Sinhala Range: 0D80–0DFF
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ka И @И Ka M Л @Л Ga Н @Н Ga M М @М Nga О @О Ca П
ISO/IEC JTC1/SC2/WG2 N3319R L2/07-295R 2007-09-11 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal for encoding the Javanese script in the UCS Source: Michael Everson, SEI (Universal Scripts Project) Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Replaces: N3292 Date: 2007-09-11 1. Introduction. The Javanese script, or aksara Jawa, is used for writing the Javanese language, the native language of one of the peoples of Java, known locally as basa Jawa. It is a descendent of the ancient Brahmi script of India, and so has many similarities with modern scripts of South Asia and Southeast Asia which are also members of that family. The Javanese script is also used for writing Sanskrit, Jawa Kuna (a kind of Sanskritized Javanese), and Kawi, as well as the Sundanese language, also spoken on the island of Java, and the Sasak language, spoken on the island of Lombok. Javanese script was in current use in Java until about 1945; in 1928 Bahasa Indonesia was made the national language of Indonesia and its influence eclipsed that of other languages and their scripts. Traditional Javanese texts are written on palm leaves; books of these bound together are called lontar, a word which derives from ron ‘leaf’ and tal ‘palm’. 2.1. Consonant letters. Consonants have an inherent -a vowel sound. Consonants combine with following consonants in the usual Brahmic fashion: the inherent vowel is “killed” by the PANGKON, and the follow- ing consonant is subjoined or postfixed, often with a change in shape: §£ ndha = § NA + @¿ PANGKON + £ DA-MAHAPRANA; üù n. -

Design of Javanese Text to Speech Application
Design of Javanese Text to Speech Application Yulia, Liliana, Rudy Adipranata, Gregorius Satia Budhi Informatics Department, Industrial Technology Faculty, Petra Christian University Surabaya, Indonesia [email protected] Abstract—Javanese is one of the many regional languages used in Indonesia. Javanese language is used by most of the population in Java. But now along with the development of the era, the use of regional languages including Javanese language is to be re- duced especially among the younger generation. One way to help conserve the use of Javanese language is to utilize information technologies, one of them is by developing a text to speech appli- cation that can be used to find out how the pronunciation of Ja- vanese language. In this paper, we discussed the design for Java- nese text to speech applications uses finite state automata. The design result will be used as rules to separate syllables when im- plementing text to speech application. Index Terms—Javanese language; Finite state automata; Text to speech. Figure 1: Basic Javanese characters I. INTRODUCTION In addition to the basic characters, the Javanese character Javanese language is a language widely spoken by the peo- has supplementary characters, consist of symbols for express- ple of Java. It is one of the regional languages of many region- ing vowels as well as a combination of two specific conso- al languages spoken in Indonesia. As one of the assets of na- nants. This supplementary characters is called sandhangan tional culture, Javanese language needs to be preserved. The and can be seen in Figure 2 [5]. younger generation is now more interested in learning a for- Symbol Example Read eign language, rather than the native Indonesian local lan- guage. -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

