Amino Acid Recognition by Aminoacyl-Trna Synthetases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Side-Chain Liquid Crystal Polymers (SCLCP): Methods and Materials. an Overview
Materials 2009, 2, 95-128; doi:10.3390/ma2010095 OPEN ACCESS materials ISSN 1996-1944 www.mdpi.com/journal/materials Review Side-chain Liquid Crystal Polymers (SCLCP): Methods and Materials. An Overview Tomasz Ganicz * and Włodzimierz Stańczyk Centre of Molecular and Macromolecular Studies, Polish Academy of Science, Sienkiewicza 112, 90- 363 Łódź, Poland; E-Mail: [email protected] * Author to whom correspondence should be addressed; E-Mail: [email protected]; Tel. +48-42-684-71-13; Fax: +48-42-684-71-26 Received: 5 February 2009; in revised form: 3 March 2009 / Accepted: 9 March 2009 / Published: 11 March 2009 Abstract: This review focuses on recent developments in the chemistry of side chain liquid crystal polymers. It concentrates on current trends in synthetic methods and novel, well defined structures, supramolecular arrangements, properties, and applications. The review covers literature published in this century, apart from some areas, such as dendritic and elastomeric systems, which have been recently reviewed. Keywords: Liquid crystals, side chain polymers, polymer modification, polymer synthesis, self-assembly. 1. Introduction Over thirty years ago the work of Finkelmann and Ringsdorf [1,2] gave important momentum to synthesis of side chain liquid crystal polymers (SCLCPs), materials which combine the anisotropy of liquid crystalline mesogens with the mechanical properties of polymers. Although there were some earlier attempts [2], their approach of decoupling the motions of a polymer main chain from a mesogen, thus allowed side chain moieties to build up long range ordering (Figure 1). They were able to synthesize polymers with nematic, smectic and cholesteric phases via free radical polymerization of methacryloyl type monomers [3]. -

The Role of Side-Chain Branch Position on Thermal Property of Poly-3-Alkylthiophenes
Polymer Chemistry The Role of Side-chain Branch Position on Thermal Property of Poly-3-alkylthiophenes Journal: Polymer Chemistry Manuscript ID PY-ART-07-2019-001026.R2 Article Type: Paper Date Submitted by the 02-Oct-2019 Author: Complete List of Authors: Gu, Xiaodan; University of Southern Mississippi, School of Polymer Science and Engineering Cao, Zhiqiang; University of Southern Mississippi, School of Polymer Science and Engineering Galuska, Luke; University of Southern Mississippi, School of Polymer Science and Engineering Qian, Zhiyuan; University of Southern Mississippi, School of Polymer Science and Engineering Zhang, Song; University of Southern Mississippi, School of Polymer Science and Engineering Huang, Lifeng; University of Southern Mississippi, School of Polymers and High Performance Materials Prine, Nathaniel; University of Southern Mississippi, School of Polymer Science and Engineering Li, Tianyu; Oak Ridge National Laboratory; University of Tennessee Knoxville He, Youjun; Oak Ridge National Laboratory Hong, Kunlun; Oak Ridge National Laboratory, Center for Nanophase Materials Science; Oak Ridge National Laboratory, Center for Nanophase Materials Science Page 1 of 13 PleasePolymer do not Chemistryadjust margins ARTICLE The Role of Side-chain Branch Position on Thermal Property of Poly-3-alkylthiophenes Received 00th January 20xx, a a a a a a Accepted 00th January 20xx Zhiqiang Cao, Luke Galuska, Zhiyuan Qian, Song Zhang, Lifeng Huang, Nathaniel Prine, Tianyu Li,b, c Youjun He,b Kunlun Hong,*b, c and Xiaodan Gu*a DOI: 10.1039/x0xx00000x Thermomechanical properties of conjugated polymers (CPs) are greatly influenced by both their microstructures and backbone structures. In the present work, to investigate the effect of side-chain branch position on the backbone’s mobility and molecular packing structure, four poly (3-alkylthiophene-2, 5-diyl) derivatives (P3ATs) with different side chains, either branched and linear, were synthesized by a quasi-living Kumada catalyst transfer polymerization (KCTP) method. -

