Network-Based Identification of Genetic Factors in Ageing, Lifestyle
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Whole-Genome Microarray Detects Deletions and Loss of Heterozygosity of Chromosome 3 Occurring Exclusively in Metastasizing Uveal Melanoma
Anatomy and Pathology Whole-Genome Microarray Detects Deletions and Loss of Heterozygosity of Chromosome 3 Occurring Exclusively in Metastasizing Uveal Melanoma Sarah L. Lake,1 Sarah E. Coupland,1 Azzam F. G. Taktak,2 and Bertil E. Damato3 PURPOSE. To detect deletions and loss of heterozygosity of disease is fatal in 92% of patients within 2 years of diagnosis. chromosome 3 in a rare subset of fatal, disomy 3 uveal mela- Clinical and histopathologic risk factors for UM metastasis noma (UM), undetectable by fluorescence in situ hybridization include large basal tumor diameter (LBD), ciliary body involve- (FISH). ment, epithelioid cytomorphology, extracellular matrix peri- ϩ ETHODS odic acid-Schiff-positive (PAS ) loops, and high mitotic M . Multiplex ligation-dependent probe amplification 3,4 5 (MLPA) with the P027 UM assay was performed on formalin- count. Prescher et al. showed that a nonrandom genetic fixed, paraffin-embedded (FFPE) whole tumor sections from 19 change, monosomy 3, correlates strongly with metastatic death, and the correlation has since been confirmed by several disomy 3 metastasizing UMs. Whole-genome microarray analy- 3,6–10 ses using a single-nucleotide polymorphism microarray (aSNP) groups. Consequently, fluorescence in situ hybridization were performed on frozen tissue samples from four fatal dis- (FISH) detection of chromosome 3 using a centromeric probe omy 3 metastasizing UMs and three disomy 3 tumors with Ͼ5 became routine practice for UM prognostication; however, 5% years’ metastasis-free survival. to 20% of disomy 3 UM patients unexpectedly develop metas- tases.11 Attempts have therefore been made to identify the RESULTS. Two metastasizing UMs that had been classified as minimal region(s) of deletion on chromosome 3.12–15 Despite disomy 3 by FISH analysis of a small tumor sample were found these studies, little progress has been made in defining the key on MLPA analysis to show monosomy 3. -

Multifactorial Erβ and NOTCH1 Control of Squamous Differentiation and Cancer
Multifactorial ERβ and NOTCH1 control of squamous differentiation and cancer Yang Sui Brooks, … , Karine Lefort, G. Paolo Dotto J Clin Invest. 2014;124(5):2260-2276. https://doi.org/10.1172/JCI72718. Research Article Oncology Downmodulation or loss-of-function mutations of the gene encoding NOTCH1 are associated with dysfunctional squamous cell differentiation and development of squamous cell carcinoma (SCC) in skin and internal organs. While NOTCH1 receptor activation has been well characterized, little is known about how NOTCH1 gene transcription is regulated. Using bioinformatics and functional screening approaches, we identified several regulators of the NOTCH1 gene in keratinocytes, with the transcription factors DLX5 and EGR3 and estrogen receptor β (ERβ) directly controlling its expression in differentiation. DLX5 and ERG3 are required for RNA polymerase II (PolII) recruitment to the NOTCH1 locus, while ERβ controls NOTCH1 transcription through RNA PolII pause release. Expression of several identified NOTCH1 regulators, including ERβ, is frequently compromised in skin, head and neck, and lung SCCs and SCC-derived cell lines. Furthermore, a keratinocyte ERβ–dependent program of gene expression is subverted in SCCs from various body sites, and there are consistent differences in mutation and gene-expression signatures of head and neck and lung SCCs in female versus male patients. Experimentally increased ERβ expression or treatment with ERβ agonists inhibited proliferation of SCC cells and promoted NOTCH1 expression and squamous differentiation both in vitro and in mouse xenotransplants. Our data identify a link between transcriptional control of NOTCH1 expression and the estrogen response in keratinocytes, with implications for differentiation therapy of squamous cancer. Find the latest version: https://jci.me/72718/pdf Research article Multifactorial ERβ and NOTCH1 control of squamous differentiation and cancer Yang Sui Brooks,1,2 Paola Ostano,3 Seung-Hee Jo,1,2 Jun Dai,1,2 Spiro Getsios,4 Piotr Dziunycz,5 Günther F.L. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

