Modelling Space and Time in Historical Texts Gregory, Ian N.; Donaldson, Christopher; Hardie, Andrew; Rayson, Paul
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Folk Song in Cumbria: a Distinctive Regional
FOLK SONG IN CUMBRIA: A DISTINCTIVE REGIONAL REPERTOIRE? A dissertation submitted in partial fulfilment of the degree of Doctor of Philosophy by Susan Margaret Allan, MA (Lancaster), BEd (London) University of Lancaster, November 2016 ABSTRACT One of the lacunae of traditional music scholarship in England has been the lack of systematic study of folk song and its performance in discrete geographical areas. This thesis endeavours to address this gap in knowledge for one region through a study of Cumbrian folk song and its performance over the past two hundred years. Although primarily a social history of popular culture, with some elements of ethnography and a little musicology, it is also a participant-observer study from the personal perspective of one who has performed and collected Cumbrian folk songs for some forty years. The principal task has been to research and present the folk songs known to have been published or performed in Cumbria since circa 1900, designated as the Cumbrian Folk Song Corpus: a body of 515 songs from 1010 different sources, including manuscripts, print, recordings and broadcasts. The thesis begins with the history of the best-known Cumbrian folk song, ‘D’Ye Ken John Peel’ from its date of composition around 1830 through to the late twentieth century. From this narrative the main themes of the thesis are drawn out: the problem of defining ‘folk song’, given its eclectic nature; the role of the various collectors, mediators and performers of folk songs over the years, including myself; the range of different contexts in which the songs have been performed, and by whom; the vexed questions of ‘authenticity’ and ‘invented tradition’, and the extent to which this repertoire is a distinctive regional one. -

Office of the Police and Crime Commissioner for Cumbria - Pcc Expenses
OFFICE OF THE POLICE AND CRIME COMMISSIONER FOR CUMBRIA - PCC EXPENSES Name: Peter McCall Month: January 2018 Date Reason/Event Location Mode of Cost Accommodation Other Total Travel 30/01/2018 – NCA meeting London Train £107.00 VSC £102.50 Tube £12.70 £275.85 31/01/2018 Tube £12.70 M&S £16.95 Car Park £24.00 Total £107.00 £102.50 £66.35 £275.85 OFFICE OF THE POLICE AND CRIME COMMISSIONER FOR CUMBRIA - PCC EXPENSES Name: Peter McCall Month: February 2018 Date Reason/Event Location Mode of Cost Accommodation Other Total Travel Total Nil Return Nil Return Nil Return Nil Return OFFICE OF THE POLICE AND CRIME COMMISSIONER FOR CUMBRIA - PCC EXPENSES Name: Peter McCall Month: March 2018 Date Reason/Event Location Mode of Cost Accommodation Other Total Travel 19/01/2018 Penrith Show Ainstable Own 33 miles @ 44 £14.52 Annual Dinner vehicle ppm £14.52 06/02/2018 Internet Safety Day Cockermouth Own 51 miles @ 44 £22.44 at Cockermouth vehicle ppm £22.44 School 07/02/2018 Meet the Police Carlisle Own 36 miles @ 44 £15.84 event in Carlisle vehicle ppm £15.84 13/02/2018 U3A Speaking Ulverston Pool car Car park £3.20 £3.20 Engagement 15/02/2018 Army Cadets event Cockermouth Own 52 miles @ 44 £22.88 vehicle ppm £22.88 22/02/2018 Attend Operation Longtown Own 53 miles @ 44 £23.32 ‘Running Bear’ vehicle ppm £23.32 12/03/2018 Meetings with Carlisle Pool car Car park £ 1.90 £1.90 Cumbria County Council and Carlisle City Council 15/03/2018 Visit Cockermouth Cockermouth Own 52 miles @ 44 Car park £1.20 £24.08 Mountain Rescue vehicle ppm £22.88 22/03/2018 Media -
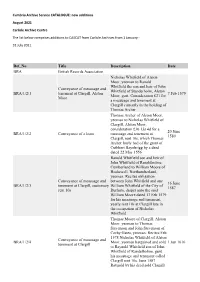
New Additions to CASCAT from Carlisle Archives
Cumbria Archive Service CATALOGUE: new additions August 2021 Carlisle Archive Centre The list below comprises additions to CASCAT from Carlisle Archives from 1 January - 31 July 2021. Ref_No Title Description Date BRA British Records Association Nicholas Whitfield of Alston Moor, yeoman to Ranald Whitfield the son and heir of John Conveyance of messuage and Whitfield of Standerholm, Alston BRA/1/2/1 tenement at Clargill, Alston 7 Feb 1579 Moor, gent. Consideration £21 for Moor a messuage and tenement at Clargill currently in the holding of Thomas Archer Thomas Archer of Alston Moor, yeoman to Nicholas Whitfield of Clargill, Alston Moor, consideration £36 13s 4d for a 20 June BRA/1/2/2 Conveyance of a lease messuage and tenement at 1580 Clargill, rent 10s, which Thomas Archer lately had of the grant of Cuthbert Baynbrigg by a deed dated 22 May 1556 Ranold Whitfield son and heir of John Whitfield of Ranaldholme, Cumberland to William Moore of Heshewell, Northumberland, yeoman. Recites obligation Conveyance of messuage and between John Whitfield and one 16 June BRA/1/2/3 tenement at Clargill, customary William Whitfield of the City of 1587 rent 10s Durham, draper unto the said William Moore dated 13 Feb 1579 for his messuage and tenement, yearly rent 10s at Clargill late in the occupation of Nicholas Whitfield Thomas Moore of Clargill, Alston Moor, yeoman to Thomas Stevenson and John Stevenson of Corby Gates, yeoman. Recites Feb 1578 Nicholas Whitfield of Alston Conveyance of messuage and BRA/1/2/4 Moor, yeoman bargained and sold 1 Jun 1616 tenement at Clargill to Raynold Whitfield son of John Whitfield of Randelholme, gent. -

