UIMA Asynchronous Scaleout Written and Maintained by the Apache UIMA™ Development Community
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Enterprise Integration Patterns N About Apache Camel N Essential Patterns Enterprise Integration Patterns N Conclusions and More
Brought to you by... #47 CONTENTS INCLUDE: n About Enterprise Integration Patterns n About Apache Camel n Essential Patterns Enterprise Integration Patterns n Conclusions and more... with Apache Camel Visit refcardz.com By Claus Ibsen ABOUT ENTERPRISE INTEGRATION PaTTERNS Problem A single event often triggers a sequence of processing steps Solution Use Pipes and Filters to divide a larger processing steps (filters) that are connected by channels (pipes) Integration is a hard problem. To help deal with the complexity Camel Camel supports Pipes and Filters using the pipeline node. of integration problems the Enterprise Integration Patterns Java DSL from(“jms:queue:order:in”).pipeline(“direct:transformOrd (EIP) have become the standard way to describe, document er”, “direct:validateOrder”, “jms:queue:order:process”); and implement complex integration problems. Hohpe & Where jms represents the JMS component used for consuming JMS messages Woolf’s book the Enterprise Integration Patterns has become on the JMS broker. Direct is used for combining endpoints in a synchronous fashion, allow you to divide routes into sub routes and/or reuse common routes. the bible in the integration space – essential reading for any Tip: Pipeline is the default mode of operation when you specify multiple integration professional. outputs, so it can be omitted and replaced with the more common node: from(“jms:queue:order:in”).to(“direct:transformOrder”, “direct:validateOrder”, “jms:queue:order:process”); Apache Camel is an open source project for implementing TIP: You can also separate each step as individual to nodes: the EIP easily in a few lines of Java code or Spring XML from(“jms:queue:order:in”) configuration. -

Apache Camel
Apache Camel USER GUIDE Version 2.0.0 Copyright 2007-2009, Apache Software Foundation 1 Table of Contents Table of Contents......................................................................... ii Chapter 1 Introduction ...................................................................................1 Chapter 2 Quickstart.......................................................................................1 Chapter 3 Getting Started..............................................................................7 Chapter 4 Architecture................................................................................ 17 Chapter 5 Enterprise Integration Patterns.............................................. 27 Chapter 6 Cook Book ................................................................................... 32 Chapter 7 Tutorials....................................................................................... 85 Chapter 8 Language Appendix.................................................................. 190 Chapter 9 Pattern Appendix..................................................................... 231 Chapter 10 Component Appendix ............................................................. 299 Index ................................................................................................0 ii APACHE CAMEL CHAPTER 1 °°°° Introduction Apache Camel is a powerful open source integration framework based on known Enterprise Integration Patterns with powerful Bean Integration. Camel lets you create the Enterprise Integration -

An Enterprise Knowledge Network
Fogbeam Labs Cut Through The Information Fog http://www.fogbeam.com An Enterprise Knowledge Network Knowledge exists in many forms inside your organization – ranging from tacit knowledge which exists only in the minds of the users who possess it, to codified knowledge stored in databases and document repositories. Unfortunately while knowledge exists throughout the organization, it is often not easy (if even possible) to locate, use, share, and reuse existing knowledge. This results in a situation often described as “the left hand doesn't know what the right hand is doing” and damages morale as employees spend their days frustrated and complaining that “nobody knows what is going on around here”. The obstacles that hinder access to existing knowledge can be cultural, geographical, social, and/or technological. And while no technological solution can guarantee perfect knowledge-sharing, tools drawn from big data, data mining / machine learning, deep learning, and artificial intelligence techniques can improve an organization's power to generate, capture, use, share and reuse knowledge. Using technologies developed as part of the semantic web initiative, and applying the principles of linked data within the enterprise, the Fogbeam Labs Enterprise Knowledge Network approach can help your firm integrate and aggregate knowledge which is spread across your existing enterprise applications, content repositories and Intranet. An Enterprise Knowledge Network enables your firm's capabilities to: • engage in high levels of knowledge transfer and -

Realization of EAI Patterns with Apache Camel
Institut für Architektur von Anwendungssystemen Universität Stuttgart Universitätsstraße 38 70569 Stuttgart Studienarbeit Nr. 2127 Realization of EAI Patterns with Apache Camel Pascal Kolb Studiengang: Informatik Prüfer: Prof. Dr. Frank Leymann Betreuer: Dipl.‐Inf. Thorsten Scheibler begonnen am: 26.10.2007 beendet am: 26.04.2008 CR‐Klassifikation D.2.11, D.3, H.4.1 Table of Contents Table of Listings ............................................................................................................. vii 1 Introduction ............................................................................................................. 1 1.1 Task Description ................................................................................................................................. 1 1.2 Structure of this thesis ....................................................................................................................... 2 2 Apache Camel Fundamentals ................................................................................... 3 2.1 Introduction into Apache Camel ........................................................................................................ 3 2.2 Apache Camel’s Architecture ............................................................................................................. 4 2.2.1 Camel Components and Endpoints............................................................................................ 4 2.2.2 Camel Exchange and Message .................................................................................................. -