The Capacity of Long-Term in Vitro Proliferation of Acute Myeloid
The Capacity of Long-Term in Vitro Proliferation of Acute Myeloid Leukemia Cells Supported Only by Exogenous Cytokines Is Associated with a Patient Subset with Adverse Outcome Annette K. Brenner, Elise Aasebø, Maria Hernandez-Valladares, Frode Selheim, Frode Berven, Ida-Sofie Grønningsæter, Sushma Bartaula-Brevik and Øystein Bruserud Supplementary Material S2 of S31 Table S1. Detailed information about the 68 AML patients included in the study. # of blasts Viability Proliferation Cytokine Viable cells Change in ID Gender Age Etiology FAB Cytogenetics Mutations CD34 Colonies (109/L) (%) 48 h (cpm) secretion (106) 5 weeks phenotype 1 M 42 de novo 241 M2 normal Flt3 pos 31.0 3848 low 0.24 7 yes 2 M 82 MF 12.4 M2 t(9;22) wt pos 81.6 74,686 low 1.43 969 yes 3 F 49 CML/relapse 149 M2 complex n.d. pos 26.2 3472 low 0.08 n.d. no 4 M 33 de novo 62.0 M2 normal wt pos 67.5 6206 low 0.08 6.5 no 5 M 71 relapse 91.0 M4 normal NPM1 pos 63.5 21,331 low 0.17 n.d. yes 6 M 83 de novo 109 M1 n.d. wt pos 19.1 8764 low 1.65 693 no 7 F 77 MDS 26.4 M1 normal wt pos 89.4 53,799 high 3.43 2746 no 8 M 46 de novo 26.9 M1 normal NPM1 n.d. n.d. 3472 low 1.56 n.d. no 9 M 68 MF 50.8 M4 normal D835 pos 69.4 1640 low 0.08 n.d. -

A Flexible Microfluidic System for Single-Cell Transcriptome Profiling
www.nature.com/scientificreports OPEN A fexible microfuidic system for single‑cell transcriptome profling elucidates phased transcriptional regulators of cell cycle Karen Davey1,7, Daniel Wong2,7, Filip Konopacki2, Eugene Kwa1, Tony Ly3, Heike Fiegler2 & Christopher R. Sibley 1,4,5,6* Single cell transcriptome profling has emerged as a breakthrough technology for the high‑resolution understanding of complex cellular systems. Here we report a fexible, cost‑efective and user‑ friendly droplet‑based microfuidics system, called the Nadia Instrument, that can allow 3′ mRNA capture of ~ 50,000 single cells or individual nuclei in a single run. The precise pressure‑based system demonstrates highly reproducible droplet size, low doublet rates and high mRNA capture efciencies that compare favorably in the feld. Moreover, when combined with the Nadia Innovate, the system can be transformed into an adaptable setup that enables use of diferent bufers and barcoded bead confgurations to facilitate diverse applications. Finally, by 3′ mRNA profling asynchronous human and mouse cells at diferent phases of the cell cycle, we demonstrate the system’s ability to readily distinguish distinct cell populations and infer underlying transcriptional regulatory networks. Notably this provided supportive evidence for multiple transcription factors that had little or no known link to the cell cycle (e.g. DRAP1, ZKSCAN1 and CEBPZ). In summary, the Nadia platform represents a promising and fexible technology for future transcriptomic studies, and other related applications, at cell resolution. Single cell transcriptome profling has recently emerged as a breakthrough technology for understanding how cellular heterogeneity contributes to complex biological systems. Indeed, cultured cells, microorganisms, biopsies, blood and other tissues can be rapidly profled for quantifcation of gene expression at cell resolution. -
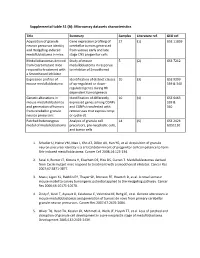
Supplemental Table S1 (A): Microarray Datasets Characteristics
Supplemental table S1 (A): Microarray datasets characteristics Title Summary Samples Literature ref. GEO ref. Acquisition of granule Gene expression profiling of 27 (1) GSE 11859 neuron precursor identity cerebellar tumors generated and Hedgehog‐induced from various early and late medulloblastoma in mice. stage CNS progenitor cells Medulloblastomas derived Study of mouse 5 (2) GSE 7212 from Cxcr6 mutant mice medulloblastoma in response respond to treatment with to inhibitor of Smoothened a Smoothened inhibitor Expression profiles of Identification of distinct classes 10 (3) GSE 9299 mouse medulloblastoma of up‐regulated or down‐ 339 & 340 regulated genes during Hh dependent tumorigenesis Genetic alterations in Identification of differently 10 (4) GSE 6463 mouse medulloblastomas expressed genes among CGNPs 339 & and generation of tumors and CGNPs transfected with 340 from cerebellar granule retroviruses that express nmyc neuron precursors or cyclin‐d1 Patched heterozygous Analysis of granule cell 14 (5) GSE 2426 model of medulloblastoma precursors, pre‐neoplastic cells, GDS1110 and tumor cells 1. Schuller U, Heine VM, Mao J, Kho AT, Dillon AK, Han YG, et al. Acquisition of granule neuron precursor identity is a critical determinant of progenitor cell competence to form Shh‐induced medulloblastoma. Cancer Cell 2008;14:123‐134. 2. Sasai K, Romer JT, Kimura H, Eberhart DE, Rice DS, Curran T. Medulloblastomas derived from Cxcr6 mutant mice respond to treatment with a smoothened inhibitor. Cancer Res 2007;67:3871‐3877. 3. Mao J, Ligon KL, Rakhlin EY, Thayer SP, Bronson RT, Rowitch D, et al. A novel somatic mouse model to survey tumorigenic potential applied to the Hedgehog pathway. Cancer Res 2006;66:10171‐10178. -

