Understanding Player Positions in the NBA
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Developing Small Forwards by Mike Procopio
Developing Small Forwards By Mike Procopio The Small Forward is very similar to a shooting guard as far as the skills that need to be developed. Usually the small forward is bigger than the shooting guard, which will open up more opportunities on both ends of the floor. Small forwards tend to handle the ball more in the offense than shooting guards do unless their team starts a combo guard or multiple point guards in the rotation. Most of your routine that you develop for a small forward workout should be similar than the drills used form the shooting guard workout. Where the workouts differ is the amount of screen and roll and offense off of the dribble should be increased in the small forward workout. Also, if the small forward that you are working with is bigger say 6'5 or taller at the high school/ college level or 6'6 or taller at the pro level a lot of post work should be incorporated in the routine. Opening Developing a small forward is like developing a point guard, shooting guard, and post player all in one. A small forward needs to know how to clear their defender so when you start working on off the dribble offense emphasize going somewhere with the dribble. Repetitions just like any position is very important with their mid and deep ranged jumpers. A player's physical traits (size,athletic ability, and skill) has a big impact on the workout that you put them through. Don't cookie cut your small forward workout for all small forwards. -

Determine the Position of Basketball Players Using SMART (Simple Multi-Atribute Rating Technique) Method
Determine The Position of Basketball Players Using SMART (Simple Multi-Atribute Rating Technique) Method Muhammad Ali Syakur1, Sigit Susanto Putro 2, Achmad Roviqi3, Achmad Jauhari4, Devie Rosa Anamisa5, Eka Malasari Rochman6, Mula’ab 7 {[email protected], [email protected], [email protected]} Informatic Engineering Courses, The Faculty of Engineering, Universitas trunojoyo Madura Jalan Raya Telang, PO BOX 02 Kamal, Bangkalan – 691621234567 Abstract. Basketball players usually have some playing position. A coach will determine the right position in the competition by looking the data of players. Therefore, with decision support system determine the position of the basketball player by coach is very helpful to achieve the maximum result in every competition. For building decision support system, selection position of the player comes from the player’s data using the SMART method the purpose of providing recommendation to the coaches for the selection the each player’s position, as well knowing the needs of the five player who matched is placed on the center position, point guard, Shooting guard, small forward and power forward. The result of SMART can be implemented in the election system player’s position and has a 61% accuracy is obtained from the result of comparison between the result of the calculation system with the data of the coaches recommendation. Keywords: basket ball, player position, SMART. 1 Introduction Basketball is one exercise that is done for one’s physical fitness. Many exercise can do it by someone with the abilities and their talents. One of Exercise in Indonesia is Basketball, this exercise have many fans from student in high school and collage. -

Fastest 40 Minutes in Basketball, 2012-2013
University of Arkansas, Fayetteville ScholarWorks@UARK Arkansas Men’s Basketball Athletics 2013 Media Guide: Fastest 40 Minutes in Basketball, 2012-2013 University of Arkansas, Fayetteville. Athletics Media Relations Follow this and additional works at: https://scholarworks.uark.edu/basketball-men Citation University of Arkansas, Fayetteville. Athletics Media Relations. (2013). Media Guide: Fastest 40 Minutes in Basketball, 2012-2013. Arkansas Men’s Basketball. Retrieved from https://scholarworks.uark.edu/ basketball-men/10 This Periodical is brought to you for free and open access by the Athletics at ScholarWorks@UARK. It has been accepted for inclusion in Arkansas Men’s Basketball by an authorized administrator of ScholarWorks@UARK. For more information, please contact [email protected]. TABLE OF CONTENTS This is Arkansas Basketball 2012-13 Razorbacks Razorback Records Quick Facts ........................................3 Kikko Haydar .............................48-50 1,000-Point Scorers ................124-127 Television Roster ...............................4 Rashad Madden ..........................51-53 Scoring Average Records ............... 128 Roster ................................................5 Hunter Mickelson ......................54-56 Points Records ...............................129 Bud Walton Arena ..........................6-7 Marshawn Powell .......................57-59 30-Point Games ............................. 130 Razorback Nation ...........................8-9 Rickey Scott ................................60-62 -

