Image2song: Song Retrieval Via Bridging Image Content and Lyric
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Excesss Karaoke Master by Artist
XS Master by ARTIST Artist Song Title Artist Song Title (hed) Planet Earth Bartender TOOTIMETOOTIMETOOTIM ? & The Mysterians 96 Tears E 10 Years Beautiful UGH! Wasteland 1999 Man United Squad Lift It High (All About 10,000 Maniacs Candy Everybody Wants Belief) More Than This 2 Chainz Bigger Than You (feat. Drake & Quavo) [clean] Trouble Me I'm Different 100 Proof Aged In Soul Somebody's Been Sleeping I'm Different (explicit) 10cc Donna 2 Chainz & Chris Brown Countdown Dreadlock Holiday 2 Chainz & Kendrick Fuckin' Problems I'm Mandy Fly Me Lamar I'm Not In Love 2 Chainz & Pharrell Feds Watching (explicit) Rubber Bullets 2 Chainz feat Drake No Lie (explicit) Things We Do For Love, 2 Chainz feat Kanye West Birthday Song (explicit) The 2 Evisa Oh La La La Wall Street Shuffle 2 Live Crew Do Wah Diddy Diddy 112 Dance With Me Me So Horny It's Over Now We Want Some Pussy Peaches & Cream 2 Pac California Love U Already Know Changes 112 feat Mase Puff Daddy Only You & Notorious B.I.G. Dear Mama 12 Gauge Dunkie Butt I Get Around 12 Stones We Are One Thugz Mansion 1910 Fruitgum Co. Simon Says Until The End Of Time 1975, The Chocolate 2 Pistols & Ray J You Know Me City, The 2 Pistols & T-Pain & Tay She Got It Dizm Girls (clean) 2 Unlimited No Limits If You're Too Shy (Let Me Know) 20 Fingers Short Dick Man If You're Too Shy (Let Me 21 Savage & Offset &Metro Ghostface Killers Know) Boomin & Travis Scott It's Not Living (If It's Not 21st Century Girls 21st Century Girls With You 2am Club Too Fucked Up To Call It's Not Living (If It's Not 2AM Club Not -

November '92 Sound
mb Nove er ’92 . 2 , NoSS UUNN DD HHHH, YOU DON’T know the shape I’m “O in,” Levon Helm was wailing plaintively over the P.A. as the lights came up at Off Broad- way, a St. Louis nightclub. The DJ’s choice of that particular Band normally prohibits). Brian McTavish of the number couldn’t have been more Star’s “Nighthawk” column was on assign- relevant. Four days on the road ment, so no luck there. A television spot with the Tom Russell Band were wasn't in the budget, so we'd have to rely coming to a close, leaving me primarily on word of mouth for ticket sales. fatigued and exhilarated at the same time. Day 1 – Kansas City The show had run late, and The Tom Russell Band, standin’ on the corner: Barry the management was doing its Ramus (bass), Fats Kaplin (accordion, pedal steel, Waiting at the Comfort Inn for the band harmonica, and more), Tom Russell (guitar, vocals), to roll in to town provided a chance to see a best to herd patrons out the Mike Warner (drums, backing vocals), Andrew Hardin door. As the crowd congratulat- (guitar, harmony vocals). prima donna in action. A member of Lash ing the band dispersed, S LaRue’sband was pressuring the desk clerk staff cartoonist Dug joined me in ap- to change his room assignment, first to down the hall, then, deciding that wasn’t proaching Tom, and in our best Wayne and up a request for an interview left on his toll good enough, to a different floor. -

Store Fixtures
? * J. ■?s*;''-'p ;r ■>.' S'Tli / . MARY CHENEY LIBRARY 8ATD1IIMT, NOVEMBEB XI, U « f ^ p ag e t w e l v e flIanrIirBtfr £ti»nins ¥?rdU> ATdrage D ully Nut Pruuu Run Fm ths Maath at Oetohar, IMS the roads were open for stage and wagon travel, the going waa rough In Josephine Role (!3iiirch Fair About Town and drivers had to carry their 9,594 Heard Along Main Street trusty axes to remove debrli^ fallen trees and other obstacles. Rivera Ends Tonight ORANGE HALL BINGO IIIM IxnilM P im e a of IM And on Some of Mdnche»ter*g Side Streets, Too had to ferried or forded and in flUrkwoatbor otroot |lo opene^ general the going waa anything but 22 REGULAR GAMES Mtmehester— 'A City o i VUtage Charm tbt m tf----- ** with frtenda In New comfortable, particularly for pas Another Large Crowd at Haven. ____ Before Manchester amounted to Stem prevailed, and hence most of sengers. AdvardMag oa Faga 12) MANCHESTER, CONN„ MONDAY, NOVEMBER 29,1948 (FOURI'EEN PAGES) PRICE FOUR C i m the settlement and administration “The development of the high 6 SPECIA LS VOL. LXVUL, NO, 59 A' oocUon ^M aln ot^t’e much, and when important places way system is closely related to ’St. Bridgets; Car to Be UfliUnr w u enerffioed was on the county system. Most like Coventry and Bolton, Ashford of the shipment of tobacco was by the attempt to provide a means of Awarded Sweepstoire and Door Prize loot night In preparation f o r Mon- water from a river wharf. -

