An Enterprise Knowledge Network
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Enterprise Integration Patterns N About Apache Camel N Essential Patterns Enterprise Integration Patterns N Conclusions and More
Brought to you by... #47 CONTENTS INCLUDE: n About Enterprise Integration Patterns n About Apache Camel n Essential Patterns Enterprise Integration Patterns n Conclusions and more... with Apache Camel Visit refcardz.com By Claus Ibsen ABOUT ENTERPRISE INTEGRATION PaTTERNS Problem A single event often triggers a sequence of processing steps Solution Use Pipes and Filters to divide a larger processing steps (filters) that are connected by channels (pipes) Integration is a hard problem. To help deal with the complexity Camel Camel supports Pipes and Filters using the pipeline node. of integration problems the Enterprise Integration Patterns Java DSL from(“jms:queue:order:in”).pipeline(“direct:transformOrd (EIP) have become the standard way to describe, document er”, “direct:validateOrder”, “jms:queue:order:process”); and implement complex integration problems. Hohpe & Where jms represents the JMS component used for consuming JMS messages Woolf’s book the Enterprise Integration Patterns has become on the JMS broker. Direct is used for combining endpoints in a synchronous fashion, allow you to divide routes into sub routes and/or reuse common routes. the bible in the integration space – essential reading for any Tip: Pipeline is the default mode of operation when you specify multiple integration professional. outputs, so it can be omitted and replaced with the more common node: from(“jms:queue:order:in”).to(“direct:transformOrder”, “direct:validateOrder”, “jms:queue:order:process”); Apache Camel is an open source project for implementing TIP: You can also separate each step as individual to nodes: the EIP easily in a few lines of Java code or Spring XML from(“jms:queue:order:in”) configuration. -

Apache Camel
Apache Camel USER GUIDE Version 2.0.0 Copyright 2007-2009, Apache Software Foundation 1 Table of Contents Table of Contents......................................................................... ii Chapter 1 Introduction ...................................................................................1 Chapter 2 Quickstart.......................................................................................1 Chapter 3 Getting Started..............................................................................7 Chapter 4 Architecture................................................................................ 17 Chapter 5 Enterprise Integration Patterns.............................................. 27 Chapter 6 Cook Book ................................................................................... 32 Chapter 7 Tutorials....................................................................................... 85 Chapter 8 Language Appendix.................................................................. 190 Chapter 9 Pattern Appendix..................................................................... 231 Chapter 10 Component Appendix ............................................................. 299 Index ................................................................................................0 ii APACHE CAMEL CHAPTER 1 °°°° Introduction Apache Camel is a powerful open source integration framework based on known Enterprise Integration Patterns with powerful Bean Integration. Camel lets you create the Enterprise Integration -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Graft: a Debugging Tool for Apache Giraph
Graft: A Debugging Tool For Apache Giraph Semih Salihoglu, Jaeho Shin, Vikesh Khanna, Ba Quan Truong, Jennifer Widom Stanford University {semih, jaeho.shin, vikesh, bqtruong, widom}@cs.stanford.edu ABSTRACT optional master.compute() function is executed by the Master We address the problem of debugging programs written for Pregel- task between supersteps. like systems. After interviewing Giraph and GPS users, we devel- We have tackled the challenge of debugging programs written oped Graft. Graft supports the debugging cycle that users typically for Pregel-like systems. Despite being a core component of pro- go through: (1) Users describe programmatically the set of vertices grammers’ development cycles, very little work has been done on they are interested in inspecting. During execution, Graft captures debugging in these systems. We interviewed several Giraph and the context information of these vertices across supersteps. (2) Us- GPS programmers (hereafter referred to as “users”) and studied vertex.compute() ing Graft’s GUI, users visualize how the values and messages of the how they currently debug their functions. captured vertices change from superstep to superstep,narrowing in We found that the following three steps were common across users: suspicious vertices and supersteps. (3) Users replay the exact lines (1) Users add print statements to their code to capture information of the vertex.compute() function that executed for the sus- about a select set of potentially “buggy” vertices, e.g., vertices that picious vertices and supersteps, by copying code that Graft gener- are assigned incorrect values, send incorrect messages, or throw ates into their development environments’ line-by-line debuggers. -

