2019 Abstracts Sessions Overiew
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Crossroads in Eden: the Development of Fort Lupton, 1835-2000
CROSSROADS IN EDEN: THE DEVELOPMENT OF FORT LUPTON, 1835-2000 A HISTORICAL CONTEXT Submitted to: Historic Preservation Board City of Fort Lupton, Weld County, Colorado Prepared by: Adam Thomas SWCA Environmental Consultants State Historical Fund Project 02-02-075, Deliverable 3: Fort Lupton Historic Survey and Context SWCA Cultural Resource Report 2003-141 October 2003 CROSSROADS IN EDEN: DEVELOPMENT OF FORT LUPTON, 1835-2000 A HISTORICAL CONTEXT Submitted to: Historic Preservation Board City of Fort Lupton, Weld County, Colorado Prepared by: Adam Thomas SWCA Inc. Environmental Consultants 8461 Turnpike Drive Suite 100 Westminster, Colorado 80031 Bill Martin, Project Manager Kevin W. Thompson, Principal Investigator State Historical Fund Project 02-02-075, Deliverable 3: Fort Lupton Historic Survey and Context SWCA Cultural Resource Report 2003-141 October 2003 TABLE OF CONTENTS Introduction: Timeless Connections iv A Note on Sources v Chapter 1: South Platte River Basin Prehistory to 1860 1 European Exploration 2 • Fort Lupton and Early Settlers 6 Chapter 2: A City Develops 12 Commercial and Civic Development 14 • Residential Development 17 • Social Life and Entertainment 20 • Public Services and Utilities 22 • Churches 24 • Schools 26 Chapter 3: The Freighter’s Campground: History of Transportation in Fort Lupton 28 Stage Lines and Toll Roads 28 • Railroads 29 • The Automobile Age 33 Chapter 4: Bounty of the Earth: Agriculture, Food-Processing, and the Oil and Gas Industries 37 Ranching 37 • Farming and Irrigation 39 • Food-Processing Industry 41 • Oil and Gas 46 Chapter 5: A Town of Diversity: Ethnic Heritage of Fort Lupton 48 Germans from Russia 48 • Hispanics 50 • Japanese 55 Conclusion: A Historical Crossroads 58 Notes 59 Bibliography 66 FIGURES, MAPS, AND TABLES Fig. -

Saccadic Eye Movements and Perceptual Judgments Reveal a Shared Visual Representation That Is Increasingly Accurate Over Time ⇑ Wieske Van Zoest A, , Amelia R
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Vision Research 51 (2011) 111–119 Contents lists available at ScienceDirect Vision Research journal homepage: www.elsevier.com/locate/visres Saccadic eye movements and perceptual judgments reveal a shared visual representation that is increasingly accurate over time ⇑ Wieske van Zoest a, , Amelia R. Hunt b a Cognitive Psychology, Vrije Universiteit Amsterdam, van der Boechorststraat 1, 1081 BT, Amsterdam, The Netherlands b School of Psychology, University of Aberdeen, Aberdeen AB24 2UB, UK article info abstract Article history: Although there is evidence to suggest visual illusions affect perceptual judgments more than actions, Received 7 July 2010 many studies have failed to detect task-dependant dissociations. In two experiments we attempt to Received in revised form 22 September 2010 resolve the contradiction by exploring the time-course of visual illusion effects on both saccadic eye movements and perceptual judgments, using the Judd illusion. The results showed that, regardless of whether a saccadic response or a perceptual judgement was made, the illusory bias was larger when Keywords: responses were based on less information, that is, when saccadic latencies were short, or display duration Perception and action was brief. The time-course of the effect was similar for both the saccadic responses and perceptual judge- Visual illusions ments, suggesting that both modes may be driven by a shared visual representation. Changes in the Saccadic eye movements Time-course of processing strength of the illusion over time also highlight the importance of controlling for the latency of different response systems when evaluating possible dissociations between them. -