Owner's Manual
Concert Performer Series Digital Piano Owner’s Manual Model: CP116 All descriptions and specifications in this manual are subject to change without notice. II Important Safety Instructions SAVE THESE INSTRUCTIONS INSTRUCTIONS PERTAINING TO A RISK OF FIRE, ELECTRIC SHOCK, OR INJURY TO PERSONS WARNING Examples of Picture Symbols TO REDUCE THE RISK OF CAUTION FIRE OR ELECTRIC denotes that care should be taken. SHOCK, DO NOT EXPOSE The example instructs the user to take care RISK OF ELECTRIC SHOCK THIS PRODUCT TO RAIN not to allow fingers to be trapped. DO NOT OPEN OR MOISTURE. denotes a prohibited operation. The example instructs that disassembly of AVIS : RISQUE DE CHOC ELECTRIQUE - NE PAS OUVRIR. the product is prohibited. TO REDUCE THE RISK OF ELECTRIC SHOCK, DO NOT REMOVE COVER (OR BACK). denotes an operation that should be NO USER-SERVICEABLE PARTS INSIDE. REFER SERVICING TO QUALIFIED SERVICE PERSONNEL. carried out. The lighting flash with arrowhead symbol, within The example instructs the user to remove the an equilateral triangle, is intended to alert the user The exclamation point within an equilateral triangle to the presence of uninsulated "dangerous voltage" is intended to alert the user to the presence of power cord plug from the AC outlet. within the product's enclosure that may be of important operating and maintenance (servicing) sufficient magnitude to constitute a risk of electric instructions in the leterature accompanying the shock to persons. product. Read all the instructions before using the product. WARNING - When using electric products, basic precautions should always be followed, including the following. Indicates a potential hazard that could result in death WARNING or serious injury if the product is handled incorrectly. -

Augsome Karaoke Song List Page 1
AUGSome Karaoke Song List 44 - When Your Heart Stops Beating 112 - Come See Me 112 - Cupid 112 - Dance With Me 112 - It's Over Now 112 - Only You 112 - Peaches And Cream 112 - U Already Know 311 - All Mixed Up 311 - Amber 311 - Beyond The Gray Sky 311 - Creatures (For A While) 311 - Don't Tread On Me 311 - Down 311 - First Straw 311 - Hey You 311 - I'll Be Here Awhile 311 - Love Song 311 - You Wouldn't Believe 411 - Dumb 411 - On My Knees 411 - Teardrops 702 - Get It Together 702 - I Still Love You 702 - Steelo 702 - Where My Girls At 911 - All I Want Is You 911 - How Do You Want Me To Love You 911 - Little Bit More, A 911 - More Than A Woman 911 - Party People (Friday Night) 911 - Private Number 1927 - That's When I Think Of You 1975 - Chocolate 1975 - City 1975 - Love Me 1975 - Robbers 1975 - Sex 1975 - Sound 1975 - Ugh 1 Giant Leap And Jazz Maxi - My Culture 10 Years - Beautiful 10 Years - Through The Iris 10 Years - Wasteland 10,000 Maniacs - Because The Night 10,000 Maniacs - Candy Everybody Wants 10,000 Maniacs - Like The Weather 10,000 Maniacs - More Than This 10,000 Maniacs - These Are The Days 10,000 Maniacs - Trouble Me 100 Proof Aged In Soul - Somebody's Been Sleeping Page 1 AUGSome Karaoke Song List 101 Dalmations - Cruella de Vil 10Cc - Donna 10Cc - Dreadlock Holiday 10Cc - I'm Mandy 10Cc - I'm Not In Love 10Cc - Rubber Bullets 10Cc - Things We Do For Love, The 10Cc - Wall Street Shuffle 112 And Ludacris - Hot And Wet 12 Gauge - Dunkie Butt 12 Stones - Crash 12 Stones - We Are One 1910 Fruitgum Co. -

R/Evolution: Social Medicine in Ink