Realization of EAI Patterns with Apache Camel
Institut für Architektur von Anwendungssystemen Universität Stuttgart Universitätsstraße 38 70569 Stuttgart Studienarbeit Nr. 2127 Realization of EAI Patterns with Apache Camel Pascal Kolb Studiengang: Informatik Prüfer: Prof. Dr. Frank Leymann Betreuer: Dipl.‐Inf. Thorsten Scheibler begonnen am: 26.10.2007 beendet am: 26.04.2008 CR‐Klassifikation D.2.11, D.3, H.4.1 Table of Contents Table of Listings ............................................................................................................. vii 1 Introduction ............................................................................................................. 1 1.1 Task Description ................................................................................................................................. 1 1.2 Structure of this thesis ....................................................................................................................... 2 2 Apache Camel Fundamentals ................................................................................... 3 2.1 Introduction into Apache Camel ........................................................................................................ 3 2.2 Apache Camel’s Architecture ............................................................................................................. 4 2.2.1 Camel Components and Endpoints............................................................................................ 4 2.2.2 Camel Exchange and Message .................................................................................................. -

Apache Giraph 3
Other Distributed Frameworks Shannon Quinn Distinction 1. General Compute Engines – Hadoop 2. User-facing APIs – Cascading – Scalding Alternative Frameworks 1. Apache Mahout 2. Apache Giraph 3. GraphLab 4. Apache Storm 5. Apache Tez 6. Apache Flink Alternative Frameworks 1. Apache Mahout 2. Apache Giraph 3. GraphLab 4. Apache Storm 5. Apache Tez 6. Apache Flink Apache Mahout • A Tale of Two Frameworks 1. Distributed machine learning on Hadoop – 0.1 to 0.9 2. “Samsara” – New in 0.10+ Machine learning on Hadoop • Born out of the Apache Lucene project • Built on Hadoop (all in Java) • Pragmatic machine learning at scale 1: Recommendation 2: Classification 3: Clustering Other MapReduce algorithms • Dimensionality reduction – Lanczos – SSVD – LDA • Regression – Logistic – Linear – Random Forest • Evolutionary algorithms Mahout-Samsara • Programming “environment” for distributed machine learning • R-like syntax • Interactive shell (like Spark) • Under-the-hood algebraic optimizer • Engine-agnostic – Spark – H2O – Flink – ? Mahout-Samsara Mahout • 3 main components Engine-agnostic environment for Engine-specific Legacy MapReduce building scalable ML algorithms (Spark, algorithms algorithms H2O) (Samsara) Mahout • v0.10.0 released April 11 (as in, 5 days ago!) • 0.10.1 – More base linear algebra functionality • 0.11.0 – Compatible with Spark 1.3 • 1.0 – ? Mahout features by engine Mahout features by engine Mahout features by engine • No engine-agnostic clustering algorithms yet – Still the domain of legacy MapReduce • H2O and especially Flink -

