Investigation of Transfer Languages for Parsing Latin: Italic Branch Vs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

KHAZAR UNIVERSITY Faculty
KHAZAR UNIVERSITY Faculty: School of Humanities and Social Sciences Department: English Language and Literature Specialty: English Language and Literature MA THESIS Theme: Historical English Borrowings Master Student: Aynura Huseynova Supervisor: Eldar Shahgaldiyev, Ph.D. January -2014 1 Contents Introduction…………………………………………………....3 – 9 Chapter I: Survey of the English language. Word Stock……………… 10-16 To which group does English language belong? …………… 16-23 Historical Background…………..………………................... 23-27 The historical periods of English language…………………. 27-31 Chapter II: English Borrowings and Their Structural Analysis. The History of English Language (Historical Approach)…… 32-68 Chapter III: Tendency of Future Development of English Borrowings……………………………................... 69-72 Conclusion…………………………………………............ 73-74 References………………………………………………… 75-76 2 INTRODUCTION Although at the end of the every century, learning Latin, Greek, Arabic, Spanish, German, French language spread while replacing each other. But for two centuries the English language got non-substitutive, unchanged status as the world's international language and learning of this language began to spread in our republic widely. The cause of widely spread of the English language all over the not only being the powerful maritime empire Great Britain‘s global colonization policy, but also was easy to master language. It is known that among world languages English has rich vocabulary reserve. The changes in nation's economic-political and cultural life, new production methods, new scientific achievements and technological progress, main turn in agriculture, changes in social structure, science, culture, trade, the development of literature, the creation of the state, and etc., such events were the cause of further enrichment and affect the structure of the dictionary of the English language. -
Internal Classification of Indo-European Languages: Survey
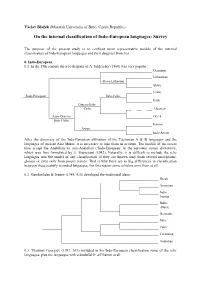
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

Curriculum Vitae
CURRICULUM VITAE Vassilis Lambropoulos C. P. Cavafy Professor of Modern Greek Professor of Classical Studies and Comparative Literature University of Michigan I. PERSONAL Born 1953, Athens, Greece II. EDUCATION University of Athens (Greece), Department of Byzantine and Modern Greek Studies, 1971-75 (B.A. 1975) University of Thessaloniki (Greece), Department of Byzantine and Modern Greek Studies, 1976- 79 (Ph.D. 1980) Dissertation Topic: The Poetics of Roman Jakobson Dissertation Title: “Roman Jakobson's Theory of Parallelism” University of Birmingham (England), School of Hellenic and Roman Studies and Department of English, 1979-81, Postdoctoral Fellow III. PROFESSIONAL HISTORY The Ohio State University, Dept. of Near Eastern, Judaic, and Hellenic Languages and Literatures (1981-96) and Dept. of Greek and Latin, Modern Greek Program (1996-99): Assistant (1981-87), Associate (1987-92), and Professor (1992-99) of Modern Greek Dept. of Comparative Studies: Associate Faculty (1989-99) Dept. of History: Associate Faculty (1997-99) University of Michigan, Departments of Classical Studies and Comparative Literature (1999-): C. P. Cavafy Professor of Modern Greek Lambropoulos CV 2 2 IV. FELLOWSHIPS, HONORS and AWARDS Greek Ministry of Culture, Undergraduate Scholarship, University of Athens (Greece), 1971-72 Greek National Scholarship Foundation, Postdoctoral Fellowship, University of Birmingham (England), 1979-81 National Endowment for the Humanities Scholarship for participation in NEH Summer Seminar for College Teachers, "Greek Concepts of Myth and Contemporary Theory," directed by Gregory Nagy, Harvard University, July-August 1985 National Endowment for the Humanities Fellowship for University Teachers, 1992-93 Ohio State University Distinguished Scholar Award (one of six campus-wide annual awards), 1994 LSA/OVPR Michigan Humanities Award (one of ten College-wide annual one-semester fellowships), 2005 Outstanding Professor of the Year Award, Office of Greek Life, University of Michigan, April 2005 The Stavros S. -