INDIANAPOLIS RECORDER Newspaper Media Service Guide
INDIANAPOLIS RECORDER NEwspaper mEDIA SERvICE guIDE Do you have a product you are trying to promote? Can the general community benefit from the services that your company provides? Are you trying to reach a specific audience? If you answered yes to any of these questions, the Recorder media group has exactly what you need. At 123-years-old, the Recorder has been a mainstay in the community by providing powerful and informative news that enhances the knowledge of African-Americans throughout Indiana, the country and even the world. we also have a newly-enhanced website which allow us to address your needs with a more technologically-advanced approach. we are committed to being quality news-gathering resources that not only service the general community, but also work hard to effectively meet the needs of our clients. Feel free to peruse this media kit. Our talented sales staff is readily available to provide you with a competitively-priced proposal that will successfully meet all of your needs. we are here to serve you! A RICH HISTORY OF EXCELLENCE The Indianapolis Recorder Newspaper is the nation’s fourth oldest surviving African-American newspaper in the country. What began in 1895 as a two- page church bulletin created by co-founders George P. Stewart and Will Porter now hails as one of the top African-American publications in the United States. In 1897, the newspaper’s co-founders expanded their successful newssheet into a weekly newspaper. The earliest existing issues of the Recorder date back to 1899 – the same year that Porter sold his share of the paper to Stewart. -

234 CHAPTER 6: GENERAL DISCUSSION Introduction the Broad Themes of This Thesis Have Ranged from Crossmodal Plasticity to Automat
234 CHAPTER 6: GENERAL DISCUSSION Introduction The broad themes of this thesis have ranged from crossmodal plasticity to automaticity (behavioral and neural), and rehabilitation of the blind population. Crossmodal plasticity is critical to the learning of any sensory substitution encoding, as sensory substitution inherently bridges across two modalities: the sense that receives the information, and that which interprets it. The automaticity of sensory substitution was studied both behaviorally (Chapter 3) and with neural imaging (Chapter 4). Automaticity of SS is critical to improving blind rehabilitation with sensory substitution, and the studies in this thesis will aid in the development of better training techniques and device encodings. Finally, blind rehabilitation has recurred as a theme throughout all of the thesis chapters, and is an important end application of this research. Discussion Crossmodal Plasticity Crossmodal plasticity is the foundation of all sensory substitution learning. Through crossmodal interactions and then plastic changes of those interactions, sensory substitution stimuli are interpreted visually, and action is generated. The type of plasticity, whether strengthening or weakening of existing neural connections or the generation of new neural connections, likely depends on the task, duration of training, and visual deprivation of the participant (i.e., blind or sighted). 235 The experiments in this thesis all rely on plastic changes across the senses to generate improved performance at sensory substitution tasks. The results of these plastic changes are measured behaviorally in Chapters 2 and 3, and with neural imaging (fMRI) in Chapters 4 and 5. In Chapter 2, the constancy processing of SS stimuli (after training) is likely mediated by visual neural regions that are activated by crossmodal plastic changes. -

The Ponzo Illusion with Auditory Substitution of Vision in Sighted and Early-Blind Subjects
Perception, 2005, volume 34, pages 857 ^ 867 DOI:10.1068/p5219 The Ponzo illusion with auditory substitution of vision in sighted and early-blind subjects L Renier, C Laloyauxô, O Collignon, D Tranduy, A Vanlierde, R Bruyer½, A G De Volder# Neural Rehabilitation Engineering Laboratory, Universite¨ Catholique de Louvain, 54 Avenue Hippocrate, Brussels B-1200, Belgium; ô Cognitive Science Research Unit, Universite¨ Libre de Bruxelles, 50 Avenue F D Roosevelt, Brussels B-1050, Belgium; ½ Cognitive Neurosciences Unit, Universite¨ Catholique de Louvain, 10 Place du Cardinal Mercier, Louvain-la-Neuve B-1348, Belgium; e-mail: [email protected] Received 12 February 2004, in revised form 22 November 2004; published online 6 July 2005 Abstract. We tested the effects of using a prosthesis for substitution of vision with audition (PSVA) on sensitivity to the Ponzo illusion. The effects of visual experience on the susceptibility to this illusion were also assessed. In one experiment, both early-blind and blindfolded sighted volunteers used the PSVA to explore several variants of the Ponzo illusion as well as control stimuli. No effects of the illusion were observed. The results indicate that subjects focused their attention on the two central horizontal bars of the stimuli, without processing the contextual cues that convey perspective in the Ponzo figure. In a second experiment, we required subjects to use the PSVA to consider the two converging oblique lines of the stimuli before comparing the length of the two horizontal bars. Here we were able to observe susceptibility to the Ponzo illusion in the sighted group, but to a lesser extent than in a sighted non-PSVA control group. -