Datasheet Blank Template
SAN TA C RUZ BI OTEC HNOL OG Y, INC . Fe65L (Y-14): sc-104237 BACKGROUND PRODUCT Fe65L (Fe65-like protein), also known as APBB2 (amyloid β (A4) precursor Each vial contains 200 µg IgG in 1.0 ml of PBS with < 0.1% sodium azide protein-binding, family B, member 2), is a 758 amino acid protein that contains and 0.1% gelatin. one WW domain and 2 PID domains. Binding to the intracellular domain of Blocking peptide available for competition studies, sc-104237 P, (100 µg the -amyloid precursor protein, Fe65L is thought to modulate the internal - β peptide in 0.5 ml PBS containing < 0.1% sodium azide and 0.2% BSA). ization and, therefore, the accessibility and function of β-amyloid. Via its ability to control the intracellular accumulation of -amyloid, Fe65L is thought β APPLICATIONS to play a role in the pathogenesis of Alzheimer’s disease. Multiple isoforms of Fe65L exist due to alternative splicing events. The gene encoding Fe65L Fe65L (Y-14) is recommended for detection of Fe65L of mouse, rat and maps to human chromosome 4, which encodes nearly 6% of the human human origin by Western Blotting (starting dilution 1:200, dilution range genome and has the largest gene deserts (regions of the genome with no 1:100-1:1000), immunoprecipitation [1-2 µg per 100-500 µg of total protein protein encoding genes) of all of the human chromosomes. Defects in some (1 ml of cell lysate)], immunofluorescence (starting dilution 1:50, dilution of the genes located on chromosome 4 are associated with Huntington’s range 1:50-1:500) and solid phase ELISA (starting dilution 1:30, dilution dis ease, Ellis-van Creveld syndrome, methylmalonic acidemia and polycystic range 1:30-1:3000). -