Basketball Study Guide
Basketball Study Guide Basketball Terms: Free Throw‐ A free shot taken from the foul line as a result of a foul. Overhead Pass‐ Throwing the ball with both hands over one’s head. Bounce Pass‐ Pass with both hands and bounces about ¾ of the way between you and your teammate. Chest Pass‐ Pass with both hands to the other teammates chest. Baseball Pass‐ Pass with one hand, similar to a baseball throw. Lob Pass‐ Normally a high pass over a defender into a post player. Basketball Positions: Center‐ Usually the tallest player on the team and works mainly under the baskets, blocking shots, grabbing rebounds and dunking. Forward‐ These players work near the basket both in offense and defense. Power Forward‐ Usually the physically larger and stronger of the forwards. Small Forward‐ Slightly bigger than guards but with plenty of style and grace and are usually more athletic than a power forward. Guard‐ These are usually the smaller, quicker players of the team but have exceptional ball handling skills. Shooting Guard‐ Usually the marksman of the team and can do anything, shoot, defend, rebound and takes a lot of the shots from the outside. Point Guard‐ The player that runs the team and brings the ball up the court for the majority of the time. Most Common Called Fouls or Infractions: Personal Foul‐ Called when illegal body contact occurs between opposing players. Charging‐ Called when a player moving with the ball runs into a defender who has established a set guarding position. Blocking‐ A defensive player may not stand in the way of a dribbling player unless that defender has established his or her position. -

Michael Jordan: a Biography
Michael Jordan: A Biography David L. Porter Greenwood Press MICHAEL JORDAN Recent Titles in Greenwood Biographies Tiger Woods: A Biography Lawrence J. Londino Mohandas K. Gandhi: A Biography Patricia Cronin Marcello Muhammad Ali: A Biography Anthony O. Edmonds Martin Luther King, Jr.: A Biography Roger Bruns Wilma Rudolph: A Biography Maureen M. Smith Condoleezza Rice: A Biography Jacqueline Edmondson Arnold Schwarzenegger: A Biography Louise Krasniewicz and Michael Blitz Billie Holiday: A Biography Meg Greene Elvis Presley: A Biography Kathleen Tracy Shaquille O’Neal: A Biography Murry R. Nelson Dr. Dre: A Biography John Borgmeyer Bonnie and Clyde: A Biography Nate Hendley Martha Stewart: A Biography Joann F. Price MICHAEL JORDAN A Biography David L. Porter GREENWOOD BIOGRAPHIES GREENWOOD PRESS WESTPORT, CONNECTICUT • LONDON Library of Congress Cataloging-in-Publication Data Porter, David L., 1941- Michael Jordan : a biography / David L. Porter. p. cm. — (Greenwood biographies, ISSN 1540–4900) Includes bibliographical references and index. ISBN-13: 978-0-313-33767-3 (alk. paper) ISBN-10: 0-313-33767-5 (alk. paper) 1. Jordan, Michael, 1963- 2. Basketball players—United States— Biography. I. Title. GV884.J67P67 2007 796.323092—dc22 [B] 2007009605 British Library Cataloguing in Publication Data is available. Copyright © 2007 by David L. Porter All rights reserved. No portion of this book may be reproduced, by any process or technique, without the express written consent of the publisher. Library of Congress Catalog Card Number: 2007009605 ISBN-13: 978–0–313–33767–3 ISBN-10: 0–313–33767–5 ISSN: 1540–4900 First published in 2007 Greenwood Press, 88 Post Road West, Westport, CT 06881 An imprint of Greenwood Publishing Group, Inc. -

Shooting Guard Day 9:00-10:00: Warmups ● 9:00-9:15: Stretch/Roll Call O Spread the Children out Across the Court
Day 2: Shooting Guard Day 9:00-10:00: Warmups ● 9:00-9:15: Stretch/Roll Call o Spread the children out across the court. 8 lines. ● 9:15-9:30: Explain the camp o Introduce coaches, curriculum, and schedule ● 9:30-9:45: Form six lines on the baseline. o Regular: Running, Back pedal, high knee, power skip, karaoke, defense slide, Frankenstein, lunges, bear-crawl ● 9:45-10:00: Ball Warm-up o Right hand, left hand, V dribble, backpedal dribble 10:00-11:00: Drill Stations ● Drill Station 1: V-Cut/L-Cut/backdoor o The coach will stand at the top of the 3-point line to start. Two lines will form on both wings of the 3-point line. Players from each line will take turns cutting for the ball. Once the cut is complete, the coach will pass to the player for a spot-up shot or lay-up. Emphasize agility and quick changes of direction. ● Drill Station 2: Help defense (One pass away) o 3 offensive players will line up around the 3-point line, within passing distance. 2 players will stand between them in defensive stance. The offensive players will pass to one-another around the perimeter. The defensive players will practice switching and help defense. Emphasize the fundamentals of 1 or 2 passes away. ● Drill Station 3: Elbow to elbow shot challenge o Set up two cones at each end of the free-throw line. The coach will stand under the basket, while the player begins at either cone. The drill begins when the coach passes to the player. -