Der Europäischen Gemeinschaften Nr
26 . 3 . 84 Amtsblatt der Europäischen Gemeinschaften Nr . L 82 / 67 RICHTLINIE DES RATES vom 28 . Februar 1984 betreffend das Gemeinschaftsverzeichnis der benachteiligten landwirtschaftlichen Gebiete im Sinne der Richtlinie 75 /268 / EWG ( Vereinigtes Königreich ) ( 84 / 169 / EWG ) DER RAT DER EUROPAISCHEN GEMEINSCHAFTEN — Folgende Indexzahlen über schwach ertragsfähige Böden gemäß Artikel 3 Absatz 4 Buchstabe a ) der Richtlinie 75 / 268 / EWG wurden bei der Bestimmung gestützt auf den Vertrag zur Gründung der Euro jeder der betreffenden Zonen zugrunde gelegt : über päischen Wirtschaftsgemeinschaft , 70 % liegender Anteil des Grünlandes an der landwirt schaftlichen Nutzfläche , Besatzdichte unter 1 Groß vieheinheit ( GVE ) je Hektar Futterfläche und nicht über gestützt auf die Richtlinie 75 / 268 / EWG des Rates vom 65 % des nationalen Durchschnitts liegende Pachten . 28 . April 1975 über die Landwirtschaft in Berggebieten und in bestimmten benachteiligten Gebieten ( J ), zuletzt geändert durch die Richtlinie 82 / 786 / EWG ( 2 ), insbe Die deutlich hinter dem Durchschnitt zurückbleibenden sondere auf Artikel 2 Absatz 2 , Wirtschaftsergebnisse der Betriebe im Sinne von Arti kel 3 Absatz 4 Buchstabe b ) der Richtlinie 75 / 268 / EWG wurden durch die Tatsache belegt , daß das auf Vorschlag der Kommission , Arbeitseinkommen 80 % des nationalen Durchschnitts nicht übersteigt . nach Stellungnahme des Europäischen Parlaments ( 3 ), Zur Feststellung der in Artikel 3 Absatz 4 Buchstabe c ) der Richtlinie 75 / 268 / EWG genannten geringen Bevöl in Erwägung nachstehender Gründe : kerungsdichte wurde die Tatsache zugrunde gelegt, daß die Bevölkerungsdichte unter Ausschluß der Bevölke In der Richtlinie 75 / 276 / EWG ( 4 ) werden die Gebiete rung von Städten und Industriegebieten nicht über 55 Einwohner je qkm liegt ; die entsprechenden Durch des Vereinigten Königreichs bezeichnet , die in dem schnittszahlen für das Vereinigte Königreich und die Gemeinschaftsverzeichnis der benachteiligten Gebiete Gemeinschaft liegen bei 229 beziehungsweise 163 . -