G Protein-Coupled Receptors
G PROTEIN-COUPLED RECEPTORS Overview:- The completion of the Human Genome Project allowed the identification of a large family of proteins with a common motif of seven groups of 20-24 hydrophobic amino acids arranged as α-helices. Approximately 800 of these seven transmembrane (7TM) receptors have been identified of which over 300 are non-olfactory receptors (see Frederikson et al., 2003; Lagerstrom and Schioth, 2008). Subdivision on the basis of sequence homology allows the definition of rhodopsin, secretin, adhesion, glutamate and Frizzled receptor families. NC-IUPHAR recognizes Classes A, B, and C, which equate to the rhodopsin, secretin, and glutamate receptor families. The nomenclature of 7TM receptors is commonly used interchangeably with G protein-coupled receptors (GPCR), although the former nomenclature recognises signalling of 7TM receptors through pathways not involving G proteins. For example, adiponectin and membrane progestin receptors have some sequence homology to 7TM receptors but signal independently of G-proteins and appear to reside in membranes in an inverted fashion compared to conventional GPCR. Additionally, the NPR-C natriuretic peptide receptor has a single transmembrane domain structure, but appears to couple to G proteins to generate cellular responses. The 300+ non-olfactory GPCR are the targets for the majority of drugs in clinical usage (Overington et al., 2006), although only a minority of these receptors are exploited therapeutically. Signalling through GPCR is enacted by the activation of heterotrimeric GTP-binding proteins (G proteins), made up of α, β and γ subunits, where the α and βγ subunits are responsible for signalling. The α subunit (tabulated below) allows definition of one series of signalling cascades and allows grouping of GPCRs to suggest common cellular, tissue and behavioural responses. -

Identification of Potential Key Genes and Pathway Linked with Sporadic Creutzfeldt-Jakob Disease Based on Integrated Bioinformatics Analyses
medRxiv preprint doi: https://doi.org/10.1101/2020.12.21.20248688; this version posted December 24, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. Identification of potential key genes and pathway linked with sporadic Creutzfeldt-Jakob disease based on integrated bioinformatics analyses Basavaraj Vastrad1, Chanabasayya Vastrad*2 , Iranna Kotturshetti 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karanataka, India. 3. Department of Ayurveda, Rajiv Gandhi Education Society`s Ayurvedic Medical College, Ron, Karnataka 562209, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India NOTE: This preprint reports new research that has not been certified by peer review and should not be used to guide clinical practice. medRxiv preprint doi: https://doi.org/10.1101/2020.12.21.20248688; this version posted December 24, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. Abstract Sporadic Creutzfeldt-Jakob disease (sCJD) is neurodegenerative disease also called prion disease linked with poor prognosis. The aim of the current study was to illuminate the underlying molecular mechanisms of sCJD. The mRNA microarray dataset GSE124571 was downloaded from the Gene Expression Omnibus database. Differentially expressed genes (DEGs) were screened. -

Screening of Potential Genes and Transcription Factors Of
ANIMAL STUDY e-ISSN 1643-3750 © Med Sci Monit, 2018; 24: 503-510 DOI: 10.12659/MSM.907445 Received: 2017.10.08 Accepted: 2018.01.01 Screening of Potential Genes and Transcription Published: 2018.01.25 Factors of Postoperative Cognitive Dysfunction via Bioinformatics Methods Authors’ Contribution: ABE 1 Yafeng Wang 1 Department of Anesthesiology, The First Affiliated Hospital of Guangxi Medical Study Design A AB 1 Ailan Huang University, Nanning, Guangxi, P.R. China Data Collection B 2 Department of Gynecology, People’s Hospital of Guangxi Zhuang Autonomous Statistical Analysis C BEF 1 Lixia Gan Region, The First Affiliated Hospital of Guangxi Medical University, Nanning, Data Interpretation D BCF 1 Yanli Bao Guangxi, P.R. China Manuscript Preparation E BDF 1 Weilin Zhu 3 Department of Anesthesiology, The First Affiliated Hospital of Guangxi Medical Literature Search F University, Nanning, Guangxi, P.R. China Funds Collection G EF 1 Yanyan Hu AE 1 Li Ma CF 2 Shiyang Wei DE 3 Yuyan Lan Corresponding Author: Yafeng Wang, e-mail: [email protected] Source of support: Departmental sources Background: The aim of this study was to explore the potential genes and transcription factors involved in postoperative cognitive dysfunction (POCD) via bioinformatics analysis. Material/Methods: GSE95070 miRNA expression profiles were downloaded from Gene Expression Omnibus database, which in- cluded five hippocampal tissues from POCD mice and controls. Moreover, the differentially expressed miRNAs (DEMs) between the two groups were identified. In addition, the target genes of DEMs were predicted using Targetscan 7.1, followed by protein-protein interaction (PPI) network construction, functional enrichment anal- ysis, pathway analysis, and prediction of transcription factors (TFs) targeting the potential targets. -

