Neural Methods for Effective, Efficient, and Exposure-Aware Information
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Paul Sykes Lecture – Sat, Jan 27 @ 7:30Pm Ice on Mercury, Featuring Dr
NOVANEWSLETTEROFTHEVANCOUVERCENTRERASC VOLUME2018ISSUE1JANUARYFEBRUARY2018 Paul Sykes Lecture – Sat, Jan 27 @ 7:30pm Ice on Mercury, Featuring Dr. Nancy Chabot of Johns Hopkins University SFU Burnaby Campus, Room SWH 10081 Even though Mercury is the Dr. Nancy L. Chabot is a and Case Western Reserve Uni- planet closest to the Sun, there planetary scientist at the Johns versity. She has been a mem- are places at its poles that never Hopkins Applied Physics Labo- ber of five field teams with the receive sunlight and are very ratory (apl). She received an Antarctic Search for Meteorites cold—cold enough to hold wa- (ansmet) program and served ter ice! In this presentation, Dr. as the Instrument Scientist for Chabot will show the multiple the Mercury Dual Imaging Sys- lines of evidence that regions tem (mdis) on the messenger near Mercury’s poles hold water mission. Her research interests ice—from the first discovery involve understanding the evo- by Earth-based radar observa- lution of rocky planetary bod- tions to multiple data sets from ies in the Solar System, and at nasa’s messenger spacecraft, apl she oversees an experimen- the first spacecraft ever to or- tal geochemistry laboratory bit the planet Mercury. These that is used to conduct experi- combined results suggest that ments related to this topic. Dr. Mercury’s polar ice deposits Chabot has served as an Associ- are substantial, perhaps compa- ate Editor for the journal Mete- rable to the amount of water in oritics and Planetary Science, Lake Ontario! Where did the chair of nasa’s Small Bodies ice come from and how did it undergraduate degree in physics Assessment Group, a member get there? Dr. -

Naming the Extrasolar Planets
Naming the extrasolar planets W. Lyra Max Planck Institute for Astronomy, K¨onigstuhl 17, 69177, Heidelberg, Germany [email protected] Abstract and OGLE-TR-182 b, which does not help educators convey the message that these planets are quite similar to Jupiter. Extrasolar planets are not named and are referred to only In stark contrast, the sentence“planet Apollo is a gas giant by their assigned scientific designation. The reason given like Jupiter” is heavily - yet invisibly - coated with Coper- by the IAU to not name the planets is that it is consid- nicanism. ered impractical as planets are expected to be common. I One reason given by the IAU for not considering naming advance some reasons as to why this logic is flawed, and sug- the extrasolar planets is that it is a task deemed impractical. gest names for the 403 extrasolar planet candidates known One source is quoted as having said “if planets are found to as of Oct 2009. The names follow a scheme of association occur very frequently in the Universe, a system of individual with the constellation that the host star pertains to, and names for planets might well rapidly be found equally im- therefore are mostly drawn from Roman-Greek mythology. practicable as it is for stars, as planet discoveries progress.” Other mythologies may also be used given that a suitable 1. This leads to a second argument. It is indeed impractical association is established. to name all stars. But some stars are named nonetheless. In fact, all other classes of astronomical bodies are named. -

