Labelling Companies Referred to in Newspaper Articles
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

International Naming Conventions NAFSA TX State Mtg
1 2 3 4 1. Transcription is a more phonetic interpretation, while transliteration represents the letters exactly 2. Why transcription instead of transliteration? • Some English vowel sounds don’t exist in the other language and vice‐versa • Some English consonant sounds don’t exist in the other language and vice‐versa • Some languages are not written with letters 3. What issues are related to transcription and transliteration? • Lack of consistent rules from some languages or varying sets of rules • Country variation in choice of rules • Country/regional variations in pronunciation • Same name may be transcribed differently even within the same family • More confusing when common or religious names cross over several countries with different scripts (i.e., Mohammad et al) 5 Dark green countries represent those countries where Arabic is the official language. Lighter green represents those countries in which Arabic is either one of several official languages or is a language of everyday usage. Middle East and Central Asia: • Kurdish and Turkmen in Iraq • Farsi (Persian) and Baluchi in Iran • Dari, Pashto and Uzbek in Afghanistan • Uyghur, Kazakh and Kyrgyz in northwest China South Asia: • Urdu, Punjabi, Sindhi, Kashmiri, and Baluchi in Pakistan • Urdu and Kashmiri in India Southeast Asia: • Malay in Burma • Used for religious purposes in Malaysia, Indonesia, southern Thailand, Singapore, and the Philippines Africa: • Bedawi or Beja in Sudan • Hausa in Nigeria • Tamazight and other Berber languages 6 The name Mohamed is an excellent example. The name is literally written as M‐H‐M‐D. However, vowels and pronunciation depend on the region. D and T are interchangeable depending on the region, and the middle “M” is sometimes repeated when transcribed. -

Family Law Form 12.982(A), Petition for Change of Name (Adult) (02/18) Copies, and the Clerk Can Tell You the Amount of the Charges
INSTRUCTIONS FOR FLORIDA SUPREME COURT APPROVED FAMILY LAW FORM 12.982(a) PETITION FOR CHANGE OF NAME (ADULT) (02/18) When should this form be used? This form should be used when an adult wants the court to change his or her name. This form is not to be used in connection with a dissolution of marriage or for adoption of child(ren). If you want a change of name because of a dissolution of marriage or adoption of child(ren) that is not yet final, the change of name should be requested as part of that case. This form should be typed or printed in black ink and must be signed before a notary public or deputy clerk. You should file the original with the clerk of the circuit court in the county where you live and keep a copy for your records. What should I do next? Unless you are seeking to restore a former name, you must have fingerprints submitted for a state and national criminal records check. The fingerprints must be taken in a manner approved by the Department of Law Enforcement and must be submitted to the Department for a state and national criminal records check. You may not request a hearing on the petition until the clerk of court has received the results of your criminal history records check. The clerk of court can instruct you on the process for having the fingerprints taken and submitted, including information on law enforcement agencies or service providers authorized to submit fingerprints electronically to the Department of Law Enforcement. -

Reference Guides for Registering Students with Non English Names
Getting It Right Reference Guides for Registering Students With Non-English Names Jason Greenberg Motamedi, Ph.D. Zafreen Jaffery, Ed.D. Allyson Hagen Education Northwest June 2016 U.S. Department of Education John B. King Jr., Secretary Institute of Education Sciences Ruth Neild, Deputy Director for Policy and Research Delegated Duties of the Director National Center for Education Evaluation and Regional Assistance Joy Lesnick, Acting Commissioner Amy Johnson, Action Editor OK-Choon Park, Project Officer REL 2016-158 The National Center for Education Evaluation and Regional Assistance (NCEE) conducts unbiased large-scale evaluations of education programs and practices supported by federal funds; provides research-based technical assistance to educators and policymakers; and supports the synthesis and the widespread dissemination of the results of research and evaluation throughout the United States. JUNE 2016 This project has been funded at least in part with federal funds from the U.S. Department of Education under contract number ED‐IES‐12‐C‐0003. The content of this publication does not necessarily reflect the views or policies of the U.S. Department of Education nor does mention of trade names, commercial products, or organizations imply endorsement by the U.S. Government. REL Northwest, operated by Education Northwest, partners with practitioners and policymakers to strengthen data and research use. As one of 10 federally funded regional educational laboratories, we conduct research studies, provide training and technical assistance, and disseminate information. Our work focuses on regional challenges such as turning around low-performing schools, improving college and career readiness, and promoting equitable and excellent outcomes for all students. -