Al Exposure Increases Proline Levels by Different Pathways in An
www.nature.com/scientificreports OPEN Al exposure increases proline levels by diferent pathways in an Al‑sensitive and an Al‑tolerant rye genotype Alexandra de Sousa1,2, Hamada AbdElgawad2,4, Fernanda Fidalgo1, Jorge Teixeira1, Manuela Matos3, Badreldin A. Hamed4, Samy Selim5, Wael N. Hozzein6, Gerrit T. S. Beemster2 & Han Asard2* Aluminium (Al) toxicity limits crop productivity, particularly at low soil pH. Proline (Pro) plays a role in protecting plants against various abiotic stresses. Using the relatively Al‑tolerant cereal rye (Secale cereale L.), we evaluated Pro metabolism in roots and shoots of two genotypes difering in Al tolerance, var. RioDeva (sensitive) and var. Beira (tolerant). Most enzyme activities and metabolites of Pro biosynthesis were analysed. Al induced increases in Pro levels in each genotype, but the mechanisms were diferent and were also diferent between roots and shoots. The Al‑tolerant genotype accumulated highest Pro levels and this stronger increase was ascribed to simultaneous activation of the ornithine (Orn)‑biosynthetic pathway and decrease in Pro oxidation. The Orn pathway was particularly enhanced in roots. Nitrate reductase (NR) activity, N levels, and N/C ratios demonstrate that N‑metabolism is less inhibited in the Al‑tolerant line. The correlation between Pro changes and diferences in Al‑sensitivity between these two genotypes, supports a role for Pro in Al tolerance. Our results suggest that diferential responses in Pro biosynthesis may be linked to N‑availability. Understanding the role of Pro in diferences between genotypes in stress responses, could be valuable in plant selection and breeding for Al resistance. Proline (Pro) is involved in a wide range of plant physiological and developmental processes1. -
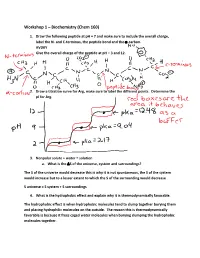
Workshop 1 – Biochemistry (Chem 160)
Workshop 1 – Biochemistry (Chem 160) 1. Draw the following peptide at pH = 7 and make sure to include the overall charge, label the N- and C-terminus, the peptide bond and the -carbon. AVDKY Give the overall charge of the peptide at pH = 3 and 12. 2. Draw a titration curve for Arg, make sure to label the different points. Determine the pI for Arg. 3. Nonpolar solute + water = solution a. What is the S of the universe, system and surroundings? The S of the universe would decrease this is why it is not spontaneous, the S of the system would increase but to a lesser extent to which the S of the surrounding would decrease S universe = S system + S surroundings 4. What is the hydrophobic effect and explain why it is thermodynamically favorable. The hydrophobic effect is when hydrophobic molecules tend to clump together burying them and placing hydrophilic molecules on the outside. The reason this is thermodynamically favorable is because it frees caged water molecules when burying clumping the hydrophobic molecules together. 5. Urea dissolves very readily in water, but the solution becomes very cold as the urea dissolves. How is this possible? Urea dissolves in water because when dissolving there is a net increase in entropy of the universe. The heat exchange, getting colder only reflects the enthalpy (H) component of the total energy change. The entropy change is high enough to offset the enthalpy component and to add up to an overall -G 6. A mutation that changes an alanine residue in the interior of a protein to valine is found to lead to a loss of activity. -

Improved Prediction of Protein Side-Chain Conformations with SCWRL4 Georgii G
proteins STRUCTURE O FUNCTION O BIOINFORMATICS Improved prediction of protein side-chain conformations with SCWRL4 Georgii G. Krivov,1,2 Maxim V. Shapovalov,1 and Roland L. Dunbrack Jr.1* 1 Institute for Cancer Research, Fox Chase Cancer Center, 333 Cottman Avenue, Philadelphia, Pennsylvania 19111 2 Department of Applied Mathematics, Moscow Engineering Physics Institute (MEPhI), Kashirskoe Shosse 31, Moscow 115409, Russian Federation INTRODUCTION ABSTRACT The side-chain conformation prediction problem is an integral Determination of side-chain conformations is an component of protein structure determination, protein structure important step in protein structure prediction and protein design. Many such methods have prediction, and protein design. In single-site mutants and in closely been presented, although only a small number related proteins, the backbone often changes little and structure pre- 1 are in widespread use. SCWRL is one such diction can be accomplished by accurate side-chain prediction. In method, and the SCWRL3 program (2003) has docking of ligands and other proteins, taking into account changes remained popular because of its speed, accuracy, in side-chain conformation is often critical to accurate structure pre- and ease-of-use for the purpose of homology dictions of complexes.2–4 Even in methods that take account of modeling. However, higher accuracy at compara- changes in backbone conformation, one step in the process is recal- ble speed is desirable. This has been achieved in culation of side-chain conformation or ‘‘repacking.’’5 Because many a new program SCWRL4 through: (1) a new backbone conformations may be sampled in model refinements, backbone-dependent rotamer library based on side-chain prediction must also be very fast. -