Institute of Theoretical Physics and Astronomy, Vilnius University
INSTITUTE OF THEORETICAL PHYSICS AND ASTRONOMY, VILNIUS UNIVERSITY Justas Zdanaviˇcius INTERSTELLAR EXTINCTION IN THE DIRECTION OF THE CAMELOPARDALIS DARK CLOUDS Doctoral dissertation Physical sciences, physics (02 P), astronomy, space research, cosmic chemistry (P 520) Vilnius, 2006 Disertacija rengta 1995 - 2005 metais Vilniaus universiteto Teorin˙es fizikos ir astronomijos institute Disertacija ginama eksternu Mokslinis konsultantas prof.habil.dr. V. Straiˇzys (Vilniaus universiteto Teorin˙es fizikos ir astronomijos institutas, fiziniai mokslai, fizika – 02 P) VILNIAUS UNIVERSITETO TEORINES˙ FIZIKOS IR ASTRONOMIJOS INSTITUTAS Justas Zdanaviˇcius TARPZVAIGˇ ZDINˇ EEKSTINKCIJA˙ ZIRAFOSˇ TAMSIU¸JU¸ DEBESU¸KRYPTIMI Daktaro disertacija Fiziniai mokslai, fizika (02 P), astronomija, erdv˙es tyrimai, kosmin˙e chemija (P 520) Vilnius, 2006 CONTENTS PUBLICATIONONTHESUBJECTOFTHEDISSERTATION .....................5 1. INTRODUCTION ................................................................6 2. REVIEWOFTHELITERATURE ................................................8 2.1. InvestigationsoftheinterstellarextinctioninCamelopardalis ..................8 2.2. Distinctiveobjectsinthearea ................................................10 2.3. Extinctionlawintheinvestigatedarea .......................................11 2.4. Galacticmodelsandluminosityfunctions .....................................11 2.5. SpiralstructureoftheGalaxyintheinvestigateddirection ...................12 3. METHODS ......................................................................14 -

Astronomy Magazine Special Issue
γ ι ζ γ δ α κ β κ ε γ β ρ ε ζ υ α φ ψ ω χ α π χ φ γ ω ο ι δ κ α ξ υ λ τ μ β α σ θ ε β σ δ γ ψ λ ω σ η ν θ Aι must-have for all stargazers η δ μ NEW EDITION! ζ λ β ε η κ NGC 6664 NGC 6539 ε τ μ NGC 6712 α υ δ ζ M26 ν NGC 6649 ψ Struve 2325 ζ ξ ATLAS χ α NGC 6604 ξ ο ν ν SCUTUM M16 of the γ SERP β NGC 6605 γ V450 ξ η υ η NGC 6645 M17 φ θ M18 ζ ρ ρ1 π Barnard 92 ο χ σ M25 M24 STARS M23 ν β κ All-in-one introduction ALL NEW MAPS WITH: to the night sky 42,000 more stars (87,000 plotted down to magnitude 8.5) AND 150+ more deep-sky objects (more than 1,200 total) The Eagle Nebula (M16) combines a dark nebula and a star cluster. In 100+ this intense region of star formation, “pillars” form at the boundaries spectacular between hot and cold gas. You’ll find this object on Map 14, a celestial portion of which lies above. photos PLUS: How to observe star clusters, nebulae, and galaxies AS2-CV0610.indd 1 6/10/10 4:17 PM NEW EDITION! AtlAs Tour the night sky of the The staff of Astronomy magazine decided to This atlas presents produce its first star atlas in 2006. -

IC-342 IC-342 Is an Intermediate Spiral Galaxy in the Constellation Camelopardalis
