12, Bannerghatta Road, U.S.A Bangalore-560029 Karnataka, www.chelsio.com India Tel: 408.962.3600 Tel: +91-80-4039-6800 Fax: 408.962.3661 Chelsio KK (Japan) Yamato Building 8F, 5-27-3 Sendagaya, Shibuya-ku, Tokyo 151-0051, Japan Sales For all sales inquiries please send email to [email protected] Support For all support related questions please send email to [email protected] Copyright © 2018. Chelsio Communications. All Rights Reserved. Chelsio ® is a registered trademark of Chelsio Communications. All other marks and names mentioned herein may be trademarks of their respective companies. Chelsio Unified Wire for Linux ii Document History Version Revision Date 1.0.0 12/08/2011 -

Use Style: Paper Title
Exploiting Neighborhood Similarity for Virtual Machine Migration over Wide-Area Network Hsu-Fang Lai, Yu-Sung Wu*, and Yu-Jui Cheng Department of Computer Science National Chiao Tung University, Taiwan [email protected], [email protected], [email protected] Abstract—Conventional virtual machine (VM) migration regions have different times for peak workloads. We can thus focuses on transferring a VM’s memory and CPU states across improve resource utilization through load balancing across host machines. The VM’s disk image has to remain accessible datacenters in different geographic regions. And, for the to both the source and destination host machines through purpose of fault tolerance, the ability of VM migration across shared storage during the migration. As a result, conventional geographic regions can improve resilience against virtual machine migration is limited to host machines on the geographic region related failures. For instance, if a region is same local area network (LAN) since sharing storage across expecting a hurricane, we can migrate the VMs away from wide-area network (WAN) is inefficient. As datacenters are the region to a datacenter that is not on the path of the being constructed around the globe, we envision the need for hurricane. VM migration across datacenter boundaries. We thus propose However, it is not feasible to apply existing VM a system aiming to achieve efficient VM migration over wide area network. The system exploits similarity in the storage migration mechanisms in a wide-area network environment. data of neighboring VMs by first indexing the VM storage A shared storage across WAN would be rather inefficient images and then using the index to locate storage data blocks due to the limited bandwidth and the long transmission from neighboring VMs, as opposed to pulling all data from the latency of WAN. -

ZEA, a Data Management Approach for SMR
ZEA, A Data Management Approach for SMR Adam Manzanares Co-Authors • Western Digital Research – Cyril Guyot, Damien Le Moal, Zvonimir Bandic • University of California, Santa Cruz – Noah Watkins, Carlos Maltzahn ©2016 Western Digital Corporation or affiliates. All rights reserved. 2 Why SMR ? • HDDs are not going away – Exponential growth of data still exists – $/TB vs. Flash is still much lower – We want to continue this trend! • Traditional Recording (PMR) is reaching scalability limits – SMR is a density enhancing technology being shipped right now. • Future recording technologies may behave like SMR – Write constraint similarities – HAMR ©2016 Western Digital Corporation or affiliates. All rights reserved. 3 Flavors of SMR • SMR Constraint – Writes must be sequential to avoid data loss • Drive Managed – Transparent to the user – Comes at the cost of predictability and additional drive resources • Host Aware – Host is aware of SMR working model – If user does something “wrong” the drive will fix the problem internally • Host Managed – Host is aware of SMR working model – If user does something “wrong” the drive will reject the IO request ©2016 Western Digital Corporation or affiliates. All rights reserved. 4 SMR Drive Device Model • New SCSI standard Zoned Block Commands (ZBC) – SATA equivalent ZAC • Drive described by zones and their restrictions Type Write Intended Use Con Abbreviation Restriction Conventional None In-place updates Increased CZ Resources Sequential None Mostly sequential Variable SPZ Preferred writes Performance Sequential Sequential Write Only sequential SRZ Required writes • Our user space library (libzbc) queries zone information from the drive – https://github.com/hgst/libzbc ©2016 Western Digital Corporation or affiliates. -

Storage Administration Guide Storage Administration Guide SUSE Linux Enterprise Server 15 SP2
SUSE Linux Enterprise Server 15 SP2 Storage Administration Guide Storage Administration Guide SUSE Linux Enterprise Server 15 SP2 Provides information about how to manage storage devices on a SUSE Linux Enterprise Server. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents About This Guide xii 1 Available Documentation xii 2 Giving Feedback xiv 3 Documentation Conventions xiv 4 Product Life Cycle and Support xvi Support Statement for SUSE Linux Enterprise Server xvii • Technology Previews xviii I FILE SYSTEMS AND MOUNTING 1 1 Overview -

