Operating Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -

Applicability of the Tunnel Setup Protocol (TSP) for the Hubs and Spokes Problem Draft-Blanchet-V6ops-Tunnelbroker-Tsp-03.Txt
Applicability of the Tunnel Setup Protocol (TSP) for the Hubs and Spokes Problem draft-blanchet-v6ops-tunnelbroker-tsp-03.txt IETF Softwire interim meeting Hong Kong, Feb. 2006 [email protected] [email protected] 1.0 IETF Softwire Interim – February 2006 – Hong Kong ::1 Overview • TSP and softwires requirements – Non-technical • Relation to existing standards and documentation • Document status • Independent implementations • Deployments • Time to market – Technical • NAT traversal and encapsulation types • Nomadicity, address allocation and prefix delegation •Scalability • Multicast •AAA •O&M • Additional benefits – Extensibility – Debugging and to diagnostics – Optimal encapsulation IETF Softwire Interim – February 2006 – Hong Kong ::2 Standards And Documentation • TSP is based on existing standards – Based on the tunnel broker model (RFC3053). – SASL (RFC2222) is used as authentication framework. • Supports SASL anonymous (RFC2245) • Supports Digest-MD5 (RFC2831). – Uses standard v6v4 encapsulation as specified in RFC4213. • Documentation – First published as draft-vg-ngtrans-tsp-00.txt in 2001. – Version 2.0 of the protocol (with NAT traversal) as draft-blanchet-v6ops-tunnelbroker-tsp-00.txt. – Now published as draft-blanchet-v6ops-tunnelbroker-tsp-03.txt. • Status – No issue presently documented concerning the protocol. IETF Softwire Interim – February 2006 – Hong Kong ::3 Implementations • Implemented on diverse client operating systems – Windows, MacOSX, Linux, FreeBSD, OpenBSD, NetBSD, VxWorks. • Manufacturers -

1. ARIN Ipv6 Wiki Acceptable Use
1. ARIN IPv6 Wiki Acceptable Use . 3 2. IPv6 Info Home . 3 2.1 Explore IPv6 . 5 2.1.1 The Basics . 6 2.1.1.1 IPv6 Address Allocation BCP . 6 2.1.2 IPv6 Presentations and Documents . 9 2.1.2.1 ARIN XXIII Presentations . 11 2.1.2.2 IPv6 at Caribbean Sector . 12 2.1.2.3 IPv6 at ARIN XXIII Comment . 12 2.1.2.4 IPv6 at ARIN XXI . 12 2.1.2.4.1 IPv6 at ARIN XXI Main-Event . 13 2.1.2.4.2 IPv6 at ARIN XXI Pre-Game . 14 2.1.2.4.3 IPv6 at ARIN XXI Stats . 14 2.1.2.4.4 IPv6 at ARIN XXI Network-Setup . 18 2.1.2.4.5 IPv6 at ARIN 21 . 21 2.1.3 IPv6 in the News . 21 2.1.3.1 Global IPv6 Survey . 23 2.1.3.2 IPv6 Penetration Survey Results . 23 2.1.4 Book Reviews . 25 2.1.4.1 An IPv6 Deployment Guide . 25 2.1.4.2 Day One: Advanced IPv6 Configuration . 25 2.1.4.3 Day One Exploring IPv6 . 25 2.1.4.4 IPv6 Essentials . 26 2.1.4.5 Migrating to IPv6 . 26 2.1.4.6 Running IPv6 . 26 2.1.4.7 IPv6, Theorie et pratique . 26 2.1.4.8 Internetworking IPv6 With Cisco Routers . 26 2.1.4.9 Guide to TCP/IP, 4th Edition . 26 2.1.4.10 Understanding IPv6, Third Edition . 27 2.1.5 Educating Yourself about IPv6 . -
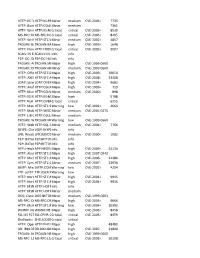
HTTP: IIS "Propfind" Rem HTTP:IIS:PROPFIND Minor Medium
HTTP: IIS "propfind"HTTP:IIS:PROPFIND RemoteMinor DoS medium CVE-2003-0226 7735 HTTP: IkonboardHTTP:CGI:IKONBOARD-BADCOOKIE IllegalMinor Cookie Languagemedium 7361 HTTP: WindowsHTTP:IIS:NSIISLOG-OF Media CriticalServices NSIISlog.DLLcritical BufferCVE-2003-0349 Overflow 8035 MS-RPC: DCOMMS-RPC:DCOM:EXPLOIT ExploitCritical critical CVE-2003-0352 8205 HTTP: WinHelp32.exeHTTP:STC:WINHELP32-OF2 RemoteMinor Buffermedium Overrun CVE-2002-0823(2) 4857 TROJAN: BackTROJAN:BACKORIFICE:BO2K-CONNECT Orifice 2000Major Client Connectionhigh CVE-1999-0660 1648 HTTP: FrontpageHTTP:FRONTPAGE:FP30REG.DLL-OF fp30reg.dllCritical Overflowcritical CVE-2003-0822 9007 SCAN: IIS EnumerationSCAN:II:IIS-ISAPI-ENUMInfo info P2P: DC: DirectP2P:DC:HUB-LOGIN ConnectInfo Plus Plus Clientinfo Hub Login TROJAN: AOLTROJAN:MISC:AOLADMIN-SRV-RESP Admin ServerMajor Responsehigh CVE-1999-0660 TROJAN: DigitalTROJAN:MISC:ROOTBEER-CLIENT RootbeerMinor Client Connectmedium CVE-1999-0660 HTTP: OfficeHTTP:STC:DL:OFFICEART-PROP Art PropertyMajor Table Bufferhigh OverflowCVE-2009-2528 36650 HTTP: AXIS CommunicationsHTTP:STC:ACTIVEX:AXIS-CAMERAMajor Camerahigh Control (AxisCamControl.ocx)CVE-2008-5260 33408 Unsafe ActiveX Control LDAP: IpswitchLDAP:OVERFLOW:IMAIL-ASN1 IMail LDAPMajor Daemonhigh Remote BufferCVE-2004-0297 Overflow 9682 HTTP: AnyformHTTP:CGI:ANYFORM-SEMICOLON SemicolonMajor high CVE-1999-0066 719 HTTP: Mini HTTP:CGI:W3-MSQL-FILE-DISCLSRSQL w3-msqlMinor File View mediumDisclosure CVE-2000-0012 898 HTTP: IIS MFCHTTP:IIS:MFC-EXT-OF ISAPI FrameworkMajor Overflowhigh (via -