MONTHLY OBSERVER’S CHALLENGE Las Vegas Astronomical Society Compiled by: Roger Ivester, Boiling Springs, North Carolina & Fred Rayworth, Las Vegas, Nevada With special assistance from: Rob Lambert, Las Vegas, Nevada November 2010 IC 342 (Caldwell 5) - Hidden Galaxy in Camelopardalis Introduction The purpose of the observer’s challenge is to encourage the pursuit of visual observing. It is open to everyone that is interested, and if you are able to contribute notes, drawings, or photographs, we will be happy to include them in our monthly summary. Observing is not only a pleasure, but an art. With the main focus of amateur astronomy on astrophotography, many times people tend to forget how it was in the days before cameras, clock drives, and GOTO. Astronomy depended on what was seen through the eyepiece. Not only did it satisfy an innate curiosity, but it allowed the first astronomers to discover the beauty and the wonderment of the night sky. Before photography, all observations depended on what the astronomer saw in the eyepiece, and how they recorded their observations. This was done through notes and drawings and that is the tradition we are stressing in the observers challenge. By combining our visual observations with our drawings, and sometimes, astrophotography (from those with the equipment and talent to do so), we get a unique understanding of what it is like to look through an eyepiece, and to see what is really there. The hope is that you will read through these notes and become inspired to take more time at the eyepiece studying each object, and looking for those subtle details that you might never have noticed before. -

Vente De 2 Ans Montés Samedi 14 Mai Breeze Le 13 Mai
11saint-cloud Vente de 2 ans montés Samedi 14 mai Breeze le 13 mai en association avec Index_Alpha_14_05 24/03/11 19:09 Page 71 Index alphabétique Alphabetical index NomsNOM des yearlings . .SUF . .Nos LOT NOM LOT ALKATARA . .0142 N(FAB'S MELODY 2009) . .0030 AMESBURY . .0148 N(FACTICE 2009) . .0031 FORCE MAJEUR . .0003 N(FAR DISTANCE 2009) . .0032 JOHN TUCKER . .0103 N(FIN 2009) . .0034 LIBERTY CAT . .0116 N(FLAMES 2009) . .0035 LUCAYAN . .0051 N(FOLLE LADY 2009) . .0036 MARCILHAC . .0074 N(FRANCAIS 2009) . .0037 MOST WANTED . .0123 N(GENDER DANCE 2009) . .0038 N(ABBEYLEIX LADY 2009) . .0139 N(GERMANCE 2009) . .0039 N(ABINGTON ANGEL 2009) . .0140 N(GILT LINKED 2009) . .0040 N(AIR BISCUIT 2009) . .0141 N(GREAT LADY SLEW 2009) . .0041 N(ALL EMBRACING 2009) . .0143 N(GRIN AND DARE IT 2009) . .0042 N(AMANDIAN 2009) . .0144 N(HARIYA 2009) . .0043 N(AMAZON BEAUTY 2009) . .0145 N(HOH MY DARLING 2009) . .0044 N(AMY G 2009) . .0146 N(INFINITY 2009) . .0045 N(ANSWER DO 2009) . .0147 N(INKLING 2009) . .0046 N(ARES VALLIS 2009) . .0149 N(JUST WOOD 2009) . .0048 N(AUCTION ROOM 2009) . .0150 N(KACSA 2009) . .0049 N(AVEZIA 2009) . .0151 N(KASSARIYA 2009) . .0050 N(BARCONEY 2009) . .0152 N(LALINA 2009) . .0052 N(BASHFUL 2009) . .0153 N(LANDELA 2009) . .0053 N(BAYOURIDA 2009) . .0154 N(LES ALIZES 2009) . .0054 N(BEE EATER 2009) . .0155 N(LIBRE 2009) . .0055 N(BELLA FIORELLA 2009) . .0156 N(LOUELLA 2009) . .0056 N(BERKELEY LODGE 2009) . .0157 N(LUANDA 2009) . .0057 N(BLACK PENNY 2009) . .0158 N(LUNA NEGRA 2009) . -

Popular Names of Deep Sky (Galaxies,Nebulae and Clusters) Viciana’S List