Index to Gallery Geograph
INDEX TO GALLERY GEOGRAPH IMAGES These images are taken from the Geograph website under the Creative Commons Licence. They have all been incorporated into the appropriate township entry in the Images of (this township) entry on the Right-hand side. [1343 images as at 1st March 2019] IMAGES FROM HISTORIC PUBLICATIONS From W G Collingwood, The Lake Counties 1932; paintings by A Reginald Smith, Titles 01 Windermere above Skelwith 03 The Langdales from Loughrigg 02 Grasmere Church Bridge Tarn 04 Snow-capped Wetherlam 05 Winter, near Skelwith Bridge 06 Showery Weather, Coniston 07 In the Duddon Valley 08 The Honister Pass 09 Buttermere 10 Crummock-water 11 Derwentwater 12 Borrowdale 13 Old Cottage, Stonethwaite 14 Thirlmere, 15 Ullswater, 16 Mardale (Evening), Engravings Thomas Pennant Alston Moor 1801 Appleby Castle Naworth castle Pendragon castle Margaret Countess of Kirkby Lonsdale bridge Lanercost Priory Cumberland Anne Clifford's Column Images from Hutchinson's History of Cumberland 1794 Vol 1 Title page Lanercost Priory Lanercost Priory Bewcastle Cross Walton House, Walton Naworth Castle Warwick Hall Wetheral Cells Wetheral Priory Wetheral Church Giant's Cave Brougham Giant's Cave Interior Brougham Hall Penrith Castle Blencow Hall, Greystoke Dacre Castle Millom Castle Vol 2 Carlisle Castle Whitehaven Whitehaven St Nicholas Whitehaven St James Whitehaven Castle Cockermouth Bridge Keswick Pocklington's Island Castlerigg Stone Circle Grange in Borrowdale Bowder Stone Bassenthwaite lake Roman Altars, Maryport Aqua-tints and engravings from -

The English Lake District
La Salle University La Salle University Digital Commons Art Museum Exhibition Catalogues La Salle University Art Museum 10-1980 The nE glish Lake District La Salle University Art Museum James A. Butler Paul F. Betz Follow this and additional works at: http://digitalcommons.lasalle.edu/exhibition_catalogues Part of the Fine Arts Commons, and the History of Art, Architecture, and Archaeology Commons Recommended Citation La Salle University Art Museum; Butler, James A.; and Betz, Paul F., "The nE glish Lake District" (1980). Art Museum Exhibition Catalogues. 90. http://digitalcommons.lasalle.edu/exhibition_catalogues/90 This Book is brought to you for free and open access by the La Salle University Art Museum at La Salle University Digital Commons. It has been accepted for inclusion in Art Museum Exhibition Catalogues by an authorized administrator of La Salle University Digital Commons. For more information, please contact [email protected]. T/ie CEnglisti ^ake district ROMANTIC ART AND LITERATURE OF THE ENGLISH LAKE DISTRICT La Salle College Art Gallery 21 October - 26 November 1380 Preface This exhibition presents the art and literature of the English Lake District, a place--once the counties of Westmorland and Cumber land, now merged into one county, Cumbria— on the west coast about two hundred fifty miles north of London. Special emphasis has been placed on providing a visual record of Derwentwater (where Coleridge lived) and of Grasmere (the home of Wordsworth). In addition, four display cases house exhibits on Wordsworth, on Lake District writers and painters, on early Lake District tourism, and on The Cornell Wordsworth Series. The exhibition has been planned and assembled by James A. -

Landscape Conservation Action Plan Part 1
Fellfoot Forward Landscape Conservation Action Plan Part 1 Fellfoot Forward Landscape Partnership Scheme Landscape Conservation Action Plan 1 Fellfoot Forward is led by the North Pennines AONB Partnership and supported by the National Lottery Heritage Fund. Our Fellfoot Forward Landscape Partnership includes these partners Contents Landscape Conservation Action Plan Part 1 1. Acknowledgements 3 8 Fellfoot Forward LPS: making it happen 88 2. Foreword 4 8.1 Fellfoot Forward: the first steps 89 3. Executive Summary: A Manifesto for Our Landscape 5 8.2 Community consultation 90 4 Using the LCAP 6 8.3 Fellfoot Forward LPS Advisory Board 93 5 Understanding the Fellfoot Forward Landscape 7 8.4 Fellfoot Forward: 2020 – 2024 94 5.1 Location 8 8.5 Key milestones and events 94 5.2 What do we mean by landscape? 9 8.6 Delivery partners 96 5.3 Statement of Significance: 8.7 Staff team 96 what makes our Fellfoot landscape special? 10 8.8 Fellfoot Forward LPS: Risk register 98 5.4 Landscape Character Assessment 12 8.9 Financial arrangements 105 5.5 Beneath it all: Geology 32 8.10 Scheme office 106 5.6 Our past: pre-history to present day 38 8.11 Future Fair 106 5.7 Communities 41 8.12 Communications framework 107 5.8 The visitor experience 45 8.13 Evaluation and monitoring 113 5.9 Wildlife and habitats of the Fellfoot landscape 50 8.14 Changes to Scheme programme and budget since first stage submission 114 5.10 Moorlands 51 9 Key strategy documents 118 5.11 Grassland 52 5.12 Rivers and Streams 53 APPENDICES 5.13 Trees, woodlands and hedgerows 54 1 Glossary -

