Metagenomic Screening for Lipolytic Genes Reveals an Ecology-Clustered Distribution Pattern
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
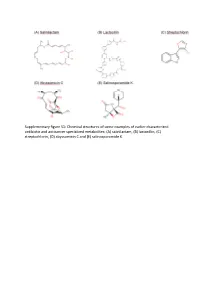
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

Genomics 98 (2011) 370–375
Genomics 98 (2011) 370–375 Contents lists available at ScienceDirect Genomics journal homepage: www.elsevier.com/locate/ygeno Whole-genome comparison clarifies close phylogenetic relationships between the phyla Dictyoglomi and Thermotogae Hiromi Nishida a,⁎, Teruhiko Beppu b, Kenji Ueda b a Agricultural Bioinformatics Research Unit, Graduate School of Agricultural and Life Sciences, University of Tokyo, 1-1-1 Yayoi, Bunkyo-ku, Tokyo 113-8657, Japan b Life Science Research Center, College of Bioresource Sciences, Nihon University, Fujisawa, Japan article info abstract Article history: The anaerobic thermophilic bacterial genus Dictyoglomus is characterized by the ability to produce useful Received 2 June 2011 enzymes such as amylase, mannanase, and xylanase. Despite the significance, the phylogenetic position of Accepted 1 August 2011 Dictyoglomus has not yet been clarified, since it exhibits ambiguous phylogenetic positions in a single gene Available online 7 August 2011 sequence comparison-based analysis. The number of substitutions at the diverging point of Dictyoglomus is insufficient to show the relationships in a single gene comparison-based analysis. Hence, we studied its Keywords: evolutionary trait based on whole-genome comparison. Both gene content and orthologous protein sequence Whole-genome comparison Dictyoglomus comparisons indicated that Dictyoglomus is most closely related to the phylum Thermotogae and it forms a Bacterial systematics monophyletic group with Coprothermobacter proteolyticus (a constituent of the phylum Firmicutes) and Coprothermobacter proteolyticus Thermotogae. Our findings indicate that C. proteolyticus does not belong to the phylum Firmicutes and that the Thermotogae phylum Dictyoglomi is not closely related to either the phylum Firmicutes or Synergistetes but to the phylum Thermotogae. © 2011 Elsevier Inc. -

Diversity of Understudied Archaeal and Bacterial Populations of Yellowstone National Park: from Genes to Genomes Daniel Colman
University of New Mexico UNM Digital Repository Biology ETDs Electronic Theses and Dissertations 7-1-2015 Diversity of understudied archaeal and bacterial populations of Yellowstone National Park: from genes to genomes Daniel Colman Follow this and additional works at: https://digitalrepository.unm.edu/biol_etds Recommended Citation Colman, Daniel. "Diversity of understudied archaeal and bacterial populations of Yellowstone National Park: from genes to genomes." (2015). https://digitalrepository.unm.edu/biol_etds/18 This Dissertation is brought to you for free and open access by the Electronic Theses and Dissertations at UNM Digital Repository. It has been accepted for inclusion in Biology ETDs by an authorized administrator of UNM Digital Repository. For more information, please contact [email protected]. Daniel Robert Colman Candidate Biology Department This dissertation is approved, and it is acceptable in quality and form for publication: Approved by the Dissertation Committee: Cristina Takacs-Vesbach , Chairperson Robert Sinsabaugh Laura Crossey Diana Northup i Diversity of understudied archaeal and bacterial populations from Yellowstone National Park: from genes to genomes by Daniel Robert Colman B.S. Biology, University of New Mexico, 2009 DISSERTATION Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy Biology The University of New Mexico Albuquerque, New Mexico July 2015 ii DEDICATION I would like to dedicate this dissertation to my late grandfather, Kenneth Leo Colman, associate professor of Animal Science in the Wool laboratory at Montana State University, who even very near the end of his earthly tenure, thought it pertinent to quiz my knowledge of oxidized nitrogen compounds. He was a man of great curiosity about the natural world, and to whom I owe an acknowledgement for his legacy of intellectual (and actual) wanderlust. -