Overbrook Presbyterian Church News from the Crossroads February 2019 Letter from the Pastor
Overbrook Presbyterian Church News from the Crossroads February 2019 Letter from the Pastor Overbrook Presbyterian Friends, Church is a welcoming and diverse Christian While God does not change, I give great thanks that we continue to change! community that seeks actively to love and serve God, each other, Scripture reminds us that “Jesus Christ is the same yesterday and today and and the world. forever” (Hebrews 13:8, NRSV). Our faithful response is to be “transformed by the renewing —Mission Statement of our minds” (Romans 12:2b), taking comfort that Christ is making “all things new” (Revelation 21:5). Notice how Christ is not making new things, there is a transformation that all things are new. Rev. Raymond Bonwell Bridge Pastor Things continue to change at Overbrook Presbyterian Church. The shift to intentional education for all ages (3-103) was off to a magnificent start. There were 29 adults present in Rev. David K. McMillan the Chapel on Sunday, January 6, as we began a look at the Sermon on the Mount (Matthew Pastor Emeritus 5-7). Dr. Christopher Gage Director of Music This shift allows the entire community to worship together, and to participate together after Sharon Parker worship. This time after worship will be very important on February 24, when Session has called a congregational meeting to 1. Vote on the Pastoral Candidate, and 2. Receive the Annual Reports. Lisa Faso Office Manager As you heard from the Pastoral Nominating Committee (PNC) at worship on Sunday, January 27, the PNC has identified a candidate they will nominate. The candidate will Carol Rozmiarek preach on Sunday, February 24, with the congregational meeting immediately to follow to Financial Secretary vote. -
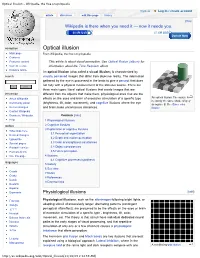
Optical Illusion - Wikipedia, the Free Encyclopedia
Optical illusion - Wikipedia, the free encyclopedia Try Beta Log in / create account article discussion edit this page history [Hide] Wikipedia is there when you need it — now it needs you. $0.6M USD $7.5M USD Donate Now navigation Optical illusion Main page From Wikipedia, the free encyclopedia Contents Featured content This article is about visual perception. See Optical Illusion (album) for Current events information about the Time Requiem album. Random article An optical illusion (also called a visual illusion) is characterized by search visually perceived images that differ from objective reality. The information gathered by the eye is processed in the brain to give a percept that does not tally with a physical measurement of the stimulus source. There are three main types: literal optical illusions that create images that are interaction different from the objects that make them, physiological ones that are the An optical illusion. The square A About Wikipedia effects on the eyes and brain of excessive stimulation of a specific type is exactly the same shade of grey Community portal (brightness, tilt, color, movement), and cognitive illusions where the eye as square B. See Same color Recent changes and brain make unconscious inferences. illusion Contact Wikipedia Donate to Wikipedia Contents [hide] Help 1 Physiological illusions toolbox 2 Cognitive illusions 3 Explanation of cognitive illusions What links here 3.1 Perceptual organization Related changes 3.2 Depth and motion perception Upload file Special pages 3.3 Color and brightness -