COVID-19 (Dati Nga 2019 Novel Coronavirus, Wenno 2019-Ncov) Dagiti Kanayon a Masalsaludsod
COVID-19 (dati nga 2019 Novel Coronavirus, wenno 2019-nCoV) Dagiti Kanayon a Masalsaludsod Napabaro idi Pebrero 28, 2020 Dagiti Acronym ken abbreviation a nausar iti daytoy a dokumento: 2019-nCoV: 2019 Novel Coronavirus CDC: US Centers for Disease Control & Prevention COVID-19: Coronavirus Disease 2019 HDOH: State of Hawaii Department of Health MERS: Middle East Respiratory Syndrome SARS: Severe Acute Respiratory Syndrome SARS-CoV-2: Severe Acute Respiratory Syndrome Coronavirus 2 WHO: World Health Organization HNL: Daniel K. Inouye International Airport HENERAL A PAKAAMMO Ania ti COVID-19? COVID-19 (dati nga maaw-awagan ti “2019 Novel Coronavirus,” pinabassitda kas “2019-nCoV”) ket maysa a baro a sakit ti respiratory virus nga immuna a naduktalan idiay central Chinese city ti Wuhan, probinsya ti Hubei. Daytoy ket nagwaras idiay dadduma pay a syudad ti China ken kasdiay met iti nasurok a 27 nga pagilian, kadwa ditoyen ti Estados Unidos. Idi Enero 30, 2020, indeklara ti WHO ti Emergency of International Concern. Itatta awan met ti kumpirmado a kaso ti 2019-nCoV ditoy Hawaii. Ania ti usto a nagan daytoy rimsua ken nagwaras a sakit ken ti virus a nangparnuay iti daytoy? 2019-nCov ti nagan na, saan kadi? Dagiti eksperto ti virus iti sangalubongan ket opisyaldan a pinanaganan ti virus a nangparnuay ti ti outbreak ti “SARS-CoV-2.” Daytoy ket napabassit a “Severe Acute Respiratory Syndrome Coronavirus 2.” Kalpasan nga inadal dagiti siyentista ti baro nga coronavirus, naammoanda nga daytoy ket halos agpadada iti virus a nangpataud ti SARS epidemic idi 2002 ken 2003. Ti virus a nangpataud ti SARS ket naawagan kas SARS-CoV, isu nga daytoy baro a coronavirus ket maaw- awagan nga SARS-CoV-2. -

Balinese Romanization Table
Balinese Principal consonants1 (h)a2 ᬳ ᭄ᬳ na ᬦ ᭄ᬦ ca ᬘ ᭄ᬘ᭄ᬘ ra ᬭ ᭄ᬭ ka ᬓ ᭄ᬓ da ᬤ ᭄ᬤ ta ᬢ ᭄ᬢ sa ᬲ ᭄ᬲ wa ᬯ la ᬮ ᭄ᬙ pa ᬧ ᭄ᬧ ḍa ᬟ ᭄ᬠ dha ᬥ ᭄ᬟ ja ᬚ ᭄ᬚ ya ᬬ ᭄ᬬ ña ᬜ ᭄ᬜ ma ᬫ ᭄ᬫ ga ᬕ ᭄ᬕ ba ᬩ ᭄ᬩ ṭa ᬝ ᭄ᬝ nga ᬗ ᭄ᬗ Other consonant forms3 na (ṇa) ᬡ ᭄ᬡ ca (cha) ᭄ᬙ᭄ᬙ ta (tha) ᬣ ᭄ᬣ sa (śa) ᬱ ᭄ᬱ sa (ṣa) ᬰ ᭄ᬰ pa (pha) ᬨ ᭄ᬛ ga (gha) ᬖ ᭄ᬖ ba (bha) ᬪ ᭄ᬪ ‘a ᬗ᬴ ha ᬳ᬴ kha ᬓ᬴ fa ᬧ᬴ za ᬚ᬴ gha ᬕ᬴ Vowels and other agglutinating signs4 5 a ᬅ 6 ā ᬵ ᬆ e ᬾ ᬏ ai ᬿ ᬐ ĕ ᭂ ö ᭃ i ᬶ ᬇ ī ᬷ ᬈ o ᭀ ᬑ au ᭁ ᬒ u7 ᬸ ᬉ ū ᬹ ᬊ ya, ia8 ᭄ᬬ r9 ᬃ ra ᭄ᬭ rĕ ᬋ rö ᬌ ᬻ lĕ ᬍ ᬼ lö ᬎ ᬽ h ᬄ ng ᬂ ng ᬁ Numerals 1 2 3 4 5 ᭑ ᭒ ᭓ ᭔ ᭕ 6 7 8 9 0 ᭖ ᭗ ᭘ ᭙ ᭐ 1 Each consonant has two forms, the regular and the appended, shown on the left and right respectively in the romanization table. The vowel a is implicit after all consonants and consonant clusters and should be supplied in transliteration, unless: (a) another vowel is indicated by the appropriate sign; or (b) the absence of any vowel is indicated by the use of an adeg-adeg sign ( ). (Also known as the tengenen sign; ᭄ paten in Javanese.) 2 This character often serves as a neutral seat for a vowel, in which case the h is not transcribed. -