Thermaerobacter Marianensis Type Strain (7P75a)
Lawrence Berkeley National Laboratory Recent Work Title Complete genome sequence of Thermaerobacter marianensis type strain (7p75a). Permalink https://escholarship.org/uc/item/2km2g1rj Journal Standards in genomic sciences, 3(3) ISSN 1944-3277 Authors Han, Cliff Gu, Wei Zhang, Xiaojing et al. Publication Date 2010-12-15 DOI 10.4056/sigs.1373474 Peer reviewed eScholarship.org Powered by the California Digital Library University of California Standards in Genomic Sciences (2010) 3:337-345 DOI:10.4056/sigs.1373474 Complete genome sequence of Thermaerobacter T marianensis type strain (7p75a ) Cliff Han1,2, Wei Gu1,2, Xiaojing Zhang1,2, Alla Lapidus1, Matt Nolan1, Alex Copeland1, Susan Lucas1, Tijana Glavina Del Rio1, Hope Tice1, Jan-Fang Cheng1, Roxane Tapia1,2, Lynne Goodwin1,2, Sam Pitluck1, Ioanna Pagani1, Natalia Ivanova1, Konstantinos Mavromatis1, Natalia Mikhailova1, Amrita Pati1, Amy Chen3, Krishna Palaniappan3, Miriam Land1,4, Loren Hauser1,4, Yun-Juan Chang1,4, Cynthia D. Jeffries1,4, Susanne Schneider5, Manfred Rohde6, Markus Göker5, Rüdiger Pukall5, Tanja Woyke1, James Bristow1, Jonathan A. Eisen1,7, Victor Markowitz3, Philip Hugenholtz1, Nikos C. Kyrpides1, Hans-Peter Klenk5*, and John C. Detter1,2 1 DOE Joint Genome Institute, Walnut Creek, California, USA 2 Los Alamos National Laboratory, Bioscience Division, Los Alamos, New Mexico, USA 3 Biological Data Management and Technology Center, Lawrence Berkeley National Laboratory, Berkeley, California, USA 4 Oak Ridge National Laboratory, Oak Ridge, Tennessee, USA 5 DSMZ - German Collection of Microorganisms and Cell Cultures GmbH, Braunschweig, Germany 6 HZI – Helmholtz Centre for Infection Research, Braunschweig, Germany 7 University of California Davis Genome Center, Davis, California, USA *Corresponding author: Hans-Peter Klenk Keywords: strictly aerobic, none-motile, Gram-variable, thermophilic, chemoheterotrophic, deep-sea, family Incertae Sedis XVII, Clostridiales, GEBA Thermaerobacter marianensis Takai et al. -

Sporulation Evolution and Specialization in Bacillus
bioRxiv preprint doi: https://doi.org/10.1101/473793; this version posted March 11, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. Research article From root to tips: sporulation evolution and specialization in Bacillus subtilis and the intestinal pathogen Clostridioides difficile Paula Ramos-Silva1*, Mónica Serrano2, Adriano O. Henriques2 1Instituto Gulbenkian de Ciência, Oeiras, Portugal 2Instituto de Tecnologia Química e Biológica, Universidade Nova de Lisboa, Oeiras, Portugal *Corresponding author: Present address: Naturalis Biodiversity Center, Marine Biodiversity, Leiden, The Netherlands Phone: 0031 717519283 Email: [email protected] (Paula Ramos-Silva) Running title: Sporulation from root to tips Keywords: sporulation, bacterial genome evolution, horizontal gene transfer, taxon- specific genes, Bacillus subtilis, Clostridioides difficile 1 bioRxiv preprint doi: https://doi.org/10.1101/473793; this version posted March 11, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. Abstract Bacteria of the Firmicutes phylum are able to enter a developmental pathway that culminates with the formation of a highly resistant, dormant spore. Spores allow environmental persistence, dissemination and for pathogens, are infection vehicles. In both the model Bacillus subtilis, an aerobic species, and in the intestinal pathogen Clostridioides difficile, an obligate anaerobe, sporulation mobilizes hundreds of genes. -

