The Structure, Function and Evolution of the Extracellular Matrix: a Systems-Level Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cytogenomic SNP Microarray - Fetal ARUP Test Code 2002366 Maternal Contamination Study Fetal Spec Fetal Cells
Patient Report |FINAL Client: Example Client ABC123 Patient: Patient, Example 123 Test Drive Salt Lake City, UT 84108 DOB 2/13/1987 UNITED STATES Gender: Female Patient Identifiers: 01234567890ABCD, 012345 Physician: Doctor, Example Visit Number (FIN): 01234567890ABCD Collection Date: 00/00/0000 00:00 Cytogenomic SNP Microarray - Fetal ARUP test code 2002366 Maternal Contamination Study Fetal Spec Fetal Cells Single fetal genotype present; no maternal cells present. Fetal and maternal samples were tested using STR markers to rule out maternal cell contamination. This result has been reviewed and approved by Maternal Specimen Yes Cytogenomic SNP Microarray - Fetal Abnormal * (Ref Interval: Normal) Test Performed: Cytogenomic SNP Microarray- Fetal (ARRAY FE) Specimen Type: Direct (uncultured) villi Indication for Testing: Patient with 46,XX,t(4;13)(p16.3;q12) (Quest: EN935475D) ----------------------------------------------------------------- ----- RESULT SUMMARY Abnormal Microarray Result (Male) Unbalanced Translocation Involving Chromosomes 4 and 13 Classification: Pathogenic 4p Terminal Deletion (Wolf-Hirschhorn syndrome) Copy number change: 4p16.3p16.2 loss Size: 5.1 Mb 13q Proximal Region Deletion Copy number change: 13q11q12.12 loss Size: 6.1 Mb ----------------------------------------------------------------- ----- RESULT DESCRIPTION This analysis showed a terminal deletion (1 copy present) involving chromosome 4 within 4p16.3p16.2 and a proximal interstitial deletion (1 copy present) involving chromosome 13 within 13q11q12.12. This -

Variation in FCN1 Affects Biosynthesis of Ficolin-1 and Is Associated With
Genes and Immunity (2012) 13, 515–522 & 2012 Macmillan Publishers Limited All rights reserved 1466-4879/12 www.nature.com/gene ORIGINAL ARTICLE Variation in FCN1 affects biosynthesis of ficolin-1 and is associated with outcome of systemic inflammation L Munthe-Fog1, T Hummelshoj1, C Honore´ 1, ME Moller1, MO Skjoedt1, I Palsgaard1, N Borregaard2, HO Madsen1 and P Garred1 Ficolin-1 is a recognition molecule of the lectin complement pathway. The ficolin-1 gene FCN1 is polymorphic, but the functional and clinical consequences are unknown.The concentration of ficolin-1 in plasma and FCN1 polymorphisms in positions À 1981 (rs2989727), À 791 (rs28909068), À 542 (rs10120023), À 271 (rs28909976), À 144 (rs10117466) and þ 7918 (rs1071583) were determined in 100 healthy individuals. FCN1 expression by isolated monocytes and granulocytes and ficolin-1 levels in monocyte culture supernatants were assessed in 21 FCN1-genotyped individuals. FCN1 polymorphisms were determined in a cohort of 251 patients with systemic inflammation. High ficolin-1 plasma levels were significantly associated with the minor alleles in position À 542 and À 144. These alleles were also significantly associated with high FCN1 mRNA expression. The level of ficolin-1 in culture supernatants was significantly higher in individuals homozygous for the minor alleles at positions À 542 and À 144. Homozygosity for these alleles was significantly associated with fatal outcome in patients with systemic inflammation. None of the other investigated polymorphisms were associated with FCN1 and ficolin-1 expression, concentration or disease outcome. Functional polymorphic sites in the promoter region of FCN1 regulate both the expression and synthesis of ficolin-1 and are associated with outcome in severe inflammation. -