Vowel Change in English and German: a Comparative Analysis
Vowel change in English and German: a comparative analysis Miriam Calvo Fernández Degree in English Studies Academic Year: 2017/2018 Supervisor: Reinhard Bruno Stempel Department of English and German Philology and Translation Abstract English and German descend from the same parent language: West-Germanic, from which other languages, such as Dutch, Afrikaans, Flemish, or Frisian come as well. These would, therefore, be called “sister” languages, since they share a number of features in syntax, morphology or phonology, among others. The history of English and German as sister languages dates back to the Late antiquity, when they were dialects of a Proto-West-Germanic language. After their split, more than 1,400 years ago, they developed their own language systems, which were almost identical at their earlier stages. However, this is not the case anymore, as can be seen in their current vowel systems: the German vowel system is composed of 23 monophthongs and 8 diphthongs, while that of English has only 12 monophthongs and 8 diphthongs. The present paper analyses how the English and German vowels have gradually changed over time in an attempt to understand the differences and similarities found in their current vowel systems. In order to do so, I explain in detail the previous stages through which both English and German went, giving special attention to the vowel changes from a phonological perspective. Not only do I describe such processes, but I also contrast the paths both languages took, which is key to understand all the differences and similarities present in modern English and German. The analysis shows that one of the main reasons for the differences between modern German and English is to be found in all the languages English has come into contact with in the course of its history, which have exerted a significant influence on its vowel system, making it simpler than that of German. -

GREEKS and PRE-GREEKS: Aegean Prehistory and Greek
GREEKS AND PRE-GREEKS By systematically confronting Greek tradition of the Heroic Age with the evidence of both linguistics and archaeology, Margalit Finkelberg proposes a multi-disciplinary assessment of the ethnic, linguistic and cultural situation in Greece in the second millennium BC. The main thesis of this book is that the Greeks started their history as a multi-ethnic population group consisting of both Greek- speaking newcomers and the indigenous population of the land, and that the body of ‘Hellenes’ as known to us from the historic period was a deliberate self-creation. The book addresses such issues as the structure of heroic genealogy, the linguistic and cultural identity of the indigenous population of Greece, the patterns of marriage be- tween heterogeneous groups as they emerge in literary and historical sources, the dialect map of Bronze Age Greece, the factors respon- sible for the collapse of the Mycenaean civilisation and, finally, the construction of the myth of the Trojan War. margalit finkelberg is Professor of Classics at Tel Aviv University. Her previous publications include The Birth of Literary Fiction in Ancient Greece (1998). GREEKS AND PRE-GREEKS Aegean Prehistory and Greek Heroic Tradition MARGALIT FINKELBERG cambridge university press Cambridge, New York, Melbourne, Madrid, Cape Town, Singapore, São Paulo Cambridge University Press The Edinburgh Building, Cambridge cb2 2ru, UK Published in the United States of America by Cambridge University Press, New York www.cambridge.org Information on this title: www.cambridge.org/9780521852166 © Margalit Finkelberg 2005 This publication is in copyright. Subject to statutory exception and to the provision of relevant collective licensing agreements, no reproduction of any part may take place without the written permission of Cambridge University Press. -

Univerza V Mariboru Filozofska Fakulteta
UNIVERZA V MARIBORU FILOZOFSKA FAKULTETA Oddelek za anglistiko in amerikanistiko DIPLOMSKO DELO Iva Starc Maribor, 2011 UNIVERZA V MARIBORU FILOZOFSKA FAKULTETA Oddelek za anglistiko in amerikanistiko Diplomsko delo INDOEVROPEJCI IN BESEDE SKUPNEGA IZVORA INDOEVROPSKIH JEZIKOV Graduation thesis INDO-EUROPEANS AND WORDS OF COMMON ORIGINS FROM THE INDO-EUROPEAN LANGUAGES Mentorica: Kandidatka: red. prof. dr. Dunja Jutronić Iva Starc Maribor, 2011 Lektorici: Maja Schweiger, profesorica angleškega in nemškega jezika Maja Malnarič, profesorica slovenskega in nemškega jezika ZAHVALA Zahvaljujem se mentorici, red. prof. dr. Dunji Jutronić, za strokovno pomoč pri izdelavi diplomskega dela. Iskrena hvala družini in prijateljem za vso pomoč in podporo v času študija. I Z J A V A Podpisana Iva Starc, rojena 22.08.1987 študentka Filozofske fakultete Univerze v Mariboru, smer angleški jezik s književnostjo in sociologija, izjavljam, da je diplomsko delo z naslovom Indo-Europeans and words of common origins from the Indo-European languages pri mentorici red. prof. dr. Dunji Jutronić, avtorsko delo. V diplomskem delu so uporabljeni viri in literatura korektno navedeni; teksti niso prepisani brez navedbe avtorjev. _______________________ Maribor, 2011 POVZETEK Indoevropejci predstavljajo najštevilčnejšo jezikovno družino sveta. Zaradi svoje številčnosti in raznolikosti so skozi zgodovino pomembno vplivali na oblikovanje današnjega sveta. Mnogi strokovnjaki skušajo pojasniti njihov izvor in način, po katerem so živeli, a jih pri tem ovira predvsem primanjkljaj dokazov. V prvem delu diplomske naloge so bili opisani indoevropski jeziki in narodi, ki uporabljajo te jezike v Evropi in Aziji. Tako kot številna strokovna dela, se je tudi diplomsko delo poskušalo najti domovino Indoevropejcev in poti po katerih je potekala njihova razselitev. -