Which Organisms Are Used for Anti-Biofouling Studies
Table S1. Semi-systematic review raw data answering: Which organisms are used for anti-biofouling studies? Antifoulant Method Organism(s) Model Bacteria Type of Biofilm Source (Y if mentioned) Detection Method composite membranes E. coli ATCC25922 Y LIVE/DEAD baclight [1] stain S. aureus ATCC255923 composite membranes E. coli ATCC25922 Y colony counting [2] S. aureus RSKK 1009 graphene oxide Saccharomycetes colony counting [3] methyl p-hydroxybenzoate L. monocytogenes [4] potassium sorbate P. putida Y. enterocolitica A. hydrophila composite membranes E. coli Y FESEM [5] (unspecified/unique sample type) S. aureus (unspecified/unique sample type) K. pneumonia ATCC13883 P. aeruginosa BAA-1744 composite membranes E. coli Y SEM [6] (unspecified/unique sample type) S. aureus (unspecified/unique sample type) graphene oxide E. coli ATCC25922 Y colony counting [7] S. aureus ATCC9144 P. aeruginosa ATCCPAO1 composite membranes E. coli Y measuring flux [8] (unspecified/unique sample type) graphene oxide E. coli Y colony counting [9] (unspecified/unique SEM sample type) LIVE/DEAD baclight S. aureus stain (unspecified/unique sample type) modified membrane P. aeruginosa P60 Y DAPI [10] Bacillus sp. G-84 LIVE/DEAD baclight stain bacteriophages E. coli (K12) Y measuring flux [11] ATCC11303-B4 quorum quenching P. aeruginosa KCTC LIVE/DEAD baclight [12] 2513 stain modified membrane E. coli colony counting [13] (unspecified/unique colony counting sample type) measuring flux S. aureus (unspecified/unique sample type) modified membrane E. coli BW26437 Y measuring flux [14] graphene oxide Klebsiella colony counting [15] (unspecified/unique sample type) P. aeruginosa (unspecified/unique sample type) graphene oxide P. aeruginosa measuring flux [16] (unspecified/unique sample type) composite membranes E. -

Food Waste Composting and Microbial Community Structure Profiling
processes Review Food Waste Composting and Microbial Community Structure Profiling Kishneth Palaniveloo 1,* , Muhammad Azri Amran 1, Nur Azeyanti Norhashim 1 , Nuradilla Mohamad-Fauzi 1,2, Fang Peng-Hui 3, Low Hui-Wen 3, Yap Kai-Lin 3, Looi Jiale 3, Melissa Goh Chian-Yee 3, Lai Jing-Yi 3, Baskaran Gunasekaran 3,* and Shariza Abdul Razak 4,* 1 Institute of Ocean and Earth Sciences, Institute for Advanced Studies Building, University of Malaya, Wilayah Persekutuan Kuala Lumpur 50603, Malaysia; [email protected] (M.A.A.); [email protected] (N.A.N.) 2 Institute of Biological Sciences, Faculty of Science, University of Malaya, Wilayah Persekutuan Kuala Lumpur 50603, Malaysia; [email protected] 3 Faculty of Applied Science, UCSI University (South Wing), Cheras, Wilayah Persekutuan Kuala Lumpur 56000, Malaysia; [email protected] (F.P.-H.); [email protected] (L.H.-W.); [email protected] (Y.K.-L.); [email protected] (L.J.); [email protected] (M.G.C.-Y.); [email protected] (L.J.-Y.) 4 Nutrition and Dietetics Program, School of Health Sciences, Health Campus, Universiti Sains Malaysia, Kubang Kerian 16150, Kelantan, Malaysia * Correspondence: [email protected] (K.P.); [email protected] (B.G.); [email protected] (S.A.R.); Tel.: +60-3-7967-4640 (K.P.); +60-16-323-4159 (B.G.); +60-19-964-4043 (S.A.R.) Received: 20 May 2020; Accepted: 16 June 2020; Published: 22 June 2020 Abstract: Over the last decade, food waste has been one of the major issues globally as it brings a negative impact on the environment and health. -