Answer the Questions and Improve Your Knowledge of Basketball
Develop Your Knowledge of the Basketball Rules Answer the questions and improve your knowledge of Basketball The answers are on the page after the questions to help you Assignment Task 1. RULES Basketball Rules 1 Why are there rules In basketball? (ensures safety and fair competition otherwise it would be chaos) 2 How is a game of basketball started/ restarted? 2a Started 2b Restarted 3 How many players can you have on the pitch at any time? Why it is important to have rules in sports? If there were no rules in sports, then there really wouldn't be anything. Rules bring order and fairness, without rules there would be chaos, and it wouldn't be a real game; just a bunch of people doing there own thing with no goal or point. The game would actually be boring without rules. Rules are very important for anything because they make things more interesting and managed. If there were no rules in sports, then they would become boring because nobody would understand that what is going on or what not. Rules are what actually define what the game is!! If no rules existed at all, one could use boxing gloves another might use cricket balls,and another player might just run around beating people up. It is the rules that actually tell us what the sport is: including what equipment is used and what the boundaries are. Without it there would be no sports Sports have rules so everyone can play fair and there can be a winner and a loser, each of which conditions teach valuable life lessons for all. -
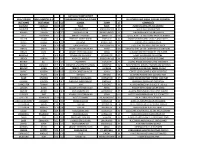
July 10-11 Camp Report (A-B-C Order) Bold Denotes D-1
JULY 10-11 CAMP REPORT (A-B-C ORDER) BOLD DENOTES D-1 UNDERLINED/ITALICS=D-2/NAIA ALL OTHERS HAVE SMALL COLLEGE POTENTIAL LAST NAME FIRST NAME HT CL SCHOOL TOWN ST COMMENTS ASHFORD MARCUS 5'10 12 PARIS PARIS KY POINT CREATES OFF THE DRIBBLE BALDWIN TYLER 6'1 10 GRACE BAPTIST MADISONVILLE KY SOLID ROLE PLAYER TYPE BARNES JOSHUA 5'10 11 SIMON KENTON INDEPENDENCE KY LEAD MAN HANDLES AND PASSES BELL CAMAYAN 5'5 8 MARIETTA MIDDLE MARIETTA GA QUICK, ATHLETIC AND LONG BACKCOURTMAN BILITER EVAN 5'8 7 PINEVILLE INDEPENDENT PINEVILLE KY HARD WORKER WHO SHOOTS AND PASSES BOLES ISAIAH 6'5 12 CAVERNA HORSE CAVE KY STRONG POST BANGS INSIDE BOX LIAM 5'10 10 GRACE BAPTIST MADISONVILLE KY EXCELS AT DISTRIBUTING THE ROCK BRADS JAMES 5'9 12 LEGACY CHRISTIAN ACAD XENIA OH POSSESSES ALL OF THE INGREDIENTS FOR POINT BRADS CLINT LEGACY CHRISTIAN ACAD XENIA OH A LEADER ON BOTH ENDS OF THE FLOOR BRANNEN CJ 6'2 11 COVINGTON CATHOLIC COVINGTON KY LANKY SWINGMAN CAN SCORE BROCK ABRAM 5'7 8 KNOX CO. MIDDLE BARBOURVILLE KY CRAFTY POINT GUARD GOT GAME BROWN ELI 5'7 9 TILGHMAN PADUCAH KY A LONG RANGE SHOOTER WHO STROKES IT BROWN DOMINIC 5'7 9 MEMPHIS UNIVERSITY SCHOOL MEMPHIS TN POINT SHOOTS, DRIVES, FINISHES AND DEFENDS BRYANT VANN 6'7 12 TRINITY CHRISTIAN JACKSON TN MOBILE 3-4 CAN PLAY INSIDE OR OUT BURKE ASHTON 5'10 12 LEGACY CHRISTIAN ACAD XENIA OH CRAFTY LEAD GUARD IS VERY VERSATILE BURNEY KYLAN 6'0 12 ANTIOCH ANTIOCH TN SLASHING PENETRATOR DEFENDS TOO BUSH LINCOLN 6'5 10 FREDERICK DOUGLASS LEXINGTON KY GOOD INSIDE/OUTSIDE THREAT CAN PLAY CALLEBS HAYDEN 5'9 8 PINEVILLE INDEPENDENT PINEVILLE KY POSSESSES EXCELLENT POTENTIAL CARPENTER TOMMY 5'9 8 IHM FLORENCE KY A HARD WORKER WHO GIVES IT HIS ALL CARSON BLAKE LEGACY CHRISTIAN ACAD XENIA OH PASSER WITH GOOD COURT SENSE CARVER ASHER 6'0 9 MUHLENBERG CO. -