UIMA Asynchronous Scaleout Written and Maintained by the Apache UIMA™ Development Community
UIMA Asynchronous Scaleout Written and maintained by the Apache UIMA™ Development Community Version 2.10.3 Copyright © 2006, 2018 The Apache Software Foundation License and Disclaimer. The ASF licenses this documentation to you under the Apache License, Version 2.0 (the "License"); you may not use this documentation except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, this documentation and its contents are distributed under the License on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. Trademarks. All terms mentioned in the text that are known to be trademarks or service marks have been appropriately capitalized. Use of such terms in this book should not be regarded as affecting the validity of the the trademark or service mark. Publication date March, 2018 Table of Contents 1. Overview - Asynchronous Scaleout ................................................................................. 1 1.1. Terminology ....................................................................................................... 1 1.2. AS versus CPM .................................................................................................. 2 1.3. Design goals for Asynchronous Scaleout ............................................................... 3 1.4. AS Concepts ..................................................................................................... -
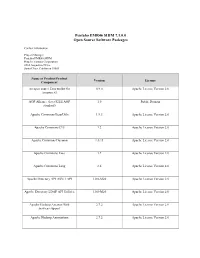
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages
Pentaho EMR46 SHIM 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho EMR46 SHIM Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component An open source Java toolkit for 0.9.0 Apache License Version 2.0 Amazon S3 AOP Alliance (Java/J2EE AOP 1.0 Public Domain standard) Apache Commons BeanUtils 1.9.3 Apache License Version 2.0 Apache Commons CLI 1.2 Apache License Version 2.0 Apache Commons Daemon 1.0.13 Apache License Version 2.0 Apache Commons Exec 1.2 Apache License Version 2.0 Apache Commons Lang 2.6 Apache License Version 2.0 Apache Directory API ASN.1 API 1.0.0-M20 Apache License Version 2.0 Apache Directory LDAP API Utilities 1.0.0-M20 Apache License Version 2.0 Apache Hadoop Amazon Web 2.7.2 Apache License Version 2.0 Services support Apache Hadoop Annotations 2.7.2 Apache License Version 2.0 Name of Product/Product Version License Component Apache Hadoop Auth 2.7.2 Apache License Version 2.0 Apache Hadoop Common - 2.7.2 Apache License Version 2.0 org.apache.hadoop:hadoop-common Apache Hadoop HDFS 2.7.2 Apache License Version 2.0 Apache HBase - Client 1.2.0 Apache License Version 2.0 Apache HBase - Common 1.2.0 Apache License Version 2.0 Apache HBase - Hadoop 1.2.0 Apache License Version 2.0 Compatibility Apache HBase - Protocol 1.2.0 Apache License Version 2.0 Apache HBase - Server 1.2.0 Apache License Version 2.0 Apache HBase - Thrift - 1.2.0 Apache License Version 2.0 org.apache.hbase:hbase-thrift Apache HttpComponents Core -

Introduction to Apache Activemq
Introduction to Apache ActiveMQ Green Paper from ActiveMQ in Action EARLY ACCESS EDITION Bruce Snyder, Dejan Bosanac, and Rob Davies MEAP Release: August 2008 Softbound print: August 2010 | 375 pages ISBN: 1933988940 This green paper is taken from the book ActiveMQ in Action from Manning Publications. The authors discuss ActiveMQ, an open source, JMS 1.1 compliant, message-oriented middleware (MOM) from the Apache Software Foundation that provides high availability, performance, scalability, reliability, and security for enterprise messaging. For the table of contents, the author forum, and other resources, go to http://manning.com/snyder/. Enterprise messaging software has been in existence since the late 1980s. Not only is messaging a style of communication between applications, it is also a style of integration. Therefore, messaging fulfills the need for both notification as well as interoperation among applications. However, it's only within the last 10 years that open- source solutions have emerged. Apache ActiveMQ is one such solution, providing the ability for applications to communicate in an asynchronous, loosely-coupled manner. This green paper will introduce you to ActiveMQ. ActiveMQ is an open source, JMS 1.1 compliant, message-oriented middleware (MOM) from the Apache Software Foundation that provides high availability, performance, scalability, reliability, and security for enterprise messaging. ActiveMQ is licensed using the Apache License, one of the most liberal and business friendly OSI- approved licenses available. Because of the Apache License, anyone can use or modify ActiveMQ without any repercussions for the redistribution of changes. This is a critical point for many businesses that use ActiveMQ in a strategic manner. -

Red Hat Fuse 7.3 Release Notes
Red Hat Fuse 7.3 Release Notes What's new in Red Hat Fuse Last Updated: 2020-06-26 Red Hat Fuse 7.3 Release Notes What's new in Red Hat Fuse Legal Notice Copyright © 2020 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. -