Chapter 2 Introduction to Big Data Technology
Chapter 2 Introduction to Big data Technology Bilal Abu-Salih1, Pornpit Wongthongtham2 Dengya Zhu3 , Kit Yan Chan3 , Amit Rudra3 1The University of Jordan 2 The University of Western Australia 3 Curtin University Abstract: Big data is no more “all just hype” but widely applied in nearly all aspects of our business, governments, and organizations with the technology stack of AI. Its influences are far beyond a simple technique innovation but involves all rears in the world. This chapter will first have historical review of big data; followed by discussion of characteristics of big data, i.e. from the 3V’s to up 10V’s of big data. The chapter then introduces technology stacks for an organization to build a big data application, from infrastructure/platform/ecosystem to constructional units and components. Finally, we provide some big data online resources for reference. Keywords Big data, 3V of Big data, Cloud Computing, Data Lake, Enterprise Data Centre, PaaS, IaaS, SaaS, Hadoop, Spark, HBase, Information retrieval, Solr 2.1 Introduction The ability to exploit the ever-growing amounts of business-related data will al- low to comprehend what is emerging in the world. In this context, Big Data is one of the current major buzzwords [1]. Big Data (BD) is the technical term used in reference to the vast quantity of heterogeneous datasets which are created and spread rapidly, and for which the conventional techniques used to process, analyse, retrieve, store and visualise such massive sets of data are now unsuitable and inad- equate. This can be seen in many areas such as sensor-generated data, social media, uploading and downloading of digital media. -

Study Materials for Big Data Processing Tools
MASARYK UNIVERSITY FACULTY OF INFORMATICS Study materials for Big Data processing tools BACHELOR'S THESIS Martin Durkac Brno, Spring 2021 MASARYK UNIVERSITY FACULTY OF INFORMATICS Study materials for Big Data processing tools BACHELOR'S THESIS Martin Durkáč Brno, Spring 2021 This is where a copy of the official signed thesis assignment and a copy of the Statement of an Author is located in the printed version of the document. Declaration Hereby I declare that this paper is my original authorial work, which I have worked out on my own. All sources, references, and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Martin Durkäc Advisor: RNDr. Martin Macák i Acknowledgements I would like to thank my supervisor RNDr. Martin Macak for all the support and guidance. His constant feedback helped me to improve and finish it. I would also like to express my gratitude towards my colleagues at Greycortex for letting me use their resources to develop the practical part of the thesis. ii Abstract This thesis focuses on providing study materials for the Big Data sem• inar. The thesis is divided into six chapters plus a conclusion, where the first chapter introduces Big Data in general, four chapters contain information about Big Data processing tools and the sixth chapter describes study materials provided in this thesis. For each Big Data processing tool, the thesis contains a practical demonstration and an assignment for the seminar in the attachments. All the assignments are provided in both with and without solution forms. -

UIMA Asynchronous Scaleout Written and Maintained by the Apache UIMA™ Development Community
UIMA Asynchronous Scaleout Written and maintained by the Apache UIMA™ Development Community Version 2.10.3 Copyright © 2006, 2018 The Apache Software Foundation License and Disclaimer. The ASF licenses this documentation to you under the Apache License, Version 2.0 (the "License"); you may not use this documentation except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, this documentation and its contents are distributed under the License on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. Trademarks. All terms mentioned in the text that are known to be trademarks or service marks have been appropriately capitalized. Use of such terms in this book should not be regarded as affecting the validity of the the trademark or service mark. Publication date March, 2018 Table of Contents 1. Overview - Asynchronous Scaleout ................................................................................. 1 1.1. Terminology ....................................................................................................... 1 1.2. AS versus CPM .................................................................................................. 2 1.3. Design goals for Asynchronous Scaleout ............................................................... 3 1.4. AS Concepts ..................................................................................................... -