University of Windsor Scholarship at UWindsor Electronic Theses and Dissertations Theses, Dissertations, and Major Papers 2005 R/evolution: Social medicine in ink. Philip Morais University of Windsor Follow this and additional works at: https://scholar.uwindsor.ca/etd Recommended Citation Morais, Philip, "R/evolution: Social medicine in ink." (2005). Electronic Theses and Dissertations. 3261. https://scholar.uwindsor.ca/etd/3261 This online database contains the full-text of PhD dissertations and Masters’ theses of University of Windsor students from 1954 forward. These documents are made available for personal study and research purposes only, in accordance with the Canadian Copyright Act and the Creative Commons license—CC BY-NC-ND (Attribution, Non-Commercial, No Derivative Works). Under this license, works must always be attributed to the copyright holder (original author), cannot be used for any commercial purposes, and may not be altered. Any other use would require the permission of the copyright holder. Students may inquire about withdrawing their dissertation and/or thesis from this database. For additional inquiries, please contact the repository administrator via email ([email protected]) or by telephone at 519-253-3000ext. 3208. R/Evolution: Social Medicine in Ink by Philip Morais A Thesis Submitted to the Faculty of Graduate Studies and Research through English Language, Literature and Creative Writing in Partial Fulfillment of the Requirements for the Degree of Master of Arts at the University of Windsor Windsor, Ontario, -

Carter-Exhibit-30-1497356322.Pdf
Date / Time Direction Party Description Extraction Phone Type 6/1/14 2:46 PM Incoming From: 7746788888 Conrad Roy are you okay Michelle SMS Messages 6/1/14 3:36 PM Outgoing To: 7746788888 Conrad Roy Not really why Michelle SMS Messages 6/1/14 3:47 PM Incoming From: 7746788888 Conrad Roy Because tell me Michelle SMS Messages I'm just having a hard time with food again and losing 6/1/14 3:48 PM Outgoing To: 7746788888 Conrad Roy Michelle SMS Messages weight and it makes me really upset I wish you had my problem and I had yours, because we 6/1/14 3:49 PM Incoming From: 7746788888 Conrad Roy Michelle SMS Messages both wouldn't have a problem I kinda figured out the main reason of my depression and 6/1/14 3:49 PM Incoming From: 7746788888 Conrad Roy Michelle SMS Messages anxiety in past 6/1/14 3:50 PM Outgoing To: 7746788888 Conrad Roy What do u mean? Michelle SMS Messages And we would both still have a problem haha it would just 6/1/14 3:50 PM Outgoing To: 7746788888 Conrad Roy Michelle SMS Messages get switched no because you would be able to take care of it and I would 6/1/14 3:51 PM Incoming From: 7746788888 Conrad Roy Michelle SMS Messages too 6/1/14 3:51 PM Outgoing To: 7746788888 Conrad Roy How? Michelle SMS Messages 6/1/14 3:52 PM Incoming From: 7746788888 Conrad Roy I have social anxiety Michelle SMS Messages I know you do and I wish you didn't. -

Report No Pub Date Note Abstract
DOCUMENT RESUME ED 360 203 SO 022 783 AUTHOR Kniep, Willard, Ed.; Danant, 3oelle, Ed. TITLE Perspectives from the South in Development Education. Development Education Annual 1990/1991. INSTITUTION National Clearinghouse on Development Education, New York, NY. REPORT NO ISSN- 1064-6657 PUB DATE [91] NOTE 49p. AVAILABLE FROMNational Clearinghouse on Development Education, The American Forum for Global Education, 45 John Street, Suite 1200, New York, NY 10038 ($6). PUB TYPE Collected Works - General (020) EDRS PRICE MF01/PCO2 Plus Postage. DESCRIPTORS *Developing Nations; *Economic Development; Foreign Countries; Global Approach; Industrialization; *International Education; International Programs; World Affairs IDENTIFIERS Africa; Asia; Caribbean; *Development Education; Latin America ABSTRACT This annual publication presents perspectives on development education from developing nations or "Southern" countries. The following articles are included: "Development Education: Education Beyond Labels" (P. Christenson); "Synthesis and Reflections of Annual '90/91" (J. Sommer); "Creating the World in Our Own Image: The American Media Defines Africa" (M. Mpanya); "Development Education about Africa: Decoding the Domination" (E. Aw); "InterAction Guidelines for Educating about Development" (T. Keehn; N. VanderWerf); "Understanding the Realities in Latin American & the Caribbean: An Insider's Assessment of U.S. Education Materials on the Region" (B. Taveras); "Learning about Asia by Inserting Structural Analysis in Development Education" (A. Purnomo); "Development Education within Minnesota Communities: The Role of the International Student" (D. Abebe); "Women to Women: A South-North Dialogue through Video" (C. Radomski); "The YWCA Model: An Interview with Joyce Gillilan-Goldberg"; "Development Education is a Two-Way Street: The Experience of an Indian Educator in East Tennessee" (S. Nataraj); "Partner in Residence at Heifer Project International: A Voice from the South. -
ED234413.Pdf
DOCUMENT RESUME ED 234'43.3 CS 207 855 \ 4 AUTHOR HarSte, Jerome C.;. And Others TITLE The Young Child as Writer-Reader,and Informant. Final Report. INSTITUTION Indiana Univ., Bloomington.Dept: of Language Education. SPONS AGENCY National 'nat. of Education (ED),Washington, DC. PUB'DATE Feb 83 GRANT NIE-d-80-0121 NOTE 479p.; For related document,see ED 213 041. Several pages may be marginally legible. PUB TYPE Reports - Research/Technical (143) EDRS PRICE MF01/PC20 Plus Postage. DESCRIPTORS Child Development; *ChildLanguage; Educational Theories; Integrated Activities;Language Research; *Learning Theories; *LinguisticTheory; Preschool Education; Primary Education;Reading Instruction; Reading Skills; *SociolinguisticS;SpellingrWriting Instruction; *Writing Research;Writing Skills; *Written Language IDENTIFIERS *Reading Writing' Relationship ABSTRACT The Second of a two- volumereport, this document focuses on the study of writtenlanguage growth and development 3-, 4-, 5 -, and 6-year-old children. among' The first section of thereport introduces the program of researchby examining its methodological and conceptual contexts. TheSecond section provides illustrativeand alternative looks at theyoung child as writer-reader and reader=writer,, highlighting key_transactions in literacy and literacy learning:. The third section pullstogether and kdentifies how the researchers' thinking about_literacyandliteracy learning changedas a result of their research and offersan evolving model of key proceises involved in literacylearning. The fourth section comprises a series of papers dealing with the spellingprocess, children's writing; developmentas seen in letters, rereading, and therole of literature.in the language poolof children. The fifth section contains taxonomies developed forstudying the surface textscreated by children: in the study. Extenslivereferences are included,.andan addend6m includes examples of tasksequence and researcher script, "sample characteristics" charts,and Sample characteristics statements. -
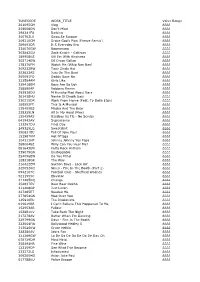
TUNECODE WORK TITLE Value Range 261095CM
TUNECODE WORK_TITLE Value Range 261095CM Vlog ££££ 259008DN Don't Mind ££££ 298241FU Barking ££££ 300703LV Swag Se Swagat ££££ 309210CM Drake God's Plan (Freeze Remix) ££££ 289693DR It S Everyday Bro ££££ 234070GW Boomerang ££££ 302842GU Zack Knight - Galtiyan ££££ 189958KS Kill Em With Kindness ££££ 302714EW Dil Diyan Gallan ££££ 178176FM Watch Me (Whip Nae Nae) ££££ 309232BW Tiger Zinda Hai ££££ 253823AS Juju On The Beat ££££ 265091FQ Daddy Says No ££££ 232584AM Girls Like ££££ 329418BM Boys Are So Ugh ££££ 258890AP Robbery Remix ££££ 292938DU M Huncho Mad About Bars ££££ 261438HU Nashe Si Chadh Gayi ££££ 230215DR Work From Home (Feat. Ty Dolla $Ign) ££££ 188552FT This Is A Musical ££££ 135455BS Masha And The Bear ££££ 238329LN All In My Head (Flex) ££££ 155459AS Bassboy Vs Tlc - No Scrubs ££££ 041942AV Supernanny ££££ 133267DU Final Day ££££ 249325LQ Sweatshirt ££££ 290631EU Fall Of Jake Paul ££££ 153987KM Hot N*Gga ££££ 304111HP Johnny Johnny Yes Papa ££££ 2680048Z Willy Can You Hear Me? ££££ 081643EN Party Rock Anthem ££££ 239079GN Unstoppable ££££ 254096EW Do You Mind ££££ 128318GR The Way ££££ 216422EM Section Boyz - Lock Arf ££££ 325052KQ Nines - Fire In The Booth (Part 2) ££££ 0942107C Football Club - Sheffield Wednes ££££ 5211555C Elevator ££££ 311205DQ Change ££££ 254637EV Baar Baar Dekho ££££ 311408GP Just Listen ££££ 227485ET Needed Me ££££ 277854GN Mad Over You ££££ 125910EU The Illusionists ££££ 019619BR I Can't Believe This Happened To Me ££££ 152953AR Fallout ££££ 153881KV Take Back The Night ££££ 217278AV Better When -