Geometrical Illusions
Oxford Reference The Oxford Companion to Consciousness Edited by Tim Bayne, Axel Cleeremans, and Patrick Wilken Publisher: Oxford University Press Print Publication Date: 2009 Print ISBN-13: 9780198569510 Published online: 2010 Current Online Version: 2010 eISBN: 9780191727924 illusions Illusions confuse and bias the machinery in the brain that constructs our representations of the world, because they reveal a discrepancy between what we perceive and what is objectively out there in the world. But both illusions and accurate perceptions are governed by the same lawful perceptual processes. Despite the deceptive simplicity of illusions, there are no fully agreed theories about their causes. Illusions include geometrical illusions, in which angles, lengths, or shapes are misperceived; illusions of lightness, in which the context distorts the perceived lightness of objects; and illusions of representation, including puzzle pictures, ambiguous pictures, and impossible figures. 1. Geometrical illusions 2. Illusions of lightness 3. Illusions of representation 1. Geometrical illusions Figure I1 shows some illusory distortions in perceived angles, named after their discoverers; the Zollner, Hering and Poggendorff illusions, and Fraser's LIFE figure. Length illusions include the Müller–Lyer, the vertical–horizontal, and the Ponzo illusion. Shape illusions include Roger Shepard's tables and Kitaoka's bulge illusion. In the Zollner illusion, the long oblique lines are parallel, but they appear to be tilted away from the small fins that cross them. In the Hering illusion the verticals are parallel but appear to be bowed outward, again in a direction away from the inducing lines. In the Poggendorff illusion, the right‐hand oblique line looks as though it would pass above the left‐hand oblique if extended, although both are really exactly aligned. -

Research Article Looking Into Task-Specific Activation Using a Prosthesis Substituting Vision with Audition
International Scholarly Research Network ISRN Rehabilitation Volume 2012, Article ID 490950, 15 pages doi:10.5402/2012/490950 Research Article Looking into Task-Specific Activation Using a Prosthesis Substituting Vision with Audition Paula Plaza,1 Isabel Cuevas,1 Cecile´ Grandin,2 Anne G. De Volder,1 and Laurent Renier1 1 Neural Rehabilitation Group, Institute of Neuroscience, Universit´eCatholiquedeLouvain,AvenueHippocrate54, UCL B1.54.09, 1200 Brussels, Belgium 2 Functional Magnetic Resonance Imaging Section, Department of Radiology, Universit´e Catholique de Louvain, Cliniques Universitaires Saint-Luc, Avenue Hippocrate 10, 1200 Brussels, Belgium Correspondence should be addressed to Anne G. De Volder, [email protected] Received 26 August 2011; Accepted 25 October 2011 Academic Editors: G. Kerkhoff and C. I. Renner Copyright © 2012 Paula Plaza et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. A visual-to-auditory sensory substitution device initially developed for the blind is known to allow visual-like perception through sequential exploratory strategies. Here we used functional magnetic resonance imaging (fMRI) to test whether processing the location versus the orientation of simple (elementary) “visual” stimuli encoded into sounds using the device modulates the brain activity within the dorsal visual stream in the absence of sequential exploration of these stimuli. Location and orientation detection with the device induced a similar recruitment of frontoparietal brain areas in blindfolded sighted subjects as the corresponding tasks using the same stimuli in the same subjects in vision. We observed a similar preference of the right superior parietal lobule for spatial localization over orientation processing in both sensory modalities. -

Susceptibility to Ebbinghaus and Müller-Lyer
Manning et al. Molecular Autism (2017) 8:16 DOI 10.1186/s13229-017-0127-y RESEARCH Open Access Susceptibility to Ebbinghaus and Müller- Lyer illusions in autistic children: a comparison of three different methods Catherine Manning1* , Michael J. Morgan2,3, Craig T. W. Allen4 and Elizabeth Pellicano4,5 Abstract Background: Studies reporting altered susceptibility to visual illusions in autistic individuals compared to that typically developing individuals have been taken to reflect differences in perception (e.g. reduced global processing), but could instead reflect differences in higher-level decision-making strategies. Methods: We measured susceptibility to two contextual illusions (Ebbinghaus, Müller-Lyer) in autistic children aged 6–14 years and typically developing children matched in age and non-verbal ability using three methods. In experiment 1, we used a new two-alternative-forced-choice method with a roving pedestal designed to minimise cognitive biases. Here, children judged which of two comparison stimuli was most similar in size to a reference stimulus. In experiments 2 and 3, we used methods previously used with autistic populations. In experiment 2, children judged whether stimuli were the ‘same’ or ‘different’, and in experiment 3, we used a method-of- adjustment task. Results: Across all tasks, autistic children were equally susceptible to the Ebbinghaus illusion as typically developing children. Autistic children showed a heightened susceptibility to the Müller-Lyer illusion, but only in the method-of- adjustment task. This result may reflect differences in decisional criteria. Conclusions: Our results are inconsistent with theories proposing reduced contextual integration in autism and suggest that previous reports of altered susceptibility to illusions may arise from differences in decision-making, rather than differences in perception per se. -