The Indo-Europeanization of the World from a Central Asian Homeland: New Approaches, Paradigms and Insights from Our Research Publications on Ancient India
Journal of Social Science Studies ISSN 2329-9150 2016, Vol. 3, No. 1 The Indo-Europeanization of the World from a Central Asian Homeland: New Approaches, Paradigms and Insights from Our Research Publications on Ancient India Sujay Rao Mandavilli (Corresponding author) Independent Scholar, India E-mail: [email protected] Received: August 3, 2015 Accepted: September 8, 2015 Published: September 10, 2015 doi:10.5296/jsss.v3i1.8278 URL: http://dx.doi.org/10.5296/jsss.v3i1.8278 Abstract In this paper, we bring together the concepts put forth in our previous papers and throw new light on how the Indo-Europeanization of the world may have happened from the conventional Central Asian homeland and explain the same using maps and diagrams. We also propose the ‘Ten modes of linguistic transformations associated with Human migrations.’ With this, the significance of the proposed term ‘Base Indo-European’ in lieu of the old term ‘Proto Indo-European’ will become abundantly clear to most readers. The approaches presented in this paper are somewhat superior to existing approaches, and as such are expected to replace them in the longer run. Detailed maps and notes demonstrating and explaining how linguistic transformations might have taken place in South Asia are available in this paper as understood from our previous research papers, and scholars from other parts of the world are invited to develop similar paradigms with regard to their home countries as far as the available data or evidence will allow them. This will help piece together a gigantic jig-saw puzzle, and lead to a revolution of sorts in the field, leading to a ripple-effect that will strongly impact several other related fields of study as well. -

Notes on the Consonants in the Greek of Asia Minor
The Classical Quarterly http://journals.cambridge.org/CAQ Additional services for The Classical Quarterly: Email alerts: Click here Subscriptions: Click here Commercial reprints: Click here Terms of use : Click here Notes on the Consonants in the Greek of Asia Minor D. Emrys Evans The Classical Quarterly / Volume 12 / Issue 3-4 / October 1918, pp 162 - 170 DOI: 10.1017/S000983880001260X, Published online: 11 February 2009 Link to this article: http://journals.cambridge.org/abstract_S000983880001260X How to cite this article: D. Emrys Evans (1918). Notes on the Consonants in the Greek of Asia Minor. The Classical Quarterly, 12, pp 162-170 doi:10.1017/S000983880001260X Request Permissions : Click here Downloaded from http://journals.cambridge.org/CAQ, IP address: 131.173.48.20 on 15 Apr 2015 NOTES ON THE CONSONANTS IN THE GREEK OF ASIA MINOR. THE ASPIRATES. THE change of the Greek aspirates into the voiceless spirants of the modern language was already beginning to appear in some of the ancient dialects.1 The intermediate stage in this development is naturally that of affricates, ph, th, kh, becoming pf, #, kx respectively, a stage seen in such spellings as /leTrjWaKXora.2 The evidence of the inscriptions shows that the change was not readily effected in Attic,3 and the clearest mark of this conservatism is the interchange of aspirates and tenues. The Koiprj inscriptions of Asia Minor furnish striking evidence of the value attached to the aspirates there during the early centuries of our era. An examination of the inscriptions belonging to the area, which may be taken to correspond roughly with the limits of ancient Phrygia, shows a steady confusion over a great extent of it between the aspirates </>, 8, %> and the tenues IT, T, K. -