A Guide Through the District of the Lakes in the North of England : With
Edward M. Rowe Collection of William Wordsworth DA 670 .LI W67 1835 L. Tom Perry Special Collections Harold B. Lee Library Brigham Young University BRIGHAM YOUNG UNIVERSITY 3 1197 23079 8925 Digitized by the Internet Archive in 2011 with funding from Brigham Young University http://www.archive.org/details/guidethroughdistOOword 1* "TV- I m #j GUIDE THROUGH THE * DISTRICT OF THE LAKES IN Ctie Nortf) of iSnglantr, WITH A DESCRIPTION OF THE SCENERY, &c. FOR THE USE OF TOURISTS AND RESIDENTS. FIFTH EDITION, WITH CONSIDERABLE ADDITIONS. By WILLIAM WORDSWORTH. KENDAL: PUBLISHED BY HUDSON AND NICHOLSON, AND IN LONDON BY LONGMAN & CO., r.'CXON, AND r." ! tTAE^lH & CO. Ytyll U-20QC& CjMtfo J YJoR , KENDAL: Printed by Hudson and Nicholson. ... • • • Tl^-i —— CONTENTS. DIRECTIONS AND INFORMATION FOR THE TOURIST. Windermere,—Ambleside.—Coniston.— Ulpha Kirk. Road from Ambleside to Keswick.—Grasmere,—The Vale of Keswick.—Buttermere and Crummock.— Loweswater. —Wastdale. —Ullswater, with its tribu- - i. tary Streams.—Haweswater, &c. Poge% DESCRIPTION of THE SCENERY of THE LAKES. SECTION FIRST. VIEW OF THE COUNTRY AS FORMED BY NATURE. Vales diverging from a common Centre.—Effect of Light and Shadow as dependant upon the Position of the Vales. — Mountains, — their Substance,—Surfaces, and Colours. — Winter Colouring. — The Vales, Lakes,— Islands, —Tarns, -— Woods,— Rivers,— Cli- mate,—Night. - - - p. 1 SECTION SECOND. I ASPECT OF THE COUNTRY AS AFFECTED BY ITS INHABITANTS. Retrospect. —Primitive Aspect.—Roman and British Antiquities, — Feudal Tenantry, — their Habitations and Enclosures.—Tenantry reduced in Number by the Union of the Two Crowns.— State of Society after that Event. —Cottages,—Bridges,—Places of Wor- ship, —Parks and Mansions.—General Picture of So- ciety. -

North Pennines Archaeology Ltd
NORTH PENNINES ARCHAEOLOGY LTD Project Report No. CP 1245/11 ARCHAEOLOGICAL EVALUATION OF A BRONZE AGE CREMATION CEMETERY ON BRACKENBER MOOR, APPLEBY-IN-WESTMORLAND, CUMBRIA NGR: NY 7083 1982 ALTOGETHER ARCHAEOLOGY FIELDWORK MODULE 5 FOR NORTH PENNINES AONB PARTNERSHIP Martin Railton, BA (Hons) MA MIfA September 2011 North Pennines Archaeology Ltd Nenthead Mines Heritage Centre, Nenthead, Alston CUMBRIA CA9 3PD Tel: (01434) 382045 Fax: (01434) 382294 Email: [email protected] North Pennines Archaeology Ltd is a wholly owned company of North Pennines Archaeology Ltd Company Registration No. 4847034 VAT Registration No. 817 2284 31 CONTENTS Page 1 INTRODUCTION AND LOCATION .................................................................................... 1 2 HISTORICAL AND ARCHAEOLOGICAL BACKROUND ................................................ 2 2.1 Brackenber Moor .................................................................................................................... 2 2.2 The Evaluation Site ................................................................................................................. 3 2.3 Previous Archaeological Work ............................................................................................... 4 3 AIMS AND METHODOLOGY ............................................................................................. 5 3.1 Project Aims and Objectives ................................................................................................... 5 3.2 Topographic Survey ............................................................................................................... -