Visual Illusions: an Interesting Tool to Investigate Developmental Dyslexia and Autism Spectrum Disorder
fnhum-10-00175 April 21, 2016 Time: 15:22 # 1 CORE Metadata, citation and similar papers at core.ac.uk Provided by Frontiers - Publisher Connector REVIEW published: 25 April 2016 doi: 10.3389/fnhum.2016.00175 Visual Illusions: An Interesting Tool to Investigate Developmental Dyslexia and Autism Spectrum Disorder Simone Gori1,2*, Massimo Molteni2 and Andrea Facoetti2,3 1 Department of Human and Social Sciences, University of Bergamo, Bergamo, Italy, 2 Child Psychopathology Unit, Scientific Institute, IRCCS Eugenio Medea, Bosisio Parini, Italy, 3 Developmental and Cognitive Neuroscience Lab, Department of General Psychology, University of Padova, Padua, Italy A visual illusion refers to a percept that is different in some aspect from the physical stimulus. Illusions are a powerful non-invasive tool for understanding the neurobiology of vision, telling us, indirectly, how the brain processes visual stimuli. There are some neurodevelopmental disorders characterized by visual deficits. Surprisingly, just a few studies investigated illusory perception in clinical populations. Our aim is to review the literature supporting a possible role for visual illusions in helping us understand the visual deficits in developmental dyslexia and autism spectrum disorder. Future studies could develop new tools – based on visual illusions – to identify an early risk for neurodevelopmental disorders. Keywords: illusory effect, perception, attention, autistic traits, reading disorder VISUAL ILLUSION AS A TOOL TO INVESTIGATE BRAIN Edited by: PROCESSING Baingio Pinna, University of Sassari, Italy A visual illusion refers to a percept that is different from what would be typically predicted based Reviewed by: on the physical stimulus. Illusory perception is often experienced as a real percept. -

A Review of Abnormalities in the Perception of Visual Illusions in Schizophrenia
Psychon Bull Rev (2017) 24:734–751 DOI 10.3758/s13423-016-1168-5 THEORETICAL REVIEW A review of abnormalities in the perception of visual illusions in schizophrenia Daniel J. King1 & Joanne Hodgekins2 & Philippe A. Chouinard3 & Virginie-Anne Chouinard4,5 & Irene Sperandio6 Published online: 11 October 2016 # The Author(s) 2016. This article is published with open access at Springerlink.com Abstract Specific abnormalities of vision in schizophre- Keywords Schizophrenia . Visual illusions . Low-level nia have been observed to affect high-level and some vision . High-level vision low-level integration mechanisms, suggesting that people with schizophrenia may experience anomalies across dif- ferent stages in the visual system affecting either early or Introduction late processing or both. Here, we review the research into visual illusion perception in schizophrenia and the Visual illusions are a key methodology in vision research to issues which previous research has faced. One general help us understand and make inferences about the mecha- finding that emerged from the literature is that those with nisms for creating subjective experiences of the visual world. schizophrenia are mostly immune to the effects of high- They place constraints on the processing of a stimulus and level illusory displays, but this effect is not consistent allow for the reliable manipulation and quantification of the across all low-level illusions. The present review sug- visual mechanisms the illusion engages (Silverstein & Keane, gests that this resistance is due to the weakening of 2011b). Examining visual illusions in individuals with schizo- top–down perceptual mechanisms and may be relevant phrenia may provide further insight into how these individuals to the understanding of symptoms of visual distortion perceive the world and how their visual perception differs rather than hallucinations as previously thought.