Selenocysteine, Pyrrolysine, and the Unique Energy Metabolism of Methanogenic Archaea
Hindawi Publishing Corporation Archaea Volume 2010, Article ID 453642, 14 pages doi:10.1155/2010/453642 Review Article Selenocysteine, Pyrrolysine, and the Unique Energy Metabolism of Methanogenic Archaea Michael Rother1 and Joseph A. Krzycki2 1 Institut fur¨ Molekulare Biowissenschaften, Molekulare Mikrobiologie & Bioenergetik, Johann Wolfgang Goethe-Universitat,¨ Max-von-Laue-Str. 9, 60438 Frankfurt am Main, Germany 2 Department of Microbiology, The Ohio State University, 376 Biological Sciences Building 484 West 12th Avenue Columbus, OH 43210-1292, USA Correspondence should be addressed to Michael Rother, [email protected] andJosephA.Krzycki,[email protected] Received 15 June 2010; Accepted 13 July 2010 Academic Editor: Jerry Eichler Copyright © 2010 M. Rother and J. A. Krzycki. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Methanogenic archaea are a group of strictly anaerobic microorganisms characterized by their strict dependence on the process of methanogenesis for energy conservation. Among the archaea, they are also the only known group synthesizing proteins containing selenocysteine or pyrrolysine. All but one of the known archaeal pyrrolysine-containing and all but two of the confirmed archaeal selenocysteine-containing protein are involved in methanogenesis. Synthesis of these proteins proceeds through suppression of translational stop codons but otherwise the two systems are fundamentally different. This paper highlights these differences and summarizes the recent developments in selenocysteine- and pyrrolysine-related research on archaea and aims to put this knowledge into the context of their unique energy metabolism. 1. Introduction found to correspond to pyrrolysine in the crystal structure [9, 10] and have its own tRNA [11]. -

Conformational Properties of Constrained Proline Analogues and Their Application in Nanobiology”
UNIVERSITAT POLITÈCNICA DE CATALUNYA DEPARTAMENT D’ENGINYERIA QUÍMICA “CONFORMATIONAL PROPERTIES OF CONSTRAINED PROLINE ANALOGUES AND THEIR APPLICATION IN NANOBIOLOGY” Alejandra Flores Ortega Supervisors: Dr. Carlos Alemán Llansó and Dr. Jordi Casanovas Salas. th Barcelona, 27 January 2009 “Chance is a word void of sense; nothing can exist without a cause”. François-Marie Arouet, Voltaire “Imagination will often carry us to worlds that never were. But without it, we go nowhere”. Carl Sagan iii ACKNOWLEDGEMENTS I would like to acknowledge to Dr. Carlos Aleman and Dr. Jordi Cassanovas Salas for an interesting research theme, and scientific support. I gratefully acknowledge to Dr. David Zanuy for interesting suggestions and strong discussions, without their support this would be an unfulfilled task. Also I, would like to address my thanks to all my colleagues in my group and department, specially Elaine Armelin for assiting me in many different ways. I thank not only my friends, but also colleagues for helping me to overcome the stressful time, without whom it would have been difficult to cope up. I wish to express my gratefulness to my parents, specially to my mother, María Esther, for all his care, and support. Also I will like to thanks to my friends and specially Jesus, Merches, Laura y Arturo. My PhD thesis have been finished for all this support. I am greatly indepted to Dr. Ruth Nussinov at NCI, Dr. Carlos Cativiela at the University of Zaragoza and Ana I. Jiménez at the “Instituto de Ciencias de Materiales de Aragon” for a collaborative effort. I wish to thank all my colleague in the “Chimie et Biochimie Théoriques, Faculté des Sciences et Techniques” in Nancy France, I will be grateful to have worked with : Pr. -