Harp: Collective Communication on Hadoop
HHarp:arp: CollectiveCollective CommunicationCommunication onon HadooHadoopp Judy Qiu, Indiana University SA OutlineOutline • Machine Learning on Big Data • Big Data Tools • Iterative MapReduce model • MDS Demo • Harp SA MachineMachine LearningLearning onon BigBig DataData • Mahout on Hadoop • https://mahout.apache.org/ • MLlib on Spark • http://spark.apache.org/mllib/ • GraphLab Toolkits • http://graphlab.org/projects/toolkits.html • GraphLab Computer Vision Toolkit SA World Data DAG Model MapReduce Model Graph Model BSP/Collective Mode Hadoop MPI HaLoop Giraph Twister Hama or GraphLab ions/ ions/ Spark GraphX ning Harp Stratosphere Dryad/ Reef DryadLIN Q Pig/PigLatin Hive Query Tez Drill Shark MRQL S4 Storm or ming Samza Spark Streaming BigBig DataData ToolsTools forfor HPCHPC andand SupercomputingSupercomputing • MPI(Message Passing Interface, 1992) • Provide standardized function interfaces for communication between parallel processes. • Collective communication operations • Broadcast, Scatter, Gather, Reduce, Allgather, Allreduce, Reduce‐scatter. • Popular implementations • MPICH (2001) • OpenMPI (2004) • http://www.open‐mpi.org/ SA MapReduceMapReduce ModelModel Google MapReduce (2004) • Jeffrey Dean et al. MapReduce: Simplified Data Processing on Large Clusters. OSDI 2004. Apache Hadoop (2005) • http://hadoop.apache.org/ • http://developer.yahoo.com/hadoop/tutorial/ Apache Hadoop 2.0 (2012) • Vinod Kumar Vavilapalli et al. Apache Hadoop YARN: Yet Another Resource Negotiator, SO 2013. • Separation between resource management and computation -

UIMA Asynchronous Scaleout Written and Maintained by the Apache UIMA™ Development Community
UIMA Asynchronous Scaleout Written and maintained by the Apache UIMA™ Development Community Version 2.4.0 Copyright © 2006, 2012 The Apache Software Foundation License and Disclaimer. The ASF licenses this documentation to you under the Apache License, Version 2.0 (the "License"); you may not use this documentation except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, this documentation and its contents are distributed under the License on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. Trademarks. All terms mentioned in the text that are known to be trademarks or service marks have been appropriately capitalized. Use of such terms in this book should not be regarded as affecting the validity of the the trademark or service mark. Publication date November, 2012 Table of Contents 1. Overview - Asynchronous Scaleout ................................................................................. 1 1.1. Terminology ....................................................................................................... 1 1.2. AS versus CPM .................................................................................................. 2 1.3. Design goals for Asynchronous Scaleout ............................................................... 3 1.4. AS Concepts ..................................................................................................... -
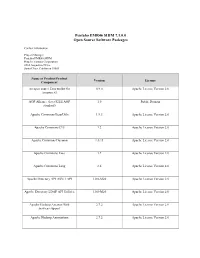
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho EMR46 SHIM Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache Commons BeanUtils 1.9.3 Apache License Version 2.0 Apache Commons CLI 1.2 Apache License Version 2.0 Apache Commons Daemon 1.0.13 Apache License Version 2.0 Apache Commons Exec 1.2 Apache License Version 2.0 Apache Commons Lang 2.6 Apache License Version 2.0 Apache Directory API ASN.1 API 1.0.0-M20 Apache License Version 2.0 Apache Directory LDAP API Utilities 1.0.0-M20 Apache License Version 2.0 Apache Hadoop Amazon Web 2.7.2 Apache License Version 2.0 Services support Apache Hadoop Annotations 2.7.2 Apache License Version 2.0 Name of Product/Product Version License Component Apache Hadoop Auth 2.7.2 Apache License Version 2.0 Apache Hadoop Common - 2.7.2 Apache License Version 2.0 org.apache.hadoop:hadoop-common Apache Hadoop HDFS 2.7.2 Apache License Version 2.0 Apache HBase - Client 1.2.0 Apache License Version 2.0 Apache HBase - Common 1.2.0 Apache License Version 2.0 Apache HBase - Hadoop 1.2.0 Apache License Version 2.0 Compatibility Apache HBase - Protocol 1.2.0 Apache License Version 2.0 Apache HBase - Server 1.2.0 Apache License Version 2.0 Apache HBase - Thrift - 1.2.0 Apache License Version 2.0 org.apache.hbase:hbase-thrift Apache HttpComponents Core