Brookings Africa Research Fellows Application
Foreign Policy Pre-Doctoral Research Fellowship Program Application How to Apply: Interested candidates should submit the following: • Application questionnaire and research project proposal; • One publication or writing sample of 10 pages or less (excerpts of larger works acceptable) in PDF format; • Official or unofficial transcript from graduate institution (course names, professor names, grades received) in PDF format; and • One email message containing all required application attachments is highly preferred, with “PreDoc Application – [Last Name, First Name]” in the subject line. • In addition, three confidential letters of recommendation must be submitted to Brookings directly by referees. Instructions are included at the bottom of this document. Application Deadlines: • Applicants must submit a complete application package to [email protected] no later than January 31, 2016 in order to be considered as a candidate. • Letters of reference must be submitted to [email protected] no later than February 15, 2016. Please Note: • Materials sent through regular postal service will not be accepted. • Incomplete applications and those received after the deadline will not be considered. - continued - 1 Personal Information Full Legal Name (as it appears on your passport):____________________________________________________ Preferred name (or nickname):______________________________________________________ Current position/title: _________________________________________________________________________ __________________________________________________________________________________________ -

U.S. Citizen – Adult Name Change on Social Security Card to Change Your Name on Your Card, You Must Show Us Documents Proving Your Legal Name Change and Identity
U.S. Citizen – Adult Name Change on Social Security Card To change your name on your card, you must show us documents proving your legal name change and identity. You also must show us a document proving your U.S. citizenship, if it is not already in our records. You must present original documents or copies certified by the agency that issued them. We cannot accept photocopies or notarized copies. To prove You must show One of the following documents: • Marriage document; • Divorce decree; Your legal name change • Certificate of naturalization showing a new name; or • Court order for a name change. We may ask to see identity documents showing your old name and documents showing your new name. Identity documents in your old name may be expired. A document showing your name, identifying information, and photograph, such as one of the following: • U.S. driver’s license; • State-issued non-driver’s identification card; or • U.S. passport. Your identity We may be able to accept your: • Employer identification card; • School identification card; • Health insurance card; or • U.S. military identification card. One of the following documents: • U.S. birth certificate; • U.S. Consular Report of Birth Abroad; Your U.S. citizenship • U.S. passport; • Certificate of Naturalization; or • Certificate of Citizenship. 1-800-772-1213 1-800-325-0778 (TTY) www.socialsecurity.gov SocialSecurity.gov Social Security Administration Publication No. 05-10513 | ICN 470117 | Unit of Issue — HD (one hundred) June 2017 (Recycle prior editions) U.S. Citizen – Adult Name Change on Social Security Card Produced and published at U.S. -
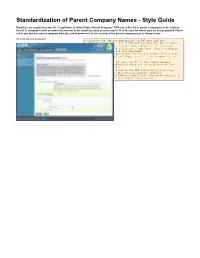
Standardization of Parent Company Names - Style Guide
Standardization of Parent Company Names - Style Guide Reporters are required to enter the "Legal Name of United States Parent Company." EPA has defined U.S. parent company(s) as the highest- level U.S. company(s) with an ownership interest in the reporting entity as of December 31 of the year for which data are being reported. Please select you facility's parent company from the pick-list provided. A screen snap of the parent company page is shown below: >> Click this link to expand To improve the quality and utility of GHG data EPA has established guidelines for standardizing corporate parent names. As a first step EPA has established a pick list of existing corporate parents. The following 4 steps were taken standardize the names of on the pick list including: 1) Names were standardized and research was conducted to verify the name submitted was the highest-level of the company in the U. S. 2) For GHG reporters who also report to the Toxics Release Inventory (TRI), standardized names were sourced from the TRI parent company database. 3) For the sectors covered by the GHG reporting program only, parent companies were derived from internet research. 4) The List of Parent Companies with local government agencies (e. g., city, town, county government) was removed. A list of the parent company names provided on this pick list is available here. If your facility's parent company is not already on the parent company pick-list you will need to enter the parent company's name in e-GGRT. The following provides a "style guide" for parent company naming: Remember to: Eliminate all periods Enter & instead of AND Use "North America" instead of NA When reporting the Parent Company, use the terms displayed in the "Acronym" column of the table below: Acronym Definition CORP Corporation ASSOC Association CO Company DIV Division INC Incorp/Incorp./Incorporated LP Limited Partnership LTD Limited LLC Limited Liability Company PTNR Partnership USA United States of America US United States. -