REVIEW ARTICLE the Genetics of Autism
REVIEW ARTICLE The Genetics of Autism Rebecca Muhle, BA*; Stephanie V. Trentacoste, BA*; and Isabelle Rapin, MD‡ ABSTRACT. Autism is a complex, behaviorally de- tribution of a few well characterized X-linked disorders, fined, static disorder of the immature brain that is of male-to-male transmission in a number of families rules great concern to the practicing pediatrician because of an out X-linkage as the prevailing mode of inheritance. The astonishing 556% reported increase in pediatric preva- recurrence rate in siblings of affected children is ϳ2% to lence between 1991 and 1997, to a prevalence higher than 8%, much higher than the prevalence rate in the general that of spina bifida, cancer, or Down syndrome. This population but much lower than in single-gene diseases. jump is probably attributable to heightened awareness Twin studies reported 60% concordance for classic au- and changing diagnostic criteria rather than to new en- tism in monozygotic (MZ) twins versus 0 in dizygotic vironmental influences. Autism is not a disease but a (DZ) twins, the higher MZ concordance attesting to ge- syndrome with multiple nongenetic and genetic causes. netic inheritance as the predominant causative agent. By autism (the autistic spectrum disorders [ASDs]), we Reevaluation for a broader autistic phenotype that in- mean the wide spectrum of developmental disorders cluded communication and social disorders increased characterized by impairments in 3 behavioral domains: 1) concordance remarkably from 60% to 92% in MZ twins social interaction; 2) language, communication, and and from 0% to 10% in DZ pairs. This suggests that imaginative play; and 3) range of interests and activities. -

Accelerating Matchmaking of Novel Dysmorphology Syndromes Through Clinical and Genomic Characterization of a Large Cohort
ORIGINAL RESEARCH ARTICLE © American College of Medical Genetics and Genomics Accelerating matchmaking of novel dysmorphology syndromes through clinical and genomic characterization of a large cohort Ranad Shaheen, PhD1, Nisha Patel, PhD1, Hanan Shamseldin, MSc1, Fatema Alzahrani, BSc1, Ruah Al-Yamany, MD1, Agaadir ALMoisheer, MSc1, Nour Ewida, BSc1, Shamsa Anazi, MSc1, Maha Alnemer, MD2, Mohamed Elsheikh, MD3, Khaled Alfaleh, MD3,4, Muneera Alshammari, MD4, Amal Alhashem, MD5, Abdullah A. Alangari, MD4, Mustafa A. Salih, MD4, Martin Kircher, MD6, Riza M. Daza, PhD6, Niema Ibrahim, BSc1, Salma M. Wakil, PhD1, Ahmed Alaqeel, MD7, Ikhlas Altowaijri, MD7, Jay Shendure, MD, PhD6, Amro Al-Habib, MD7, Eissa Faqieh, MD8 and Fowzan S. Alkuraya, MD1,9 Purpose: Dysmorphology syndromes are among the most common and C3ORF17). A significant minority of the phenotypes (6/31, 19%), referrals to clinical genetics specialists. Inability to match the dysmor- however, were caused by genes known to cause Mendelian pheno- phology pattern to a known syndrome can pose a major diagnostic chal- types, thus expanding the phenotypic spectrum of the diseases linked lenge. With an aim to accelerate the establishment of new syndromes to these genes. The conspicuous inheritance pattern and the highly and their genetic etiology, we describe our experience with multiplex specific phenotypes appear to have contributed to the high yield consanguineous families that appeared to represent novel autosomal (90%) of plausible molecular diagnoses in our study cohort. recessive dysmorphology syndromes at the time of evaluation. Conclusion: Reporting detailed clinical and genomic analysis of Methods: Combined autozygome/exome analysis of multiplex a large series of apparently novel dysmorphology syndromes will consanguineous families with apparently novel dysmorphology syn- likely lead to a trend to accelerate the establishment of novel syn- dromes.