PALEO-BALKANIAN LANGUAGES I: HELLENIC LANGUAGES in the Last
SBORNIK PRACI FILOZOFICKE FAKULTY BRNENSKE UNIVERZITY STUDIA MINORA FACULTATIS PHILOSOPHICAE UNIVERSITATIS BRUNENSIS N 10, 2005 VACLAV BLAZEK PALEO-BALKANIAN LANGUAGES I: HELLENIC LANGUAGES In the last three decades several important monographs and monographic arti cles were devoted to the Paleo-Balkanian languages. Let us mention first just these studies: GEORGIEV, VLADIMIR I. (1981). Introduction to the History of the Indo-European Lan guages. Sofia: Bulgarian Academy of Sciences, 1981. HAJNAL, IVO (2003). Methodische Vorbemerkungen zu einer Palaeolinguistik des Bal- kanraums. In Languages in Prehistoric Europe. Ed. by ALFRED BAMMESBERGER & THEO VENNEMANN. Heidelberg: Winter, 2003, 117-145. KATICIC, RADOSLAV (1976). Ancient Languages of the Balkans. The Hague — Paris: Mouton, 1976. NEROZNAK, VLADIMIR P. (1978). Paleobalkanskie jazyki. Moskva: Nauka, 1978. SOLTA, GEORG R. (1980). Einfuhrung in die Balkanlinguistik mit besonderer Berucksi- chtigung des Substrats und des Balkanlateinischen. Darmstadt: Wissenschaftliche Buchhandlung, 1980. The Indo-European languages of the ancient Balkan peninsula represent only a geographical unit. From the point of view of genetic classification, they can be classified into at least three taxonomical units, including some languages histori cally attested beyond the geographical borders of the Peninsula: I. Hellenic: Phrygian, Greek, Macedonian, Paionic, Epirotic, ?Messapic. II. South Balkanian: Pelasgic. III. Southeast Balkanian: Thracian IV. Northwest Balkanian: Daco-Getic, Mysian, Dardanian, Illyrian, Albanian. In the present study the relic languages of the first, i.e. Hellenic, group, are described. 16 VACLAV BLA2EK I. HELLENIC A. Phrygian Historical Phrygia occupied the territory between the upper streams of the Rhyndacus and Maeandrus in the west and the river Halys and the lake Tatta in the east. -

Seeking the Traces of the Indo-European Homeland
FROM AUGUST SCHLEICHER TO SERGEI STAROSTIN On the development of the tree-diagram models of the Indo-European languages Václav Blažek The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 1 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

Origin of the Slavs
ORIGIN OF THE SLAVS II Their Language, Institutions And Native Tribes by RA Goryn Table of Contents Origins of Slavonic Language In ancient times when people had to migrate they took with them their most precious possessions, the means to eke their livelihood, their cattle, the seeds to sow in the new country, and above all their gods and sacred objects to sustain their spirit and faith in the new place. The migrations from Central Asia and India to Syria, Anatolia and Europe were caused as far as we know by a natural disaster. The rise of the Himalayas, Hindu Kush and the Pamirs caused the rise of the level of the surrounding country, drying up the rivers and seas, causing drought and desiccation. The tectonic clash of the earth's crusts that produced the mountains forced several massive migrations from the area. The first civilisation in the Nile valley is identified as the product of Central Asian culture. Sumerians maintained long-standing connections between Central Asia and the Nile valley before the second known massive migration c. 5000 B.C. to Mesopotamia. The invasions of 2150 B. C. that brought the Phrygian culture to Anatolia and the Danube valley is identifiable with the first such invasion described in Greek mythology as the invasions of Osiris or Dionysus, the worshippers of Arna, and the culture that brought the Amazons to Syria, Anatolia and the Balkans. Colonisation of the Nile valley started considerably earlier than the reign of the gods and demi-gods in Egypt. The proto-Slavs are seen to have emerged out of the population that came in the third massive migration and are linked firmly by culture and religious ties to Dionysiac religious beliefs and rituals. -

Vowel Change in English and German: a Comparative Analysis
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Archivo Digital para la Docencia y la Investigación Vowel change in English and German: a comparative analysis Miriam Calvo Fernández Degree in English Studies Academic Year: 2017/2018 Supervisor: Reinhard Bruno Stempel Department of English and German Philology and Translation Abstract English and German descend from the same parent language: West-Germanic, from which other languages, such as Dutch, Afrikaans, Flemish, or Frisian come as well. These would, therefore, be called “sister” languages, since they share a number of features in syntax, morphology or phonology, among others. The history of English and German as sister languages dates back to the Late antiquity, when they were dialects of a Proto-West-Germanic language. After their split, more than 1,400 years ago, they developed their own language systems, which were almost identical at their earlier stages. However, this is not the case anymore, as can be seen in their current vowel systems: the German vowel system is composed of 23 monophthongs and 8 diphthongs, while that of English has only 12 monophthongs and 8 diphthongs. The present paper analyses how the English and German vowels have gradually changed over time in an attempt to understand the differences and similarities found in their current vowel systems. In order to do so, I explain in detail the previous stages through which both English and German went, giving special attention to the vowel changes from a phonological perspective. Not only do I describe such processes, but I also contrast the paths both languages took, which is key to understand all the differences and similarities present in modern English and German.