Washington State Birth Filing Form
Washington State Birth Parent Information Form Fields with asterisk (*) are required and appear on the Birth Certificate. For Hospital Use Only Mother’s Medical Record #: Prefer Parent / Parent Labels on Birth Certificate Yes No Child’s Medical Record #: (Default Labels are Mother / Father) Plurality: 1- single birth 2- twin 3- triplet Other: If multiple, this worksheet is for child: 1- first born 2- second born 3- third born Other: Child’s Information *1. Child’s Name First Middle Last Suffix *2. Child’s Date of Birth (MM/DD/YYYY) *3. Time of Birth *4. Child’s Sex Male Female 5. Type of Birthplace 6. Planned Birth Place, if different (specify): Hospital Freestanding Birth Center Clinic/Doctor’s Office (specify) Enroute Home Other : Child’s Information Child’s *7. Name of Facility (If not a facility, enter name of place and address) *8. County of Birth *9. City of Birth Mother’s Information 10. Mother’s Current Legal Name First Middle Last Suffix *11. Mother’s Name Prior to First Marriage First Middle Last/Maiden *12. Date of Birth (MM/DD/YYYY) *13. Birthplace (State, Territory, or Foreign Country) 14. Social Security Number 15a. Do you want to get a Social Security Number for your child? Yes No 15b. Do you need a Verification Letter of Birth for your child? Yes No 16a. Residence: Number and Street (e.g., 624 SE 5th St.) Apt No. 16b. If not U.S.; Country 16c. State 16d. County 16e. If you live on Tribal Reservation, give name 16f. City or Town 16g. Zip Code + 4 16h. -

Child Protection and Other Legislation Amendment Bill 2020
Child Protection and Other Legislation Amendment Bill 2020 Report No. 71, 56th Parliament Legal Affairs and Community Safety Committee August 2020 Legal Affairs and Community Safety Committee Chair Mr Peter Russo MP, Member for Toohey Deputy Chair Mr James Lister MP, Member for Southern Downs1 Members Mr Stephen Andrew MP, Member for Mirani Mrs Laura Gerber MP, Member for Currumbin Mrs Melissa McMahon MP, Member for Macalister2 Ms Corrine McMillan MP, Member for Mansfield Committee Secretariat Telephone +61 7 3553 6641 Fax +61 7 3553 6699 Email [email protected] Technical Scrutiny +61 7 3553 6601 Secretariat Committee Web Page www.parliament.qld.gov.au/lacsc Acknowledgements The committee acknowledges the assistance provided by the Department of Child Safety, Youth and Women and the Queensland Parliamentary Library. 1 Mr Rob Molhoek MP, Member for Southport, was a substitute for the Deputy Chair, Mr James Lister MP, Member for Southern Downs, on 10 August 2020 2 Mr Chris Whiting MP, Member for Bancroft was a substitute for Mrs Melissa McMahon MP, Member for Macalister, on 27 July 2020. Child Protection and Other Legislation Amendment Bill 2020 Contents Abbreviations iii Chair’s foreword v Recommendation vi 1 Introduction 1 1.1 Role of the committee 1 1.2 Inquiry process 1 1.3 Policy objectives of the Bill 1 1.4 Government consultation on the Bill 2 1.5 Should the Bill be passed? 3 2 Background to the Bill 4 2.1 Adoption as a means of providing permanency 4 2.1.1 Legislation in other jurisdictions 4 2.1.2 Research on adoption -

ASES Foundation 2021 Fellowship Program Grant Application
ASES Foundation 2021 Fellowship Program Grant Application Grant Requestor Information Date of the request: Legal Name of Organization/Institution (Requestor): Street: City: State Zip: Primary Contact Information Name: Phone: Fax: E-mail: Nonprofit Status Description of organization (e.g., hospital, charitable organization, educational organization, professional association): Mission: Is the Requestor a recognized 501(c)3 OR 501 (c)6? Yes No If the answer is no, explain your entity’s status: Federal Tax ID#*: *Please include the current W-9 for requestor and a copy of tax exemption letter Payee Information (if different from grant requestor above) Legal Name: Street: City: State Zip: Primary Contact Information Name: Phone: Fax: E-mail: ASES-Recognized Fellowship Program Information Fellowship Program Name: Accreditation status: (check all that apply) ACGME accredited ASES-recognized Program Year fellowship began: Years of participation in the ASES Fellowship Match: Fellowship Director’s Title: Fellowship Director’s Name (Last, First): ASES Member: Yes No Member category: Dedicated Fellowship Program Faculty Members (list first/last name and credentials below): Faculty 1 ASES Member Category Faculty 2 ASES Member Category Faculty 3 ASES Member Category Faculty 4 ASES Member Category Faculty 5 ASES Member Category Total Number of Fellows to Participate in the 2020-2021 Fellowship: Total Number of Fellows that Participated in the 2019-2020 Fellowship: Are all program fellows US/Canada graduates with license to practice in US/Canada? Yes -