Downregulation of the Clotting Cascade by the Protein C
Downregulation of the clotting cascade by the protein C F. Stavenuiter, E.A.M. Bouwens, L.O. Mosnier I Simposio Conjunto EHA - SAH Department of Molecular and Experimental Medicine, The Scripps Research Institute, La Jolla, CA, USA HEMATOLOGÍA, Vol.17 Número Extraordinario XXI CONGRESO E-mail: [email protected] Octubre 2013 Abstract APC mutants, which provide unique insights into The protein C pathway provides important biologi- the relative contributions of APC’s anticoagulant or cal activities to maintain the fluidity of the circula- cytoprotective activities to the beneficial effects of tion, prevent thrombosis, and protect the integrity APC in various murine injury and disease models. of the vasculature in response to injury. Activated Because of its multiple physiological and pharmaco- protein C (APC), in concert with its co-factors and logical activities, the anticoagulant and cytoprotec- cell receptors, assembles in specific macromolecular tive protein C pathway have important implications complexes to provide efficient proteolysis of multiple for the (patho)physiology of vascular disease and substrates that result in anticoagulant and cytopro- for translational research exploring novel therapeu- tective activities. Numerous studies on APC’s struc- tic strategies to combat complex medical disorders ture-function relation with its co-factors, cell recep- such as thrombosis, inflammation, ischemic stroke tors, and substrates provide valuable insights into the and neurodegenerative disease. molecular mechanisms and presumed assembly of Learning goals the macromolecular complexes that are responsible At the conclusion of this activity, participants should for APC’s activities. These insights allow for molecu- know that: lar engineering approaches specifically targeting the - the protein C pathway provides multiple im- interaction of APC with one of its substrates or co- portant functions to maintain a regulated bal- factors. -

Tooth Enamel and Its Dynamic Protein Matrix
International Journal of Molecular Sciences Review Tooth Enamel and Its Dynamic Protein Matrix Ana Gil-Bona 1,2,* and Felicitas B. Bidlack 1,2,* 1 The Forsyth Institute, Cambridge, MA 02142, USA 2 Department of Developmental Biology, Harvard School of Dental Medicine, Boston, MA 02115, USA * Correspondence: [email protected] (A.G.-B.); [email protected] (F.B.B.) Received: 26 May 2020; Accepted: 20 June 2020; Published: 23 June 2020 Abstract: Tooth enamel is the outer covering of tooth crowns, the hardest material in the mammalian body, yet fracture resistant. The extremely high content of 95 wt% calcium phosphate in healthy adult teeth is achieved through mineralization of a proteinaceous matrix that changes in abundance and composition. Enamel-specific proteins and proteases are known to be critical for proper enamel formation. Recent proteomics analyses revealed many other proteins with their roles in enamel formation yet to be unraveled. Although the exact protein composition of healthy tooth enamel is still unknown, it is apparent that compromised enamel deviates in amount and composition of its organic material. Why these differences affect both the mineralization process before tooth eruption and the properties of erupted teeth will become apparent as proteomics protocols are adjusted to the variability between species, tooth size, sample size and ephemeral organic content of forming teeth. This review summarizes the current knowledge and published proteomics data of healthy and diseased tooth enamel, including advancements in forensic applications and disease models in animals. A summary and discussion of the status quo highlights how recent proteomics findings advance our understating of the complexity and temporal changes of extracellular matrix composition during tooth enamel formation. -

Searching for Novel Peptide Hormones in the Human Genome Olivier Mirabeau
Searching for novel peptide hormones in the human genome Olivier Mirabeau To cite this version: Olivier Mirabeau. Searching for novel peptide hormones in the human genome. Life Sciences [q-bio]. Université Montpellier II - Sciences et Techniques du Languedoc, 2008. English. tel-00340710 HAL Id: tel-00340710 https://tel.archives-ouvertes.fr/tel-00340710 Submitted on 21 Nov 2008 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. UNIVERSITE MONTPELLIER II SCIENCES ET TECHNIQUES DU LANGUEDOC THESE pour obtenir le grade de DOCTEUR DE L'UNIVERSITE MONTPELLIER II Discipline : Biologie Informatique Ecole Doctorale : Sciences chimiques et biologiques pour la santé Formation doctorale : Biologie-Santé Recherche de nouvelles hormones peptidiques codées par le génome humain par Olivier Mirabeau présentée et soutenue publiquement le 30 janvier 2008 JURY M. Hubert Vaudry Rapporteur M. Jean-Philippe Vert Rapporteur Mme Nadia Rosenthal Examinatrice M. Jean Martinez Président M. Olivier Gascuel Directeur M. Cornelius Gross Examinateur Résumé Résumé Cette thèse porte sur la découverte de gènes humains non caractérisés codant pour des précurseurs à hormones peptidiques. Les hormones peptidiques (PH) ont un rôle important dans la plupart des processus physiologiques du corps humain. -