Linux Ipv6 HOWTO (En)
Linux IPv6 HOWTO (en) Peter Bieringer pb at bieringer dot de Linux IPv6 HOWTO (en) by Peter Bieringer The goal of the Linux IPv6 HOWTO is to answer both basic and advanced questions about IPv6 on the Linux operating system. This HOWTO will provide the reader with enough information to install, configure, and use IPv6 applications on Linux machines. Intermediate releases of this HOWTO are available at mirrors.bieringer.de (http://mirrors.bieringer.de/Linux+IPv6-HOWTO/) or mirrors.deepspace6.net (http://mirrors.deepspace6.net/Linux+IPv6-HOWTO/). See also revision history for changes. Revision History Revision 0.67wip 2020-04-04 Revised by: PB Revision 0.66 2014-05-15 Revised by: PB Revision 0.65 2009-12-13 Revised by: PB Revision 0.64 2009-06-11 Revised by: PB Revision 0.60 2007-05-31 Revised by: PB Revision 0.51 2006-11-08 Revised by: PB Table of Contents 1. General.......................................................................................................................................................................1 1.1. Copyright, license and others.........................................................................................................................1 1.1.1. Copyright...........................................................................................................................................1 1.1.2. License...............................................................................................................................................1 1.1.3. About the author................................................................................................................................1 -

Grandstream Networks, Inc. GWN7000 Enterprise Multi-WAN Gigabit VPN Router User Manual
Grandstream Networks, Inc. GWN7000 Enterprise Multi-WAN Gigabit VPN Router User Manual COPYRIGHT ©2017 Grandstream Networks, Inc. http://www.grandstream.com All rights reserved. Information in this document is subject to change without notice. Reproduction or transmittal of the entire or any part, in any form or by any means, electronic or print, for any purpose without the express written permission of Grandstream Networks, Inc. is not permitted. The latest electronic version of this guide is available for download here: http://www.grandstream.com/support Grandstream is a registered trademark and Grandstream logo is trademark of Grandstream Networks, Inc. in the United States, Europe and other countries. OPEN SOURCE LICENSES GWN7000 firmware contains third-party open source software. Grandstream Open source licenses can be downloaded from Grandstream web site from here CAUTION Changes or modifications to this product not expressly approved by Grandstream, or operation of this product in any way other than as detailed by this guide, could void your manufacturer warranty. WARNING Please do not use a different power adaptor with devices as it may cause damage to the products and void the manufacturer warranty. P a g e | 2 GWN7000 User Manual Table of Contents DOCUMENT PURPOSE ............................................................................................... 10 CHANGE LOG .............................................................................................................. 11 Firmware Version 1.0.2.75 .................................................................................................................. -