POPULAR NAMES OF DEEP SKY (GALAXIES,NEBULAE AND CLUSTERS) VICIANA’S LIST 2ª version August 2014 There isn’t any astronomical guide or star chart without a list of popular names of deep sky objects. Given the huge amount of celestial bodies labeled only with a number, the popular names given to them serve as a friendly anchor in a broad and complicated science such as Astronomy The origin of these names is varied. Some of them come from mythology (Pleiades); others from their discoverer; some describe their shape or singularities; (for instance, a rotten egg, because of its odor); and others belong to a constellation (Great Orion Nebula); etc. The real popular names of celestial bodies are those that for some special characteristic, have been inspired by the imagination of astronomers and amateurs. The most complete list is proposed by SEDS (Students for the Exploration and Development of Space). Other sources that have been used to produce this illustrated dictionary are AstroSurf, Wikipedia, Astronomy Picture of the Day, Skymap computer program, Cartes du ciel and a large bibliography of THE NAMES OF THE UNIVERSE. If you know other name of popular deep sky objects and you think it is important to include them in the popular names’ list, please send it to [email protected] with at least three references from different websites. If you have a good photo of some of the deep sky objects, please send it with standard technical specifications and an optional comment. It will be published in the names of the Universe blog. It could also be included in the ILLUSTRATED DICTIONARY OF POPULAR NAMES OF DEEP SKY. -

High-Precision Time-Series Photometry for the Discovery and Characterization of Transiting Exoplanets
University of Louisville ThinkIR: The University of Louisville's Institutional Repository Electronic Theses and Dissertations 5-2015 High-precision time-series photometry for the discovery and characterization of transiting exoplanets. Karen Alicia Collins 1962- University of Louisville Follow this and additional works at: https://ir.library.louisville.edu/etd Part of the Astrophysics and Astronomy Commons, and the Physics Commons Recommended Citation Collins, Karen Alicia 1962-, "High-precision time-series photometry for the discovery and characterization of transiting exoplanets." (2015). Electronic Theses and Dissertations. Paper 2104. https://doi.org/10.18297/etd/2104 This Doctoral Dissertation is brought to you for free and open access by ThinkIR: The University of Louisville's Institutional Repository. It has been accepted for inclusion in Electronic Theses and Dissertations by an authorized administrator of ThinkIR: The University of Louisville's Institutional Repository. This title appears here courtesy of the author, who has retained all other copyrights. For more information, please contact [email protected]. HIGH-PRECISION TIME-SERIES PHOTOMETRY FOR THE DISCOVERY AND CHARACTERIZATION OF TRANSITING EXOPLANETS By Karen A. Collins B.S., Georgia Institute of Technology, 1984 M.S., Georgia Institute of Technology, 1990 M.S., University of Louisville, 2008 A Dissertation Submitted to the Faculty of the College of Arts and Sciences of the University of Louisville in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy in Physics Department of Physics and Astronomy University of Louisville Louisville, Kentucky May 2015 HIGH-PRECISION TIME-SERIES PHOTOMETRY FOR THE DISCOVERY AND CHARACTERIZATION OF TRANSITING EXOPLANETS By Karen A. Collins B.S., Georgia Institute of Technology, 1984 M.S., Georgia Institute of Technology, 1990 M.S., University of Louisville, 2008 A Dissertation Approved On April 17, 2015 by the following Dissertation Committee: Dissertation Director Dr. -