Oncogenomics of C-Myc Transgenic Mice Reveal Novel Regulators of Extracellular Signaling, Angiogenesis and Invasion with Clinica
www.impactjournals.com/oncotarget/ Oncotarget, 2017, Vol. 8, (No. 60), pp: 101808-101831 Research Paper Oncogenomics of c-Myc transgenic mice reveal novel regulators of extracellular signaling, angiogenesis and invasion with clinical significance for human lung adenocarcinoma Yari Ciribilli1,2 and Jürgen Borlak2 1Centre for Integrative Biology (CIBIO), University of Trento, 38123 Povo (TN), Italy 2Centre for Pharmacology and Toxicology, Hannover Medical School, 30625 Hannover, Germany Correspondence to: Jürgen Borlak, email: [email protected] Keywords: c-Myc transgenic mouse model of lung cancer, papillary adenocarcinomas, whole genome scans, c-Myc regulatory gene networks, c-Myc targeted regulators of extracellular signaling Received: June 26, 2017 Accepted: September 21, 2017 Published: October 23, 2017 Copyright: Ciribilli et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License 3.0 (CC BY 3.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. ABSTRACT The c-Myc transcription factor is frequently deregulated in cancers. To search for disease diagnostic and druggable targets a transgenic lung cancer disease model was investigated. Oncogenomics identified c-Myc target genes in lung tumors. These were validated by RT-PCR, Western Blotting, EMSA assays and ChIP-seq data retrieved from public sources. Gene reporter and ChIP assays verified functional importance of c-Myc binding sites. The clinical significance was established by RT-qPCR in tumor and matched healthy control tissues, by RNA-seq data retrieved from the TCGA Consortium and by immunohistochemistry recovered from the Human Protein Atlas repository. In transgenic lung tumors 25 novel candidate genes were identified. -

The EMILIN/Multimerin Family
View metadata, citation and similar papers at core.ac.uk brought to you by CORE REVIEW ARTICLE published: 06 Januaryprovided 2012 by Frontiers - Publisher Connector doi: 10.3389/fimmu.2011.00093 The EMILIN/multimerin family Alfonso Colombatti 1,2,3*, Paola Spessotto1, Roberto Doliana1, Maurizio Mongiat 1, Giorgio Maria Bressan4 and Gennaro Esposito2,3 1 Experimental Oncology 2, Centro di Riferimento Oncologico, Istituto di Ricerca e Cura a Carattere Scientifico, Aviano, Italy 2 Department of Biomedical Science and Technology, University of Udine, Udine, Italy 3 Microgravity, Ageing, Training, Immobility Excellence Center, University of Udine, Udine, Italy 4 Department of Histology Microbiology and Medical Biotechnologies, University of Padova, Padova, Italy Edited by: Elastin microfibrillar interface proteins (EMILINs) and Multimerins (EMILIN1, EMILIN2, Uday Kishore, Brunel University, UK Multimerin1, and Multimerin2) constitute a four member family that in addition to the Reviewed by: shared C-terminus gC1q domain typical of the gC1q/TNF superfamily members contain a Uday Kishore, Brunel University, UK Kenneth Reid, Green Templeton N-terminus unique cysteine-rich EMI domain. These glycoproteins are homotrimeric and College University of Oxford, UK assemble into high molecular weight multimers. They are predominantly expressed in *Correspondence: the extracellular matrix and contribute to several cellular functions in part associated with Alfonso Colombatti, Division of the gC1q domain and in part not yet assigned nor linked to other specific regions of the Experimental Oncology 2, Centro di sequence. Among the latter is the control of arterial blood pressure, the inhibition of Bacil- Riferimento Oncologico, Istituto di Ricerca e Cura a Carattere Scientifico, lus anthracis cell cytotoxicity, the promotion of cell death, the proangiogenic function, and 33081 Aviano, Italy. -
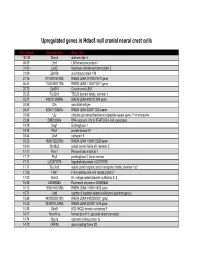
Supp Table 1.Pdf
Upregulated genes in Hdac8 null cranial neural crest cells fold change Gene Symbol Gene Title 134.39 Stmn4 stathmin-like 4 46.05 Lhx1 LIM homeobox protein 1 31.45 Lect2 leukocyte cell-derived chemotaxin 2 31.09 Zfp108 zinc finger protein 108 27.74 0710007G10Rik RIKEN cDNA 0710007G10 gene 26.31 1700019O17Rik RIKEN cDNA 1700019O17 gene 25.72 Cyb561 Cytochrome b-561 25.35 Tsc22d1 TSC22 domain family, member 1 25.27 4921513I08Rik RIKEN cDNA 4921513I08 gene 24.58 Ofa oncofetal antigen 24.47 B230112I24Rik RIKEN cDNA B230112I24 gene 23.86 Uty ubiquitously transcribed tetratricopeptide repeat gene, Y chromosome 22.84 D8Ertd268e DNA segment, Chr 8, ERATO Doi 268, expressed 19.78 Dag1 Dystroglycan 1 19.74 Pkn1 protein kinase N1 18.64 Cts8 cathepsin 8 18.23 1500012D20Rik RIKEN cDNA 1500012D20 gene 18.09 Slc43a2 solute carrier family 43, member 2 17.17 Pcm1 Pericentriolar material 1 17.17 Prg2 proteoglycan 2, bone marrow 17.11 LOC671579 hypothetical protein LOC671579 17.11 Slco1a5 solute carrier organic anion transporter family, member 1a5 17.02 Fbxl7 F-box and leucine-rich repeat protein 7 17.02 Kcns2 K+ voltage-gated channel, subfamily S, 2 16.93 AW493845 Expressed sequence AW493845 16.12 1600014K23Rik RIKEN cDNA 1600014K23 gene 15.71 Cst8 cystatin 8 (cystatin-related epididymal spermatogenic) 15.68 4922502D21Rik RIKEN cDNA 4922502D21 gene 15.32 2810011L19Rik RIKEN cDNA 2810011L19 gene 15.08 Btbd9 BTB (POZ) domain containing 9 14.77 Hoxa11os homeo box A11, opposite strand transcript 14.74 Obp1a odorant binding protein Ia 14.72 ORF28 open reading -