Nav6tf Technology Report
North American IPv6 Task Force (NAv6TF) Technology Report “IPv6 Security Technology Paper” Version 1.0 July 22, 2006 Primary Author/Editor: Merike Kaeo Contributing Authors: David Green, Jim Bound, Yanick Pouffary [email protected] NAv6TF www.nav6tf.org IPv6 Network Security Architectures V1.0 1. SCOPE......................................................................................................................................................................4 2. INTRODUCTION ...................................................................................................................................................4 3. INFORMATION SECURITY FUNDAMENTALS.........................................................................................4 3.1. SECURITY PROPERTIES ......................................................................................................................................5 3.2. SECURITY SERVICES ..........................................................................................................................................6 4. COMPARING IPV4 AND IPV6 SECURITY.......................................................................................................8 5. (RE)INTRODUCING THE END-TO-END SECURITY MODEL.....................................................................9 5.1. HYBRID END-TO-END AND NETWORK CENTRIC SECURITY .............................................................................10 5.1.1. Distributed Firewalls .............................................................................................................................10 -

2010-2011 Catalog
SAN DIEGO CITY COLLEGE 2010-2011 CATALOG Fall 2010, Spring 2011, Summer 2011 1313 Park Blvd., San Diego, CA 92101 619-388-3400 www.sdcity.edu Terrence J. Burgess, Ph.D. President San Diego City College is accredited by the Accrediting Commission for Community and Junior Colleges of the Western Association of Schools and Colleges, 10 Commercial Blvd., Ste. 204, Novato, CA 94949, 415-506-0234, an institutional accrediting body recognized by the Council for Higher Education Accreditation and the U.S. Department of Education. Welcome to City College 25,000 students within the next decade, our City College Master Plan is in full swing. Welcome to City College to Welcome In 2009, we opened the one-stop Academic Success Center for students. This centralized resource hub provides academic support services to students such as the Tutoring Center, the English Center, the Math Center, Umoja- a Transfer Success Program, CalWORKs, EOPS, the Math, Engineering and Science Achievement (MESA) Program, New Horizons and TRIO. Students are also enjoying classes in the new Health, Exercise Science and Athletics facility next to the Harry West Gymnasium. In the year ahead, we break ground on several new buildings, including Arts and Humanities, Business 2 Technology, Science and a General Purpose Classroom for Math and Social Sciences. With more demands than ever on your time, City is working hard to accommodate your busy work and family schedules. We offer more than 100 majors, 100 certificate programs and 1,500 classes each semester, many online. Accredited by the Western Association of Schools and Colleges, your degree or certificate President's Message from City College certifies to transfer universities and employers that you have met the highest national Welcome to San Diego City College-- standards. -

Ipv6 for Linux and Z/VM
IPv6 for Linux and z/VM Rick Troth Velocity Software Velocity Software Inc. Velocity Software GmbH <[email protected]> 196-D Castro Street Max-Joseph-Str. 5 http://www.velocitysoftware.com/ Mountain View CA 94041 D-68167 Mannheim 650-964-8867 Germany VM and Linux Workshop 2012 +49 (0)621 373844 University of Kentucky Copyright © 2012 Velocity Software, Inc. All Rights Reserved. Other products and company names mentioned herein may be trademarks of their respective owners. Disclaimer The content of this presentation is informational only and is not intended to be an endorsement by Velocity Software. (ie: I am speaking only for myself.) The reader or attendee is responsible for his/her own use of the concepts and examples presented herein. In other words: Your mileage may vary. “It Depends.” Results not typical. Actual mileage will probably be less. Use only as directed. Do not fold, spindle, or mutilate. Not to be taken on an empty stomach. Refrigerate after opening. In all cases, “If you can't measure it, I'm just not interested.” 2 Internet Protocol Version 6 World IPv6 Day § 2011-June-8 World IPv6 Launch § 2012-June-6 3 Internet Protocol Version 6 What really is IPv6 and why should we do it? Where to get IPv6 connectivity? What systems can talk IPv6? How does one enable Ipv6? § on Linux § on z/VM Now what?? § IPv6-specific Resources 4 What happened to IPv5? Experimental § Internet Stream Protocol Not really called IPv5 Protocol header says “5” 5 Internet Protocol Version 6 Ports do not change (TCP, UDP) Funny syntax .. -