A Barrier to Indic-Language Implementation of Unicode Is the Perception That Encoding Order in Unicode Is Equivalent to Lingui
Issues in Indic Language Collation Issues in Indic Language Collation Cathy Wissink Program Manager, Windows Globalization Microsoft Corporation I. Introduction As the software market for India1 grows, so does the interest in developing products for this market, and Unicode is part of many vendors’ solutions. However, many software vendors see a barrier to implementing Unicode on products for the Indic-language market. This barrier is the perception that deficiencies in Unicode will keep software developers from creating products that are culturally and linguistically appropriate for the Indian market. This perception manifests itself in a number of ways, but one major concern that the Indic language community has voiced is the fact that the Unicode character encoding order is not appropriate for linguistic collation (or sorting). This belief that character encoding order in Unicode must be equivalent to linguistic collation of these same scripts and their respective languages is considered by some developers a blocking point to adoption of Unicode in the Indian market, and is indicative of the greater concern within the Indic-language community about the feasibility of Unicode for their scripts. This paper will demonstrate that this perceived barrier to Unicode adoption does not exist and that it is possible to provide properly globalized software for the Indic market with the current implementation of Unicode, using the example of Indic language collation. A brief history of Indic encodings will be given to set the stage for the current mentality regarding Unicode in the Indian market. The basics of linguistic collation and its application to Indic scripts will then be discussed, compared to encoding, and demonstrated as it exists on Windows XP. -
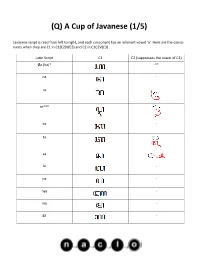
Q) a Cup of Javanese (1/5
(Q) A Cup of Javanese (1/5) Javanese script is read from left to right, and each consonant has an inherent vowel ‘a’. Here are the conso- nants when they are C1 in C1(C2)V(C3) and C2 in C1C2V(C3). Latin Script C1 C2 (suppresses the vowel of C1) Øa (ha)* -** na - ra re*** ka - ta sa la - pa - nya - ma - ga - (Q) A Cup of Javanese (2/5) Javanese script is read from left to right, and each consonant has an inherent vowel ‘a’. Here are the conso- nants when they are C1 in C1(C2)V(C3) and C2 in C1C2V(C3). Latin Script C1 C2 (suppresses the vowel of C1) ba nga - *The consonant is either ‘Ø’ (no consonant) or ‘h,’ but the problem contains only the former. **The ‘-’ means that the form exists, but not in this problem. ***The CV combination ‘re’ (historical remnant of /ɽ/) has its own special letters. ‘ng,’ ‘h,’ and ‘r’ must be C3 in (C1)(C2)VC3 before another C or at the end of a word. All other consonants after V must be C1 of the next syllable. If these consonants end a word, a ‘vowel suppressor’ must be added to suppress the inherent ‘a.’ Latin Script C3 -ng -h -r -C (vowel suppressor) Consonants can be modified to change the inherent vowel ‘a’ in C1(C2)V(C3). Latin Script V* e** (Q) A Cup of Javanese (3/5) Latin Script V* i é u o * If C2 is on the right side of C1, then ‘e,’ ‘i,’ and ‘u’ modify C2. -