Meteor.Mcse.Hu
MCSE 2016/3 meteor.mcse.hu A Mars négy arca SZJA 1%! Az MCSE adószáma: 19009162-2-43 A Tharsis-régió három pajzsvulkánja és az Olympus Mons a Mars Express 2014. június 29-én készült felvételén (ESA / DLR / FU Berlin / Justin Cowart). TARTALOM Áttörés a fizikában......................... 3 GW150914: elõször hallottuk az Univerzum zenéjét....................... 4 A csillagászat ............................ 8 meteorA Magyar Csillagászati Egyesület lapja Journal of the Hungarian Astronomical Association Csillagászati hírek ........................ 10 H–1300 Budapest, Pf. 148., Hungary 1037 Budapest, Laborc u. 2/C. A távcsövek világa TELEFON/FAX: (1) 240-7708, +36-70-548-9124 Egy „klasszikus” naptávcsõ születése ........ 18 E-MAIL: [email protected], Honlap: meteor.mcse.hu HU ISSN 0133-249X Szabadszemes jelenségek Kiadó: Magyar Csillagászati Egyesület Gyöngyházfényû felhõk – történelmi észlelés! .. 22 FÔSZERKESZTÔ: Mizser Attila A hónap asztrofotója: hajnali együttállás ....... 27 SZERKESZTÔBIZOTTSÁG: Dr. Fûrész Gábor, Dr. Kiss László, Dr. Kereszturi Ákos, Dr. Kolláth Zoltán, Bolygók Mizser Attila, Dr. Sánta Gábor, Sárneczky Krisztián, Mars-oppozíció 2014 .................... 28 Dr. Szabados László és Dr. Szalai Tamás SZÍNES ELÕKÉSZÍTÉS: KÁRMÁN STÚDIÓ Nap FELELÔS KIADÓ: AZ MCSE ELNÖKE Téli változékony Napok .................38 A Meteor elôfizetési díja 2016-ra: (nem tagok számára) 7200 Ft Hold Egy szám ára: 600 Ft Januári Hold .........................42 Az egyesületi tagság formái (2016) • rendes tagsági díj (jogi személyek számára is) Meteorok -
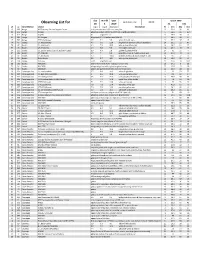
Observing List
day month year Epoch 2000 local clock time: 22.00 Observing List for 18 5 2019 RA DEC alt az Constellation object mag A mag B Separation description hr min deg min 10 305 Auriga M37 January Salt and Pepper Cluster rich, open cluster of 150 stars, very fine 5 52.4 32 33 20 315 Auriga IC2149 planetary nebula, stellar to small disk, slightly elongated 5 56.5 46 6.3 15 319 Auriga Capella 0.1 alignment star 5 16.6 46 0 21 303 Auriga UU Aurigae Magnitude 5.1-7.0 carbon star (AL# 36) 6 36.5 38 27 15 307 Auriga 37 Theta Aurigae 2.6 7.1 3.6 white & bluish stars 5 59.7 37 13 74 45 Bootes 17, Kappa Bootis 4.6 6.6 13.4 bright white primary & bluish secondary 14 13.5 51 47 73 47 Bootes 21, Iota Bootis 4.9 7.5 38.5 wide yellow & blue pair 14 16.2 51 22 57 131 Bootes 29, Pi Bootis 4.9 5.8 5.6 fine bright white pair 14 40.7 16 25 64 115 Bootes 36, Epsilon Bootis (Izar) (*311) (HIP72105) 2.9 4.9 2.8 golden & greenish-blue 14 45 27 4 57 124 Bootes 37, Xi Bootis 4.7 7 6.6 beautiful yellow & reddish orange pair 14 51.4 19 6 62 86 Bootes 51, Mu Bootis 4.3 7 108.3 primary of yellow & close orange BC pair 15 24.5 37 23 62 96 Bootes Delta Bootis 3.5 8.7 105 wide yellow & blue pair 15 15.5 33 19 62 138 Bootes Arcturus -0.11 alignment star 14 15.6 19 10.4 56 162 Bootes NGC5248 galaxy with bright stellar nucleus and oval halo 13 37.5 8 53 72 56 Bootes NGC5676 elongated galaxy with slightly brighter center 14 32.8 49 28 72 59 Bootes NGC5689 galaxy, elongated streak with prominent oval core 14 35.5 48 45 16 330 Camelopardalis 1 Camelopardalis 5.7 6.8 10.3 white & -