The Genetic Basis of Hyaline Fibromatosis Syndrome in Patients from a Consanguineous Background: a Case Series
Youssefian et al. BMC Medical Genetics (2018) 19:87 https://doi.org/10.1186/s12881-018-0581-1 CASE REPORT Open Access The genetic basis of hyaline fibromatosis syndrome in patients from a consanguineous background: a case series Leila Youssefian1,4†, Hassan Vahidnezhad1,2†, Andrew Touati1,3†, Vahid Ziaee5†, Amir Hossein Saeidian1, Sara Pajouhanfar1, Sirous Zeinali2,6 and Jouni Uitto1* Abstract Background: Hyaline fibromatosis syndrome (HFS) is a rare heritable multi-systemic disorder with significant dermatologic manifestations. It is caused by mutations in ANTXR2, which encodes a transmembrane receptor involved in collagen VI regulation in the extracellular matrix. Over 40 mutations in the ANTXR2 gene have been associated with cases of HFS. Variable severity of the disorder in different patients has been proposed to be related to the specific mutations in these patients and their location within the gene. Case presentation: In this report, we describe four cases of HFS from consanguineous backgrounds. Genetic analysis identified a novel homozygous frameshift deletion c.969del (p.Ile323Metfs*14) in one case, the previously reported mutation c.134 T > C (p.Leu45Pro) in another case, and the recurrent homozygous frameshift mutation c.1073dup (p.Ala359Cysfs*13) in two cases. The epidemiology of this latter mutation is of particular interest, as it is a candidate for inhibition of nonsense-mediated mRNA decay. Haplotype analysis was performed to determine the origin of this mutation in this consanguineous cohort, which suggested that it may develop sporadically in different populations. Conclusions: This information provides insights on genotype-phenotype correlations, identifies a previously unreported mutation in ANTXR2, and improves the understanding of a recurrent mutation in HFS. -

Anti-HABP2 Monoclonal Antibody, Clone FQS25662 (DCABH-7346) This Product Is for Research Use Only and Is Not Intended for Diagnostic Use
Anti-HABP2 monoclonal antibody, clone FQS25662 (DCABH-7346) This product is for research use only and is not intended for diagnostic use. PRODUCT INFORMATION Product Overview Rabbit monoclonal to HABP2 Antigen Description Cleaves the alpha-chain at multiple sites and the beta-chain between Lys-53 and Lys-54 but not the gamma-chain of fibrinogen and therefore does not initiate the formation of the fibrin clot and does not cause the fibrinolysis directly. It does not cleave (activate) prothrombin and plasminogen but converts the inactive single chain urinary plasminogen activator (pro-urokinase) to the active two chain form. Activates coagulation factor VII. Immunogen Synthetic peptide (the amino acid sequence is considered to be commercially sensitive) within Human HABP2 aa 350-450. The exact sequence is proprietary.Database link: Q14520 Isotype IgG Source/Host Rabbit Species Reactivity Mouse, Rat, Human Clone FQS25662 Purity Tissue culture supernatant Conjugate Unconjugated Applications WB, IHC-P, ICC/IF Positive Control Human fetal liver, HepG2, MCF-7 and A549 lysate. Rat liver tissue. HepG2 cells. Format Liquid Size 100 μl Buffer Preservative: 0.01% Sodium azide; Constituents: 40% Glycerol, 59% PBS, 0.05% BSA Preservative 0.01% Sodium Azide Storage Store at +4°C short term (1-2 weeks). Upon delivery aliquot. Store at -20°C long term. Avoid freeze / thaw cycle. Ship Shipped at 4°C. 45-1 Ramsey Road, Shirley, NY 11967, USA Email: [email protected] Tel: 1-631-624-4882 Fax: 1-631-938-8221 1 © Creative Diagnostics All Rights Reserved -