Direct Charging of Trnacua with Pyrrolysine in Vitro and in Vivo
letters to nature .............................................................. gene product (see Supplementary Fig. S1). The tRNA pool extracted from Methanosarcina acetivorans or tRNACUA transcribed in vitro Direct charging of tRNACUA with was used in charging experiments. Charged and uncharged tRNA species were separated by electrophoresis in a denaturing acid-urea pyrrolysine in vitro and in vivo 10,11 polyacrylamide gel and tRNACUA was specifically detected by northern blotting with an oligonucleotide probe. The oligonucleo- Sherry K. Blight1*, Ross C. Larue1*, Anirban Mahapatra1*, tide complementary to tRNA could hybridize to a tRNA in the David G. Longstaff1, Edward Chang1, Gang Zhao2†, Patrick T. Kang4, CUA Kari B. Green-Church5, Michael K. Chan2,3,4 & Joseph A. Krzycki1,4 pool of tRNAs isolated from wild-type M. acetivorans but not to the tRNA pool from a pylT deletion mutant of M. acetivorans (A.M., 1Department of Microbiology, 484 West 12th Avenue, 2Department of Chemistry, A. Patel, J. Soares, R.L. and J.A.K., unpublished observations). 3 100 West 18th Avenue, Department of Biochemistry, 484 West 12th Avenue, Both tRNACUA and aminoacyl-tRNACUA were detectable in the The Ohio State University, Columbus, Ohio 43210, USA isolated cellular tRNA pool (Fig. 1). Alkaline hydrolysis deacylated 4Ohio State University Biochemistry Program, 484 West 12th Avenue, The Ohio the cellular charged species, but subsequent incubation with pyrro- State University, Columbus, Ohio 43210, USA lysine, ATP and PylS-His6 resulted in maximal conversion of 50% of 5CCIC/Mass Spectrometry and Proteomics Facility, The Ohio State University, deacylated tRNACUA to a species that migrated with the same 116 W 19th Ave, Columbus, Ohio 43210, USA electrophoretic mobility as the aminoacyl-tRNACUA present in the * These authors contributed equally to this work. -

Asparagine-Proline Sequence Within Membrane-Spanning Segment of SREBP Triggers Intramembrane Cleavage by Site-2 Protease
Asparagine-proline sequence within membrane-spanning segment of SREBP triggers intramembrane cleavage by Site-2 protease Jin Ye*†, Utpal P. Dave´ *†, Nick V. Grishin‡, Joseph L. Goldstein*§, and Michael S. Brown*§ Departments of *Molecular Genetics and ‡Biochemistry, University of Texas Southwestern Medical Center, 5323 Harry Hines Boulevard, Dallas, TX 75390-9046 Contributed by Joseph L. Goldstein, March 16, 2000 The NH2-terminal domains of membrane-bound sterol regulatory nus. It translocates to the nucleus, where it activates more than element-binding proteins (SREBPs) are released into the cytosol by 20 genes encoding enzymes of cholesterol and fatty acid synthesis regulated intramembrane proteolysis, after which they enter the as well as the low density lipoprotein receptor (6, 7). When nucleus to activate genes encoding lipid biosynthetic enzymes. sterols build up in cells, the SREBP͞SCAP complex fails to exit Intramembrane proteolysis is catalyzed by Site-2 protease (S2P), a the ER, and it never reaches S1P (8, 9). As a result, the hydrophobic zinc metalloprotease that cleaves SREBPs at a mem- NH2-terminal domains of the SREBPs are no longer released brane-embedded leucine-cysteine bond. In the current study, we into the nucleus, and transcription of the target genes declines. use domain-swapping methods to localize the residues within This mechanism allows cholesterol to inhibit its own synthesis the SREBP-2 membrane-spanning segment that are required for and uptake, thereby preventing cholesterol overaccumulation in cleavage by S2P. The studies reveal a requirement for an asparag- cells. ine-proline sequence in the middle third of the transmembrane The human gene encoding S2P was cloned by complementa- segment. -

Electrochemical Studies of Dl-Leucine, L-Proline and L
ELECTROCHEMICAL STUDIES OF DL -LEUCINE, 60 L-PROLINE AND L-TRYPTOPHAN AND THEIR INTERACTION WITH COPPER AND IRON 30 c b A) M. A. Jabbar, R. J. Mannan, S. Salauddin and B. µ a Rashid 0 Department of Chemistry, University of Dhaka, ( Current Dhaka-1000, Bangladesh -30 Introduction -60 In vitro study of the charge transfer reactions coupled -800 -400 0 400 800 with chemical reactions can give important indication of Potential vs. Ag/AgCl (mV) about actual biological processes occurring in human Fig.1. Comparison of the cyclic voltammogram of system. Understanding of such charge-transfer 5.0mM (a) DL -Leucine, (b) Cu-DL -Leucine ion and mechanism will help to determine the effectiveness of (c) [Fe-DL -Leucine] in 0.1M KCl solution at a Pt- nutrition, metabolism and treatment of various biological button electrode. Scan rates 50 mV/s. disorders. In the previous research, the redox behaviour of 40 various amino acids and biochemically important compounds and their charge transfer reaction and their b interaction of metal ions were studied [1,2]. In the present 20 ) a c research, the redox behavior and the charge transfer µΑ kinetics of DL -Leucine, L-Proline and L-Tryptophan in 0 the presence and absence of copper and iron will be investigated. Current ( -20 Experimental A computerized electrochemistry system developed by -40 -800 -400 0 400 800 Advanced Analytics, Virginia, USA, (Model-2040) Potential vs. Ag/AgCl (mV) consisting of three electrodes micro-cell with a saturated Ag/AgCl reference, a Pt-wire auxiliary and a pretreated Fig.2 . Comparison of the cyclic voltammogram of Pt-button working electrode is employed to investigate 5.0mM (a) L-Proline, (b) Cu-L-Proline and (c) Fe-L- Proline in 0.1M KCl solution at a Pt-button different amino acids and metal-amino acid systems. -