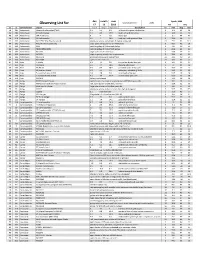
Observing List
day month year Epoch 2000 local clock time: 2.00 Observing List for 17 11 2019 RA DEC alt az Constellation object mag A mag B Separation description hr min deg min 58 286 Andromeda Gamma Andromedae (*266) 2.3 5.5 9.8 yellow & blue green double star 2 3.9 42 19 40 283 Andromeda Pi Andromedae 4.4 8.6 35.9 bright white & faint blue 0 36.9 33 43 48 295 Andromeda STF 79 (Struve) 6 7 7.8 bluish pair 1 0.1 44 42 59 279 Andromeda 59 Andromedae 6.5 7 16.6 neat pair, both greenish blue 2 10.9 39 2 32 301 Andromeda NGC 7662 (The Blue Snowball) planetary nebula, fairly bright & slightly elongated 23 25.9 42 32.1 44 292 Andromeda M31 (Andromeda Galaxy) large sprial arm galaxy like the Milky Way 0 42.7 41 16 44 291 Andromeda M32 satellite galaxy of Andromeda Galaxy 0 42.7 40 52 44 293 Andromeda M110 (NGC205) satellite galaxy of Andromeda Galaxy 0 40.4 41 41 56 279 Andromeda NGC752 large open cluster of 60 stars 1 57.8 37 41 62 285 Andromeda NGC891 edge on galaxy, needle-like in appearance 2 22.6 42 21 30 300 Andromeda NGC7640 elongated galaxy with mottled halo 23 22.1 40 51 35 308 Andromeda NGC7686 open cluster of 20 stars 23 30.2 49 8 47 258 Aries 1 Arietis 6.2 7.2 2.8 fine yellow & pale blue pair 1 50.1 22 17 57 250 Aries 30 Arietis 6.6 7.4 38.6 pleasing yellow pair 2 37 24 39 59 253 Aries 33 Arietis 5.5 8.4 28.6 yellowish-white & blue pair 2 40.7 27 4 59 239 Aries 48, Epsilon Arietis 5.2 5.5 1.5 white pair, splittable @ 150x 2 59.2 21 20 46 254 Aries 5, Gamma Arietis (*262) 4.8 4.8 7.8 nice bluish-white pair 1 53.5 19 18 49 258 Aries 9, Lambda Arietis -
5-6Index 6 MB
CLEAR SKIES OBSERVING GUIDES 5-6" Carbon Stars 228 Open Clusters 751 Globular Clusters 161 Nebulae 199 Dark Nebulae 139 Planetary Nebulae 105 Supernova Remnants 10 Galaxies 693 Asterisms 65 Other 4 Clear Skies Observing Guides - ©V.A. van Wulfen - clearskies.eu - [email protected] Index ANDROMEDA - the Princess ST Andromedae And CS SU Andromedae And CS VX Andromedae And CS AQ Andromedae And CS CGCS135 And CS UY Andromedae And CS NGC7686 And OC Alessi 22 And OC NGC752 And OC NGC956 And OC NGC7662 - "Blue Snowball Nebula" And PN NGC7640 And Gx NGC404 - "Mirach's Ghost" And Gx NGC891 - "Silver Sliver Galaxy" And Gx Messier 31 (NGC224) - "Andromeda Galaxy" And Gx Messier 32 (NGC221) And Gx Messier 110 (NGC205) And Gx "Golf Putter" And Ast ANTLIA - the Air Pump AB Antliae Ant CS U Antliae Ant CS Turner 5 Ant OC ESO435-09 Ant OC NGC2997 Ant Gx NGC3001 Ant Gx NGC3038 Ant Gx NGC3175 Ant Gx NGC3223 Ant Gx NGC3250 Ant Gx NGC3258 Ant Gx NGC3268 Ant Gx NGC3271 Ant Gx NGC3275 Ant Gx NGC3281 Ant Gx Streicher 8 - "Parabola" Ant Ast APUS - the Bird of Paradise U Apodis Aps CS IC4499 Aps GC NGC6101 Aps GC Henize 2-105 Aps PN Henize 2-131 Aps PN AQUARIUS - the Water Bearer Messier 72 (NGC6981) Aqr GC Messier 2 (NGC7089) Aqr GC NGC7492 Aqr GC NGC7009 - "Saturn Nebula" Aqr PN NGC7293 - "Helix Nebula" Aqr PN NGC7184 Aqr Gx NGC7377 Aqr Gx NGC7392 Aqr Gx NGC7585 (Arp 223) Aqr Gx NGC7606 Aqr Gx NGC7721 Aqr Gx NGC7727 (Arp 222) Aqr Gx NGC7723 Aqr Gx Messier 73 (NGC6994) Aqr Ast 14 Aquarii Group Aqr Ast 5-6" V2.4 Clear Skies Observing Guides - ©V.A.