Giya Nga Mga Prinsipyo Mahitungod Sa Internal Nga Pagbakwit
GIYA NGA MGA PRINSIPYO MAHITUNGOD SA INTERNAL NGA PAGBAKWIT Pasiunang Pulong Among gihubad sa Cebuano ang dokumentong _Guiding Principles on Internal Displacement,_ nga unang giila sa Tinipong Kanasuran niadtong 1998, tungod kay usa kini ka mahinungdanong lakang sa pagpanalipod ug pag-amping sa katungod sa internal nga mga bakwit sa tibuok kalibutan. Ang katungod nga mapanalipdan batok sa pinugos o tinuyo nga pagpabakwit, sa pagdawat sa makitawhanong hinabang, nga mapanalipdan sa panahon sa pagbakwit ug luwas nga makabalik sa pinuy-anan o makabalhin maoy mga mahinungdanong tawhanong katungod nga angay tahuron aron mapatigbabaw ug mapalambo ang dignidad sa mga bakwit. Sa Pilipinas, ang pagpabakwit ug mga pag-antus nga bunga niini, ingon man ang mga paglapas, kawalay pagpakabana o paghikaw sa mga batakang tawhanong katungod-- sibil, pulitikanhon, ekonomikanhon, sosyal o kultural_sa mga biktima maoy mga rason ngano nga kinahanglang hatagan kini sa dihadihang pagtagad. Kining maong paghubad usa ka hiniusang paningkamot sa Ecumenical Commission for Displaced Families and Communities (ECDFC), sa United Nations Information Center (UNIC) ug sa United Nations High Commissioner for Refugees (UNHCR) sa tumong nga maabot ang tanan nga, sa bisan unsang paagi, nalambigit sa mga insidente sa internal nga pagpabakwit (sama sa mga pangulo sa kagamhanan, magbabalaod, mga grupo nga misalmot sa mga armadong panagsangka ug pagsulod sa kayutaan, ug non- government organizations). Hinaut nga kitang tanan makat-on o makapahimulos niining maong dokumento. Isip tubag sa awhag sa UN Commission on Human Rights sa pagpalambo sa usa ka haom nga gambalay sa pagpanalipod ug pagtabang sa mga bakwit sulod sa usa ka nasod, ang Representante sa Kalihim-Heneral sa mga Internal nga mga Bakwit nagmugna niining Giya nga mga Prinsipyo Mahitungod sa Internal nga Pagpabakwit tinambayayongan sa mga batid sa balaod sa kalibutan ug sa pagtambag sa mga ahensya sa Tinipong Kanasuran ug uban pang organisasyon, internasyonal ug rehiyonal, panggobyerno o di-panggobyerno. -

Internationalized Domain Names-Sanskrit
Policy Document For INTERNATIONALIZED DOMAIN NAMES Language: SANSKRIT 1. AUGMENTED BACKUS-NAUR FORMALISM (ABNF) .......................................... 3 1.1 Declaration of variables ............................................................................................ 3 1.2 ABNF Operators ....................................................................................................... 3 1.3 The Vowel Sequence ................................................................................................. 3 1.4 Consonant Sequence ................................................................................................. 4 1.5 ABNF Applied to the SANSKRIT IDN .................................................................... 5 2. RESTRICTION RULES ................................................................................................. 6 3. EXAMPLES ................................................................................................................... 8 4. LANGUAGE TABLE: SANSKRIT ............................................................................... 9 5. NOMENCLATURAL DESCRIPTION TABLE OF SANSKRIT LANGUAGE TABLE ............................................................................................................................................11 6. VARIANT TABLE ........................................................................................................ 14 7. EXPERTISE/BODIES CONSULTED .......................................................................... 15 8. -

The Unicode Standard, Version 3.0, Issued by the Unicode Consor- Tium and Published by Addison-Wesley
The Unicode Standard Version 3.0 The Unicode Consortium ADDISON–WESLEY An Imprint of Addison Wesley Longman, Inc. Reading, Massachusetts · Harlow, England · Menlo Park, California Berkeley, California · Don Mills, Ontario · Sydney Bonn · Amsterdam · Tokyo · Mexico City Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and Addison-Wesley was aware of a trademark claim, the designations have been printed in initial capital letters. However, not all words in initial capital letters are trademark designations. The authors and publisher have taken care in preparation of this book, but make no expressed or implied warranty of any kind and assume no responsibility for errors or omissions. No liability is assumed for incidental or consequential damages in connection with or arising out of the use of the information or programs contained herein. The Unicode Character Database and other files are provided as-is by Unicode®, Inc. No claims are made as to fitness for any particular purpose. No warranties of any kind are expressed or implied. The recipient agrees to determine applicability of information provided. If these files have been purchased on computer-readable media, the sole remedy for any claim will be exchange of defective media within ninety days of receipt. Dai Kan-Wa Jiten used as the source of reference Kanji codes was written by Tetsuji Morohashi and published by Taishukan Shoten. ISBN 0-201-61633-5 Copyright © 1991-2000 by Unicode, Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or other- wise, without the prior written permission of the publisher or Unicode, Inc. -