North West Blackburn with Darwen
Archaeological Investigations Project 2008 Building Recording North West Blackburn with Darwen Blackburn with Darwen UA (G.48.4272/2008) SD67902780 Parish: Blackburn Postal Code: BB2 2EF 53 KING STREET, BLACKBURN 53 King Street, Blackburn, Lancashire: Archaeological Building Investigation Ridings, C Lancaster : Oxford Archaeology North, Report: L9980 2008, 64pp, colour pls, figs, tabs, refs Work undertaken by: Oxford Archaeology North A building investigation of a townhouse was undertaken prior to its potential demolition. Historical research in conjunction with an addendum to a desk-based assessment revealed that the house was built in the late-18th century and not c. 1830, as had originally been assumed. The empty plot was purchased by a carpenter John Edleston the Elder, who built the existing townhouse, which he and his son [also John Edleston] would occupy till the early 19th century. During the 19th century, the house was acquired by a local calico magnate called James Pearson, then a surgeon called James Pickup, before being sold and used as the superintendent’s residence for the new County Police Station, which was built on the site of the demolished 51 King Street. The townhouse was a solitary reminder of what was once a very desirable residential area of Blackburn. Unfortunately, the only other structure of comparable age and status that still remained was 61 King Street, whilst the rest of the buildings comprised modern 20th century shops of assorted descriptions and a builder’s merchants. The property appeared to be structurally sound from the exterior, but the interior was in a poor state of repair. The townhouse had been stripped of most of its internal features, but the decoration, which appeared to date to the early 19th century, was still retained. -

Cumbria Classified Roads
Cumbria Classified (A,B & C) Roads - Published January 2021 • The list has been prepared using the available information from records compiled by the County Council and is correct to the best of our knowledge. It does not, however, constitute a definitive statement as to the status of any particular highway. • This is not a comprehensive list of the entire highway network in Cumbria although the majority of streets are included for information purposes. • The extent of the highway maintainable at public expense is not available on the list and can only be determined through the search process. • The List of Streets is a live record and is constantly being amended and updated. We update and republish it every 3 months. • Like many rural authorities, where some highways have no name at all, we usually record our information using a road numbering reference system. Street descriptors will be added to the list during the updating process along with any other missing information. • The list does not contain Recorded Public Rights of Way as shown on Cumbria County Council’s 1976 Definitive Map, nor does it contain streets that are privately maintained. • The list is property of Cumbria County Council and is only available to the public for viewing purposes and must not be copied or distributed. A (Principal) Roads STREET NAME/DESCRIPTION LOCALITY DISTRICT ROAD NUMBER Bowness-on-Windermere to A590T via Winster BOWNESS-ON-WINDERMERE SOUTH LAKELAND A5074 A591 to A593 South of Ambleside AMBLESIDE SOUTH LAKELAND A5075 A593 at Torver to A5092 via -

Charlotte Smith's Ethelinde and the Literary Construction of Grasmere
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Insight - University of Cumbria Bradshaw, Penelope (2017) Romantic recluses and humble cottages: Charlotte Smith©s Ethelinde and the literary construction of Grasmere. Women©s Writing . Downloaded from: http://insight.cumbria.ac.uk/id/eprint/3185/ Usage of any items from the University of Cumbria's institutional repository `Insight' must conform to the following fair usage guidelines. Any item and its associated metadata held in the University of Cumbria's institutional repository Insight (unless stated otherwise on the metadata record) may be copied, displayed or performed, and stored in line with the JISC fair dealing guidelines (available here) for educational and not-for-profit activities provided that · the authors, title and full bibliographic details of the item are cited clearly when any part of the work is referred to verbally or in the written form · a hyperlink/URL to the original Insight record of that item is included in any citations of the work · the content is not changed in any way · all files required for usage of the item are kept together with the main item file. You may not · sell any part of an item · refer to any part of an item without citation · amend any item or contextualise it in a way that will impugn the creator's reputation · remove or alter the copyright statement on an item. The full policy can be found here. Alternatively contact the University of Cumbria Repository Editor by emailing [email protected]. Romantic Recluses and Humble Cottages: Charlotte Smith’s Ethelinde and the Literary Construction of Grasmere Dr Penny Bradshaw Institute of the Arts, University of Cumbria, Brampton Road, Carlisle, Cumbria, CA3 9AY, UK.