A Metagenomic Window Into the 2-Km-Deep Terrestrial Subsurface Aquifer Revealed Multiple Pathways of Organic Matter Decomposition Vitaly V
FEMS Microbiology Ecology, 94, 2018, fiy152 doi: 10.1093/femsec/fiy152 Advance Access Publication Date: 7 August 2018 Research Article RESEARCH ARTICLE A metagenomic window into the 2-km-deep terrestrial subsurface aquifer revealed multiple pathways of organic matter decomposition Vitaly V. Kadnikov1, Andrey V. Mardanov1, Alexey V. Beletsky1, David Banks3, Nikolay V. Pimenov4, Yulia A. Frank2,OlgaV.Karnachuk2 and Nikolai V. Ravin1,* 1Institute of Bioengineering, Research Center of Biotechnology of the Russian Academy of Sciences, Leninsky prosp. 33-2, Moscow, 119071, Russia, 2Laboratory of Biochemistry and Molecular Biology, Tomsk State University, Lenina prosp. 35, Tomsk, 634050, Russia, 3School of Engineering, Systems Power & Energy, Glasgow University, Glasgow G12 8QQ, and Holymoor Consultancy Ltd., 360 Ashgate Road, Chesterfield, Derbyshire S40 4BW, UK and 4Winogradsky Institute of Microbiology, Research Center of Biotechnology of the Russian Academy of Sciences, Leninsky prosp 33-2, Moscow, 119071, Russia ∗Corresponding author: Institute of Bioengineering, Research Center of Biotechnology of the Russian Academy of Sciences, Leninsky prosp. 33-2, Moscow, 119071, Russia. Tel: +74997833264; Fax: +74991353051; E-mail: [email protected] One sentence summary: metagenome-assembled genomes of microorganisms from the deep subsurface thermal aquifer revealed functional diversity of the community and novel uncultured bacterial lineages Editor: Tillmann Lueders ABSTRACT We have sequenced metagenome of the microbial community of a deep subsurface thermal aquifer in the Tomsk Region of the Western Siberia, Russia. Our goal was the recovery of near-complete genomes of the community members to enable accurate reconstruction of metabolism and ecological roles of the microbial majority, including previously unstudied lineages. The water, obtained via a 2.6 km deep borehole 1-R, was anoxic, with a slightly alkaline pH, and a temperature around 45◦C. -

NOC04013 Application.Pdf(PDF, 453
ER-AN-02N 10/02 Application for approval to import into FORM 2N containment any new organism that is not genetically modified, under Section 40 of the Page 1 Hazardous Substances and New Organisms Act 1996 FORM NO2N Application for approval to IMPORT INTO CONTAINMENT ANY NEW ORGANISM THAT IS NOT GENETICALLY MODIFIED under section 40 of the Hazardous Substances and New Organisms Act 1996 Application Title: Importation of sediment/water samples collected from hydrothermal seamounts outside New Zealand Territorial waters containing Extremophilic microorganisms Applicant Organisation: Institute of Geological & Nuclear Sciences ERMA Office use only Application Code: Formally received:____/____/____ ERMA NZ Contact: Initial Fee Paid: $ Application Status: ER-AN-02N 10/02 Application for approval to import into FORM 2N containment any new organism that is not genetically modified, under Section 40 of the Page 2 Hazardous Substances and New Organisms Act 1996 IMPORTANT 1. An associated User Guide is available for this form. You should read the User Guide before completing this form. If you need further guidance in completing this form please contact ERMA New Zealand. 2. This application form covers importation into containment of any new organism that is not genetically modified, under section 40 of the Act. 3. If you are making an application to import into containment a genetically modified organism you should complete Form NO2G, instead of this form (Form NO2N). 4. This form, together with form NO2G, replaces all previous versions of Form 2. Older versions should not now be used. You should periodically check with ERMA New Zealand or on the ERMA New Zealand web site for new versions of this form. -

Phylogenomic Analysis Supports the Ancestral Presence of LPS-Outer Membranes in the Firmicutes
Phylogenomic analysis supports the ancestral presence of LPS-outer membranes in the Firmicutes. Luisa Cs Antunes, Daniel Poppleton, Andreas Klingl, Alexis Criscuolo, Bruno Dupuy, Céline Brochier-Armanet, Christophe Beloin, Simonetta Gribaldo To cite this version: Luisa Cs Antunes, Daniel Poppleton, Andreas Klingl, Alexis Criscuolo, Bruno Dupuy, et al.. Phy- logenomic analysis supports the ancestral presence of LPS-outer membranes in the Firmicutes.. eLife, eLife Sciences Publication, 2016, 5, pp.e14589. 10.7554/eLife.14589.020. pasteur-01362343 HAL Id: pasteur-01362343 https://hal-pasteur.archives-ouvertes.fr/pasteur-01362343 Submitted on 8 Sep 2016 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License RESEARCH ARTICLE Phylogenomic analysis supports the ancestral presence of LPS-outer membranes in the Firmicutes Luisa CS Antunes1†, Daniel Poppleton1†, Andreas Klingl2, Alexis Criscuolo3, Bruno Dupuy4, Ce´ line Brochier-Armanet5, Christophe Beloin6, Simonetta Gribaldo1* 1Unite´ de -