Zoned Linux Ecosystem Overview
Linux Zoned Block Device Ecosystem: No longer exotic Dmitry Fomichev Western Digital Research, System Software Group October 2019 © 2019 Western Digital Corporation or its affiliates. All rights reserved. 10/2/2019 Outline • Why zoned block devices (ZBD)? – SMR recording and zoned models • Support in Linux - status overview – Standards and kernel – Application support • Kernel support details – Overview, Block layer, File systems and device-mapper, Known problems • Application support details – SG Tools, libzbc, fio, etc. • ZNS – Why zones for flash? ZNS vs. ZBD, ZNS use cases • Ongoing Work and Next Steps © 2019 Western Digital Corporation or its affiliates. All rights reserved. 10/2/2019 2 What are Zoned Block Devices? Zoned device access model • The storage device logical block addresses Device LBA range divided in zones are divided into ranges of zones • Zone size is much larger than LBA size Zone 0 Zone 1 Zone 2 Zone 3 Zone X – E.g. 256 MB on today’s SMR disks • Zone size is fixed • Reads can be done in the usual manner Write commands • Writes within a zone must be sequential Write pointer advance the write pointer • A zone must be erased before it can be position rewritten Reset write pointer commands • Zones are identified by their start LBA rewind the write pointer © 2019 Western Digital Corporation or its affiliates. All rights reserved. 10/2/2019 3 What are Zoned Block Devices? Accommodate advanced recording technology • Shingled Magnetic Recording (SMR) disks Conventional PMR HDD SMR HDD – Enables higher areal density Discrete Tracks Overlapped Tracks – Wider write head produces stronger field, enabling smaller grains and lower noise – Better sector erasure coding, more powerful … data detection and recovery • Zoned Access – Random reads to the device are allowed – But writes within zones must be sequential Zone – Zones can be rewritten from the beginning after erasing – Additional commands are needed • Some zones of the device can still be PMR – Conventional Zones © 2019 Western Digital Corporation or its affiliates. -

Zielstrebig Artikel Zeigt, Wieadmins Damitflexiblere Undschnellere Fileserver Aufsetzen
05/2011 Das modulare Multiprotocol Storage Target im Linux-Kernel Sysadmin Zielstrebig I-SCSI 66 Mit Version 2.6.38 hält ein modular aufgebautes I-SCSI Storage Target Einzug in den offiziellen Kernel. Dieser Artikel zeigt, wie Admins damit flexiblere und schnellere Fileserver aufsetzen. Kai-Thorsten Hambrecht www.linux-magazin.de (FC), Fibre Channel over Zu den Fabric Modules als Protokolltrei- Ethernet (FCoE) oder Infi- ber des Framework gehören neben dem niband (IB) und eignet sich namengebenden I-SCSI unter anderem damit zum Einrichten flexi- auch FCoE, Fibre Channel mit Host Bus bler Storage Area Networks Adaptern (HBA) der Qla2xxx-Serie von (SAN). Qlogic, Infiniband oder ein Loopback- Seine Leistungsfähigkeit stellt Modul. Die I-SCSI-Implementierung ist das Lio-Target in Storage-Ap- bereits erfolgreich für VMware ESX 4.0 pliances von Netgear, QNAP und VMware V-Sphere 4.0 zertifiziert, oder Synology unter Beweis. funktioniert aber auch bestens mit dem Der folgende Workshop gibt nativen Initiator von Virtualbox. einen Überblick über Archi- tektur, Installation sowie die Einzug in den Kernel Konfiguration und lässt sich am besten mit der virtuellen Den Anfang im SCSI-Subsystem des Ker- Maschine auf der Linux-Ma- nels 2.6.38 [6] macht zunächst das Tar- gazin-DVD nachvollziehen get Core Module (TCM, [7]). Mit 2.6.39 (siehe Kasten „Lio-I-SCSI“). sollen die Protokolltreiber für I-SCSI, FC für Qlogic HBA sowie FCoE folgen. Da- Lio-Framework mit ersetzt langfristig das Lio-Target das bereits im Kernel enthaltene STGT (SCSI Lio ist modular aufgebaut Target Framework). und besteht aus dem Target Zur Konfiguration nutzen TCM und die Core Module (TCM), das zum zugehörigen Protokolltreiber das mit © Jeff Crow, 123RF.com Crow, © Jeff einen mit der Generic Tar- Kernel 2.6.15 im Rahmen von OCFS2 get Engine die grundlegende eingeführte Config-FS.