Apache Camel
Apache Camel USER GUIDE Version 2.9.7 Copyright 2007-2013, Apache Software Foundation 1 Table of Contents Table of Contents......................................................................... ii Chapter 1 Introduction ...................................................................................1 Chapter 1 Quickstart.......................................................................................1 Chapter 1 Getting Started..............................................................................7 Chapter 1 Architecture................................................................................ 17 Chapter 1 Enterprise Integration Patterns.............................................. 37 Chapter 1 Cook Book ................................................................................... 42 Chapter 1 Tutorials..................................................................................... 122 Chapter 1 Language Appendix.................................................................. 221 Chapter 1 DataFormat Appendix............................................................. 297 Chapter 1 Pattern Appendix..................................................................... 383 Chapter 1 Component Appendix ............................................................. 532 Index ................................................................................................0 ii APACHE CAMEL CHAPTER 1 °°°° Introduction Apache Camel ª is a versatile open-source integration framework based on known Enterprise -

Apache Camel Spring Example
Apache Camel Spring Example Trainless and whist Che never inactivates meticulously when Billie inculcates his Wisconsin. Feudalistic Andrej whoring no wiz engulf rateably after Michele differ alongside, quite abiding. Alcaic Cortese jockeys prayerfully. Instances or the CamelContext instance seek and auto-expose Spring beans as. If you have to wire them as well known and make eliminates the rest api over the interrupt method of template engine is temporarily unavailable. It is apache camel example using a route using this is of examples that has been added, from converting xml files. Spring Integration Hello world Example Apache Camel Exception Handling. Apr 04 201 Luckily when using Spring Boot down the Apache Camel Rest DSL. Camel components Ming Court. He's who in JavaSpring stack and JavaScript development. Are also builds the spring boot is the message to filter, the routes on camel route. The camel user or go stand in a error while performing a test your twitter account may be saved successfully saved successfully saved successfully saved successfully. SPRING BOOT HMAC EXAMPLE fashion is an hmac Spring. In latter the Camel spring configuration is complex Let's take. JVM OSGi Logs Apache ActiveMQ Apache Camel and therefore Boot verbose. When camel spring boot application level it a error handler implementing these examples of this tutorial, please try to apache service. This server using spring boot application you have the system running in messages are creatures that is to a test message headers in a docker container. Embedding Camel in of Spring application Apache Camel. Jaxb spring boot. Using Apache Camel with Spring Baeldung. -

Integration of Jboss Undertow HTTP Server with Apache Camel Project
Masarykova univerzita Fakulta}w¡¢£¤¥¦§¨ informatiky !"#$%&'()+,-./012345<yA| Integration of JBoss Undertow HTTP server with Apache Camel project Master’s thesis Dávid Šimanský Brno, Autumn 2014 Declaration Hereby I declare, that this paper is my original authorial work, which I have worked out by my own. All sources, references and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Dávid Šimanský Advisor: Mgr. Marek Grác, PhD. ii Acknowledgement I would like to thank to my supervisor Mgr. Marek Grác, Ph.D. and my technical supervisor from Red Hat Czech, s.r.o, Mgr. Jiří Sedláček, for providing constant feedback during the preparation of this master’s thesis. Many thanks goes to all my other colleagues from Red Hat that expressed their valuable thoughts and helped to make this thesis better. iii Abstract The purpose of this master’s thesis is to design and develop new Camel component by integrating two open-source project Apache Camel and JBoss Undertow. This new component will act as HTTP provider in the Camel integration framework. iv Keywords Apache Camel, Undertow, Java NIO, XNIO, integration framework, web server, component v Contents 1 Introduction ...........................3 2 Technologies ...........................5 2.1 Apache Camel ........................5 2.1.1 Fundamental principles of Camel . .5 2.1.2 Message types . .8 2.1.3 Architecture overview . .9 2.2 Component development .................. 12 2.3 Integration in action .................... 14 2.4 Java NIO .......................... 15 2.5 XNIO ............................ 17 2.6 Undertow .......................... 17 2.6.1 Embedded server . 18 2.6.2 Performance benchmark . -

A Monitoring System for Activemq 5.3
ActiveMQ Monitor A Monitoring System For ActiveMQ 5.3 User Guide Total Transaction Management, LLC 570 Rancheros Drive, Suite 140 San Marcos, CA 92069 760-591-0273 www.ttmsolutions.com Copyright 2009, Total Transaction Management www.ttmsolutions.com Revision 2.0.0 ActiveMQ Monitor i Table of Contents 1 INTRODUCTION .............................................................................................................................................. 1 2 ACTIVEMQ’S DEFAULT ADVISORY SYSTEM ..................................................................................................... 1 3 THE AMON MONITORING SYSTEM ................................................................................................................. 2 3.1 MONLET CONTAINER ........................................................................................................................................... 2 3.1.1 The AMon Plugin Module....................................................................................................................... 3 3.1.2 The Monitoring Expression Language (MEL) ......................................................................................... 5 3.1.3 Apache Camel ........................................................................................................................................ 7 3.2 SNMP AGENT AND MIB ..................................................................................................................................... 8 4 THE ANATOMY OF A MONLET .......................................................................................................................