140503 IPF Signatures Supplement Withfigs Thorax
Supplementary material for Heterogeneous gene expression signatures correspond to distinct lung pathologies and biomarkers of disease severity in idiopathic pulmonary fibrosis Daryle J. DePianto1*, Sanjay Chandriani1⌘*, Alexander R. Abbas1, Guiquan Jia1, Elsa N. N’Diaye1, Patrick Caplazi1, Steven E. Kauder1, Sabyasachi Biswas1, Satyajit K. Karnik1#, Connie Ha1, Zora Modrusan1, Michael A. Matthay2, Jasleen Kukreja3, Harold R. Collard2, Jackson G. Egen1, Paul J. Wolters2§, and Joseph R. Arron1§ 1Genentech Research and Early Development, South San Francisco, CA 2Department of Medicine, University of California, San Francisco, CA 3Department of Surgery, University of California, San Francisco, CA ⌘Current address: Novartis Institutes for Biomedical Research, Emeryville, CA. #Current address: Gilead Sciences, Foster City, CA. *DJD and SC contributed equally to this manuscript §PJW and JRA co-directed this project Address correspondence to Paul J. Wolters, MD University of California, San Francisco Department of Medicine Box 0111 San Francisco, CA 94143-0111 [email protected] or Joseph R. Arron, MD, PhD Genentech, Inc. MS 231C 1 DNA Way South San Francisco, CA 94080 [email protected] 1 METHODS Human lung tissue samples Tissues were obtained at UCSF from clinical samples from IPF patients at the time of biopsy or lung transplantation. All patients were seen at UCSF and the diagnosis of IPF was established through multidisciplinary review of clinical, radiological, and pathological data according to criteria established by the consensus classification of the American Thoracic Society (ATS) and European Respiratory Society (ERS), Japanese Respiratory Society (JRS), and the Latin American Thoracic Association (ALAT) (ref. 5 in main text). Non-diseased normal lung tissues were procured from lungs not used by the Northern California Transplant Donor Network. -

Field Studies Reveal a Close Relative of C. Elegans Thrives in the Fresh Figs
Woodruf and Phillips BMC Ecol (2018) 18:26 https://doi.org/10.1186/s12898-018-0182-z BMC Ecology RESEARCH ARTICLE Open Access Field studies reveal a close relative of C. elegans thrives in the fresh fgs of Ficus septica and disperses on its Ceratosolen pollinating wasps Gavin C. Woodruf1,2* and Patrick C. Phillips2 Abstract Background: Biotic interactions are ubiquitous and require information from ecology, evolutionary biology, and functional genetics in order to be understood. However, study systems that are amenable to investigations across such disparate felds are rare. Figs and fg wasps are a classic system for ecology and evolutionary biology with poor functional genetics; Caenorhabditis elegans is a classic system for functional genetics with poor ecology. In order to help bridge these disciplines, here we describe the natural history of a close relative of C. elegans, Caenorhabditis inopi- nata, that is associated with the fg Ficus septica and its pollinating Ceratosolen wasps. Results: To understand the natural context of fg-associated Caenorhabditis, fresh F. septica fgs from four Okinawan islands were sampled, dissected, and observed under microscopy. C. inopinata was found in all islands where F. septica fgs were found. C.i nopinata was routinely found in the fg interior and almost never observed on the outside surface. C. inopinata was only found in pollinated fgs, and C. inopinata was more likely to be observed in fgs with more foun- dress pollinating wasps. Actively reproducing C. inopinata dominated early phase fgs, whereas late phase fgs with emerging wasp progeny harbored C. inopinata dauer larvae. Additionally, C. inopinata was observed dismounting from Ceratosolen pollinating wasps that were placed on agar plates.