ONE and DONE One and Done: Examining the Relationship
One and Done: Examining the Relationship Between Years of College Basketball Experience and Career Statistics in the National Basketball Association Item Type Article Authors Zestcott, Colin A.; Dickens, Jessie; Bracamonte, Noah; Stone, Jeff; Harrison, C. Keith Citation Zestcott, C. A., Dickens, J., Bracamonte, N., Stone, J., & Harrison, C. K. (2020). One and Done: Examining the Relationship Between Years of College Basketball Experience and Career Statistics in the National Basketball Association. Journal of Sport and Social Issues. https://doi.org/10.1177/0193723520919815 DOI 10.1177/0193723520919815 Publisher SAGE PUBLICATIONS INC Journal JOURNAL OF SPORT & SOCIAL ISSUES Rights © The Author(s) 2020. Download date 30/09/2021 22:27:17 Item License http://rightsstatements.org/vocab/InC/1.0/ Version Final accepted manuscript Link to Item http://hdl.handle.net/10150/641584 ONE AND DONE 1 One and Done: Examining the Relationship Between Years of College Basketball Experience and Career statistics in the National Basketball Association ONE AND DONE 2 Abstract Since 2006, the so-called one and done rule prevents American high school players from joining the National Basketball Association (NBA) without at least one year of college basketball experience. While there is debate about the pros and cons of the one and done rule, few studies have fully examined how minimal (or no) college experience relates to performance in the NBA. The current study used publicly available offensive and defensive statistics for all players in the NBA from 1995-2016, to examine the relationship between years of college experience and career success in the NBA. Results showed that players with less college experience had better offensive, defensive, and advanced metric (PER and VORP) statistics than players with more college experience. -

ACADEMIC FOCUS Thunderbird M En Cross Country Runners Won the Cal Poly Bronco Invitational Saturday
I T y CAMPUS SPORTS: The ACADEMIC FOCUS Thunderbird m en cross country runners won the Cal Poly Bronco Invitational Saturday. PAGE 13. 'Law and Beyond Law; CAMPUS NEWS: SUU's NATIONAL NEWS: New Peace and Justice,' is the ~ University Centers serve many wildfires empted yesterday in topic Thursday. i who can't make it to Cedar City California-this time in San every day. PAGE 3. Bernardino County. PAGE 6. PAGE 10. CAMPUS ARTS: SUU's NAT'L SPORTS: It wasn't Noel Neeb is quickly becoming much of a showdown yesterday as one of the theatre department's the Cowboys gave Jimmy Johnson Edwin Firmage busiest actors.PAGE 12. his comeuppance. PAGE 18. I ALMANAC • October 28 &. 29, satellite voter registration, IN THUNDERBIRD CIRCLE DINING: Cedar City Public Library, final chance to register for the Nov. 5 elections. Lunch (11-1:30): Meatballs and country gravy, October vegetarian lasagna, french toast stix, soup &. salad • Influenza immunizations available at SUU Student bar, grill, deli. Health Service Clinic located in the Centrum, · room 220 (8:30 a.m. to 9:20 a.m.), or in Manzanita Dinner (5-6:30): Deluxe tostado, turkey steak, soup &. C-1 (9:30 a.m. to 5 p.m.). Cost of immunization is salad bar, grill, deli. $8. WEATHER FORECAST: • Sigma Nu Eigth Annual Haunted House, 197 S. 300 W. 7-11 p.m. SNOW HIGH: Low 40s LOW: High 20s • October 28 &. 29, satellite voter registration, Cedar IN THUNDERBIRD CIRCLE DINING: City Public Library, final chance to register for the Nov. 5 elections. -