Who Can Use These Forms?
WHO CAN USE THESE FORMS? 1. Any adult who wants to change their name for a lawful purpose can use these forms. (Examples of good reasons are given in the instructions) They are not suitable to change a child’s name. 2. Changing your name to hide from your creditors, or because you have criminal convictions, or because you are trying to defraud someone are unlawful reasons to change your name and is a misdemeanor. 3. You can change your name to protect yourself from someone who has severely abused you. However, it is strongly suggested that you see a lawyer to do a “Sealed Name Change.” If you change your name, but the records are not sealed, the court action changing your name is public and could be seen by your abuser. To get a “Sealed Name Change” you will have to persuade a judge that it is appropriate in your case to do so. Sealing the court records from the public view must be done correctly to work. This would be best done by a Lawyer who knows the appropriate forms to use and can explain the facts to the judge that would justify Sealing the Name Change in the Court files. Legal Aid Services of Oklahoma has attorneys that can do this. Many Domestic Violence Shelters may also be able to help you find an attorney to be able to do a Sealed Name Change. 4. DO NOT TRY TO USE THESE FORMS TO CHANGE A CHILD’S NAME. THESE FORMS ARE NOT DESIGNED TO CHANGE A CHILD’S NAME AND DO NOT MEET THE LEGAL REQUIREMENTS TO CHANGE A CHILD’S NAME. -

Legal Name Change/Name Correction Request
Enrollment Management Registrar's Office One University Drive Camarillo, CA 93012 Phone: (805) 437‐8500 www.csuci.edu Legal Name Change/Name Correction Request Submit this form with appropriate legal documentation (specified below) to the Registrar's Office via your myCI Portal to change your legal (primary) name in CSUCI’s student records. Current and former CSUCI employees (including student employees) can only change their legal name by going to the Human Resources office in Lindero Hall‐1804. This form, along with copies of legal documentation, must be submitted via your myCI portal by clicking on the "Demographic Corrections" service icon. Be sure to upload both the form and your legal documentation. You will be contacted if the document is . not legible For detailed instructions on how to submit this form and documents via the myCI portal please visit https:// www.csuci.edu/registrar/namechange.htm For Financial Aid recipients: Your current legal name on record at CSUCI should match your FAFSA application. Student ID: Phone: Date: Email: Current Legal Name on record at CSU Channel Islands: First Middle: Last: New/Corrected Legal Name: First Middle: Last: Enrollment Status: Do you want the new/corrected name to appear on your diploma? Applicant Current student Previously enrolled Yes No Name Change Documentation Name Correction Documentation: Acceptable Legal Documentation— • Birth Certificate Document must state old and new name. • Driver’s License • Passport Marriage License • California Identification Card Certificate of Naturalization with Petition for Name Change • Social Security Card Adoption Record with new Birth Certificate Divorce Decree (Stating restored name) Court Order Alien Registration Card I understand all University academic records and correspondence will reflect the name above. -

Request to Change Legal Name And/Or Gender (Sex)
REQUEST TO CHANGE LEGAL NAME AND/OR GENDER (SEX) To change your legal name and/or gender (sex) on your University record, fill out the relevant sections of Return this form to: this form, attach the required document(s) stated in Part B and/or Part C below, and submit to the Office of Office of the Registrar the Registrar. To add or update a preferred name, gender identity, or personal pronoun, go to MyU: My Info (z.umn.edu/myinfo). By U.S. Postal Service mail Office of the Registrar If you have applied for undergraduate admission, but have not yet registered for classes, return this form to the 200 Fraser Hall Office of Admissions, 240 Williamson Hall, 231 Pillsbury Dr. S.E., Mpls, MN 55455. 106 Pleasant St. S.E. Minneapolis, MN 55455-0433 If you are an international student, contact International Student and Scholar Services at 612-626-7100 or In person on campus [email protected] to discuss name and/or gender changes in regard to immigration documents (I-20/DS-2019). 200 Fraser Hall, East Bank For general questions about this form, please call 612-626-4432 or email [email protected]. By fax 612-625-4351 To ensure privacy online, open in Adobe Reader (free at Adobe.com). PART A. Required - Student information Full name (current) Suffix Student ID University email (or personal email, if none) Social Security Number Birthdate (mm/dd/yyyy) Current mailing address (street, apartment number or P.O. box number, city, state, ZIP code, country) College/program (applied to, current, or last attended) Term and year last attended Fall Spring May session Summer Year ________ PART B.