Convenient Preparation of Poly(L-Histidine) by the Direct Polymerization of L-Histidine Or Nim Benzyl-L-Histidine with Diphenylphosphoryl Azide
Polymer Journal, Vol. 13, No. 12, pp 1151-1154 (1981) SHORT COMMUNICATION Convenient Preparation of Poly(L-histidine) by the Direct Polymerization of L-Histidine or Nim_Benzyl-L-histidine with Diphenylphosphoryl Azide Takumi NARUSE, Bun-ichiro NAKAJIMA, Akihiro TSUTSUMI, and Norio NISHI Department of Polymer Science, Faculty of Science, Hokkaido University, Nishi 8-chome, Kita 10-jo, Kita-ku, Sapporo 060, Japan. (Received August 14, 1981) KEY WORDS Polymerization I Diphenylphosphoryl Azide (DPPA) I L- Histidine I N'm-Benzyl-L-histidine I Poly(L-histidine) I Poly(N'm-benzyl-L histidine) I IR Spectrum I 13C NMR Spectrum I Intrinsic Viscosity I Poly(L-histidine) is a very interesting poly(a histidine) by the polymerization of L-histidine with amino acid) as a synthetic functional polymer or as iodine-phosphonic acid esters was unsuccessful. The a model for the functional biopolymer such as simplification of the synthetic route for poly(L enzymes. It is known, however, that poly(L histidine) is still necessary. histidine) can not be prepared by the Fuchs Diphenylphosphoryl azide (DPPA) has been used Farthing method 1 which is very popular for prepar as a convenient reagent for racemization-free pep ing poly(a-amino acid)s. A synthetic route with tide synthesis, since it was synthesized by Shioiri et several steps involving the synthesis of NCA (a a!. in 1972.6 Recently, we reported that this reagent amino acid N-carboxyanhydride) by the rather can also be used successfully for the polymerization classical Leuchs method/ have been used for the of amino acids or peptides. -

Amino Acid Chemistry
Handout 4 Amino Acid and Protein Chemistry ANSC 619 PHYSIOLOGICAL CHEMISTRY OF LIVESTOCK SPECIES Amino Acid Chemistry I. Chemistry of amino acids A. General amino acid structure + HN3- 1. All amino acids are carboxylic acids, i.e., they have a –COOH group at the #1 carbon. 2. All amino acids contain an amino group at the #2 carbon (may amino acids have a second amino group). 3. All amino acids are zwitterions – they contain both positive and negative charges at physiological pH. II. Essential and nonessential amino acids A. Nonessential amino acids: can make the carbon skeleton 1. From glycolysis. 2. From the TCA cycle. B. Nonessential if it can be made from an essential amino acid. 1. Amino acid "sparing". 2. May still be essential under some conditions. C. Essential amino acids 1. Branched chain amino acids (isoleucine, leucine and valine) 2. Lysine 3. Methionine 4. Phenyalanine 5. Threonine 6. Tryptophan 1 Handout 4 Amino Acid and Protein Chemistry D. Essential during rapid growth or for optimal health 1. Arginine 2. Histidine E. Nonessential amino acids 1. Alanine (from pyruvate) 2. Aspartate, asparagine (from oxaloacetate) 3. Cysteine (from serine and methionine) 4. Glutamate, glutamine (from α-ketoglutarate) 5. Glycine (from serine) 6. Proline (from glutamate) 7. Serine (from 3-phosphoglycerate) 8. Tyrosine (from phenylalanine) E. Nonessential and not required for protein synthesis 1. Hydroxyproline (made postranslationally from proline) 2. Hydroxylysine (made postranslationally from lysine) III. Acidic, basic, polar, and hydrophobic amino acids A. Acidic amino acids: amino acids that can donate a hydrogen ion (proton) and thereby decrease pH in an aqueous solution 1.