Distribution of Long Linear and Branched Polyamines in the Thermophiles Belonging to the Domain Bacteria
Journal of Japanese Society for Extremophiles (2008) Vol.7 (1) Journal of Japanese Society for Extremophiles (2008), Vol. 7, 10-20 ORIGINAL PAPER Hamana Ka,b,e, Hosoya Ra, Yokota Ac, Niitsu Md, Hayashi He and Itoh Tb Distribution of long linear and branched polyamines in the thermophiles belonging to the domain Bacteria a Gunma University School of Health Sciences, Maebashi, Gunma 371-8514, Japan. bJapan Collection of Microorganisms, RIKEN, BioResource Center, Wako, Saitama 351-0198, Japan. c Institute of Molecular and Cellular Biosciences, The University of Tokyo, Tokyo 113-0032, Japan. d Faculty of Pharmaceutical Sciences, Josai University, Sakado, Saitama 350-0290, Japan. e Faculty of Engineering, Maebashi Institute of Technology, Maebashi, Gunma 371-0816, Japan. Corresponding author : Koei Hamana, [email protected] Phone : +81-27-220-8916, FAX : +81-27-220-8999 Received: April 3, 2008/ Reviced:May 26, 2008/ Acepted:June 3, 2008 Abstract Cellular polyamines of 44 newly validated have been published in eubacteria 15, 16). However, the eubacterial thermophiles growing at 45-80℃, belonging degree of thermophily is roughly estimated and not to eight orders (six phyla) of the domain Bacteria, were defined exactly. The cellular occurrence of long linear analyzed by HPLC and GC. A quaternary branched and/or branched polyamines in extremely thermophilic penta-amine, N4-bis(aminopropyl)norspermidine, was (or hyperthermophilic) eubacteria suggested that the found in Hydrogenivirga and Sulfurihydrogenibium extreme thermophiles (or hyperthermophiles) may have belonging to the order of Aquificales. Another some novel polyamine synthetic abilities possibly quaternary branched penta-amine, N4-bis(aminopropyl) associated with their thermophily 8-11, 13-15, 18, 23, 24). -

Microbial and Mineralogical Characterizations of Soils Collected from the Deep Biosphere of the Former Homestake Gold Mine, South Dakota
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln US Department of Energy Publications U.S. Department of Energy 2010 Microbial and Mineralogical Characterizations of Soils Collected from the Deep Biosphere of the Former Homestake Gold Mine, South Dakota Gurdeep Rastogi South Dakota School of Mines and Technology Shariff Osman Lawrence Berkeley National Laboratory Ravi K. Kukkadapu Pacific Northwest National Laboratory, [email protected] Mark Engelhard Pacific Northwest National Laboratory Parag A. Vaishampayan California Institute of Technology See next page for additional authors Follow this and additional works at: https://digitalcommons.unl.edu/usdoepub Part of the Bioresource and Agricultural Engineering Commons Rastogi, Gurdeep; Osman, Shariff; Kukkadapu, Ravi K.; Engelhard, Mark; Vaishampayan, Parag A.; Andersen, Gary L.; and Sani, Rajesh K., "Microbial and Mineralogical Characterizations of Soils Collected from the Deep Biosphere of the Former Homestake Gold Mine, South Dakota" (2010). US Department of Energy Publications. 170. https://digitalcommons.unl.edu/usdoepub/170 This Article is brought to you for free and open access by the U.S. Department of Energy at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in US Department of Energy Publications by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Authors Gurdeep Rastogi, Shariff Osman, Ravi K. Kukkadapu, Mark Engelhard, Parag A. Vaishampayan, Gary L. Andersen, and Rajesh K. Sani This article is available at DigitalCommons@University of Nebraska - Lincoln: https://digitalcommons.unl.edu/ usdoepub/170 Microb Ecol (2010) 60:539–550 DOI 10.1007/s00248-010-9657-y SOIL MICROBIOLOGY Microbial and Mineralogical Characterizations of Soils Collected from the Deep Biosphere of the Former Homestake Gold Mine, South Dakota Gurdeep Rastogi & Shariff Osman & Ravi Kukkadapu & Mark Engelhard & Parag A.