Lehigh University Athletics
5 SCHEDULE/RESULTS (0-1, 0-0 PATRIOT LEAGUE) LEHIGH Nov. 14 vs. Villanova (1) (Fox Sports 2) L, 77-66 18 CANISIUS 7:00 21 at Rider 7:00 MEN’S BASKETBALL 23 COLUMBIA 2:00 26 at DePaul (Fox Sports 1) 8:00 30 PENN STATE MONT ALTO 2:00 Sophomore Tim Kempton 2014 Patriot League Rookie of the Year Dec. 3 SAINT FRANCIS (Pa.) 7:00 6 at LIU Brooklyn 2:00 GAME 2: CANISIUS AT LEHIGH 18 at Quinnipiac 7:00 20 at Arizona State (Pac-12 Network) 10:00 CANISIUS GOLDEN GRIFFINS (1-0, 0-0 MAAC) 28 at UMBC 2:00 31 COLGATE* 2:00 at LEHIGH MOUNTAIN HAWKS (0-1, 0-0 PATRIOT LEAGUE) TUESDAY, NOVEMBER 18, 2014 • 7:00 PM Jan. 3 at Boston University 1:00 7 at Army* 7:00 STABLER ARENA (5,600) • BETHLEHEM, Pa. 10 LOYOLA* 2:00 PATRIOT LEAGUE NETWORK 14 at American* 7:30 17 HOLY CROSS* 2:00 SETTING THE SCENE 21 NAVY* 7:00 24 at Lafayette* 2:00 Coming off a back-and-forth season opener against #12 Villanova, the Lehigh men’s basketball 28 at Bucknell* 8:00 team returns to Stabler Arena to host Canisius in its home opener on Tuesday evening. Open- 31 BOSTON UNIVERSITY* 2:00 ing tipoff is set for 7 p.m. The Mountain Hawks gave the Wildcats a scare on Friday, holding as Feb. much as a five-point lead in the second half, then pulling within four with just over four minutes 4 ARMY* 7:00 remaining. -

New Coach + Quick Learners = Fast Start First-Year Coach Luke Flockerzi Introduces a New Offensive System As Men’S Basketball Gets Off to a Quick Start
sPoRts mEn’s BaskEtBall New Coach + Quick Learners = Fast Start First-year coach luke Flockerzi introduces a new offensive system as men’s basketball gets off to a quick start. By Dennis O'Donnell Where’s the center? And the power forwards, for that matter? As the Roches- ter men’s basketball team takes to the court this winter, Yellowjacket fans used to see- ing players in traditional positions will need to acquaint themselves with a new way of thinking about how to organize five athletes and a basketball. Gone is the standard system geared to- ward a point guard, off guard, small for- ward, power forward, and center. Instead, the Yellowjackets feature four perimeter positions and a low-post threat, known as the “hub.” Let first-year coach Luke Flockerzi draw it up: Most times on offense, Rochester will set four players high on the perimeter and one—the hub—low, closer to the basket. The players will analyze what the defense shows, then run the best offense to counter- act it. It’s not one-on-one basketball. It’s a mixture of seeing, thinking, and reacting— an approach that Flockerzi believes gives his players the freedom to make decisions and play basketball. “Anyone can bring the ball up the court,” Flockerzi says. “The point guard doesn’t have to initiate the offense because posi- tions are interchangeable.” Flockerzi debuted the system this win- ter as he took over the head coaching du- ties for the Yellowjackets. The former head coach at Skidmore College, Flockerzi suc- ceeds Mike Neer '88W (MS), who stepped down last spring after leading the Yellow- jackets for 34 seasons and establishing the program as one of the winningest in NCAA Division III.