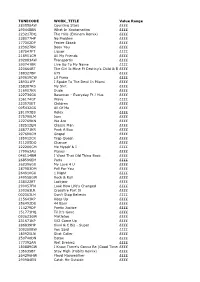
TUNECODE WORK TITLE Value Range 280558AW
TUNECODE WORK_TITLE Value Range 280558AW Counting Stars ££££ 290448BN What In Xxxtarnation ££££ 223217DQ The Hills (Eminem Remix) ££££ 238077HP No Problem ££££ 177302DP Fester Skank ££££ 223627BR Been You ££££ 187547FT Liquor ££££ 218951CM All My Friends ££££ 292083AW Transportin ££££ 290741BR Live Up To My Name ££££ 220664BT The Girl Is Mine Ft Destiny's Child & Brandy££££ 188327BP 679 ££££ 290619CW Lil Pump ££££ 289311FP I Spoke To The Devil In Miami ££££ 258307KS My Shit ££££ 216907KR Dude ££££ 222736GU Baseman - Everyday Ft J Hus ££££ 236174GT Wavy ££££ 223575ET Children ££££ 095432GS All Of Me ££££ 281093BS Rolex ££££ 275790LM Ispy ££££ 222769KN We Are ££££ 182512EN Classic Man ££££ 288771KR Peek A Boo ££££ 297690CM Gospel ££££ 185912CR Trap Queen ££££ 311205DQ Change ££££ 222206GM Me Myself & I ££££ 179963AU Planes ££££ 048114BM I Want That Old Thing Back ££££ 268596EM Paris ££££ 262396GU My Love 4 U ££££ 287983DM Fall For You ££££ 264910GU 1 Night ££££ 249558GW Rock & Roll ££££ 238022ET Lockjaw ££££ 290057FN Look How Life's Changed ££££ 230363LR Crossfire Part Iii ££££ 002363LM Don't Stop Believin ££££ 215643KP Keep Up ££££ 256492DU 44 Bars ££££ 114279DP Poetic Justice ££££ 151773HQ Til It's Gone ££££ 093623GW Mistletoe ££££ 231671KP 502 Come Up ££££ 286839HP 6ixvi & C Biz - Super ££££ 309350BW You Said ££££ 180925LN Shot Caller ££££ 250740DN Detox ££££ 177392AN Wet Dreamz ££££ 180889GW I Know There's Gonna Be (Good Times)££££ 135635BT Stay High (Habits Remix) ££££ 264296HW Floyd Mayweather ££££ 290984EN Catch Me Outside ££££ 191076BP -

William Atchison Online
William Atchison Online Compiled by Aysha Lonich, M.Ed.; annotated by Peter Langman, Ph.D. This document contains a collection of relevant forum posts, comments, and journal entries believed to have been written by William Atchison. The posts are from several of his accounts and are sequenced in chronological order. At the beginning of each year section are posts from that year whose specific publication dates are unknown. Atchison had profiles on many different websites, such as Blockland, Steam, Think Atheist, LiveJournal, Encyclopedia Dramatica, and Kiwi Farms. The creator of Kiwi Farms, Joshua Moon (whose alias is Null), began two threads shortly after the school shooting, where he and several other users posted information regarding Atchison’s aliases, profiles and posts. Articles pub- lished by The Daily Beast and The Daily Times confirmed some of this information. A complete list of sources is provided at the end of this document. This is a list of Atchison’s known aliases: Billisbill eldigato Tyrone Blacksmith Sephirot El_Digato Albanian Alchemist Sephroph Edward Digato nativenazi builder63 barajara heilkitler Kaphix Rebdoomer Sam Hyde Ganon101 DemetriusXIII Future Mass Shooter Prince N phantommastah Adam Lanza O2DGanon Norgrevival Demetrius Alcala Apophis Sturmgeist88 FuckYou MrApophis SatanicDruggie Jason Towick Digato Augustus Freeman AlGore Besides the obvious use of “Adam Lanza” as a username, several other names refer to school shooters: Rebdoomer was one of Eric Harris’s usernames; Sturmgeist88 is based on Pekka-Eric Auvinen’s username Sturmgeist89; nativenazi was one of Jeffrey Weise’s usernames. Atchison’s posts have been reprinted exactly as he wrote them. We have not made any correc- tions or alterations to the text.