Operating Systems
Operating Systems Vlastimil Babka Lubomír Bulej Vojtechˇ Horký Petr T ˚uma Operating Systems by Vlastimil Babka, Lubomír Bulej, VojtˇechHorký, and Petr T ˚uma This material is a work in progress that is provided on a fair use condition to support the Charles University Operating Systems lecture. It should not be used for any other purpose than to support the lecture. It should not be copied to prevent existence of outdated copies. It comes without warranty of any kind. This is version 1854246b129de719fb64f40976b04a31545a422e (modified) generated on 2019-09-30 17:18:19. For the latest version, check http://d3s.mff.cuni.cz/~ceres. Table of Contents 1. Introduction.......................................................................................................................1 Foreword.......................................................................................................................1 Origins..................................................................................................................1 Structure...............................................................................................................1 Historic Perspective.....................................................................................................1 Stone Age.............................................................................................................1 Transistors............................................................................................................3 Low Integration..................................................................................................4 -
A Functional and Performance-Oriented Comparison of Transition Mechanisms for Internet Transition from Ipv4 to Ipv6 Protocol
A Functional and Performance-Oriented Comparison of Transition Mechanisms for Internet Transition from IPv4 to IPv6 Protocol A Nejc Škoberne T F C I S D P C I S Ljubljana, 2013 . A Functional and Performance-Oriented Comparison of Transition Mechanisms for Internet Transition from IPv4 to IPv6 Protocol A Nejc Škoberne T F C I S D P C I S Ljubljana, 2013 . APPROVAL I hereby declare that this submission is my own work and that to the best of my knowledge, it contains no material previously published or written by another person nor material which to a substantial extent has been accepted for the award of any other degree or diploma of the university or other institute of higher learning, except where due acknowledgement has been made. — Nejc Škoberne — December 2013 T dr. Mojca Ciglarič Assistant Professor of Computer and Information Science dr. Andrej Kos Associate Professor of Electrical Engineering dr. Zoran Bosnić Assistant Professor of Computer and Information Science Dr Olaf Maennel Lecturer of Computer Science Loughborough University . PREVIOUS PUBLICATIONS I hereby declare that the research reported herein was previously published/submitted for publication in peer reviewed journals or publicly presented at the following occa- sions: [1] N. Škoberne, O. Maennel, I. Phillips, R. Bush, J. Žorž and M. Ciglarič. IPv4 Address Sharing Mechanism Classification and Tradeoff Analysis. IEEE/ACM Transactions on Networking, volume PP, number 99, 2013. doi: 10.1109/TNET.2013.2256147 [2] N. Škoberne and M. Ciglarič. Practical Evaluation of Stateful NAT64/DNS64 Translation. Advances in Electrical and Computer Engineering, volume 11, number 3, pages 49-54, 2011. -

GWN7000 User Manual P a G E | 2
Grandstream Networks, Inc. GWN7000 Enterprise Multi-WAN Gigabit VPN Router User Manual COPYRIGHT ©2020 Grandstream Networks, Inc. http://www.grandstream.com All rights reserved. Information in this document is subject to change without notice. Reproduction or transmittal of the entire or any part, in any form or by any means, electronic or print, for any purpose without the express written permission of Grandstream Networks, Inc. is not permitted. The latest electronic version of this guide is available for download here: http://www.grandstream.com/support Grandstream is a registered trademark and Grandstream logo is trademark of Grandstream Networks, Inc. in the United States, Europe and other countries. OPEN SOURCE LICENSES GWN7000 firmware contains third-party open source software. Grandstream Open source licenses can be downloaded from Grandstream web site from here CAUTION Changes or modifications to this product not expressly approved by Grandstream, or operation of this product in any way other than as detailed by this guide, could void your manufacturer warranty. WARNING Please do not use a different power adaptor with devices as it may cause damage to the products and void the manufacturer warranty. GWN7000 User Manual P a g e | 2 Version 1.0.9.6 Table of Contents DOCUMENT PURPOSE ............................................................................................... 13 CHANGE LOG .............................................................................................................. 14 Firmware Version 1.0.9.6