Tanan Ini Ginhimo Ko Para Sa Imo Nagkari Ako
TANAN INI GINHIMO KO PARA SA IMO NAGKARI AKO... bangud sa “imo” sala. “Kay nasulat na, wala sing matarung..., wala bisan isa.” (Taga Roma 3:10) “Sanglit ang tanan nagpakasala kag nawad-an sang himaya sang Dios;” (Taga Roma 3:23) “Matu-od ang pinamolong kag takus sang bug-os nga pagbaton, nga si Kristo Jesus nag-abot sa kalibutan sa pagluwas sang mga makasasala;” (1 Timoteo 1:15a) NAPATAY AKO... sa pagbayad sang “imo” sala. “Apang sia ginpilas tungud sang aton mga paglalis, ginhanog sia tungud sa aton mga kalautan: ang silot sang aton paghidait yara sa iya, kag sa iya mga labud ginaayo kita.” (Isaias 53:5) “Apang ang Dios nagpakilala sang iya kaugalingon nga gugma sa aton nga sang makasasala pa kita si Kristo napatay tungod sa aton. Busa sanglit karon ginpakama- tarung kita paagi sa iya dugo, labi pa nga maluwas kita sa kasingkal sang Dios paagi sa iya. (Mga Taga Roma 5:8-9) ”Nga sa iya gintubos kita paagi sa kapatawaran sang aton mga sala:” (Colosas 1:14) GINBANHAW AKO... sa pagluwas sa “imo” sa walay katubtuban. “Gani sarang sia sa tanan nga tion sa pagluwas sa ila nga nagapalapit sa Dios paagi sa iya, sanglit nagakabuhi sila gihapon sa pagpatunga nga nagatabang sa ila.” (Hebreo 7:25) “Ang mga karnero nagapamati sang akon tingug kag nakilala ko sia kag nagasunod sila sa akon, kag nagahatag ako sa ila sing kabuhi nga walay katapusan, kag indi na gid sila mawala, kag walay isa nga makaa- gaw sa ila sa akon kamut.” (Juan 10:27-28) “Kag ang panaksi amo ini, nga ang Dios naghatag sa aton sing kabuhi nga walay katapusan, kag ining kabuhi yara sa iya anak.” (1 Juan 5:11) DAPAT IKAW MAGHINULSOL.. -

Augmented Javanese Speech Levels Machine Translation 45
Augmented Javanese Speech Levels Machine Translation 45 Augmented Javanese Speech Levels Machine Translation Aji P. Wibawa1, Andrew Nafalski2, and Wayan F. Mahmudy3, Non-members ABSTRACT language [1, 7, 8]. Furthermore, the selection of incor- rect vocabularies [4] indicates that they lack mastery This paper presents the development of the hy- of speech levels and do not know how to use them brid corpus-based machine translation for Javanese appropriately in verbal communication. In fact, the language. The system is designed to deal with the acquisition of speech levels among teenagers can be complexity of politeness expression and speech levels classified as very poor: 36.45 out of 100. This finding of Javanese that is considered as a local language with was revealed in a research on the use of speech levels the biggest number of users in Indonesia. Statistical by youngsters in Solo [8] and the result was based on features are embedded to increase the performance written vocabulary translation tests. of the system. The edit shifting distance is applied Realizing that they cannot handle this polite form, due to increase the alignment efficiency. However, im- younger speakers usually switch into Indonesian lan- proper alignment contributed by recorded impossible guage(bahasa Indonesia), which they can handle more pair and insufficient data training is still detected. easily and they believe to be more reliable to use in This paper proposes a new improvement of the de- the global era [7-9]. If this continues, the krama form- veloped alignment algorithm based on the impossible a unique characteristic Javanese-is in the danger of pair restriction.